

单挑军旗阵型
Reinforcement learning has been at the center of many AI breakthroughs in recent years. The opportunity for algorithms to learn without the onerous constraints of data collection presents huge opportunities for key advancements. Google’s DeepMind has been at the center of Reinforcement Learning, featuring breakthroughs with projects that garnered national attention like AlphaZero, a self-trained competitive agent that became the best Go player in the world in a span of 4 days.¹
近年来,强化学习一直是许多AI突破的中心。 算法在没有繁重的数据收集约束的情况下学习的机会为关键的发展提供了巨大的机会。 Google的DeepMind一直是Reinforcement Learning的中心,其突破性项目获得了举世瞩目的项目,例如AlphaZero,这是一个经过自我训练的竞争代理商,在4天的时间内成为了世界上最好的围棋选手。¹
Traditional reinforcement learning algorithms such as Q-learning, SARSA, etc. work well in contained single agent environments, where they are able to continually explore until they find an optimal strategy. However, a key assumption of these algorithms is a stationary environment, meaning the transition probabilities and other factors remain unchanged episode to episode. When agents are trained against each other, such as in the case of poker, this assumption is impossible as both agents strategies are continually evolving leading to a dynamic environment. Furthermore, the algorithms above are deterministic in nature meaning that one action will always be considered optimal as compared to another action given a state.
传统的强化学习算法(例如Q学习,SARSA等)在包含单个代理的环境中运行良好,在这种环境中,他们可以不断探索直到找到最佳策略。 但是,这些算法的关键假设是平稳的环境,这意味着过渡概率和其他因素在各个情节之间保持不变。 当代理商相互训练时,例如在扑克中,这种假设是不可能的,因为两种代理商策略都在不断发展,从而形成了一个动态的环境。 此外,以上算法本质上是确定性的,这意味着与给定状态的另一动作相比,一个动作将始终被认为是最佳的。
Deterministic policies, however, do not hold for everyday life or poker. For example, when given an opportunity in poker, a player can bluff, meaning they represent better cards than they actually have by putting in an oversized bet meant to scare the other players into folding. However, if a player bluffs every time the opponents would recognize such a strategy and easily bankrupt the player. This leads to another class of algorithms called policy gradient algorithms which output a stochastic optimal policy that can then be sampled from.
但是,确定性策略不适用于日常生活或扑克。 例如,当有机会参加扑克比赛时,玩家可以虚张声势,这意味着他们通过下大注来吓scar其他玩家而弃牌,从而比实际拥有更好的卡牌。 但是,如果玩家每次都虚张声势,则对手会意识到这种策略并容易使玩家破产。 这导致了另一类称为策略梯度算法的算法,该算法输出随机的最优策略,然后可以从中采样。
Still, a large problem with traditional policy gradient methods is a lack of convergence due to dynamic environments as well as relatively low data efficiency. Luckily, numerous algorithms have come out in recent years that provide for a competitive self play environment that leads to optimal or near-optimal strategy such as Proximal Policy Optimization (PPO) published by OpenAI in 2017.² The uniqueness of PPO stems from the objective function which clips the probability ratio from the previous to the new model, encouraging small policy changes instead of drastic change.
仍然,传统策略梯度方法的一个大问题是由于动态环境以及相对较低的数据效率而导致缺乏收敛。 幸运的是,近年来出现了许多算法,这些算法提供了一种竞争性的自我发挥环境,可以导致最优或接近最优的策略,例如OpenAI在2017年发布的近端策略优化(PPO)。²PPO的独特性源于目标该功能可将概率比率从以前的模型限制到新模型,从而鼓励较小的政策变化,而不是剧烈的变化。
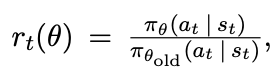
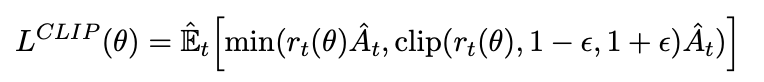
These methods have been applied successfully to numerous multi-player Atari games, so my hypothesis was that they could easily be adapted to heads up poker. In tournament poker the majority of winnings are concentrated in the winners circle, meaning that to make a profit, wins are much more important than simply “cashing” or making some money each time. A large portion of success in heads up poker is the decision to go all in or not, so in this simulation the agent had two options, fold or go all-in.
