【卷积神经网络】—— 卷积神经网络介绍及案例
深层的神经网络深度学习网络与更常见的单一隐藏层神经网络的区别在于深度,深度学习网络中,每一个节点层在前一层输出的基础上学习识别一组特定的特征。随着神经网络深度增加,节点所能识别的特征也就越来越复杂。卷积神经网络1、卷积神经网络与简单的单层神经网络的比较2、卷积神经网络的发展历史3、卷积神经网络的结构分析4、卷积网络API介绍全连接神经网络的缺点:1、参数太多,在cifar-10的数据集中,只有32
深层的神经网络
深度学习网络与更常见的单一隐藏层神经网络的区别在于深度,深度学习网络中,每一个节点层在前一层输出的基础上学习识别一组特定的特征。随着神经网络深度增加,节点所能识别的特征也就越来越复杂。
卷积神经网络介绍:一文让你理解什么是卷积神经网络 - 简书
卷积神经网络
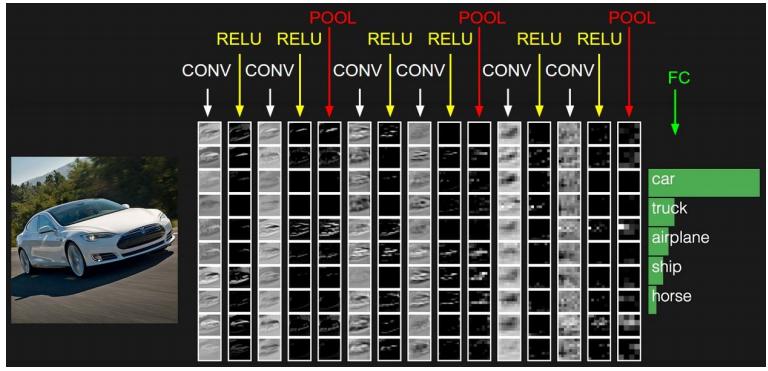
1、卷积神经网络的层级结构
- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- ReLU激励层 / ReLU layer
- 池化层 / Pooling layer
- 全连接层 / FC layer
全连接神经网络的缺点:
1、参数太多,在cifar-10的数据集中,只有32*32*3,就会有这么多权重,如果说更大的图片,比如200*200*3就需要120000多个,这完全是浪费
2、没有利用像素之间的位置信息,对于图像识别任务来说,每个像素与周围的像素都是联系比较紧密的。
3、层数限制(层数多了,反而可能效果不好)
神经网络的基本组成包括输入层、隐藏层、输出层。而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)
卷积层:通过在原始图像上平移来提取特征
池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂度(最大池化和平均池化)
2、卷积层
卷积层的零填充:
卷积核在提取特征映射时的动作称之为padding(零填充),由于移动步长不一定能整出整张图的像素宽度。其中有两种方式,SAME和VALID。
- SAME:越过边缘取样,取样的面积和输入图像的像素宽度一致。
- VALID:不越过边缘取样,取样的面积小于输入的图像的像素宽度
下面的动态图形象地展示了卷积层的计算过程:

结论:
- 大小表示方式 [长, 宽, 通道数]
- 偏置数和filter个数相等
- filter个数和最后输出的通道数相等
- 上图中的filter是2,相当于有2个人去观察5*5*3的图片(3通道) ,每个filter进行内积之和加上偏置得出一个结果。最后形成2个结果(2个通道)
怎么计算卷积输出体积大小:
- 输入体积大小 H1 * W1 * D1
- 四个超参数:
- Filter数量 K
- Filter大小 F
- 步长 S
- 零填充大小 P
- 输出体积大小 H2 * W2 * D2
- H2 = (H1 - F + 2P)/S + 1
- W2 = (W1 - F + 2P)/S + 1
- D2 = K
例如:输入的图片的大小为 28 * 28 * 1(长,宽,通道数),过滤器的大小为3 * 3,有32个,步长=1,填充P=1
H2 = (28 - 3 + 2*1)/1 + 1 = 28
W2 = (28 - 3 + 2*1)/1 +1 = 28
则输出体积大小为[28, 28, 32]
练习题:
输入图片大小为200*200,依次经过一层卷积(kemel size 5*5,padding 1,stride 2),pooling(kemel size 3*3,padding 0,stride 1),又一层卷积(kemel size 3*3,padding 1,stride 1)之后,输出特征图大小为:( C )
A.95 B.96 C.97 D.98 E.99 F.100
解析:
H2,1 = (200-5+2*1)/2+1=99.5 取99,因为填充是在图片外围填充一圈,取99刚好能够覆盖图片
H2,2 = (99-3)/1+1=97
H2,3 = (97-3+2*1)/1+1=97
卷积网络API
卷积层:
- tf.nn.conv2d(input, filter, strides=, padding=, name=None)
- 计算给定4-D input和filter张量的2维卷积
- input:给定的输入张量,具有[batch, height, width, channel],类型为float32,64
- filter:指定过滤器的大小,里面存放的是权重。[filter_height,filter_width, in_channels, out_channels] (in_channels表示过滤器的输入通道数; out_channels表示过滤器的输出通道,代表有多少个结论,最后输出多少张表。值为filter的个数,同样也是偏置的个数)
- strides:strides=[1, stride, stride, 1],步长
- padding:“SAME”,“VALID”这两种值,表示填充算法的类型。其中“VALID”表示滑动超出的部分舍弃,“SAME”表示填充,使得变化后height,width一样大。值为数值时,需要根据公式计算。
3、激励层
激活函数-Relu
CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,图像如下。
