

深度学习 正则化 正则化率
介绍: (Introduction:)
The key role of Regularization in deep learning models is to reduce overfitting of data. It makes the network simple resulting in generalization on data points never encountered before. This helps in reducing the testing error when the model performs well only on the training set.
在深学习模式的制度化 吨他的关键作用是减少数据的过度拟合 。 它使网络变得简单,从而可以概括以前从未遇到过的数据点。 当模型仅在训练集上表现良好时,这有助于减少测试错误。
Before learning about regularization let’s understand briefly about different scenarios and where it can be helpful.
在学习正则化之前,让我们简要了解不同的场景以及在什么情况下会有所帮助。
确定错误原因: (Identifying causes of errors:)
A simple model might fail to perform well on the training data while complex models may succeed in fitting the training points close to the actual function. However, the ultimate goal of any model is to perform well on unseen data. The two main error causing scenarios are:
简单的模型可能无法在训练数据上很好地执行,而复杂的模型则可能成功地将训练点拟合为接近实际功能。 但是,任何模型的最终目标都是在看不见的数据上表现良好。 导致错误的两个主要情况是:
拟合不足: (Underfitting:)
A statistical model or an algorithm is said to have underfitted when it cannot capture the underlying trend of data. The model may be too simple or biased that it is not able to justify the data trend.
当统计模型或算法无法捕获数据的潜在趋势时,称该模型不合适。 该模型可能过于简单或带有偏见,无法证明数据趋势的合理性。
It usually happens when we try to build a linear model with a non-linear data. In such cases the rules of the deep learning model are too easy and will probably make a lot of wrong predictions.
当我们尝试使用非线性数据构建线性模型时,通常会发生这种情况。 在这种情况下,深度学习模型的规则过于简单,可能会做出很多错误的预测。
Therefore, Underfitting > High Bias and Low Variance.
因此,选择欠拟合> 高偏差和低方差 。
Techniques to reduce underfitting: 1. Increase model complexity 2. Increase number of features or perform feature engineering 3. Increase the duration of training
减少欠拟合的技术:1.增加模型复杂度; 2.增加特征数量或执行特征工程; 3.增加训练时间
过度拟合: (Overfitting:)
A statistical model or an algorithm is said to have overfitted when it starts learning from all the noise or inaccuracies possessed by the training data, in a way that even minute details are recorded.
当统计模型或算法开始从训练数据所具有的所有噪声或不准确性中学习时,据说统计模型或算法已经过拟合,从而记录了详细信息。
The causes of overfitting are generally non-parametric and non-linear methods because these types of algorithms have more flexibility to build the model based on the dataset and therefore sometimes build unrealistic models. As a result, they perform poorly on the testing data.
过度拟合的原因通常是非参数方法和非线性方法,因为这些类型的算法在基于数据集构建模型时具有更大的灵活性,因此有时会构建不切实际的模型。 结果,它们在测试数据上表现不佳。
