【数据分析实战经验】预测真实员工离职率(涉及模型:随机森林、逻辑回归,数据量:28211,工具:python)
1、地区划分0、未知1、华北五省二市——北京市、天津市、河北省、河南省、内蒙古自治区、山西省、山东省2、华东五省一市——上海市、江苏省、江西省、安徽省、浙江省、福建省3、东北三省——黑龙江省、吉林省、辽宁省4、西北五省——陕西省、甘肃省、宁夏回族自治区、青海省、新疆维吾尔自治区5、西南四省一市——四川省、重庆市、贵州省、云南省、西藏自治区6、华南五省——湖北省、湖南省、广东省、广西省、海南省7、港
第二部分:员工离职预测
在上期用过bi分析了离职数据集,本期用所学的机器学习算法来试着预测职工离职概率。
点击跳转上一期:离职情况分析①
开发步骤概述

一、导入模块与文件
##引入必要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
import seaborn as sns
from sklearn import preprocessing
%matplotlib inline
## 导入文件
df_online=pd.read_csv(r'C:\Users\ADMIN\Desktop\离职预测\machine learning\online.csv')
df_offline=pd.read_csv(r'C:\Users\ADMIN\Desktop\离职预测\machine learning\offline.csv')
## 合并文件&查看
df=pd.concat([df_online,df_offline])
df.head()

共计28211行,19列特征
二、数据清洗
##去重
df.drop_duplicates()
df.info()
df.describe()
- 其中数据清洗过程过于冗长详细
- 比如工时、工种、年龄缺失,根据岗位类型、部门等等进行填补,
- 比如进公司时间缺失,可以根据年龄和工作年限反推
- 比如年龄等等之类异常值,这次主要想讲述特征工程,故不多赘述这块
三、特征工程
3.1特征构造
- 看看清洗后的数据概况
##重新设置index
df=df.reset_index(drop=True)
df.info()

一共28211条数据,其中数值型有6条,先看看有没有什么异常值。
进一步处理特征
##转换数据类型
df.出生日期=pd.to_datetime(df.出生日期)
df.进公司时间=pd.to_datetime(df.进公司时间)
##删去明显无关的特征
df.drop(['工号','姓名','合同所属地'],axis=1,inplace=True)
##转换类别特征,变成有序类别数值型特征
df.groupby(by='学历').size()
a=[]
for i in df.学历:
if i=='专科':
a.append(1)
elif i=='本科':
a.append(2)
elif i=='研究生':
a.append(3)
else:
a.append(4)
len(a)
df['教育程度']=a

因为进公司时间与工作年限,出生日期与年龄这两对特征本身基本可以互相转换,线性相关性较强,为了简单理解,本次处理先
删去进公司时间、出生日期,以及用教育程度代替学历
df.drop(['进公司时间','出生日期','学历'],axis=1,inplace=True)
得到特征

因为计算机最终都是以识别数值型的数据为基础开始机器学习,红框中还有很多文字性特征后续需要进行独热编码
- 查看正负样本比例
符合真实情况,大概是3/7开
pos_data=df[df.是否离职==1]
neg_data=df[df.是否离职==0]
print('正样本数量:{},所占比例:{}'.format(len(pos_data),len(pos_data)/len(df)))
print('负样本数量:{},所占比例:{}'.format(len(neg_data),len(neg_data)/len(df)))

