高精度实时人脸pfld模型98个关键点模型训练和c++环境部署
·
2 环境:
torchvision==0.4.0
numpy==1.17.2
torch==1.2.0
opencv_python==4.1.0.25
tensorboardX==1.8
onnx (1.4.0)
onnx-simplifier (0.2.16)
pfld模型如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
######################################################
#
# pfld.py -
# written by zhaozhichao
#
######################################################
import torch
import torch.nn as nn
import math
def conv_bn(inp, oup, kernel, stride, padding=1):
return nn.Sequential(
nn.Conv2d(inp, oup, kernel, stride, padding, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True))
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True))
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, use_res_connect, expand_ratio=6):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.use_res_connect = use_res_connect
self.conv = nn.Sequential(
nn.Conv2d(inp, inp * expand_ratio, 1, 1, 0, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU(inplace=True),
nn.Conv2d(
inp * expand_ratio,
inp * expand_ratio,
3,
stride,
1,
groups=inp * expand_ratio,
bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU(inplace=True),
nn.Conv2d(inp * expand_ratio, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class PFLDInference(nn.Module):
def __init__(self):
super(PFLDInference, self).__init__()
self.conv1 = nn.Conv2d(
3, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(
64, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.conv3_1 = InvertedResidual(64, 64, 2, False, 2)
self.block3_2 = InvertedResidual(64, 64, 1, True, 2)
self.block3_3 = InvertedResidual(64, 64, 1, True, 2)
self.block3_4 = InvertedResidual(64, 64, 1, True, 2)
self.block3_5 = InvertedResidual(64, 64, 1, True, 2)
self.conv4_1 = InvertedResidual(64, 128, 2, False, 2)
self.conv5_1 = InvertedResidual(128, 128, 1, False, 4)
self.block5_2 = InvertedResidual(128, 128, 1, True, 4)
self.block5_3 = InvertedResidual(128, 128, 1, True, 4)
self.block5_4 = InvertedResidual(128, 128, 1, True, 4)
self.block5_5 = InvertedResidual(128, 128, 1, True, 4)
self.block5_6 = InvertedResidual(128, 128, 1, True, 4)
self.conv6_1 = InvertedResidual(128, 16, 1, False, 2) # [16, 14, 14]
self.conv7 = conv_bn(16, 32, 3, 2) # [32, 7, 7]
self.conv8 = nn.Conv2d(32, 128, 7, 1, 0) # [128, 1, 1]
self.bn8 = nn.BatchNorm2d(128)
self.avg_pool1 = nn.AvgPool2d(14)
self.avg_pool2 = nn.AvgPool2d(7)
self.fc = nn.Linear(176, 196)
def forward(self, x): # x: 3, 112, 112
x = self.relu(self.bn1(self.conv1(x))) # [64, 56, 56]
x = self.relu(self.bn2(self.conv2(x))) # [64, 56, 56]
x = self.conv3_1(x)
x = self.block3_2(x)
x = self.block3_3(x)
x = self.block3_4(x)
out1 = self.block3_5(x)
x = self.conv4_1(out1)
x = self.conv5_1(x)
x = self.block5_2(x)
x = self.block5_3(x)
x = self.block5_4(x)
x = self.block5_5(x)
x = self.block5_6(x)
x = self.conv6_1(x)
x1 = self.avg_pool1(x)
x1 = x1.view(x1.size(0), -1)
x = self.conv7(x)
x2 = self.avg_pool2(x)
x2 = x2.view(x2.size(0), -1)
x3 = self.relu(self.conv8(x))
x3 = x3.view(x1.size(0), -1)
multi_scale = torch.cat([x1, x2, x3], 1)
landmarks = self.fc(multi_scale)
return out1, landmarks
class AuxiliaryNet(nn.Module):
def __init__(self):
super(AuxiliaryNet, self).__init__()
self.conv1 = conv_bn(64, 128, 3, 2)
self.conv2 = conv_bn(128, 128, 3, 1)
self.conv3 = conv_bn(128, 32, 3, 2)
self.conv4 = conv_bn(32, 128, 7, 1)
self.max_pool1 = nn.MaxPool2d(3)
self.fc1 = nn.Linear(128, 32)
self.fc2 = nn.Linear(32, 3)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.max_pool1(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
return x
# if __name__ == '__main__':
# input = torch.randn(1, 3, 112, 112)
# plfd_backbone = PFLDInference()
# auxiliarynet = AuxiliaryNet()
# features, landmarks = plfd_backbone(input)
# angle = auxiliarynet(features)
# print("angle.shape:{0:}, landmarks.shape: {1:}".format(
# angle.shape, landmarks.shape))
大致看了下模型,基本就是mobilev2末尾暴力拟合关键点。
3.
注意的是实际onnx转为ncnn时候遇见一下问题,使用onnx-simplifier去除一些琐碎的op。
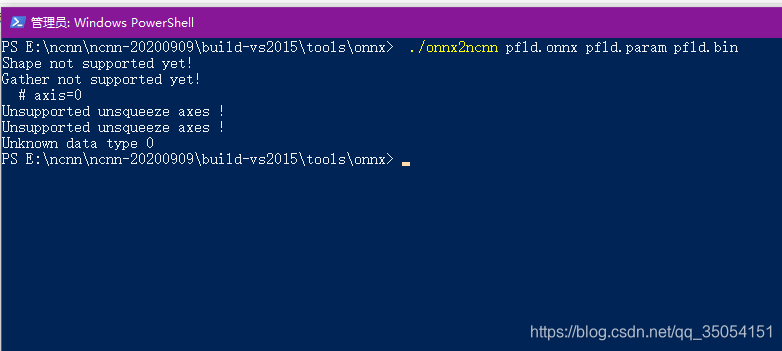
Shape not supported yet!