Therefore, Overfitting > Low Bias and High variance.
因此, 过度拟合>低偏差和高方差。
Techniques to reduce overfitting: 1. Increase training data or perform data augmentation. 2. Reduce model complexity. 3. Early stopping during the training phase depending on loss. 4. Regularization
减少过度拟合的技术:1.增加训练数据或进行数据扩充。 2.降低模型复杂度。 3.根据损失,在训练阶段尽早停止。 4. 正则化
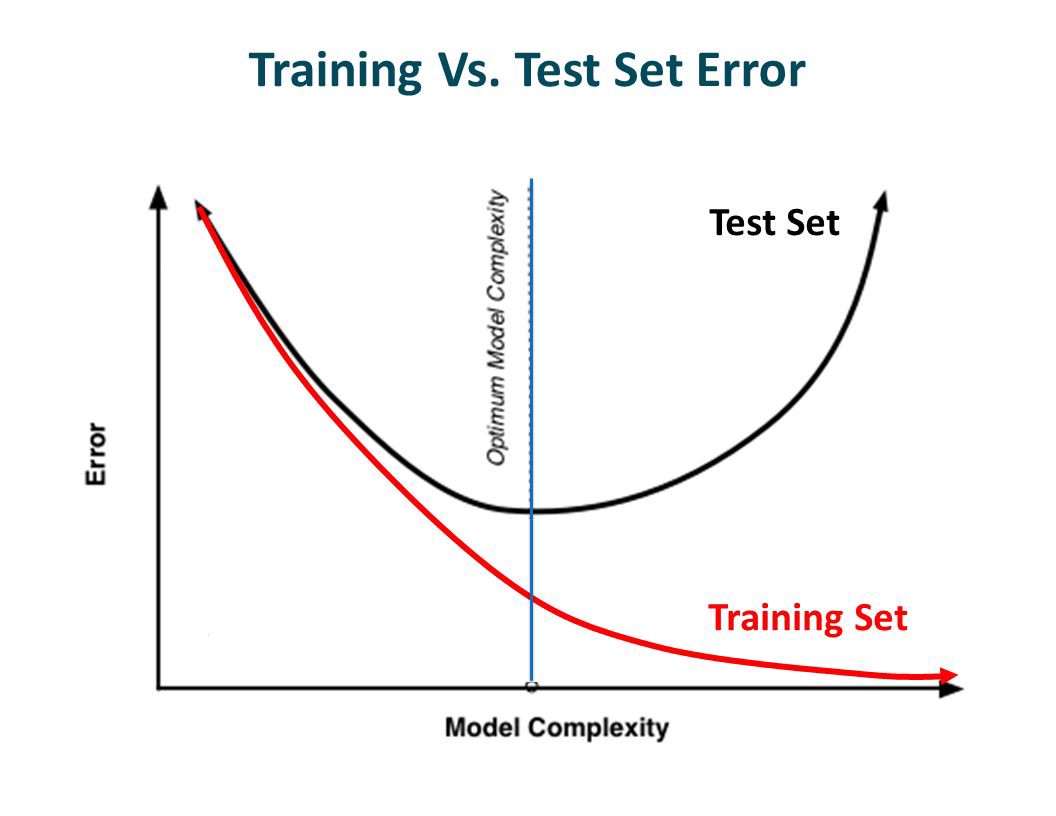
The above image shows conditions where underfitting, optimal(just-right) and overfitting occur. The goal is to train a model such that it results fall in the just-right scenario with bias-variance balance.
上图显示了发生欠拟合,最佳(恰好)和过度拟合的情况。 目的是训练模型,使其结果在偏差方差平衡恰到好处的情况下下降。
The key to any model training approach is to inspect the trends in training regularly to identify different bias-variance scenarios with the help of validation dataset.
任何模型训练方法的关键是定期检查训练趋势,并借助验证数据集来识别不同的偏差方差场景。
The following table summarizes the intuitions behind this.
下表总结了其背后的直觉。
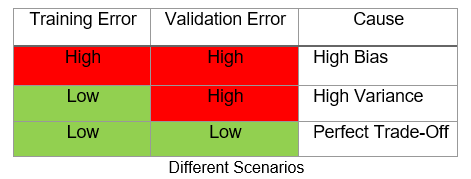
The ultimate objective of any model is to make training error small (reduces underfitting) while keeping the testing error close to it (reduces overfitting).
任何模型的最终目标都是使训练误差小(减少拟合不足),同时使测试误差接近(减少过度拟合)。
This requires appropriate selection of the algorithms and features to be used leading us to the Occam’s Razor Principle which states ‘among all the competing hypotheses that explain known hypothesis equally well, select the simplest one.’
这就需要适当选择要使用的算法和功能,从而使我们得出Occam的剃刀 原理 ,该原理指出“在所有能够很好地解释已知假设的竞争假设中,选择最简单的假设”。
In order to make the model better, we tend to over explore the features which can cause wrong fits and unsatisfying results in general. Rather, the focus should be on simplicity while exploring the features and algorithms.
为了使模型更好,我们倾向于过度研究可能导致错误拟合和不令人满意的结果的特征。 相反,在探索功能和算法时,重点应该放在简单性上 。
Since this blog focuses on regularization, if you would like to learn more about bias-variance tradeoff, I recommend you to go through this article.
由于此博客关注正则化,因此,如果您想了解有关偏差方差折衷的更多信息,建议您阅读本文 。
正则化如何减少过度拟合: (How Regularization reduces Overfitting:)
Since deep learning deals with highly complex models, it is easy for it to overfit the training data. Even when the model performs well on training data, the testing error can be quite large resulting in high variance.
由于深度学习处理高度复杂的模型,因此很容易过度拟合训练数据。 即使模型在训练数据上表现良好,测试误差也可能很大,导致高方差 。
Consider training a neural network with cost function J denoted as:
考虑使用成本函数J表示训练神经网络:
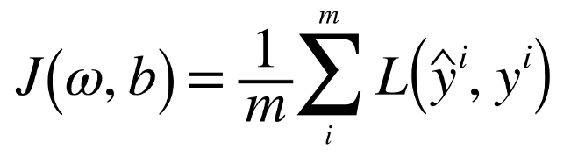
where w and b are weights and bias respectively.
