

spark与akka
For the latest version and dark-mode, read it on my blog.
有关最新版本和暗模式, 请在我的博客上阅读 。
Around the world, renewable energy use is on the rise, as those alternative energy sources could hold the key to combating climate change.
在全球范围内,可再生能源的使用量正在上升,因为这些替代能源可能成为应对气候变化的关键。
However, with its unpredictable nature, renewable energy generation brings in new technological challenges. Unlike with the old-style centralized fossil fuel generation, in which supply could be turned up and down according to demand, renewable energy generation can’t be forecast precisely. This unpredictable nature of both power generation and power consumption can lead to times of high supply not aligned with times of high demand. To face this problem, Lithium-ion batteries are being used, such as this mega-battery built by Tesla in South Australia. As power consumption is low and generation is high, batteries are able to store the inflating power for later use.
然而,由于其不可预测的性质,可再生能源发电带来了新的技术挑战。 与老式的集中化石燃料发电不同,后者可以根据需求上下调节供应量,而可再生能源发电量则无法精确预测。 发电和功耗的这种不可预测的性质可能导致高供应时间与高需求时间不符。 为了解决这个问题,人们正在使用锂离子电池,例如特斯拉在南澳大利亚生产的这种巨型电池 。 由于功耗低且发电量高,电池能够存储充气功率以备后用。
Tesla’s engineers have expanded this solution by introducing the concept of a Virtual Power Plant. In addition to giant centralized batteries, Tesla can aggregate the power produced by many individual households to form a distributed power grid. As rooftop solar systems coupled with Powerwall residential storage batteries are installed at each house, a cloud-based network is able to keep track on the batteries’ status, charge or discharge them, and to run real-time analysis on data, enabling to optimize power distribution and even manipulating the local power market.
特斯拉的工程师通过引入虚拟电厂的概念扩展了该解决方案。 除了巨型集中式电池外,特斯拉还可以聚合许多家庭所产生的电力,从而形成分布式电网。 由于在每个房屋中都安装了屋顶太阳能系统和Powerwall住宅蓄电池,因此基于云的网络能够跟踪蓄电池的状态,对其进行充电或放电,并对数据进行实时分析,从而优化配电,甚至操纵本地电力市场。
In this post, we will outline the implementation of a simple distributed Virtual Power Plant by using Scala, Akka, and the Actor Model, as we explain the basic ideas behind the Actor Model.
在这篇文章中,当我们解释Actor模型背后的基本思想时,我们将概述使用Scala,Akka和Actor模型实现一个简单的分布式虚拟电厂的实现。
该平台 (The Platform)
We wish to implement a cloud-based service that allows us to connect power-generating units (such as houses) to the network, and to query, at any given moment, the power levels of all houses connected to a given geographical region.
我们希望实现一项基于云的服务,该服务允许我们将发电设备(例如房屋)连接到网络,并在任何给定时刻查询连接到给定地理区域的所有房屋的电力水平。

Since a power resource can be a house, but it can also be a physical power plant such as a solar farm or a windmill farm, we use the generalized term Resource to describe any power-generating unit.
由于电力资源可以是房屋,也可以是诸如太阳能场或风车场之类的物理发电厂,因此我们使用通用术语“ Resource来描述任何发电单元。
In the above, a controller sends an HTTP request to connect a specific resource to a specific region in the system. The platform receives a continuous stream of Telemetry data via a dedicated WebSocket, which specifies the current battery level of that resource. The platform supports queries about battery levels of all connected Resources of a given Region.
在上面,控制器发送HTTP请求以将特定资源连接到系统中的特定区域。 该平台通过专用的WebSocket接收连续的遥测数据流,该WebSocket指定该资源的当前电池电量。 该平台支持有关给定地区所有已连接资源的电池电量的查询。
演员模型 (The Actor Model)
The system is expected to receive and process streams of real-time data that are produced by many different power-resources, and which are produced simultaneously. Handling those computations in a single thread of execution would result in unusably slow applications, memory problems, crashes, and timeouts. To support such the concurrent nature of such a platform, there is a need for Multithreading.