3.2 特征筛选
查看离职标签特征与其他维度特征的关系
法一:单个变量之间看
plt.figure
sns.countplot(x='是否离职',data=df,hue='性别') ##hue里面可以替换成学历、岗位等级等等。

箱型图表示
# 单变量关系
plt.figure()
## 离职与年龄的关系
plt.subplot(2,2,1)
sns.boxplot(x='是否离职',y='年龄',data=df)
## 离职与职级的关系
plt.subplot(2,2,2)
sns.boxplot(x='是否离职',y='岗位等级',data=df)
## 离职与工作年限的关系
plt.subplot(2,2,3)
sns.boxplot(x='是否离职',y='工作年限',data=df)
## 离职与工作年限的关系
plt.subplot(2,2,4)
sns.boxplot(x='是否离职',y='培训记录',data=df)
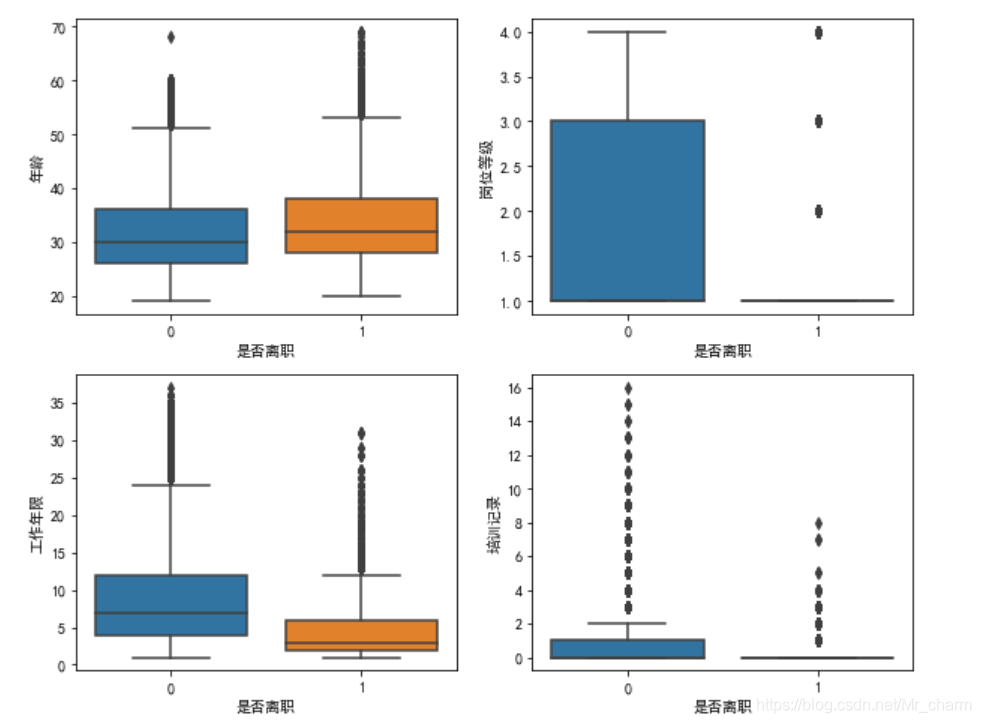
法二:多变量之间直接看
相关系数:皮尔逊(线性、连续),斯皮尔曼(离散等等),很明显与学号无关
corr=df.corr(method='spearman')
fig=plt.figure(figsize=(10,8))
sns.heatmap(corr,vmax=1,linewidths=0.01,
square=True,annot=True, cmap='viridis',linecolor='white')
plt.title('互相影响度')
plt.show()
绝对值越大于1越相关。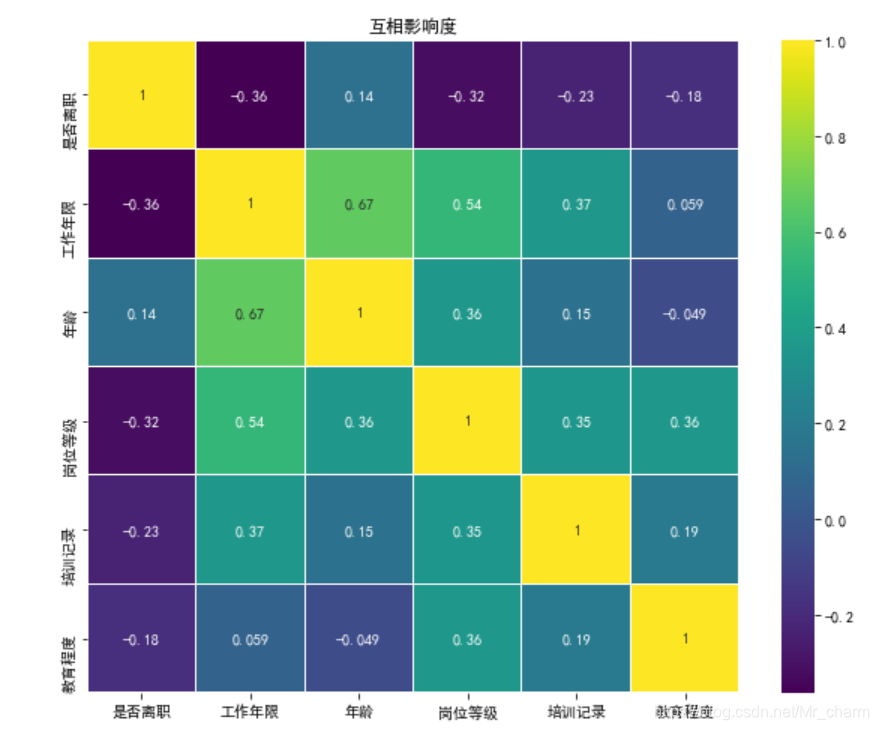
3.3 特征转换
第一步:特征分类
## 数值型特征
num_cols=['工作年限','年龄','培训记录']
## 无序类别
cat_cols=['当前机构','部门','性别','籍贯','工时','合同类型','奖惩记录','工种']
##有序类别
order_cols=['岗位等级','教育程度']
##目标列
target_cols=['是否离职']
## 所有特征列
total_cols=num_cols+cat_cols+order_cols
used_data=df[total_cols+target_cols]
print('使用{}列数据作为特征'.format(len(total_cols)))
使用13列数据作为特征
第二步:独热编码
常用两种方法进行独热编码,一种是pandas的get_dummies,一种是sklearn的OneHotEncoder。
本次使用的是第二种,先编码再分割数据集
OneHotEncoder
## 对无序类别进行独热编码"one hot"
##先进行 label Encoding
#### 无序类别 ['当前机构','部门','性别','籍贯','工时','合同类型','奖惩记录','工种']
## 当前机构
belong_label=preprocessing.LabelEncoder()
used_data['当前机构']=belong_label.fit_transform(used_data['当前机构'])
##部门
dep_label=preprocessing.LabelEncoder()
used_data['部门']=dep_label.fit_transform(used_data['部门'])
## 性别
gender_label=preprocessing.LabelEncoder()
used_data['性别']=gender_label.fit_transform(used_data['性别'])
## 籍贯
place_label=preprocessing.LabelEncoder()
used_data['籍贯']=place_label.fit_transform(used_data['籍贯'])
##工时
time_label=preprocessing.LabelEncoder()