其中w和b分别是权重和偏差。
y’ = predicted label
y'=预测标签
y = actual label
y =实际标签
m = number of training samples
m =训练样本数
We add a regularization term to this function so that it penalizes the weight matrices of nodes within the network.
我们向此函数添加一个正则化项,以便对网络内节点的权重矩阵进行惩罚。
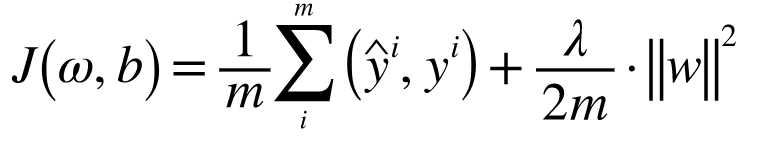
where, λ = regularization coefficient
λ=正则化系数
Update of weight w for each layer:
每层重量w的更新:

In this way, regularization term is used to make some of the weight matrices nearly equal to zero to reduce their impact. As a result, the network will be much simpler and chances of overfitting the training data reduce since, different nodes are suppressed while training. The coefficient λ needs to optimized according to the performance on validation set to obtain a well-fitted model.
以这种方式,使用正则项来使一些权重矩阵几乎等于零,以减少其影响。 结果,网络将变得更加简单,并且由于在训练时会抑制不同的节点,因此减少了过度拟合训练数据的机会。 需要根据验证集上的性能对系数λ进行优化,以获得一个拟合模型。
Another intuition lies in the activation function of output layer of a network. Since the weights tend to be smaller because of regularization, the function z is given by:
另一个直觉在于激活功能 网络的输出层。 由于权重由于正则化而趋于变小,因此函数z由下式给出:
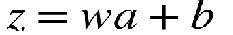
where a is the activation from the last layer.
其中a是来自最后一层的激活。
Hence, z also becomes small. Thus, any activation function like sigmoid(z) or tanh(z) has better chances of capturing values within its linear range. This results in a comparatively linear behaviour of the then complex function reducing the overfitting.
因此,z也变小。 因此,任何激活函数(如sigmoid(z)或tanh(z))都有更好的机会捕获其线性范围内的值。 这导致了当时复杂函数的相对线性行为,从而减少了过拟合。
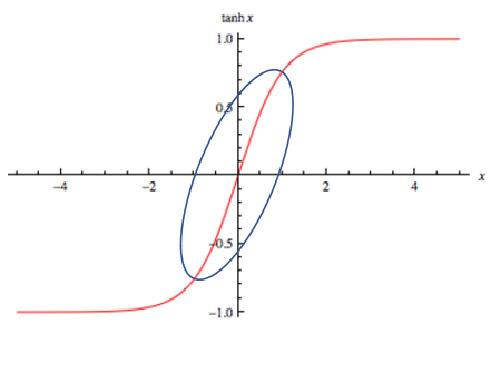
An example of tanh(z) function is shown below.
tanh(z)函数的示例如下所示。
常见的正则化技术: (Common Regularization Techniques:)
Now that we know how regularization is helpful to reduce overfitting, let us understand about the most common and effective practices.
既然我们知道正则化如何有助于减少过度拟合,那么让我们了解最常见和最有效的做法。
1. L1和L2正则化: (1. L1 and L2 Regularization:)
When we have a large number of features, the tendency of the model to overfit along with computational complexities can increase.
当我们具有大量特征时,模型过度拟合的趋势以及计算复杂性会增加。
Two powerful techniques called Ridge (performs L2 regularization) and Lasso (performs L1 regularization) regression are performed to bring down the Cost function.
执行了两种强大的技术,称为Ridge(执行L2正则化)和Lasso(执行L1正则化)回归,以降低Cost函数。
a) Ridge Regression for L2 Regularization: It penalize the variables if they are found to be too far from zero. Thus, decreasing model complexity while keeping all variables in the model.
