天池新人赛-零基础入门数据挖掘 - 二手车交易价格预测-排名374
赛题介绍:赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。具体介绍:二手车交易价格预测具体思路:用中位数填充空值修改
·
赛题介绍:
赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
具体介绍:二手车交易价格预测
具体思路:
用中位数填充空值
修改异常数据
特征归一化
切分数据集
使用神经网络和极端回归树做Stacking
提交记录: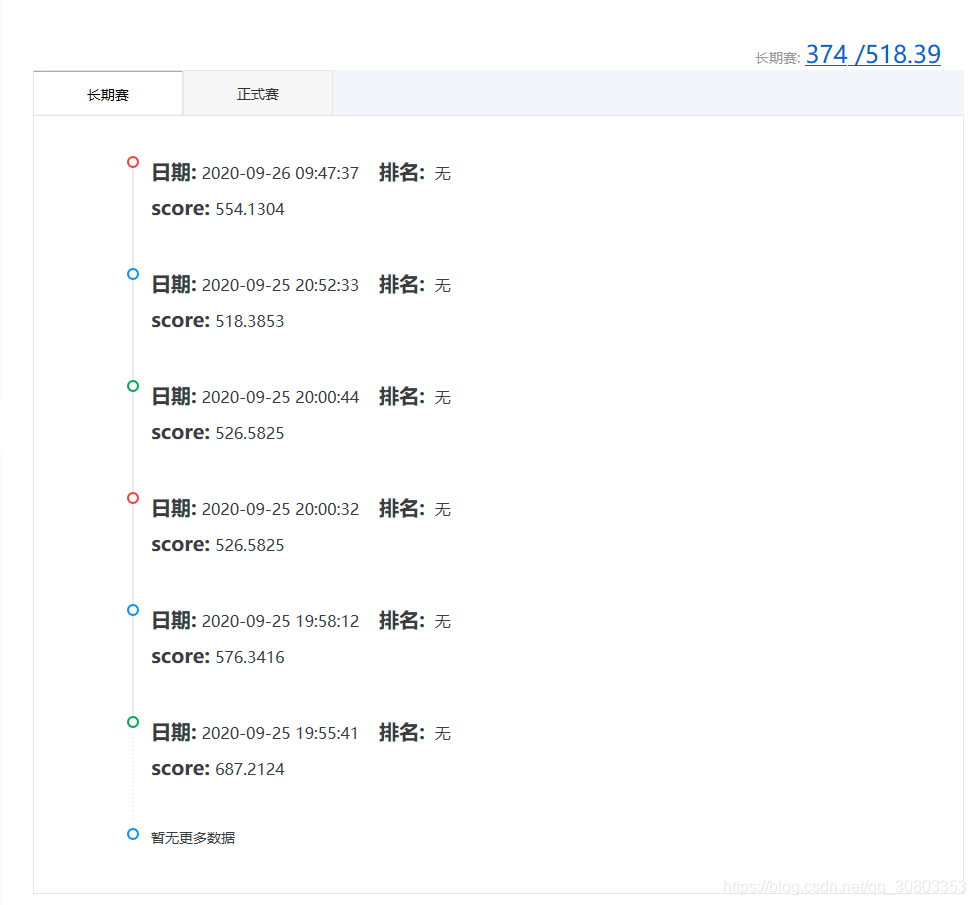
主要运行代码如下:
import os
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow import keras
from Aero_engine_life.data_model import build_model_etr
os.chdir(r'E:\项目文件\二手车交易价格\\')
from sklearn.metrics import mean_absolute_error
data_train = pd.read_csv(r'used_car_train_20200313.csv', sep=' ')
data_test = pd.read_csv(r'used_car_testB_20200421.csv', sep=' ')
data_train.replace(to_replace='-', value=np.nan, inplace=True)
data_test.replace(to_replace='-', value=np.nan, inplace=True)
# 用中位数填充空值
data_train.fillna(data_train.median(), inplace=True)
data_test.fillna(data_train.median(), inplace=True)
tags = ['model', 'brand', 'bodyType', 'fuelType', 'regionCode', 'regionCode', 'regDate', 'creatDate', 'kilometer',
'notRepairedDamage', 'power', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6',
'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14']
# 修改异常数据
data_train['power'][data_train['power'] > 600] = 600
data_test['power'][data_test['power'] > 600] = 600
# 特征归一化
min_max_scaler = MinMaxScaler()
min_max_scaler.fit(data_train[tags].values)
x = min_max_scaler.transform(data_train[tags].values)
x_ = min_max_scaler.transform(data_test[tags].values)
# 获得y值
y = data_train['price'].values
# 切分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
model = keras.Sequential([
keras.layers.Dense(250, activation='relu', input_shape=[26]),
keras.layers.Dense(250, activation='relu'),
keras.layers.Dense(250, activation='relu'),
keras.layers.Dense(1)])
model.compile(loss='mean_absolute_error',
optimizer='adam')
model.fit(x_train, y_train, batch_size=2048, epochs=111)
# 比较训练集和测试集效果
x_predict = model.predict(x_train)
test_pred = model.predict(x_test)
# model_lgb = build_model_lgb(x_train, y_train)
# val_lgb = model_lgb.predict(x_test)
model_etr = build_model_etr(x_train, y_train)
val_etr = model_etr.predict(x_test)
# model_rf = build_model_rf(x_train, y_train)
# val_rf = model_rf.predict(x_test)
# Starking 第一层
print(mean_absolute_error(y_train, x_predict))
print(mean_absolute_error(y_test, test_pred))
train_etr_pred = model_etr.predict(x_train)
print('etr训练集,mae:', mean_absolute_error(y_train, train_etr_pred))
# train_lgb_pred = model_lgb.predict(x_train)
# print('lgb训练集,mae:', mean_absolute_error(y_train, train_lgb_pred))
# write_mae('lgb', '训练集', mean_absolute_error(y_train, train_lgb_pred))
# train_rf_pred = model_rf.predict(x_train)
# print('rf训练集,mae:', mean_absolute_error(y_train, train_rf_pred))
# write_mae('rf', '训练集', mean_absolute_error(y_train, train_rf_pred))
Strak_X_train = pd.DataFrame()
# Strak_X_train['Method_1'] = train_rf_pred
# Strak_X_train['Method_2'] = train_lgb_pred
Strak_X_train['Method_3'] = train_etr_pred
Strak_X_train['Method_4'] = x_predict
Strak_X_val = pd.DataFrame()
# Strak_X_val['Method_1'] = val_rf
# Strak_X_val['Method_2'] = val_lgb
Strak_X_val['Method_3'] = val_etr
Strak_X_val['Method_4'] = test_pred
# 第二层
model_Stacking = build_model_etr(Strak_X_train, y_train)