公式:relu = max(0, x)
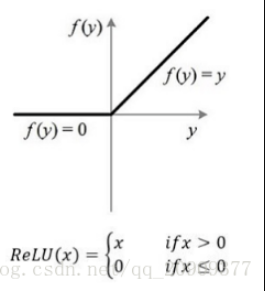
作用:把卷积层输出结果做非线性映射。增加网络的非线性分割能力。
说明:
- 采用sigmoid等函数,反向传播求误差梯度时,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多
- 对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度爆炸的情况
激活函数API
tf.nn.relu(features, name=None)
feature:卷积后加上偏置的结果(比如卷积层输出后的结果为(28,28,100) ,其中100表示多少个过滤器(神经元),就有多少个结果表)
return:结果
激活层不改变图片的大小
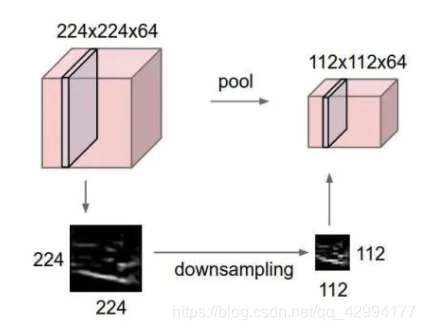
4、池化层
Pooling层主要作用是特征提取,通过去掉Feature Map中不重要的样本,进一步减少参数数量。
如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
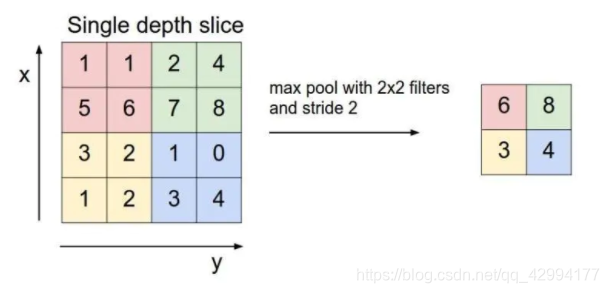
Pooling的方法很多,最常用的是Max Pooling。一般用2*2,步长为2 来做池化。
池化API
- tf.nn.max_pool(value, ksize=, strides=, padding=, name=None)
- 输入上执行最大池数
- value:4-D Tensor形状[batch, height, width, channels]
- ksize:池化窗口大小,[1, ksize, ksize, 1]
- strides:步长大小,[1, strides, strides, 1]
- padding:填充算法的类型(SAME,VALID)。使用SAME。池化层的padding="SAME",表示填充,如果不够需要填充,但是图片大小需要计算
5、全连接层
前面的卷积和池化相当于特征工程,后面的全连接相当于做特征加权。最后的全连接层在整个卷积神经网络中起到“分类器”的作用。

卷积神经网络识别手写数字案例
Mnist数据集可以从官网下载,网址:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges下载下来的数据集被分成两部分:训练集和测试集。
案例分析:
每个手写数字图片的大小为28*28,预测数字为0-9,共10个类别,图片通道为1。
我们可以自己定义卷积层,如下
一卷积层: 卷积:定义32个Filter,大小5*5,strides=1,padding="SAME",bisa=32个(有多少个Filter就有多少个偏置) 则输入:[None, 28, 28, 1] 输出:[None, 28, 28, 32]
激活:激活层不改变图片大小,输出为[None, 28, 28, 32]
池化:定义池化大小2*2,strides=2,padding="SAME" 则输入:[None, 28, 28, 32] 输出:[None, 14, 14, 32](池化层的padding="SAME",表示填充,但是图片大小需要计算)
二卷积层 : 卷积:定义64个Filter,大小5*5*32(一层卷积输出的通道=32),strides=1,padding="SAME",bisa=64个 则输入:[None, 14, 14, 32] 输出:[None, 14, 14, 64]
激活:激活层不改变图片大小,输出为[None, 14, 14, 64]
池化:定义池化大小2*2,strides=2,padding="SAME" 则输入:[None, 14, 14, 64] 输出:[None, 7, 7, 64]
全连接层: 输入二维:[None, 7*7*64] 权重:[7*7*64, 10] bias=10个 输出:[None, 10]
注意:
深度学习的学习率都非常小
完整代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
"""
卷积神经网络手写数字识别案例
"""
# 定义一个初始化权重的函数
def weight_variables(shape):
w = tf.Variable(tf.random_normal(shape=shape, mean=0.0, stddev=1.0))
return w
# 定义一个初始化偏置的函数
def bias_variables(shape):
b = tf.Variable(tf.constant(0.0, shape=shape))
return b
def model():
"""
自定义卷积模型
:return:
"""
# 1、建立数据的占位符 x[None, 784] y_true[None, 10]
with tf.variable_scope("data"):
x = tf.placeholder(tf.float32, [None, 784])
y_true = tf.placeholder(tf.int32, [None, 10])
# 2、一卷积层 定义32个Filter,大小5*5,strides=1,padding="SAME",bisa=32个
with tf.variable_scope("conv1"):
