logit回归模型_你们要的二项Logit模型在这里——离散选择模型之八
前言:本文主要介绍如何以效用最大化理论为基础,推导出二项 Logit(Binary Logit)模型。本文为系列离散选择模型(Discrete Choice Model, DCM)系列文章的第8篇。温馨提示:阅读本文之前,请准备好纸、笔、以及小板凳。自己动手推导一遍有助于理解。Probit模型的建模过程回顾在《效用最大化准则:离散选择模型的核心(Probit篇)——离散选择模型之七》一文中,我们基

前言:本文主要介绍如何以效用最大化理论为基础,推导出二项 Logit(Binary Logit)模型。
本文为系列离散选择模型(Discrete Choice Model, DCM)系列文章的第8篇。
温馨提示:阅读本文之前,请准备好纸、笔、以及小板凳。自己动手推导一遍有助于理解。
Probit模型的建模过程回顾
在《效用最大化准则:离散选择模型的核心(Probit篇)——离散选择模型之七》一文中,我们基于效用最大化理论给出了二项Probit模型的推导过程。简单回顾一下建模的过程:
- 假设对于决策主体n面临两个备选方案i和j
- 方案i的效用
可以表示为可以观测得到的、确定性的部分
和一个随机项
之和:
- 类似地,方案j的效用
可以表示为:
- 对于决策主体 n 而言,若方案 i 的效用
高于方案 j 的效用
,则 n 选取方案 i 。也就是说,n 选择方案 i 的概率
等价于事件
发生的概率:
- 如果令
和
服从均值为0、方差为
和
的正态分布,则
服从均值为0、方差为
的正态分布。在此基础上,便可以推导出Probit模型的表达形式如下面的(4)式所示。其中,
表示标准正态分布的累积分布函数。
Probit模型的特点
从建模的角度来说,Probit模型假设随机项
为解决这一问题,研究者提出,若假设随机项
Gumbel分布
Gumbel分布是一种极值型分布,常被用于极端事件的估计和预测。比如某水文站,每天观测某条河道的水位,连续观测了50年;如果单独对河道每年的最高水位进行建模,就可以考虑用Gumbel分布。除此之位,Gumbel分布还被应用于地震、洪水等极端自然灾害现象的预测。
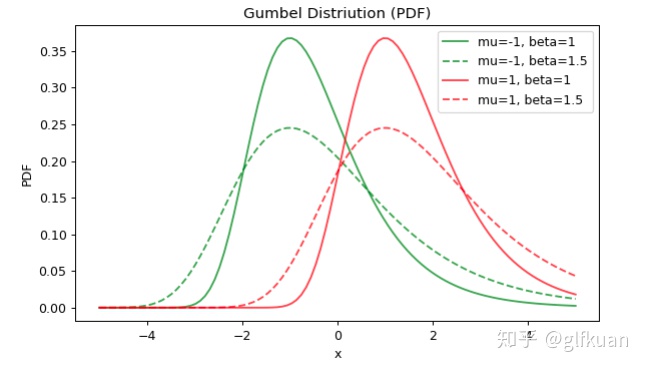
记参数为的
下图2显示了当参数
其所对应的累积分布函数(CDF)为:
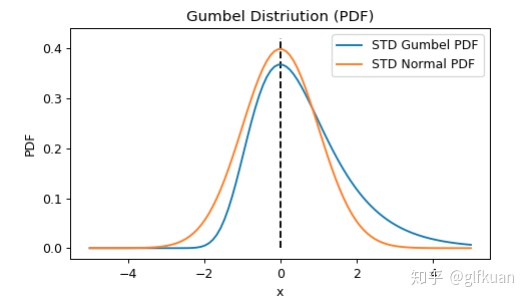
从图3中可以看出:标准Gumbel分布与标准正态分布的形状大体上接近,但Gumbel分布不是对称的,其分布呈现一定的偏态。另外,Gumbel分布尾巴要比标准正态分布更肥一点。