预计该系统将接收和处理由许多不同电源产生并同时产生的实时数据流。 在单个执行线程中处理这些计算将导致应用程序缓慢,内存问题,崩溃和超时。 为了支持这种平台的这种并发特性,需要Multithreading 。
锁很难 (Locking is hard)
With Multithreading, it is hard to guarantee a true encapsulation of shared resources. As threads can be interleaved in an arbitrary and non-deterministic way, it is easy to introduce rase-conditions and to reach a corrupted state. The only way to eliminate those risks is by coordinating those threads, usually with Locking.
使用多线程,很难保证共享资源的真正封装。 由于可以以任意和不确定的方式交错线程,因此很容易引入擦除条件并达到损坏状态 。 消除这些风险的唯一方法是协调这些线程,通常是使用Locking 。
While Locking ensures the validity of the execution, it comes with a heavy price: Locks dramatically limit parallelism, as threads often cannot work in parallel. Furthermore, it is easy to introduce deadlocks and livelocks, as coordinating between a pool of threads is complex in nature. Another considerable complexity with Locks is with Horizontal scalability — When it comes to coordinating across multiple machines, locks are also being distributed. Unfortunately, distributed locks are several magnitudes less efficient than local locks and usually impose a hard limit on scaling out. Distributed lock protocols require several communication round-trips over the network across multiple machines, which dramatically increases latency.
虽然Locking确保执行的有效性,但代价不菲:Locks极大地限制了并行性 ,因为线程通常无法并行工作。 此外,很容易引入死锁和活锁,因为线程池之间的协调本质上很复杂 。 锁的另一个相当大的复杂性是水平可伸缩性 -当涉及跨多台机器进行协调时,锁也正在分发。 不幸的是,分布式锁的效率要比本地锁低几个数量级,并且通常会对横向扩展施加硬限制。 分布式锁定协议需要跨多台计算机在网络上进行几次通信往返,这大大增加了延迟。
Writing concurrent systems using traditional low-level mechanisms such as locks and threads is difficult. The resulting software is often hard to understand and maintain.
使用传统的低级机制(例如锁和线程)编写并发系统很困难。 最终的软件通常很难理解和维护。
进入演员模型 (Enters the Actor Model)
The Actor Model is ideal for thinking about highly concurrent and scalable systems. The Actor Model provides a higher-level alternative that is much easier to reason about. In the actor model, we consider our system to be composed of Actors, computational primitives that have a private state, that can send and receive messages, and perform computations based on those messages. The system is composed of different actors who communicate via messages and never share memory.
Actor模型非常适合考虑高度并发和可扩展的系统。 Actor模型提供了更容易推理的更高层次的选择。 在参与者模型中,我们认为我们的系统由参与者 ,具有私有状态的计算原语组成,可以发送和接收消息,并根据这些消息执行计算。 该系统由不同的参与者组成,这些参与者通过消息进行通信并且从不共享内存。
“The Actor Model represents the intent of OOP in a purer way. The way classical OOP is implemented in many languages simply doesn’t take into account parallelism and introducing multi-threading “breaks” that paradigm. If nothing else I believe actors are simply a better implementation of objects.” source
“演员模型以更纯粹的方式代表了OOP的意图。 在许多语言中实现经典OOP的方式根本没有考虑到并行性,也没有引入范式的多线程“中断”。 如果没有别的,我相信参与者就是对象的更好实现。” 资源
The main benefit of using the Actor Model over classical Object-Oriented Programming is that it is a better way to model Concurrency and Distribution. Actors have no shared state, which eliminates situations of race-conditions. Thus, designing and implementing concurrent systems becomes simpler. Actors also provide location transparency, in the sense that the user of an Actor does not need to know whether that Actor lives in the same processor on a different machine. This makes it simple to write software that can scale with the needs of the application. It also gives the runtime the freedom to provide services like Adaptive Load Balancing, Cluster Rebalancing, Replication, and Partitioning.