a)用于L2正则化的Ridge回归:如果发现变量离零太远,则会对变量进行惩罚。 因此,在降低模型复杂度的同时将所有变量保留在模型中。
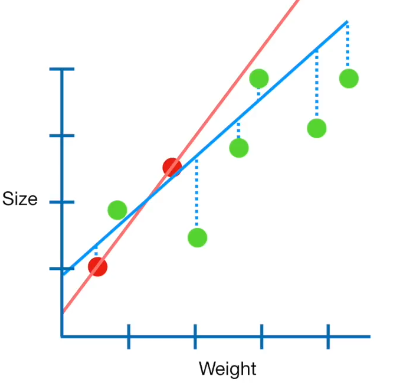
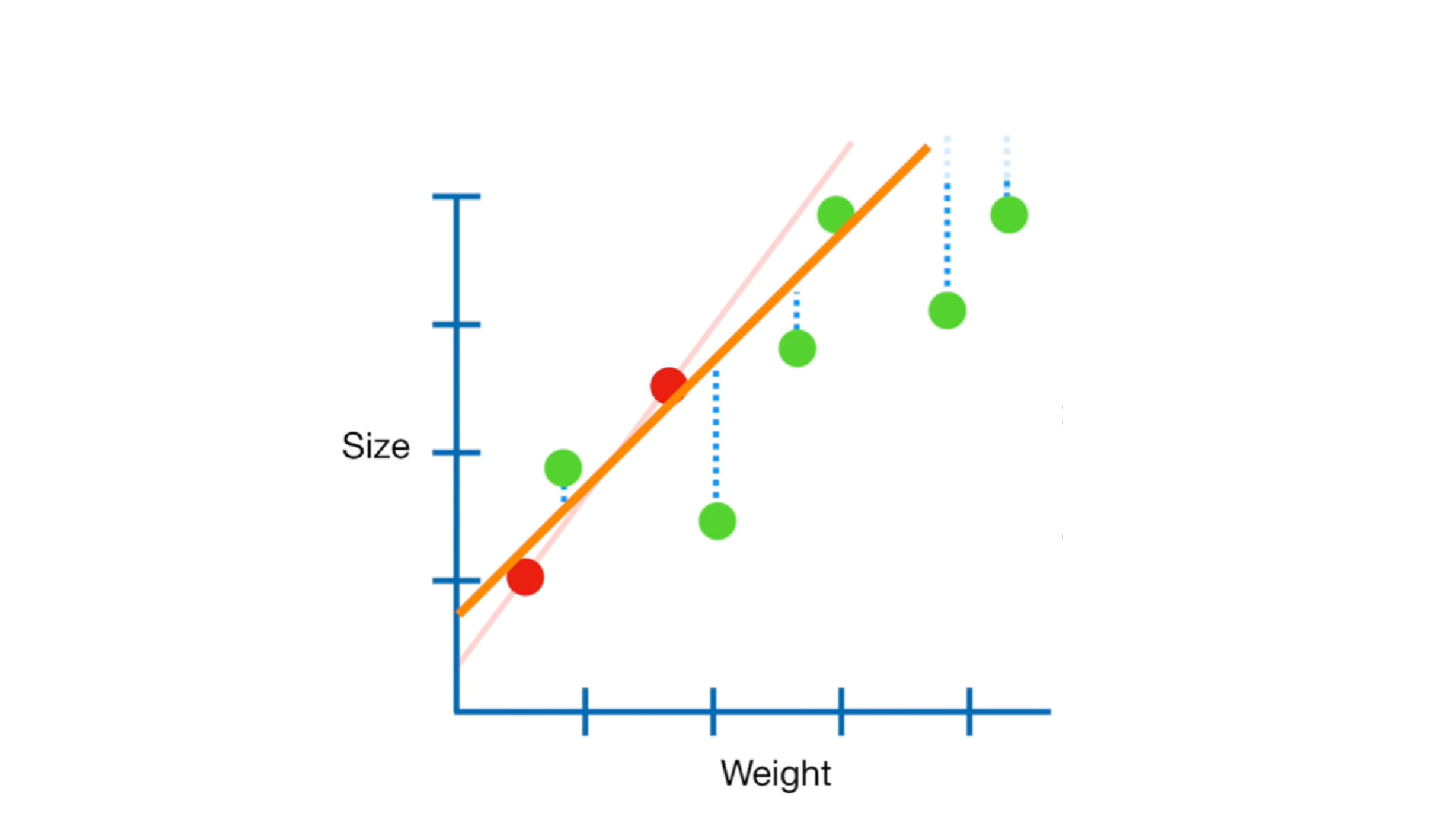
The red points in the above image correspond to the training set. The model represented by red curve fits these points but it is clear that the testing data (green points) will not perform very well.
上图中的红点对应于训练集。 用红色曲线表示的模型适合这些点,但是很明显测试数据(绿色点)的性能不是很好。
So, Ridge regression helps in finding the optimum model tat reduces overfitting on training set represented by the blue curve by introducing bias.