# 随机初始化权重(filter),偏置[32]
w_conv1 = weight_variables([5,5,1,32]) # 图片通道数=1 filter=32
b_conv1 = bias_variables([32])
# 对x进行形状的改变 [None,784] ——> [None,28,28,1]
x_reshape = tf.reshape(x, [-1, 28, 28, 1]) # 第一个值不知道就填-1
# 卷积+激活 [None,28,28,1]——>[None, 28, 28, 32]
x_relu = tf.nn.relu(tf.nn.conv2d(x_reshape, w_conv1, strides=[1,1,1,1], padding="SAME") + b_conv1)
# 池化 2*2,strides=2,padding="SAME" [None, 28, 28, 32]——>[None, 14, 14, 32]
x_pool1 = tf.nn.max_pool(x_relu, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
# 3、二卷积层 定义64个Filter,大小5*5*32,strides=1,padding="SAME",bisa=64个
with tf.variable_scope("conv2"):
# 随机初始化权重(filter) [5,5,32,64 ,偏置[64]
w_conv2 = weight_variables([5, 5, 32, 64]) # 图片通道数=32 filter=64
b_conv2 = bias_variables([64])
# 卷积、激活、池化计算
# [None, 14, 14, 32]——>[None, 14, 14, 64]
x_relu2 = tf.nn.relu(tf.nn.conv2d(x_pool1, w_conv2, strides=[1,1,1,1], padding="SAME") + b_conv2)
# 池化 2*2,strides=2,padding="SAME" [None, 14, 14, 64]——>[None, 7, 7, 64]
x_pool2 = tf.nn.max_pool(x_relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 4、全连接层 [None, 7, 7, 64]——>[None,7*7*64]*[7*7*64,10]+[10]=[None, 10]
with tf.variable_scope("fc"):
# 随机初始化权重和偏置
w_fc = weight_variables([7*7*64, 10])
b_fc = bias_variables([10])
# 修改形状 [None, 7, 7, 64]——>[None, 7*7*64]
x_fc_reshape = tf.reshape(x_pool2, [-1, 7*7*64])
# 进行矩阵运算得出每个样本的10个结果
y_predict = tf.matmul(x_fc_reshape, w_fc) + b_fc
return x, y_true, y_predict
def conv_fc():
# 获取真实的数据
mnist = input_data.read_data_sets("./data/", one_hot=True)
# 定义模型,得出输出
x, y_true, y_predict = model()
# 求所有样本损失,然后求平均损失
with tf.variable_scope("soft_cross"):
# 求平均交叉熵损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict))
# 梯度下降求损失
with tf.variable_scope("optimizer"):
# 深度学习的学习率非常小
train_op = tf.train.GradientDescentOptimizer(0.0001).minimize(loss)
# 计算准确率
with tf.variable_scope("acc"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()
# 开启会话训练
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 循环训练
for i in range(1000):
# 取出样本数据的特征数据、目标数据
mnist_x, mnist_y = mnist.train.next_batch(50)
# 运行train_op训练
sess.run(train_op, feed_dict={x: mnist_x, y_true: mnist_y})
print("训练第%d步,准确率为:%f" % (i, sess.run(accuracy, feed_dict={x: mnist_x, y_true: mnist_y})))
if __name__ == '__main__':
conv_fc()
设置的训练步数可以调的更大一点。
代码运行后展示:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)