这些方法已成功应用于众多多玩家Atari游戏中,因此我的假设是它们可以轻松地适应单挑扑克。 在锦标赛扑克中,大部分赢利都集中在赢家圈子中,这意味着要赢利,赢利比简单地“兑现”或每次赚钱都重要。 单挑扑克成功的很大一部分是决定是否全押,因此在此模拟中,座席有两种选择:弃牌或全押。
The rules of poker dictate a “small blind” and a “big blind” to start the betting, meaning that the small blind has to put in a set amount of chips and the big blind has to put in double that amount. Then cards are dealt and the players bet. The only parameters the agents were given were the following: what percentage chance they would win the current hand against a random heads up player, whether they were first to bet, and how much they had already bet. They were then fed to a simple two layer neural network.
扑克规则规定“小盲人”和“大盲人”开始下注,这意味着小盲人必须投入一定数量的筹码,而大盲人必须投入两倍的筹码。 然后发牌,玩家下注。 代理商获得的唯一参数如下:他们将在随机单挑玩家中赢得当前牌的几率,是否先下注以及已经下注多少。 然后将它们输入一个简单的两层神经网络。
The packages for comparing winners as well as simulations to determine the percentage likelihood of winning the hand given a players cards can all be found on my Github here. In order to judge the effectiveness of PPO, I decided to compare the performance to that of the Reinforce algorithm a traditional policy gradient method. I chose to test the agents at different big blind levels as well which I set to be 1/50 of their total chips, 1/20 of their total, 1/10, 1/4 and 1/2. After each hand, their chip count was reset and the episode was run again. I ran each through a million simulations and then compared. What was extremely interesting to me was that at no level of blinds, did the difference as measured in chips won between the reinforce and the PPO algorithms become significant at a .05 level. However, the policies of the two different algorithms were extremely different. For example, here is a heatmap of the PPO policy for unsuited cards when the blinds are 1/20 of the stack, and the agent is the first to bet as compared to the reinforce policy in the exact same scenario.
比较获奖者以及模拟软件包,以确定获奖给予了玩家卡都可以在我的Github上找到手的百分比可能性在这里 。 为了判断PPO的有效性,我决定将性能与传统策略梯度方法Reinforce算法的性能进行比较。 我选择在不同的大盲注级别测试代理商,我将其设置为总筹码的1/50,总筹码的1 / 20、1 / 10、1 / 4和1/2。 每手之后,将重置其筹码计数,并再次运行该情节。 我分别进行了一百万次模拟,然后进行比较。 对我而言,非常有趣的是,在无盲区的情况下,增强和PPO算法之间在获胜筹码中所测得的差异是否在0.05水平上变得显着。 但是,两种不同算法的策略截然不同。 例如,当盲注为筹码量的1/20时,这是针对不合适卡的PPO策略的热图,与在完全相同的情况下的强化策略相比,座席是第一个下注的玩家。
