

神经网络优化器的选择
When constructing a neural network, there are several optimizers available in the Keras API in order to do so.
在构造神经网络时,Keras API中提供了多个优化器来实现。
An optimizer is used to minimise the loss of a network by appropriately modifying the weights and learning rate.
优化器用于通过适当修改权重和学习率来最小化网络的损失。
For regression-based problems (where the response variable is in numerical format), the most frequently encountered optimizer is the Adam optimizer, which uses a stochastic gradient descent method that estimates first-order and second-order moments.
对于基于回归的问题(响应变量为数字格式),最常遇到的优化器是Adam优化器,它使用一种随机梯度下降方法来估算一阶和二阶矩。
The available optimizers in the Keras API are as follows:
Keras API中可用的优化器如下:
- SGD 新元
- RMSprop RMSprop
- Adam 亚当
- Adadelta 阿达达
- Adagrad 阿达格勒
- Adamax 阿达玛克斯
- Nadam 那达姆
- Ftrl Ftrl
The purpose of choosing the most suitable optimiser is not necessarily to achieve the highest accuracy per se — but rather to minimise the training required by the neural network to achieve a given level of accuracy. After all, it is much more efficient if a neural network can be trained to achieve a certain level of accuracy after 10 epochs than after 50, for instance.
选择最合适的优化器的目的不一定是要获得最高的准确性,而是要使神经网络为达到给定的准确性而所需的训练降至最低。 毕竟,如果可以训练一个神经网络在10个纪元之后达到一定水平的准确度,比50个纪要高得多。
预测酒店的平均每日房价 (Predicting Average Daily Rates for Hotels)
Let’s illustrate this using an example: predicting average daily rates (ADR) for hotels. This is the output variable.
让我们用一个例子来说明这一点:预测酒店的平均每日房价(ADR) 。 这是输出变量。
The features used in the model are as follows:
模型中使用的功能如下:
1. Cancellations: Whether a customer cancels their booking
1.取消:客户是否取消预订
2. Country of Origin
2.原产国
3. Market Segment
3.市场细分
4. Deposit Paid
4.已付定金
5. Customer Type
5.客户类型
6. Required Car Parking Spaces
6.所需的停车位
7. Arrival Date: Week Number
7.到达日期:周号
This analysis is based on the original study by Antonio, Almeida and Nunes (2016) as cited in the References section below.
该分析基于Antonio,Almeida和Nunes(2016)的原始研究,该研究在以下参考部分中引用。
A neural network model is defined with 8 input neurons, 1,669 hidden neurons, and 1 output neuron.
用8个输入神经元, 1,669个隐藏神经元和1个输出神经元定义了一个神经网络模型。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 8) 72
_________________________________________________________________
dense_1 (Dense) (None, 1669) 15021
_________________________________________________________________
dense_2 (Dense) (None, 1) 1670
=================================================================
Total params: 16,763
Trainable params: 16,763
Non-trainable params: 0Using 30 epochs and a batch size of 150, the losses across the different optimizers were compared using the available optimizers in the Keras API, along with the mean absolute error and root mean squared error performance on a separate test set.
使用30个纪元和150个批处理量,使用Keras API中可用的优化器比较了不同优化器的损失,以及在单独的测试集上的平均绝对误差和均方根误差性能。
For the purposes of this article, let’s compare the performance of the Adam and SGD optimizers.
出于本文的目的,让我们比较Adam和SGD优化器的性能。
亚当 (Adam)
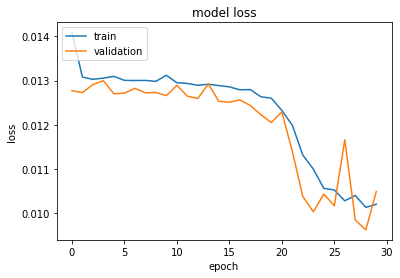
-
Mean Absolute Error: 29.89
平均绝对误差: 29.89
-
Root Mean Squared Error: 43.91
均方根误差: 43.91
新元 (SGD)
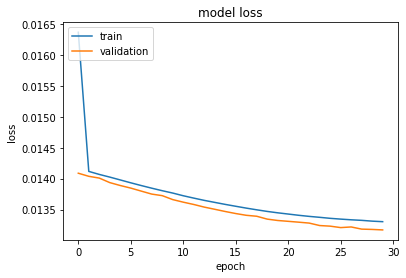
-
Mean Absolute Error: 29.15
平均绝对错误: 29.15
-
Root Mean Squared Error: 44.24
均方根误差: 44.24
When comparing these two optimizers, we see that the MAE and RMSE obtained on the test set is virtually identical. However, we see that the training and validation loss is significantly lower after 30 epochs when the Adam optimizer is used.