val_pre_Stacking = model_Stacking.predict(Strak_X_val)
test_pred1 = model.predict(x_)
subA_etr = model_etr.predict(x_)
# subA_lgb = model_lgb.predict(x_)
# subA_rf = model_rf.predict(x_)
Strak_X_test = pd.DataFrame()
# Strak_X_test['Method_1'] = subA_rf
# Strak_X_test['Method_2'] = subA_lgb
Strak_X_test['Method_3'] = subA_etr
Strak_X_test['Method_4'] = test_pred1
pred = model_Stacking.predict(Strak_X_test)
print(test_pred1)
np.savetxt('submit_s.csv', test_pred1)
模型代码如下:
import os
from sklearn.metrics import mean_absolute_error, mean_squared_error
from lightgbm import LGBMRegressor
from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor
from sklearn.model_selection import GridSearchCV
from utils.read_write import writeOneCsv, pdReadCsv
def get_train():
file = 'train_label.csv'
# file = 'download_label.csv'
# file = 'test_label.csv'
train = pdReadCsv(file, ',')
return train.values[:, 3:-1], train.values[:, -1:].ravel()
def build_model_rf(x_train, y_train):
estimator = RandomForestRegressor(criterion='mse')
param_grid = {
'max_depth': range(33, 35, 9),
'n_estimators': range(73, 77, 9),
}
model = GridSearchCV(estimator, param_grid, cv=3)
model.fit(x_train, y_train)
print('rf')
print(model.best_params_)
writeParams('rf', model.best_params_)
return model
def build_model_etr(x_train, y_train):
# 极端随机森林回归 n_estimators 即ExtraTreesRegressor最大的决策树个数
estimator = ExtraTreesRegressor(criterion='mse')
param_grid = {
'max_depth': range(33, 39, 9),
'n_estimators': range(96, 99, 9),
}
model = GridSearchCV(estimator, param_grid)
model.fit(x_train, y_train)
print('etr')
print(model.best_params_)
writeParams('etr', model.best_params_)
return model
def build_model_lgb(x_train, y_train):
estimator = LGBMRegressor()
param_grid = {
'learning_rate': [0.1],
'n_estimators': range(77, 78, 9),
'num_leaves': range(59, 66, 9)
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train.ravel())
print('lgb')
print(gbm.best_params_)
writeParams('lgb', gbm.best_params_)
return gbm
def scatter_line(y_val, y_pre):
import matplotlib.pyplot as plt
xx = range(0, len(y_val))
plt.scatter(xx, y_val, color="red", label="Sample Point", linewidth=3)
plt.plot(xx, y_pre, color="orange", label="Fitting Line", linewidth=2)
plt.legend()
plt.show()
def score_model(train, test, predict, model, data_type):
score = model.score(train, test)
print(data_type + ",R^2,", round(score, 6))
writeOneCsv(['staking', data_type, 'R^2', round(score, 6)], src + '调参记录.csv')
mae = mean_absolute_error(test, predict)
print(data_type + ',MAE,', mae)
writeOneCsv(['staking', data_type, 'MAE', mae], src + '调参记录.csv')
mse = mean_squared_error(test, predict)
print(data_type + ",MSE,", mse)
writeOneCsv(['staking', data_type, 'MSE', mse], src + '调参记录.csv')
def writeParams(model, best):
if model == 'lgb':
writeOneCsv([model, best['num_leaves'], best['n_estimators'], best['learning_rate']], src + '调参记录.csv')
else:
writeOneCsv([model, best['max_depth'], best['n_estimators'], 0], src + '调参记录.csv')
def write_mse(model, data_type, mse):
writeOneCsv([model, data_type, 'mse', mse], src + '调参记录.csv')
读写文件read_write.py的方法:
# -*- coding: utf-8 二层循环版本、比较慢
import csv
import json
import os
from urllib import request