used_data['工时']=time_label.fit_transform(used_data['工时'])
## 合同类型
con_label=preprocessing.LabelEncoder()
used_data['合同类型']=con_label.fit_transform(used_data['合同类型'])
## 奖惩记录
pun_label=preprocessing.LabelEncoder()
used_data['奖惩记录']=pun_label.fit_transform(used_data['奖惩记录'])
## 工种
work_label=preprocessing.LabelEncoder()
used_data['工种']=work_label.fit_transform(used_data['工种'])
##再进行one_hot encoding
one_hot_enc=preprocessing.OneHotEncoder()
used_cat_feats=one_hot_enc.fit_transform(used_data[['当前机构','部门','性别','籍贯','工时','合同类型','奖惩记录','工种']]).toarray()
print(used_cat_feats.shape)
发现特征维度扩充到了99列,简单看看转换后的样子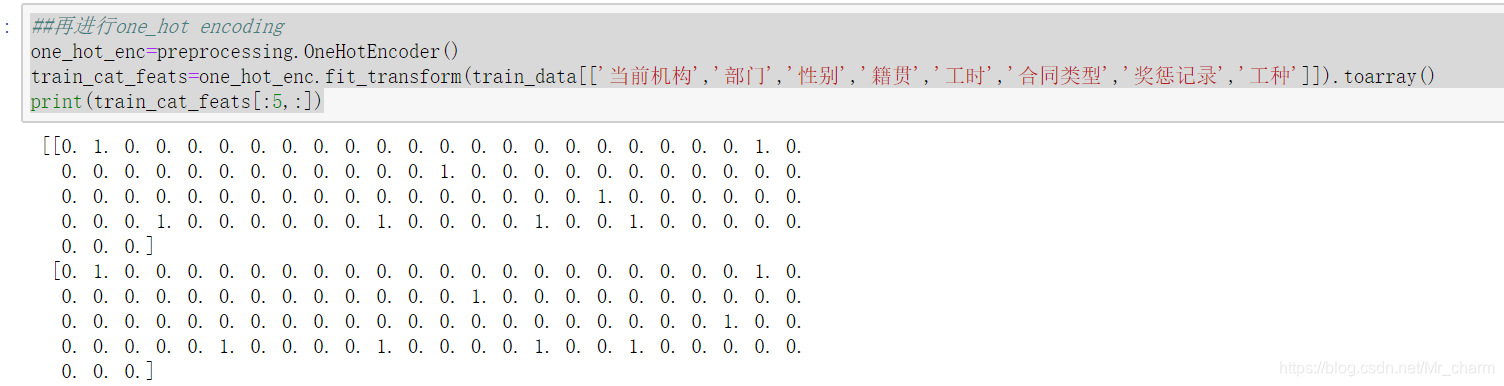
##整合特征
used_num_feats=used_data[num_cols].values
used_ord_feats=used_data[order_cols].values
used_feats=np.hstack((used_num_feats,used_ord_feats,used_cat_feats))
used_target=used_data[target_cols].values
used_feats=pd.DataFrame(used_feats)
used_target=pd.DataFrame(used_target)
used_target.columns=['是否离职']
used_data=pd.concat([used_feats,used_target],axis=1)
used_data.head()
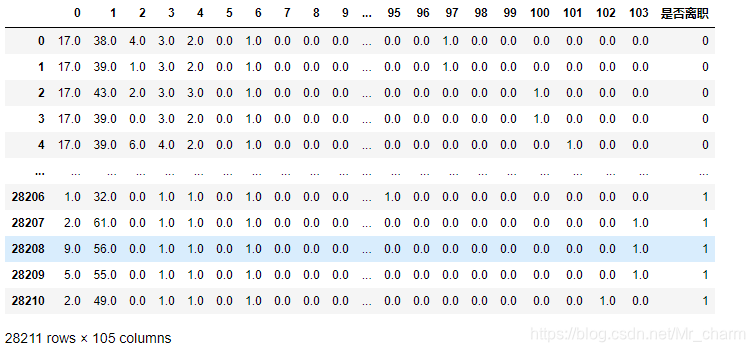
构造出105列的特征了
** 附:get_dummies**
另一种pandas自带的方法,也是整体进行编码再划分数据集。
df_1=pd.concat([train_data,pos_data])
df_1.shape
df_one_hot=pd.get_dummies(df_1[cat_cols])
df_one_hot.shape
df_2=df_1.drop(columns=cat_cols)
df_3=pd.concat([df_2,df_one_hot],axis=1)
df_3.head()

3.4 分割数据集
同样有两种方法,一种是train_test_split,另一种是人为从正负样本 2 8分,本文采用的是第二种。能够保证在训练集和测试集中样本分布接近。
人为分训练测试集
## 分割训练集,测试集,80%作为训练集,20%测试集
## 保证训练集、测试集中的正负样本比例一致
pos_data=used_data[used_data['是否离职']==1].reindex()
train_pos_data=pos_data.iloc[:int(len(pos_data)*0.8)].copy()
test_pos_data=pos_data.iloc[int(len(pos_data)*0.8):].copy()
neg_data=used_data[used_data['是否离职']==0].reindex()
train_neg_data=neg_data.iloc[:int(len(neg_data)*0.8)].copy()