因此,Ridge回归有助于找到最佳模型tat,从而通过引入偏差减少蓝色曲线表示的训练集的过度拟合。
This bias is known as the ridge regression penalty = (λ * slope²)
这种偏差称为脊回归罚分=(λ*斜率²)
The slope² contains all the input intercepts squared and added, excluding just the y (output) intercept.
斜率²包含所有输入截距的平方和加和,仅包括y(输出)截距。
b) Lasso Regression (Least Absolute Shrinkage and Selection Operator) for L1 Regularization: Previously, in ridge regression the bias was increased in order to decrease the variance using slope squares.
b) 用于L1正则化的 套索回归(最小绝对收缩和选择算子 ) :以前,在山脊回归中增加了偏差以使用斜率平方减小方差。
In Lasso regression we add an absolute value of slope, |slope| instead of slope squares to introduce a little amount of bias represented by orange curve in the below image. This bias improves over training time.
在套索回归中,我们添加斜率的绝对值| slope | 而不是斜率正方形会在下图中引入少量由橙色曲线表示的偏差。 随着训练时间的推移,这种偏见有所改善。
Therefore, lasso regression penalty = (λ * |slope|)
因此,套索回归惩罚=(λ* | slope |)
深度学习中的实现公式: (Equations for implementation in deep learning:)
>L2 regularization uses the regularization term as discussed above to penalize the weights of complex models. In simple terms the equation for cost function becomes:
> L2 正则化使用上面讨论的正则化项来惩罚复杂模型的权重。 简单来说,成本函数的等式变为:
成本函数=成本(来自y和y')+正则项, (Cost function = Cost(from y and y’) + Regularization term,)

λ = Regularization coefficient
λ=正则化系数
m = number of training samples and,
m =训练样本数,并且
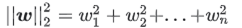
>For L1 regularization the only difference is that the regularization term contains λ/m instead of (λ/2)*m. Therefore, the cost function for L1 is:
>对于L1正则化 ,唯一的区别是正则化项包含λ/ m而不是(λ/ 2)* m。 因此,L1的成本函数为:

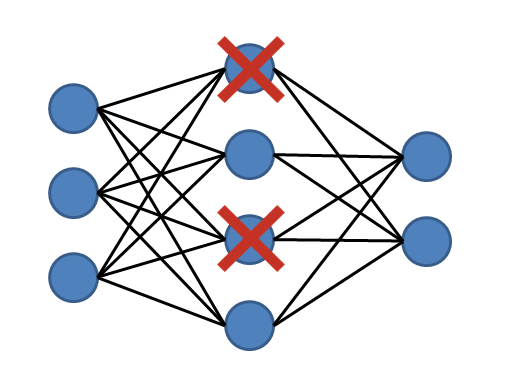
2.辍学正则化: (2. Dropout Regularization:)
This is the most intuitive regularization technique and is frequently used. At every iteration, some nodes are dropped randomly valid only for that particular iteration. A new (random) set of nodes is dropped for the upcoming iteration.
这是最直观的正则化技术,并且经常使用。 在每次迭代中,一些节点被随机丢弃,仅对该特定迭代有效。 为即将到来的迭代删除了一组新的(随机)节点。
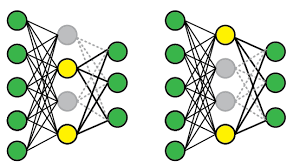
So, in this way every iteration uses different set of nodes so that the network produced is random and does not overfit the original complex structure. Bacause any feature in the network can be dropped at random, model is never heavily influenced by a particular feature thus reducing overfitting.
因此,通过这种方式,每次迭代都使用不同的节点集,因此生成的网络是随机的,不会过度适应原始的复杂结构。 由于网络中的任何特征都可以随意删除,因此模型永远不会受到特定特征的严重影响,从而减少了过拟合。
The number of nodes to be eliminated is decided by assigning keep-probabilities separately for each hidden layer of the network. Thus, we can control the effect produced by each and every layer on the network.
通过为网络的每个隐藏层 分别分配保持概率,可以确定要消除的节点数。 因此,我们可以控制网络上每一层所产生的效果。
In conclusion, regularization is an important technique in deep learning. With sufficient knowledge of overfitting scenarios and regularization implementation, the results improve to a great extend.
总之,正则化是深度学习中的一项重要技术。 有了对过度拟合场景和正则化实现的足够了解,结果可以得到很大程度的改善。
翻译自: https://medium.com/snu-ai/when-and-how-to-use-regularization-in-deep-learning-4cf3fca3950f
深度学习 正则化 正则化率




 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)