Logistic分布
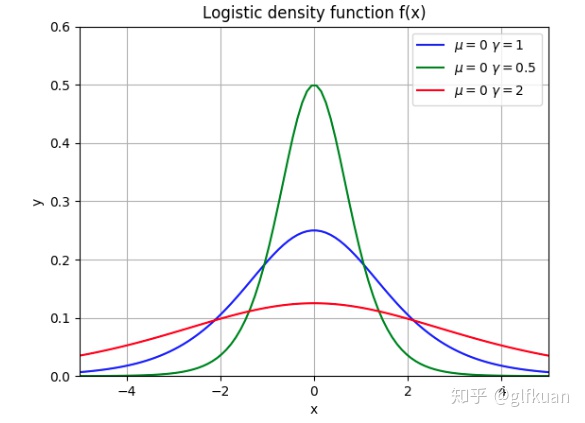
在推导二项Logit模型的表达式之前,再介绍另外一个分布:Logistic分布。
随机变量
其中,
下图4给出了参数
Logit模型的推导
先给出一条重要性质:如果随机变量
-
-
-
、
之间相互独立
则:
详细的证明过程请参见《从Gumbel分布到Logistic分布——离散选择模型之九》。
根据上面的(3)式我们知道决策主体 n 选择方案 i 的概率
在Logit模型中,我们就是假设随机效用部分
分子分母同时乘以
式中
最终,在二项Logit模型中,决策者 n 选择方案 i 的概率可以表示为:
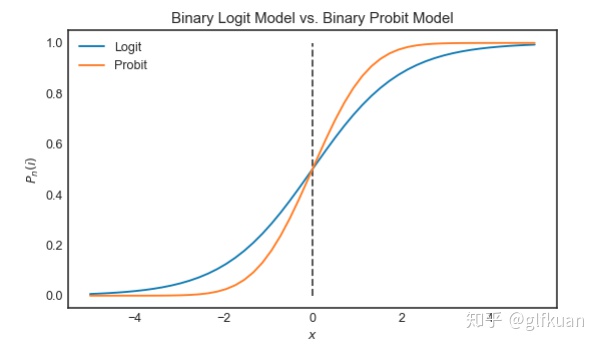
(14)式即为二项Logit模型的表达式。图5给出了仅有一个自变量时的二项Logit和二项Probit的图像:
【本篇完】
专栏文章列表(动态更新中...)
离散选择模型基础:
- 离散选择模型(Discrete Choice Model)简介
- 线性模型 vs. Logistic模型
- Logit究竟是个啥?
- Odds 和 Odds Ratio 的区别
- 正确打开/解读Logit模型系数的方式
- Logit模型拟合实战案例(SAS)
- Logit模型拟合实战案例(Python)
二项Logit/Probit:
- 效用最大化准则:离散选择模型的核心(Probit模型上篇)
- 效用最大化准则:离散选择模型的核心(Probit模型下篇)
- 效用最大化准则:离散选择模型的核心(二项Logit模型)
- 从Gumbel分布到Logistic分布
多项Logit(MNL):
- 效用最大化准则:多项Logit模型(Multinomial Logit, MNL)
- 多项Logit模型(MNL)拟合实战案例(SAS篇)
- MNL的IIA特性与“红公交/蓝公交悖论”(上篇)
- MNL的IIA特性与“红公交/蓝公交悖论”(下篇)
- 如何将决策者的属性和方案属性同时放到MNL模型中?
- Logit模型中的个人属性、方案属性数据处理案例
- 为什么条件Logit模型中没有常数项,以及,你的女神会不会不喜欢你?
- Logit模型中的ASC(Alternative-Specific Constant)是指什么?
统计学相关:
- 最大似然估计(上)
- 最大似然估计(下)
- 模型中存在共线性问题,该怎么破?
关注【DCM笔记】公众号,私信作者获取相关文章中的 练习数据 和 代码:


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)