test_neg_data=neg_data.iloc[int(len(neg_data)* 0.8):].copy()
train_data=pd.concat([train_pos_data,train_neg_data])
test_data=pd.concat([test_pos_data,test_neg_data])
print('训练集数据个数',len(train_data))
print('正负样本比例',len(train_pos_data)/len(train_neg_data))
print('测试集数据个数',len(test_data))
print('正负样本比例',len(test_pos_data)/len(test_neg_data))

最后再分别从训练、测试集中,拆分出特征和标签
train_feats=train_data.iloc[:,:-1].values
test_feats=test_data.iloc[:,:-1].values
train_target=train_data[['是否离职']].values
test_target=test_data[['是否离职']].values
print('训练数据:',train_feats.shape)
print('测试数据:',test_feats.shape)
print('训练标签:',train_target.shape)
print('测试标签:',test_target.shape)

附:利用sklearn自带的方法分
除了手动分,也可以自动代码分割
##分割训练、测试集
from sklearn.model_selection import train_test_split
X = df.drop(['是否离职'], axis=1)
y = df['是否离职']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# random_state=0 表示每次分割后结果都不一样
3.5 处理不平衡数据
注:仅在训练集中的特征列和标签列进行处理,测试集当作真实数据,不动他。
重采样
##处理不平衡数据,过采样少的样本,多次放回抽取数据,直到正负样本相近,安装 pip install-U imbalanced-learn
from imblearn.over_sampling import SMOTE
print('重采样前:')
print('正样本数:',len(y_train[y_train==1]))
print('负样本数:',len(y_train[y_train==0]))
sm=SMOTE(random_state=0)
X_re_train,y_re_train=sm.fit_resample(X_train.values,y_train.values)
print('重采样后:')
print('正样本数:',len(y_re_train[y_re_train==1]))
print('负样本数:',len(y_re_train[y_re_train==0]))

原先在训练集正负样本不均衡,现在采样成均衡1:1的数据了
最终用到的数据
##最终的测试集和训练集
print(len(train_re_feats))
print(len(train_re_target))
print(len(test_feats))
print(len(test_target))
3.5 特征降维
PCA主成成分
注意:降维要在训练集和测试集的特征列降维,但本文维度100还好,且试着降维后反而拉低了模型准确率。
可以设置n_components=‘mle’ ,让PCA自己找最合适的特征数
##PCA 降维之后看看
from sklearn.decomposition import PCA
pca=PCA(n_components=96)
train_re_feats_rf=pca.fit_transform(train_re_feats)