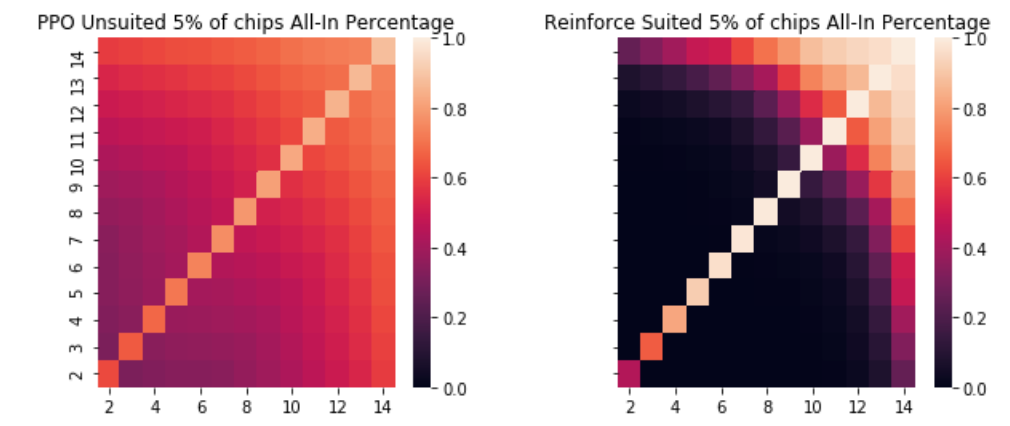
Reinforce is practically a deterministic policy whereas PPO is a far gentler transition meaning that PPO will bluff more while Reinforce will play only with a likely winner. Interestingly enough, these correspond to two different types of poker players. Those that are called “tight” only play when they think they have favorable odds, whereas “loose” players will play lots of hands, bluff and even fold some large hands if they think they are beaten. As the size of the hands increases, the reinforce agent still has closer to a deterministic policy but increases the number of combinations they will bet all-in on.
Reinforce实际上是一种确定性策略,而PPO则是一个更为温和的过渡,这意味着PPO将虚张声势,而Reinforce仅与可能的获胜者竞争。 有趣的是,它们对应于两种不同类型的扑克玩家。 那些被称为“紧身”的玩家只有在他们认为自己的赔率很高时才玩,而“松散”的玩家如果认为自己被打败,将会出很多手,虚张声势,甚至弃牌。 随着手的大小增加,加固代理仍将更接近确定性策略,但是会增加他们全押的组合数量。
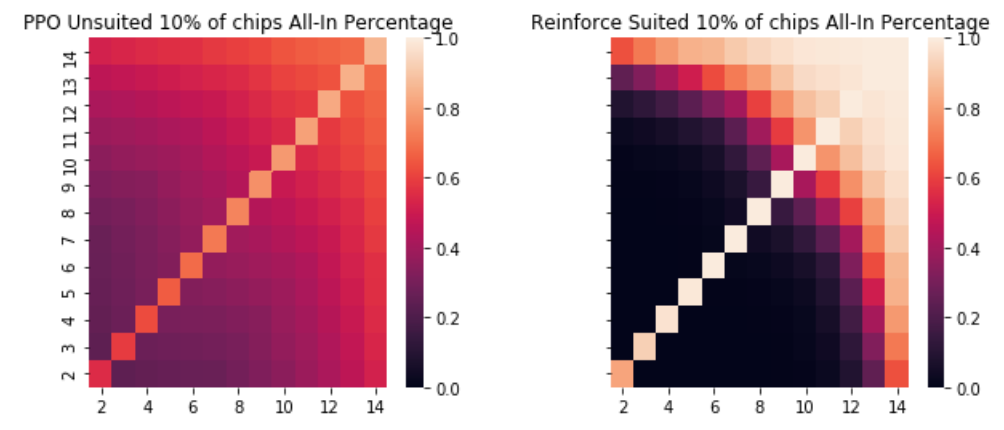
This can be seen as the agent learning a key strategy in poker known as pot odds. This is the concept that as the number of chips you can win increases relative to the size of your next bet you should be willing to play more hands. The reason being that the expected value will allow a lower probability of winning as long as the pot size is relatively large. For example, if the pot is $800 and the bet for you to go all in is $200, you would only need a 20% chance of winning that hand in order to break even in the long run if you bet as you would win $1000 chips 20% of the time thus equaling your bet of 200. However, if the pot is $200 and your all-in bet is $200 you would need a 50% of winning that hand. The agents recognize this aspect and play more loosely with their chips as they are getting pot odds than they had when the blinds were lower. We can see this reach a breaking point when the blinds are 50% of each agent's total chips and practically all hands are likely to be played.