import numpy as np
import pandas as pd
from tqdm import tqdm
# 写CSV文件,写一行就换行,追加方式
def writeCsv(relate_record, src):
with open(src, 'w', newline='\n') as csvFile:
writer = csv.writer(csvFile)
for row in relate_record:
try:
writer.writerow(row)
except Exception as e:
print(e)
print(row)
# writeCsvUTF8(relate_record,bus)
# def writeExcept(row,bus):
# with open(filePath, 'r', encoding='utf-8') as dic:
# ## dic.read()
# for item in dic:
# if item.encode('utf-8').decode('utf-8-sig').strip() == s:
# print('ok')
# print(item)
# print(s)
# 写CSV文件,写一行就换行,追加方式
def writeOneCsv(relate_record, src):
try:
with open(src, 'a', newline='\n') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(relate_record)
# csvFile.close()
except Exception as e:
print(e)
print(relate_record)
# writeCsvGBK(relate_record,bus)
# 写CSV文件,写一行就换行,追加方式
def writeCsvUTF8(relate_record, src):
try:
with open(src, 'a', newline='\n', encoding='utf-8') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(relate_record)
except:
print(relate_record)
# 写CSV文件,写一行就换行,追加方式
def writeCsvGbk(relate_record, src):
try:
with open(src, 'a', newline='\n', encoding='gbk') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(relate_record)
except:
print(relate_record)
# 写Txt文件,写一行就换行,追加方式
def writeTxt(relate_record, src):
with open(src, 'w', newline='\n') as file:
for i in relate_record:
for cell in i:
file.write(cell)
file.write(',')
file.write('\n')
file.close()
# 写Txt文件,写一行就换行,追加方式
def writeOneTxt(one_record, src):
try:
with open(src, 'a') as file:
file.write(one_record)
file.write('\n')
except Exception as e:
print(e)
# 写Json文件,写一行就换行,追加方式
def writeJson(relate_record, src):
Json_str = json.dumps(relate_record, ensure_ascii=False)
with open(src, 'a') as Json_file:
Json_file.write(Json_str)
Json_file.close()
# 写Json文件,一个数据一个文件
def writeOneJson(relate_record, src):
Json_str = json.dumps(relate_record, ensure_ascii=False)
with open(src, 'w', encoding='utf-8') as Json_file:
Json_file.write(Json_str)
Json_file.close()
def readJsonToCsv(dict, src):
df = pd.DataFrame.from_dict(dict, orient='index')
df.transpose()
df.to_csv(src)
def savPng(url,filename):
try:
rsp = request.urlopen(url)
img = rsp.read()
with open(filename, 'wb') as f:
f.write(img)
except Exception as e:
print(url)
print(e)
def readJson(filepath):
try:
with open(filepath, 'r', encoding='GBK') as file_open:
data = json.load(file_open)
file_open.close()
return data
except:
try:
with open(filepath, 'r', encoding='utf-8') as file_open:
data = json.load(file_open)
file_open.close()
return data
except:
with open(filepath, 'r', encoding = "unicode_escape") as file_open:
data = json.load(file_open)
file_open.close()
return data
def readBigData(filePath,sep):
data = pd.read_csv(filePath, sep=sep, engine='python', iterator=True)
chunkSize = 100
chunks = []
chunk = data.get_chunk(chunkSize)
chunks.append(chunk)
print('开始合并')
data = pd.concat(chunks, ignore_index=True)
return data
def readerPandas(file,sep, chunkSize=100000, patitions=10 ** 4):
reader = pd.read_csv(file, iterator=True,sep=sep)
chunks = []
with tqdm(range(patitions), 'Reading ...') as t:
for _ in t:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
break
return pd.concat(chunks, ignore_index=True)