print(train_re_feats_rf.shape)
test_feats_rf=pca.fit_transform(test_feats)
print(test_feats_rf.shape)
四、模型带入
因为本文的目的是分类,所以在分类模型中找了两个有代表性的算法,RF和LR
4.1 随机森林
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
rf_clf=RandomForestClassifier(random_state=0,n_estimators=91) #调参后续会讲
print(rf_clf.fit(train_re_feats,train_re_target))
print('训练集准确率:',rf_clf.score(train_re_feats,train_re_target))
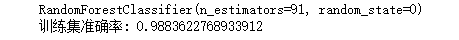
X_train_pred = rf_clf.predict(train_re_feats)
X_test_pred = rf_clf.predict(test_feats)
print('训练集混淆矩阵:')
print(metrics.confusion_matrix(train_re_target,X_train_pred,labels=[1,0]))
print('测试集混淆矩阵:')
print(metrics.confusion_matrix(test_target,X_test_pred,labels=[1,0]))
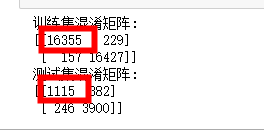
红框表示为1的数量,
##输出矩阵报告
from sklearn.metrics import classification_report
print('训练集:')
print(classification_report(train_re_target, X_train_pred))
print('测试集:')
print(classification_report(test_target, X_test_pred))
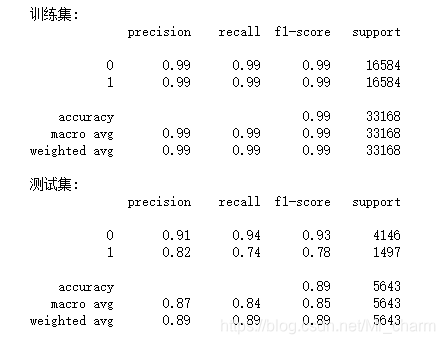
因为测试集的召回率0.74 ,动手试着调参
4.2 调参
参考文章
通过交叉验证选择最优的随机森林需要的决策树数量
##因为在测试集的召回率只有0.75,想看看能不能通过交叉验证找到n_estimators参数择优,其他参数仍然是默认值。
#n_esimators参数择优的范围是:1~101,步长为10。十折交叉验证选择最优n_estimators 。
from sklearn.model_selection import GridSearchCV
param_test1={'n_estimators':range(1,101,10)}
gsearch=GridSearchCV(estimator=RandomForestClassifier(),param_grid=param_test1,
scoring='roc_auc',cv=10)
gsearch.fit(train_re_feats,train_re_target)
print('最优选{}'.format(gsearch.best_params_))
print('最优选准确率{}'.format(gsearch.best_score_))
得到最优选的树是91棵,再重新带入4.1的代码,设置n_estimators=91
##最优选91棵决策树,没什么区别
##PCA之前的数据,不降维反而表现很好
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
rf_clf=RandomForestClassifier(random_state=0,n_estimators=91)
print(rf_clf.fit(train_re_feats,train_re_target))