与经典的面向对象编程相比,使用Actor模型的主要好处是它是对并发和分布建模的更好方法。 角色没有共享状态,这消除了竞争条件的情况。 因此,设计和实现并发系统变得更加简单。 从某种意义上讲,Actor的用户不需要知道该Actor是否位于不同机器上的同一处理器中,Actor还可以提供位置透明性 。 这使得编写可随应用程序需求扩展的软件变得简单。 它还使运行时可以自由提供诸如自适应负载平衡 , 群集重新平衡 , 复制和分区之类的服务 。
用Akka实施 (Implementation with Akka)
为什么是阿卡? (Why Akka?)
Akka is an open-source middleware for building highly-concurrent, distributed, and fault-tolerant systems on the JVM. Akka embraces Erlang’s model for fault-tolerance, colloquially known as “let it crash.” This fault-tolerance model works by organizing the various Actors in a system in a supervisor hierarchy such that each component is monitored by another, and restarted upon failure.
Akka是一种开源中间件,用于在JVM上构建高度并发 , 分布式和容错的系统。 Akka拥护Erlang的容错模型,俗称“让它崩溃”。 此容错模型通过将系统中的各个Actor组织在主管层次结构中来工作 ,以便每个组件都由另一个组件监视,并在发生故障时重新启动。
演员层次树 (The Actors hierarchy tree)
In Akka, an actor always belongs to a parent. Typically, we create an actor by calling context.actorOf(), which injects the new actor as a child into an already existing tree, as the creator actor becomes the parent of the newly created child actor.
在阿卡族,演员总是属于父母。 通常,我们通过调用context.actorOf()创建一个actor,当创建者actor成为新创建的子actor的父代时,它将作为子元素的新actor注入到已经存在的树中。
One of the main design challenges for Akka programmers is choosing the best granularity for actors. In practice, depending on the characteristics of the interactions between actors, there are usually several valid ways to organize a system. Nevertheless, we can follow some basic rules which can help us choose the most appropriate actor hierarchy. In general, we would prefer a larger granularity of Actors. A finer granularity should be considered in the following cases:
Akka程序员面临的主要设计挑战之一是为参与者选择最佳粒度 。 在实践中,根据参与者之间交互的特征,通常有几种有效的方法来组织系统。 但是,我们可以遵循一些基本规则,这些规则可以帮助我们选择最合适的参与者层次。 通常, 我们希望使用更大的Actor 粒度 。 在以下情况下,应考虑更精细的粒度:
-
A Higher concurrency is required.
需要更高的并发性 。
-
There is a complex communication between Actors, and those Actors have many possible states. This communication can be represented with a separate Actor.
Actor之间存在复杂的通信 ,并且这些Actor具有许多可能的状态。 可以使用一个单独的Actor来表示此通信。
-
The state of an Actor is large and it makes sense to divide into smaller actors.
一个Actor的状态很大 ,因此划分成较小的actor是有意义的。
-
An Actor has multiple unrelated responsibilities. Using separate actors allows individual actors to fail and to be restored with little impact on others.
演员具有多个不相关的职责 。 使用单独的actor可使单个actor失败并被恢复,而对其他actor的影响很小。
Back to our system, we can use the hierarchical nature of Akka Actors to represent the relationships between power resources and their regions, as each Resource is represented by Resource Actor, which is, in turn, a child of a corresponding Region Actor.