def readTxt(filepath):
try:
with open(filepath, 'r', encoding='gbk') as f:
lines = []
for one in f:
one = one.rstrip("\n\t")
lines.append(one)
f.close()
return lines
except:
with open(filepath, 'r', encoding='utf-8') as f:
lines = []
for one in f:
one = one.rstrip("\n\t")
lines.append(one)
f.close()
return lines
def readTxtJson(filepath):
try:
with open(filepath, 'r', encoding='utf-8') as f:
lines = []
for line in f:
line = line.rstrip("\n\t")
line = line.rstrip(" ")
lines.append(line)
Json_data = "".join(lines)
data = eval(Json_data)
f.close()
return data
except:
print(filepath)
def readToStr(filepath):
try:
with open(filepath, 'r', encoding='gbk') as f:
data = f.read()
f.close()
return data
except:
with open(filepath, 'r', encoding='utf-8') as f:
data = f.read()
f.close()
return data
def readCsv(filepath):
# encoding = 'utf-8'
encoding = 'gbk'
birth_data = []
try:
with open(filepath, 'r',encoding=encoding) as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
for row in csv_reader: # 将csv 文件中的数据保存到birth_data中
birth_data.append(row)
csvfile.close()
return birth_data
except:
with open(filepath, 'r',encoding='utf-8') as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
for row in csv_reader: # 将csv 文件中的数据保存到birth_data中
birth_data.append(row)
csvfile.close()
return birth_data
def pdReadCsv(file, sep):
try:
data = pd.read_csv(file, sep=sep,encoding='utf-8',error_bad_lines=False,engine='python')
return data
except:
data = pd.read_csv(file,sep=sep,encoding='gbk',error_bad_lines=False,engine='python')
return data
def pdToCsv(data,path):
data.to_csv(path,index=True,header=False,mode='a',sep=',')
def readExcel(file):
data = pd.read_excel(file)
return data
# 求数组中出现最多的元素
def max_list(gid_list):
temp = 0
max_rec = []
for rec in gid_list:
if gid_list.count(rec) > temp:
max_rec = rec
temp = gid_list.count(max_rec)
return max_rec
# 遍历文件夹中的所有文件
def eachFile(filepath):
pathDir = os.listdir(filepath) # 获取当前路径下的文件名,返回List
return pathDir
def find_dir_files(path):
files_list = []
for root, files in os.walk(path):
# for dir in dirs:
# print(os.path.join(root, dir))
for file in files:
files_list.append(os.path.join(root, file))
return files_list
def get_file_list(file_path):
dir_list = os.listdir(file_path)
# 注意,这里使用lambda表达式,将文件按照最后修改时间顺序升序排列
# os.path.getmtime() 函数是获取文件最后修改时间
# os.path.getctime() 函数是获取文件最后创建时间
dir_list = sorted(dir_list, key=lambda x: os.path.getmtime(os.path.join(file_path, x)))
return dir_list
# reduce_mem_usage 函数通过调整数据类型,帮助我们减少数据在内存中占用的空间
def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} kB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f} kB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
def dataToDict(file):
station = pd.read_table(file, sep='\t', usecols=[1, 2], encoding='gbk')
stationID = station.values.tolist()
dict ={}
for stations in stationID:
id = '"'+str(stations[0]) +'"'
dict[id] = '"'+stations[1]+'"'
print(dict)
if __name__ == '__main__':
file = '.Txt'
dataToDict(file)
# change_list()
# src = 'D:\data\jianguiyaun\\all_bus_line\\bianli2019\\bus_route_all\\bus_route_9000\\'
# src_list = get_file_list(src)
# full_path = os.path.join(src, src_list[0])
欢迎大家一键三连,我会持续分享的

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)