这可以看作是代理商学习扑克中的关键策略(底池赔率)的一种方法。 这是一个概念,随着您可以赢得的筹码数量相对于下一次下注的数量增加,您应该愿意多玩。 原因是只要底池大小相对较大,期望值就可以降低获胜的可能性。 例如,如果底池为$ 800,而您全押的下注为$ 200,那么您长久只需要有20%的机会赢得该手才能达到收支平衡,因为您的下注会赢得$ 1000的筹码20%的时间等于您的下注200。但是,如果底池为$ 200,而您的全下注为$ 200,则您需要赢得该手的50%。 特工们意识到了这一点,并且比起盲注较低时,他们获得底池赔率的时候他们的筹码更加宽松。 当盲注是每个特工的总筹码的50%时,我们几乎可以看到这一切都达到了极限。
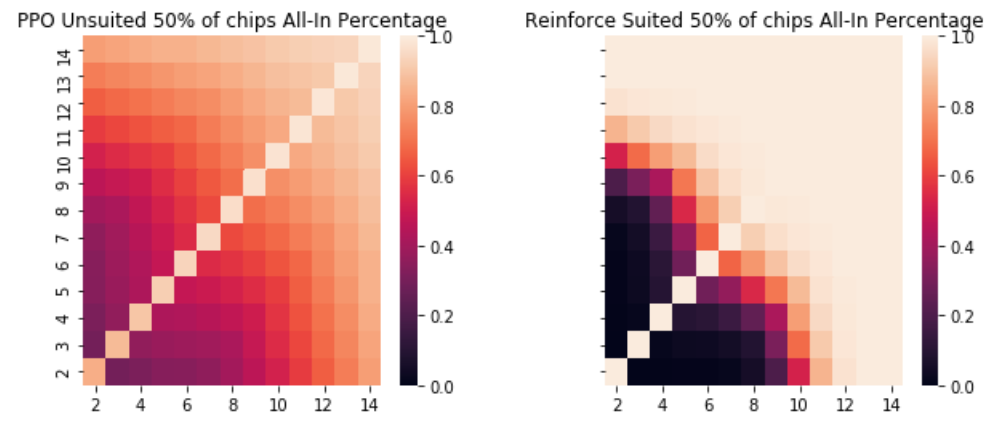
While the agents did not differ significantly in performance, as you can see from the graphs they had extremely different playing styles which was an interesting finding. I expect that as the complexity increased PPO would do better as it seems to have a smoother function that could adapt an optimal stochastic policy whereas Reinforce approached a deterministic policy. Poker, especially this limited scenario, is just one of many possible applications of policy gradient theorems that are continually being explored. It is truly a very exciting time for reinforcement learning.
尽管代理商的表现并没有显着差异,但是从图表中可以看出,他们的比赛风格截然不同,这是一个有趣的发现。 我希望随着复杂性的增加,PPO会做得更好,因为它似乎具有更平滑的功能,可以适应最佳的随机策略,而Reinforce则采用确定性策略。 扑克,尤其是在这种有限的情况下,只是不断探索的政策梯度定理的许多可能应用之一。 对于强化学习而言,这确实是一个非常令人兴奋的时刻。
-
Silver, Hubert, Schrittweiser, Hassabis. AlphaZero: Shedding new light on chess, shogi and go. https://deepmind.com/blog/article/alphazero-shedding-new-light-grand-games-chess-shogi-and-go
银,休伯特,施威,哈萨比斯。 AlphaZero:在国际象棋,将棋和围棋上崭露头角。 https://deepmind.com/blog/article/alphazero-shedding-new-light-grand-games-chess-shogi-and-go
-
Schulman, Wolski, Dhariwal, Radford, Klimov. Proximal Policy Optimization Algorithms. https://arxiv.org/abs/1710.03748
舒尔曼,沃尔斯基,达里瓦尔,拉德福德,克里莫夫。 近端策略优化算法。 https://arxiv.org/abs/1710.03748
单挑军旗阵型




 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)