回到我们的系统,我们可以使用Akka Actor的分层性质来表示电力资源与其区域之间的关系 ,因为每个Resource均由Resource Actor表示,而Resource Actor又是相应Region Actor的子代。
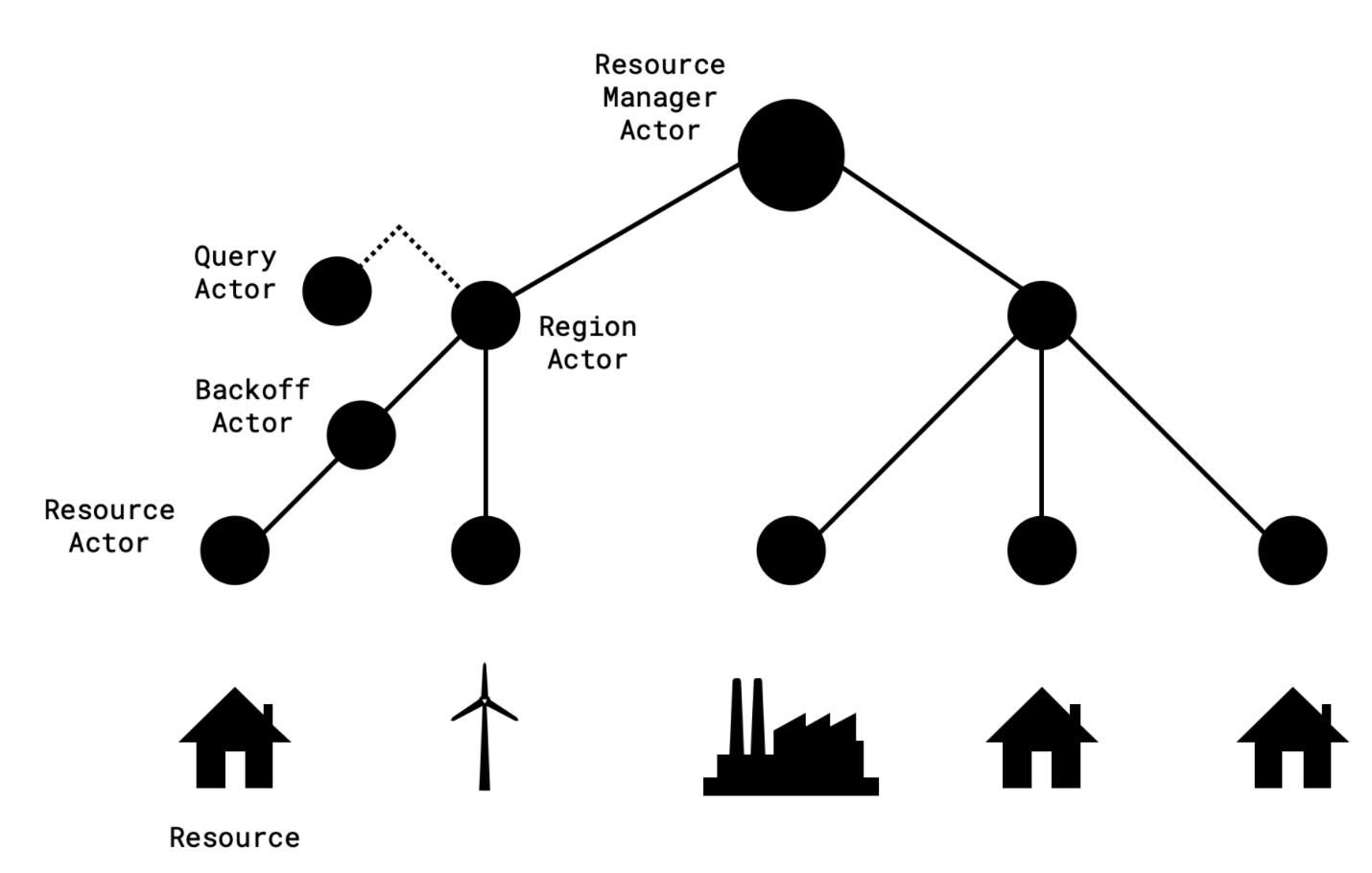
Having resources that are modeled as individual actors allows to isolates failures of one resource actor from the rest of the resources in its region, and increases the parallelism of collecting battery level reading. Similarly, representing each region as an individual actor allows us to isolates failures that occur within a region and to increases parallelism in the system, as regions can run concurrently and can be queried concurrently. To simplify the implementation even more and to enable further parallelism, we use a dedicated Actor to handle each Query request.