print('训练集准确率:',rf_clf.score(train_re_feats,train_re_target))
X_train_pred = rf_clf.predict(train_re_feats)
X_test_pred = rf_clf.predict(test_feats)
print('训练集混淆矩阵:')
print(metrics.confusion_matrix(train_re_target,X_train_pred,labels=[1,0]))
print('测试集混淆矩阵:')
print(metrics.confusion_matrix(test_target,X_test_pred,labels=[1,0]))
from sklearn.metrics import classification_report
print('训练集:')
print(classification_report(train_re_target, X_train_pred))
print('测试集:')
print(classification_report(test_target, X_test_pred))
感觉没什么区别,哈哈
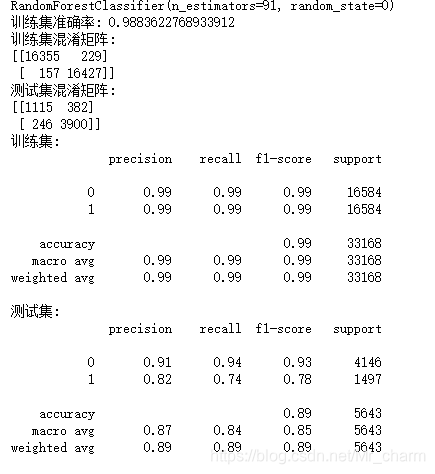
1497个离职,预测出1115个人,很顶了。
看看测试集上的预测离职为1的查准率和召回率,一个是0.82,一个是0.74还是不错的。
4.3 逻辑回归
特征数据标准化
注:训练集和测试的特征列需要用,标签列不用,前一个算法因为随机森林这类树模型本身就不需要进行标准化,但逻辑回归这类线性模型需要标准化,因为量纲之间存在较大差距会产生影响
##逻辑回归需要进行标准化,因为数据本身之间量纲存在差距,
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
test_feats = sc_X.fit_transform(test_feats)
train_re_feats = sc_X.fit_transform(train_re_feats)
#逻辑回归模型,因为本身量纲之间
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression(penalty='l1',solver='liblinear')
print(LR.fit(train_re_feats, train_re_target))
print("训练集准确率: ", LR.score(train_re_feats,train_re_target))
print("测试集准确率: ", LR.score(test_feats,test_target))
这里备注一下,如果是过拟合可以加上惩罚系数,默认是l2正则,l1的话要修改slover
# l1正则要修改solver,l2正则是默认的可以输入"l1"或"l2"来指定使用哪一种正则化方式,不填写默认"l2"。
# 注意,若选择"l1"正则化,参数solver仅能够使用求解方式”liblinear"和"saga“,若使用“l2”正则化,参数solver中所有的求解方式都可以使用。
# 注:
# solver:优化算法选择参数,有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear。solver参数决定了对逻辑回归损失函数的优化方法:
# liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
# lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
# newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
# sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅用一部分的样本来计算梯度,适合于样本数据多的时候。
# saga:快速梯度下降法,线性收敛的随机优化算法的的变种。
带入模型