比较这两个优化器时,我们发现在测试集上获得的MAE和RMSE实际上是相同的。 但是,我们看到,使用Adam优化器后,经过30个纪元后,训练和验证损失显着降低。
Even with lower training and validation loss — test accuracy using SGD was just as good — at least in this instance. However, training time using the Adam optimizer was 13.48 seconds, while it came in at 9.05 seconds for SGD.
即使培训和验证损失较低,至少在这种情况下,使用SGD进行测试的准确性也一样。 但是,使用Adam优化器的训练时间为13.48秒,而SGD的训练时间为9.05秒。
From this standpoint, one could make the argument that while Adam has shown lower training and validation loss — this does not translate into accuracy gains on the test set versus SGD, while SGD accomplished the job using less training time. While this is a simplistic example and a few seconds difference is immaterial here — this will quickly add up when using larger datasets or training more complex models.
从这一观点出发,可以得出这样的论据:尽管Adam显示出较低的训练和验证损失-这并不意味着相对于SGD而言,测试集的准确性得到了提高,而SGD却以更少的训练时间完成了这项工作。 尽管这是一个简单的示例,但此处的差别不大,因此在使用较大的数据集或训练更复杂的模型时,这会很快加在一起。
As a matter of fact, much debate continues as to whether Adam is in fact a suitable alternative to SGD — with many researchers still opting for the latter. For instance, a Cornell University study by Wilson et al (2017) found instances where adaptive methods like Adam generalise worse than SGD — even when training performance was found to be superior.
事实上,关于亚当是否真的可以替代SGD的争论仍在继续,许多研究人员仍在选择后者。 例如,威尔逊(Wilson)等人(2017年)在康奈尔大学进行的一项研究发现,即使发现训练性能更好,像亚当(Adam)这样的自适应方法也普遍比SGD糟糕。
While it is not possible to do justice to such a complex topic in this article — one important takeaway is that attention should be given to the choice of optimizer when training a neural network. It is not necessarily a given that Adam will always provide the best results, and other optimizers can achieve similar test set accuracy in less training time.
尽管在本文中不可能对这样一个复杂的主题做出公正的评价,但重要的一点是,在训练神经网络时应注意优化器的选择。 亚当将始终提供最佳结果,而其他优化器可以在更少的培训时间内获得相似的测试集精度,这并不一定是必然的。
In fact, it is good practice to test models across a range of optimizers, as each has their limitations.
实际上,最好在多个优化器之间测试模型,因为每个模型都有其局限性。
结论 (Conclusion)
This article has discussed the importance of suitable optimizer selection when constructing a neural network, and the importance of taking both accuracy and training time into consideration when doing so.
本文讨论了在构建神经网络时选择合适的优化器的重要性,以及在考虑准确性和训练时间时的重要性。
Hope you found this article useful, and any questions or feedback are greatly appreciated. The relevant references, as well as the code and datasets for running the above example are available below at the MGCodesandStats GitHub repository.
希望本文对您有用,对您的任何问题或反馈都深表感谢。 有关参考,以及运行上述示例的代码和数据集,请参见下面的MGCodesandStats GitHub存储库。
Disclaimer: This article is written on an “as is” basis and without warranty. It was written with the intention of providing an overview of data science concepts, and should not be interpreted as professional advice in any way.
免责声明:本文按“原样”撰写,不作任何担保。 它旨在提供数据科学概念的概述,并且不应以任何方式解释为专业建议。
翻译自: https://towardsdatascience.com/neural-networks-importance-of-optimizer-selection-16fdbbed3ff0
神经网络优化器的选择




 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)