将资源建模为单独的参与者,可以将一个资源参与者的故障与该区域其他资源隔离开来,并提高收集电池电量读数的并行性。 类似地,将每个区域表示为单独的参与者可以使我们隔离区域内发生的故障并增加系统中的并行度,因为区域可以同时运行并且可以同时查询。 为了进一步简化实现并进一步实现并行性,我们使用专用的Actor来处理每个查询请求。
代表资源 (Representing a Resource)
Let’s start by implementing the most basic unit of the system — A Resource. Each connected Resource is represented by a specific Actor. A Resource Actor should be able to collect and report the Battery Level of it’s associated power resource. Therefore, the Resource Actor’s Write Protocol should consist of a RecordBatteryLevel and a ReadBatteryLevel messages, where the RecordBatteryLevel holds the Battery Level value that should be recorded, and the ReadBatteryLevel allow external entities (other actors) to request the last recorded battery level. Accordingly, the Resource Actor's Read Protocol should consist of a BatteryLevelRecorded and a RespondBatteryLevel messages, where the BatteryLevelRecorded indicates to senders that their request has reached its destination, and the RespondBatteryLevel holds the returned Battery reading. The protocol can be expressed as follows:
让我们首先实现系统的最基本单元-资源。 每个连接的资源由一个特定的Actor代表。 资源参与者应该能够收集和报告其相关电源的电池电量。 因此,资源RecordBatteryLevel的写协议应由RecordBatteryLevel和ReadBatteryLevel消息组成,其中RecordBatteryLevel包含应记录的电池电量值,而ReadBatteryLevel允许外部实体(其他参与者)请求最后记录的电池电量。 因此,资源RespondBatteryLevel的读取协议应包含BatteryLevelRecorded和RespondBatteryLevel消息,其中BatteryLevelRecorded向发送方指示其请求已到达其目的地,并且RespondBatteryLevel保留返回的Battery读数。 该协议可以表示如下:
In the above, the Resource Actor properties include a regionId and a resourceId which identifies the resource and its associated region. The Actor receives also a socket endpoint through which it receives a stream of telemetry data.
另外,在上述中, Resource演员属性包括regionId和resourceId其标识资源和其相关联的区域。 Actor还接收一个套接字endpoint通过它它接收遥测数据流。
It is worth mentioning the requestId argument. A Query Actor is expected to send queries to multiple Resource Actors which belong to its associated region. Since the Resource Actors' response time is arbitrary, it is important to correlate requests and responses, in the sense that the sender could match the incoming values with their associated outgoing requests.
值得一提的是requestId参数。 期望查询参与者将查询发送到属于其关联区域的多个资源参与者。 由于资源参与者的响应时间是任意的,因此在发送方可以将传入值与其关联的传出请求进行匹配的意义上,将请求和响应关联起来非常重要。
We implement the Resource Actor as follows:
我们实现Resource角色的方法如下:
The connected webSocket is expected to send RecordBatteryLevel messages to the Resource Actor, and, as a response, the Resource Actor would replay with a BatteryLevelRecorded message. Upon a ReadBatteryLevel request, the Actor will return a RespondBatteryLevel message containing the last battery reading, which is stored in the lastBatteryLevelReading variable.
连接的webSocket有望将RecordBatteryLevel消息发送给Resource Actor,作为响应, Resource Actor将使用BatteryLevelRecorded消息进行重放。 根据ReadBatteryLevel请求,Actor将返回一个RespondBatteryLevel消息,其中包含最近一次电池读数,该消息存储在lastBatteryLevelReading变量中。
代表地区 (Representing a Region)
As mentioned, a Region Actor represents a geographical region of resources. Upon requests, this actor should register a given resource by creating a corresponding Resource Actor. It should also track which Resource Actors exist in the region and removing them from the region when they are stopped. Finally, it should handle incoming query requests.