from sklearn import metrics
X_train_pred =LR.predict(train_re_feats)
X_test_pred = LR.predict(test_feats)
print('训练集混淆矩阵:')
print(metrics.confusion_matrix(train_re_target, X_train_pred,labels=[1,0]))
print('测试集混淆矩阵:')
print(metrics.confusion_matrix(test_target, X_test_pred,labels=[1,0]))
##输出矩阵报告
from sklearn.metrics import classification_report
print('训练集:')
print(classification_report(train_re_target, X_train_pred))
print('测试集:')
print(classification_report(test_target, X_test_pred))
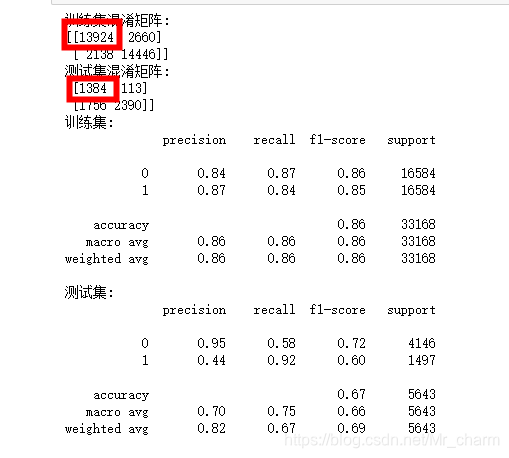
逻辑回归在测试集离职上的预测,差准率不高,但是召回率0.92 ,就是查出的有很多是在职的,但是能把离职的大部分都预测出来。
1497个离职的能预测出1384个。
4.4 ROC评估两个模型
利用ROC看面积
from sklearn import metrics
from sklearn.metrics import roc_curve
#将逻辑回归模型和高斯朴素贝叶斯模型预测出的概率均与实际值通过roc_curve比较返回假正率, 真正率, 阈值
lr_fpr, lr_tpr, lr_thresholds = roc_curve(test_target, LR.predict_proba(test_feats)[:,1])
rf_fpr, rf_tpr, rf_thresholds = roc_curve(test_target, rf_clf.predict_proba(test_feats)[:,1])
#分别计算这两个模型的auc的值, auc值就是roc曲线下的面积
lr_roc_auc = metrics.auc(lr_fpr, lr_tpr)
rf_roc_auc = metrics.auc(rf_fpr, rf_tpr)
plt.figure(figsize=(8, 5))
plt.plot([0, 1], [0, 1],'--', color='r')
plt.plot(lr_fpr, lr_tpr, label='LogisticRegression(area = %0.2f)' % lr_roc_auc)
plt.plot(rf_fpr, rf_tpr, label='(RandomForestClassifierarea = %0.2f)' % rf_roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.title('ROC')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.legend()
plt.show()
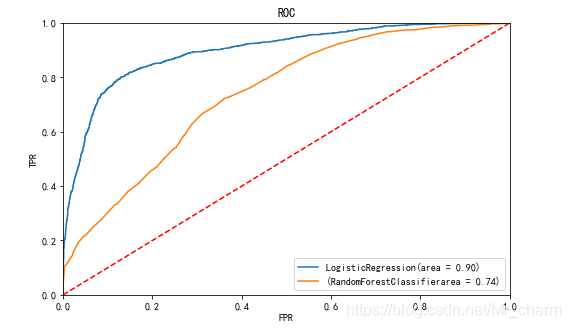
做到这,有个疑问,为什么单看随机森林整体混淆矩阵的表现会比逻辑回归高,但是ROC确低于逻辑回归。
看了一下ROC曲线的纵坐标是:TPR真正类率,预测为正且实际为正的所有正例样本比例,其实就是召回率
而横坐标是FPR,预测为正但实际为负的样本占所有负样本的比例,虚报程度。
整体上还是会选择逻辑回归。
保持渴求,不要沉寂


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)