机器学习_神经网络训练时梯度爆炸和梯度消失产生的原因及解决方法
一般在深层神经网络中,我们需要预防梯度爆炸和梯度消失的情况。梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)一般随着网络层数的增加会变得越来越明显。例如下面所示的含有三个隐藏层的神经网络,梯度消失问题发生时,接近输出层的hiden layer3的权重更新比较正常,但是前面的hidden layer1的权重更新会变得很
梯度爆炸和梯度消失问题
一般在深层神经网络中,我们需要预防梯度爆炸和梯度消失的情况。
梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)一般随着网络层数的增加会变得越来越明显。
例如下面所示的含有三个隐藏层的神经网络,梯度消失问题发生时,接近输出层的hiden layer3的权重更新比较正常,但是前面的hidden layer1的权重更新会变得很慢,导致前面的权重几乎不变,仍然接近初始化的权重,这相当于hidden layer1没有学到任何东西,此时深层网络只有后面的几层网络在学习,而且网络在实际上也等价变成了浅层网络。
那么产生这种现象的原因是什么呢?
我们来看看看反向传播的过程:
(假设网络每一层只有一个神经元,并且对于每一层yi=σ(zi)=σ(wixi+bi)y_{i} = \sigma(z_{i}) = \sigma(w_{i}x_{i} + b_{i})yi=σ(zi)=σ(wixi+bi))

可以推导出:

而sigmoid的导数σ′(x)\sigma^{'}(x)σ′(x)如下图所示:
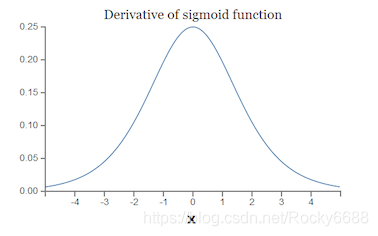
可以知道,σ′(x)\sigma^{'}(x)σ′(x)的最大值是14\frac{1}{4}41,而我们初始化的权重∣w∣|w|∣w∣通常都小于1,因此σ′(x)∣w∣<=14\sigma^{'}(x)|w| <= \frac{1}{4}σ′(x)∣w∣<=41,而且链式求导层数非常多,不断相乘的话,最后的结果越来越小,趋向于0,就会出现梯度消失的情况。
梯度爆炸则相反,σ′(x)∣w∣>1\sigma^{'}(x)|w| > 1σ′(x)∣w∣>1时,不断相乘结果变得很大。
梯度爆炸和梯度消失问题都是因为网络太深,网络权重更新不稳定造成的,本质上是因为梯度方向传播的连乘效应。
梯度爆炸和梯度消失的解决方法
- 预训练加微调。
- 梯度截断。
- 使用ReLU、LeakyReLU等激活函数。
- 加BN层。
- 使用残差结构。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)