如前所述,区域参与者代表资源的地理区域。 根据请求,此参与者应通过创建相应的资源参与者来注册给定资源 。 它还应跟踪该区域中存在哪些资源参与者,并在它们停止时将其从该区域中删除。 最后,它应该处理传入的查询请求。
In the above, we describe the Region Actor’s protocol. The RequestResourcesList and RequestAllBatteryLevels messages are used to query the Region actor for its list of connected resources and their last reported battery levels, accordingly. The battery level value is represented by BatteryLevelReading.
在上面,我们描述了Region Actor的协议。 RequestResourcesList和RequestAllBatteryLevels消息分别用于查询Region actor的连接资源列表及其上次报告的电池电量。 电池电量值由BatteryLevelReading表示。
An important consideration here is that each resource is represented by an actor that can stop during the lifecycle of the query, due to a disconnection or failure of some sort, and that new Resource Actor might join the group during the lifecycle of the query. The most simple approach to handle this dynamic nature of resources is to ignore any actor that joined after the query has begun, and if a handled actor stops during the query, we will treat the failure as BatteryLevelNotAvailable or a ResourceNotAvailable.
这里一个重要的考虑因素是,每个资源都由一个actor表示,由于某种断开或失败,actor可以在查询的生命周期内停止,并且新的Resource Actor可以在查询的生命周期内加入该组。 处理资源这种动态性质的最简单方法是忽略在查询开始后加入的任何actor,如果已处理的actor在查询期间停止,则将失败视为BatteryLevelNotAvailable或ResourceNotAvailable 。
Another consideration is that Resource Actors might take a very long time to answer or be trapped in an infinite loop. To cover such a scenario, we should define a timeout for each query and a ResourceTimedOut response.
另一个考虑因素是资源参与者可能需要很长时间才能回答或陷入无限循环。 为了解决这种情况,我们应该为每个查询定义一个超时以及一个ResourceTimedOut响应。
Next, we implement the Region actor:
接下来,我们实现Region角色:
In the above, the Region actor reacts to RequestTrackResource messages by either returning the associated Resource Actor or by registering a new resource, depending on whether the resource is already registered in this region. For this purpose, we use a simple mapping resourceIdToActor between Resource identifiers and their matching Actors. The createRegionQuery method is used to query the Region Actor, and the createResource method is used to create a new Resource Actor when necessary.
在上面, Region actor通过返回关联的Resource Actor或通过注册新资源来RequestTrackResource消息,具体取决于该资源是否已在该区域中注册。 为此,我们在资源标识符及其匹配的Actor之间使用简单的映射resourceIdToActor 。 createRegionQuery方法用于查询Region Actor,必要时, createResource方法用于创建新的Resource Actor。
添加退避层 (Adding a backoff layer)
We implement the createResource helper method as follows:
我们实现了createResource helper方法,如下所示:
Instead of creating the Resource Actor as a direct child of the Region Actor, we add an additional backoff layer. This is a common supervision pattern — the supervisor delegates tasks to subordinates and therefore must respond to their failures. When a subordinate detects a failure (i.e. throws an exception), it suspends itself and all its subordinates and sends a message to its supervisor, signaling failure. here, we create a backoff supervisor which will start the given Resource actor after it has crashed due to some exception, in increasing time intervals. We also add a 20% “noise” to vary the intervals slightly.
我们没有添加Resource Actor作为Region Actor的直接子级,而是添加了额外的退避层。 这是一种常见的监督模式 -主管将任务委托给下属,因此必须对他们的失败做出响应。 当下属检测到故障(即引发异常)时,它会挂起自身及其所有下属,并向其主管发送消息,以信号通知故障。 在这里,我们创建了一个退避监管程序,它将在给定的Resource actor因某些异常而崩溃后启动它,并以增加的时间间隔启动。 我们还添加了20%的“噪声”以稍微改变间隔。
查询Region Actor (Querying the Region Actor)
It is time to implement the createRegionQuery call, which allows us to retrieve all available battery readings which relate to that region.
