

Overfitting is an issue that occurs when a model shows high accuracy in predicting training data (the data used to build the model), but low accuracy in predicting test data (unseen data that the model has not used before).
当模型在预测训练数据(用于构建模型的数据)中显示出较高的准确性,但在预测测试数据(模型之前未使用的未知数据)中显示出低准确性时,就会发生过拟合问题。
This can particularly be a problem when it comes to using small datasets in the course of building a neural network. It is possible for the neural network to be of such a size that it “overtrains” on the training data — and therefore performs poorly when it comes to predicting new data.
当在构建神经网络的过程中使用小型数据集时,这尤其可能成为一个问题。 神经网络的大小可能使它在训练数据上“过度训练”,因此在预测新数据时表现不佳。
辍学在规范化神经网络中的作用 (Role of Dropout in Regularizing Neural Networks)
At its most basic, Dropout literally “drops-out” certain neurons from the neural network. This is to prevent excessive “noise” in the network that artificially increases the training accuracy, but does not result in any meaningful information being transferred to the output layer — i.e. any increase in the training accuracy comes from excessive training and not from any useful information from the model features themselves.
从最基本的角度讲,Dropout实际上是从神经网络中“丢弃”某些神经元。 这是为了防止网络中过分的“噪声”人为地提高训练精度,但不会导致任何有意义的信息被传输到输出层,即,训练精度的任何提高都来自过度的训练,而不是来自任何有用的信息从模型特征本身。
Dropout renders certain nodes in the network inactive as illustrated in the image at the beginning of this article — thus forcing the network to look for more meaningful patterns that influence the output layer.
如本文开头的图像所示,Dropout使网络中的某些节点处于非活动状态 -从而迫使网络寻找影响输出层的更有意义的模式。
While Dropout can technically be used in both the input and hidden layers — it is most common to use Dropout across the hidden layers, as using it on the input layer still risks discarding important information.
尽管从技术上讲可以在输入层和隐藏层中都使用Dropout,但最常见的是在隐藏层中使用Dropout,因为在输入层上使用Dropout仍然有丢弃重要信息的风险。
预测酒店的平均每日房价:基于回归的神经网络 (Predicting Average Daily Rates For Hotels: Regression-Based Neural Network)
To investigate the effectiveness of Dropout in predicting the output layer, let’s use a regression-based neural network to predict ADR (average daily rates) for customers at a hotel.
为了研究Dropout在预测输出层中的有效性,我们使用基于回归的神经网络来预测酒店客户的ADR(平均每日房价) 。
The original research by Antonio, Almeida, and Nunes (2016) is available in the References section below.
Antonio,Almeida和Nunes(2016)的原始研究可在下面的参考部分中找到。
The following features are used to predict ADR:
以下功能用于预测ADR:
- IsCanceled (whether the customer cancels their booking or not) IsCanceled(客户是否取消预订)
- Country of Origin 出生国家
- Market Segment 细分市场
- Deposit Type 存款类型
- Customer Type 客户类型
- Required Car Parking Spaces 所需停车位
- Week of Arrival (Week Number) 到达星期(星期数)
数据集 (Datasets)
Let’s consider two training datasets.
让我们考虑两个训练数据集。
Dataset 1 is the original dataset with 40,060 observations. Dataset 2 is a smaller version of the original with 100 observations.
数据集1是具有40,060个观测值的原始数据集。 数据集2是原始版本的较小版本,具有100个观测值。
A regression-based neural network model is built on each in order to predict ADR values across the test set (a separate dataset). The datasets and code for this example are available in the references section below.
基于回归的神经网络模型建立在每个模型上,以便预测整个测试集(单独的数据集)的ADR值。 该示例的数据集和代码可在下面的参考部分中找到。
无辍学的神经网络 (Neural Networks without Dropout)
数据集1-模型配置 (Dataset 1 — Model Configuration)
-
8 input layers are used in the network
网络中使用了8个输入层
-
ELU is used as the activation function.
ELU用作激活功能。
- A linear output layer is used. 使用线性输出层。
-
1,669 hidden nodes are used in the hidden layer.
在隐藏层中使用了1,669个隐藏节点。
The number of hidden nodes in the layer are determined as follows:
该层中的隐藏节点数确定如下:

With 30,045 samples in our training set (after partitioning Dataset 1 into training and validation portions), a chosen factor of 2, as well as 8 input neurons and 1 output neuron — this gives 1,669 hidden nodes.
在我们的训练集中有30,045个样本(将数据集1划分为训练和验证部分之后),2的选择因子以及8个输入神经元和1个输出神经元-这提供了1,669个隐藏节点。
Here is the structure of the neural network:
这是神经网络的结构:

Using 30 epochs, a batch size of 150, and a validation split of 20%, the model is trained.
使用30个纪元,批量大小为150个 ,验证拆分为20%来训练模型。
Here is the training and validation loss:
这是训练和验证损失:
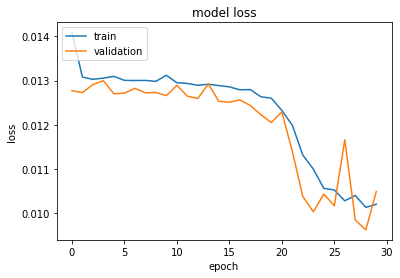
When the predictions are compared to the test set, the following errors are obtained:
将预测结果与测试集进行比较时,将获得以下误差:
-
Mean Absolute Error: 29.89
平均绝对误差: 29.89
-
Root Mean Squared Error: 43.91
均方根误差: 43.91
数据集2-模型配置 (Dataset 2 — Model Configuration)
Using the condensed dataset with only 100 observations, let us now see what the errors look like when using a much smaller dataset.
使用仅包含100个观测值的压缩数据集,现在让我们看一下使用小得多的数据集时的错误情况。
The overall configuration of the network remains the same — but this time a hidden layer with 5 nodes is used — as a dense layer of 1,669 nodes would almost certainly lead to overfitting with such a small training set.
网络的总体配置保持不变-但这次使用具有5个节点的隐藏层-因为1669个节点的密集层几乎可以肯定会导致采用如此小的训练集的过拟合。
The network configuration is as follows:
网络配置如下:

The errors obtained on the test set are as follows:
在测试集上获得的错误如下:
-
Mean Absolute Error: 39.08
平均绝对错误: 39.08
-
Root Mean Squared Error: 53.59
均方根误差: 53.59
Clearly, there has been an increase in errors when training on a smaller dataset, which indicates that the model is not performing as well on unseen data. Let’s see what happens when Dropout is introduced.
显然,在较小的数据集上进行训练时,错误增加了,这表明模型在看不见的数据上表现不佳。 让我们看看引入Dropout时会发生什么。
具有辍学的神经网络 (Neural Networks with Dropout)
The same neural network as above is run, but this time using 20% Dropout. In other words, a 20% probability that nodes in the hidden layer will be dropped in order to prevent overfitting.
运行与上面相同的神经网络,但是这次使用20%的 Dropout。 换句话说,隐藏层中的节点将丢失20%的概率,以防止过度拟合。

The results obtained are as follows:
获得的结果如下:
-
Mean Absolute Error: 39.96
平均绝对错误: 39.96
-
Root Mean Squared Error: 54.83
均方根误差: 54.83
We see that this has not had the desired effect of improving accuracy on the test set, and the errors have in fact risen slightly.
我们看到,这并没有达到改善测试集准确性的预期效果,并且误差实际上有所增加。
Let’s try 40% Dropout.
让我们尝试40%辍学率。
-
Mean Absolute Error: 41.97
平均绝对误差: 41.97
-
Root Mean Squared Error: 57.23
均方根误差: 57.23
Again, the errors have increased substantially. This indicates that instead of reducing overfitting — Dropout is eliminating valuable information from the neural network instead which is resulting in lower prediction accuracy.
再次,错误已大大增加。 这表明,与其减少过度拟合,不如说是Dropout从神经网络中消除了有价值的信息,这导致较低的预测准确性。
增加隐藏层 (Increasing Hidden Layers)
Instead of using Dropout, what if two hidden layers (5 nodes each) are used instead of one?
如果不使用Dropout,而是使用两个隐藏层(每个5个节点)而不是一个隐藏层怎么办?
Here is the updated model configuration:
这是更新的模型配置:

Under this configuration, the reported errors have decreased considerably — on par with those seen when the larger dataset was used:
在这种配置下,报告的错误已大大减少-与使用较大数据集时看到的错误相当:
-
Mean Absolute Error: 29.06
平均绝对错误: 29.06
-
Root Mean Squared Error: 43.42
均方根误差: 43.42
选择正确的功能后,丢包会变得多余 (With Proper Feature Selection, Dropout Can Become Redundant)
Why has Dropout not worked as we intended in this case?
为什么在这种情况下Dropout无法按预期工作?
One important thing to remember about this neural network is that the features for the input layer were selected before fitting the neural network.
关于该神经网络要记住的重要一件事是, 在拟合神经网络之前选择了输入层的特征。
This was done using feature selection tools such as the ExtraTreesClassifier and forward and backward feature selection — as well as manually determining if the included features make theoretical sense in predicting ADR values.
这是通过使用功能选择工具(例如ExtraTreesClassifier和向前和向后的功能选择 )以及手动确定所包含的功能在预测ADR值上是否具有理论意义来完成的。
In this regard, one can make the argument that with proper feature selection — Dropout serves little purpose and instead may simply result in eliminating valuable information from the network.
在这方面,人们可以提出这样的论点:选择适当的功能-辍学没有多大作用,而可能只是导致从网络中消除有价值的信息。
In this case, adding another hidden layer to the smaller network appears to have been sufficient in accounting for the additional variation in the output layer.
在这种情况下,将另一个隐藏层添加到较小的网络似乎足以解决输出层中的其他变化。
While Dropout can be of use if there are many irrelevant features in the input layer — proper feature selection in the first instance would mean that inducing Dropout in a neural network becomes unnecessary.
尽管在输入层中有许多不相关的特征时可以使用Dropout,但首先选择适当的特征将意味着无需在神经网络中引入Dropout。
结论 (Conclusion)
As we have seen, Dropout did not have the desired effect in improving test accuracy — even in the case of a smaller dataset.
如我们所见,即使在数据集较小的情况下,Dropout在提高测试准确性方面也没有达到预期的效果。
From this standpoint, proper feature selection prior to building a neural network will in most cases prove superior to arbitrarily applying Dropout in order to reduce overfitting. As with any model — ensuring that the variables in such a model make theoretical sense will often produce better results.
从这个角度来看,在大多数情况下,在构建神经网络之前进行适当的特征选择将优于为减少过度拟合而任意应用Dropout的优势。 与任何模型一样,确保此类模型中的变量具有理论意义,通常会产生更好的结果。
Many thanks for your time, and grateful for any comments or feedback. The code and datasets for this example is available in the MGCodesandStats GitHub repository as referenced below.
非常感谢您的宝贵时间,并感谢您提出任何意见或反馈。 MGCodesandStats GitHub存储库中提供了此示例的代码和数据集,如下所示。
Disclaimer: This article is written on an “as is” basis and without warranty. It was written with the intention of providing an overview of data science concepts, and should not be interpreted as professional advice in any way.
免责声明:本文按“原样”撰写,不作任何担保。 它旨在提供数据科学概念的概述,并且不应以任何方式解释为专业建议。
翻译自: https://towardsdatascience.com/using-dropout-with-neural-networks-not-a-magic-bullet-2fc3e4b17898




 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)