Gather not supported yet!
# axis=0
Unsupported unsqueeze axes !
Unsupported unsqueeze axes !
Unknown data type 0解决方案:简化onnx
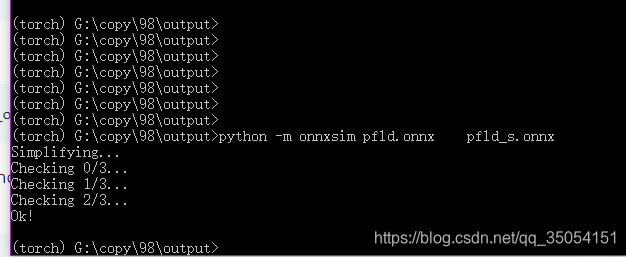
python -m onnxsim pfld.onnx pfld_s.onnxhttps://zhuanlan.zhihu.com/p/93017149?utm_source=qq,
https://github.com/daquexian/onnx-simplifier
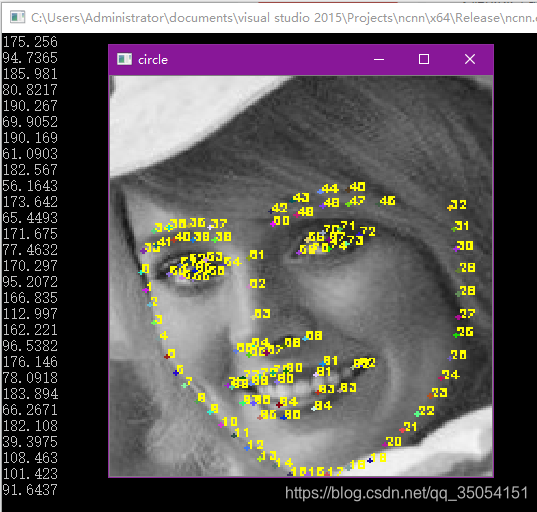
4. 使用训练转换的模型测试
#include <opencv2\opencv.hpp>
#include <map>
#include <vector>
#include <algorithm>
#include <functional>
#include <cstdlib>
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <net.h>
int main()
{
ncnn::Net pfld;
pfld.load_param("pfld-sim0.param");
pfld.load_model("pfld-sim0.bin");
cv::Mat img = cv::imread("12.jpg", 1);
ncnn::Mat in = ncnn::Mat::from_pixels_resize(img.data, ncnn::Mat::PIXEL_BGR, img.cols, img.rows, 112, 112);
const float norm_vals[3] = { 1 / 255.f, 1 / 255.f, 1 / 255.f };
in.substract_mean_normalize(0, norm_vals);
ncnn::Extractor ex = pfld.create_extractor();
ex.input("input_1", in);
ncnn::Mat out;
ex.extract("415", out);
int landmark_size_width = 112;
int landmark_size_height = 112;
int w = img.cols;
int h = img.rows;
float sw, sh;
sw = (float)w / (float)landmark_size_width;
sh = (float)h / (float)landmark_size_width;
cv::RNG rng(time(0));
for (int i = 0; i < 98; i++)
{
int icolor = (unsigned)rng;
int px = out[i * 2] * w;
int py = out[i * 2 + 1] * h;
std::cout << out[i*2]*w << std::endl;
std::cout << out[i * 2+1] * h << std::endl;
//int icolor = (unsigned)rng;
//float px, py;
//px = out[i * 2] * landmark_size_width*sw + x1;
//py = out[i * 2 + 1] * landmark_size_width*sh + y1;
//画实心点
std::string text = std::to_string(i);
cv::putText(img, text, cv::Point(px, py), cv::FONT_HERSHEY_SIMPLEX, 0.2, cv::Scalar(0, 255, 255), 1, 8, 0);
cv::circle(img, cv::Point(px, py), 1, cv::Scalar(icolor & 255, (icolor >> 8) & 255, (icolor >> 16) & 255), -1);
}
cv::namedWindow("circle",cv::WINDOW_NORMAL);
cv::imshow("circle", img);
cv::waitKey(0);
getchar();
return 0;
}
最后测试openvino转化onnx模型部署:
python mo_onnx.py --input_model pfld.onnx --input_shape=[1,3,112,112] --data_type FP32 --model_name model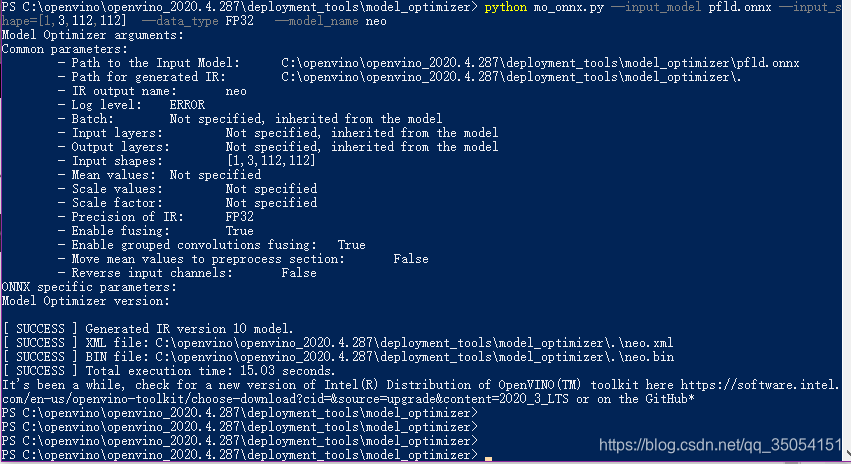

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)