现在该实现createRegionQuery调用了,它使我们能够检索与该区域有关的所有可用电池读数。
As mentioned earlier, upon an incoming query, we would like to snapshot the currently registered Resource actors and to handle them while ignoring any additional actor that joins the group during the query lifecycle. A naive approach would be to handle the query as part of the Region Actor. With this approach, and since new queries may arrive before the previous query has ended, we would have to handle separate snapshots of actors to support those different queries. This is exactly a situation in which it is better to split the Actor to more dedicated actors, where each newly created actor is responsible to handle an incoming query. In that way, we dramatically simplify the implementation, reduce dependencies, and increase parallelism.
如前所述,在传入查询时,我们想快照当前注册的Resource actor并对其进行处理,而忽略在查询生命周期中加入该组的任何其他actor。 天真的方法是将查询作为Region Actor的一部分进行处理。 使用这种方法,由于新查询可能在前一个查询结束之前到达,因此我们将不得不处理参与者的不同快照以支持这些不同的查询。 正是在这种情况下,最好将Actor拆分为更多专用的actor ,其中每个新创建的actor负责处理传入的查询。 这样,我们可以极大地简化实现,减少依赖关系并提高并行度。
In the above, calling the createRegionQuery creates a new RegionQuery Actor, which is responsible for executing the query. To support the snapshotting approach, we pass down the actorToResourceId as a snapshot of registered Resource Actors. Similarly to before, we also pass down the requestId in order to match requests with results. Next, we pass down a reference to the associated Region Actor, in order to allow the communication between the Query Actor to the Region Actor, and a pre-defined time limit to handle any timeout scenarios.
在上面,调用createRegionQuery创建一个新的RegionQuery Actor,负责执行查询。 为了支持快照方法,我们将actorToResourceId传递为已注册Resource Actor的快照。 与之前类似,我们还传递了requestId ,以使请求与results匹配 。 接下来,我们向下传递对关联的Region Actor的引用,以允许Query Actor与Region Actor之间的通信,以及用于处理任何超时情况的预定义时间限制。
查询演员 (The Query Actor)
Finally, we can implement the RegionQuery Actor, which is created by a Region Actor upon an incoming query request and is responsible for collecting the battery readings of all associated actors. In correlation to the previous section, we define the RegionQuery Actor properties:
最后,我们可以实现RegionQuery Actor,该RegionQuery Actor由Region Actor根据传入的查询请求创建,并负责收集所有相关Actor的电池读数。 与上一节相关,我们定义了RegionQuery Actor属性:
Next, we define the Actor. Once a Region Query Actor has been created, we wish it to send a ReadBatteryLevel message to each Resource Actor in the snapshot. This can be done using the Actor's life-cycle hook preStart, which allows us to run certain logic before the Actor starts.
接下来,我们定义Actor。 一旦创建了区域查询ReadBatteryLevel ,我们希望它向快照中的每个资源ReadBatteryLevel发送ReadBatteryLevel消息。 这可以使用Actor的生命周期挂钩preStart来完成,它允许我们在Actor启动之前运行某些逻辑 。
The above actor responds to RespondBatteryLevel messages arriving from various Resource Actors. In order to address any timeout issues, we use the scheduler to schedule a message that will be sent after a given delay. The Timeout message will be sent by the RegionQuery to itself. Therefore, we define the waitingForReplies call as follows:
上面的RespondBatteryLevel响应来自各种资源参与者的RespondBatteryLevel消息。 为了解决任何超时问题,我们使用scheduler来调度将在给定延迟后发送的消息。 超时消息将由RegionQuery发送给自己。 因此,我们按以下方式定义waitingForReplies调用:
In the above, upon an incoming RespondBatteryLevel message arriving from a Resource Actor, we add the incoming result to the results collection, as follows:
在上面,从Resource Actor收到传入的RespondBatteryLevel消息后,我们将传入的结果添加到结果集合中,如下所示:
For each incoming response, we check whether all Actors have replied back. In case that some actors haven’t responded yet, we continue to wait for the next response, otherwise, we send the results via the RespondAllBatteryLevels back to the Region Actor. This is done by using the context.become and context.stop which allows us to treat the Actor as a State Machine.
对于每个收到的回复,我们检查是否所有演员都已回复。 如果某些参与者尚未响应,我们将继续等待下一个响应,否则,我们将结果通过RespondAllBatteryLevels发送回地区参与者。 这是通过使用context.become和context.stop来完成的,它允许我们将Actor视为状态机 。
一位演员来统治他们 (One Actor to rule them all)
We create the ResourceManager Actor, which receives requests to track a Resource within a specific Region:
我们创建ResourceManager Actor,该Actor接收跟踪特定区域内资源的请求:
The ResourceManager Actor can be implemented as follows:
ResourceManager Actor可以按以下方式实现:
Similarly to the RegionActor, the ResourceManager maintains the list of various regions. Upon an incoming RequestTrackResource message, it passes down the message to the Region Actor. In case that the Region does not exist yet, it creates a new Region Actor.
与RegionActor , ResourceManager维护各个区域的列表。 在收到RequestTrackResource消息后,它将消息传递到Region Actor。 如果Region尚不存在,它将创建一个新的Region Actor。
This is it! We have implemented the Actors tree necessary to represent the relationship between Power Resources and their Regions. Let’s expose a simple REST API to allow other services to interact with the system.
就是这个! 我们已经实现了代表电力资源及其区域之间关系的Actor树。 让我们公开一个简单的REST API,以允许其他服务与系统进行交互。
公开REST API (Exposing a REST API)
With Akka, we can easily create an HTTP server to expose a REST API. The first endpoint to implement is the POST connect-resource which allows external services to register a new resource into the system. The request should hold the identifiers of the Resource and Region, and also the WebSocket's endpoint, through which the resource's telemetry data should be received.
使用Akka,我们可以轻松创建HTTP服务器以公开REST API。 要实现的第一个端点是POST connect-resource ,它允许外部服务将新资源注册到系统中。 该请求应包含资源和区域的标识符,以及WebSocket的端点,应通过该端点接收资源的遥测数据。
Upon a connect-resource request, we use the ask messaging pattern to send a RequestTrackResource message to the Resource Manager Actor:
收到connect-resource请求后,我们使用ask消息传递模式将RequestTrackResource消息发送给Resource Manager Actor:
The next endpoint to implement is the GET region-battery-levels which allows external services to query the latest battery readings of all resources connected to a given region.
下一个要实现的端点是GET region-battery-levels ,它允许外部服务查询连接到给定区域的所有资源的最新电池读数。
Upon a region-battery-levels request, we use the ask messaging pattern to send a RequestAllBatteryLevels message to the corresponding Region Actor. As before, we use system.actorOf to retrieve the associated Region Actor:
根据region-battery-levels请求,我们使用ask消息传递模式将RequestAllBatteryLevels消息发送给相应的Region Actor。 和以前一样,我们使用system.actorOf来检索关联的Region Actor:
Finally, we create the HTTP server with the above routes:
最后,我们使用上述路由创建HTTP服务器:
更进一步 (Take it further)
In the above, we have described a simple way to use the Actor Model and Akka in order to process IoT data in real-time, while discovering some of the fundamental ideas behind distributed processing. As a next step, we might want to increase parallelism by using Cluster Sharding — A core feature of Akka that allows distributing actors across several nodes in the cluster without having to care about their physical location in the cluster.
在上文中,我们描述了一种使用Actor模型和Akka以便实时处理IoT数据的简单方法,同时发现了分布式处理背后的一些基本思想。 下一步,我们可能想通过使用集群分片(Cluster Sharding)来提高并行度,这是Akka的一项核心功能,它允许将参与者分布在集群中的多个节点上,而不必关心它们在集群中的物理位置。
For the latest version and dark-mode, read it on my blog.
有关最新版本和暗模式, 请在我的博客上阅读 。
翻译自: https://medium.com/swlh/build-a-virtual-power-plant-with-akka-d60b5bf649cf
spark与akka




 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)