c++读取utf8文件_读取数据和处理
1.read_csv()txt文本:1)读取数据import pandas as pdimport numpy as npe1=pd.read_csv('data_test01.txt') #可以写txt文件名也可以写绝对路径e12)删除无用数据e1=pd.read_csv('data_test01.txt',sep=',',skiprows=1,skipfo...
·
1.read_csv()
txt文本:

1)读取数据
import pandas as pd
import numpy as np
e1=pd.read_csv('data_test01.txt') #可以写txt文件名也可以写绝对路径
e1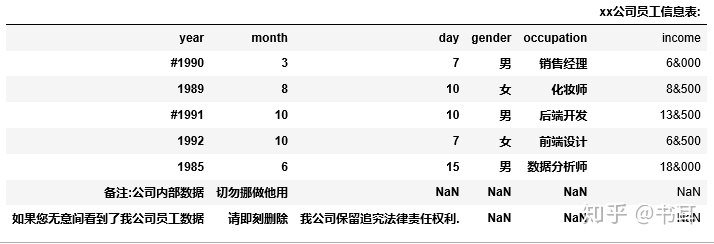
2)删除无用数据
e1=pd.read_csv('data_test01.txt',sep=',',
skiprows=1,skipfooter=2)
e1
3)解决乱码和警告信息
e1=pd.read_csv('data_test01.txt',sep=',',
skiprows=1,skipfooter=2,encoding='utf8',engine='python')
e1
4)注释内容的识别
方法1
e1=pd.read_csv('data_test01.txt',sep=',',
skiprows=1,skipfooter=2,encoding='utf8',engine='python',comment='#')
e1
方法2(只删除'#')
df=pd.read_csv('data_test01.txt',
skiprows=1,skipfooter=2,
thousands='&',
encoding='utf8',engine='python')
df['year']=df['year'].map(lambda x:x.replace("#",""))
df
5)修正千分位
e1=pd.read_csv('data_test01.txt',sep=',',
skiprows=1,skipfooter=2,
comment='#',thousands='&',
encoding='utf8',engine='python')
e1
6)合并month,day,gender并命名为birthday #parse_dates={'新列名':[想合并的列]}解析日期参数
e1=pd.read_csv('data_test01.txt',
parse_dates={'birthday':[0,1,2]},
skiprows=1,skipfooter=2,
comment='#',thousands='&',
encoding='utf8',engine='python')
e1
csv文件
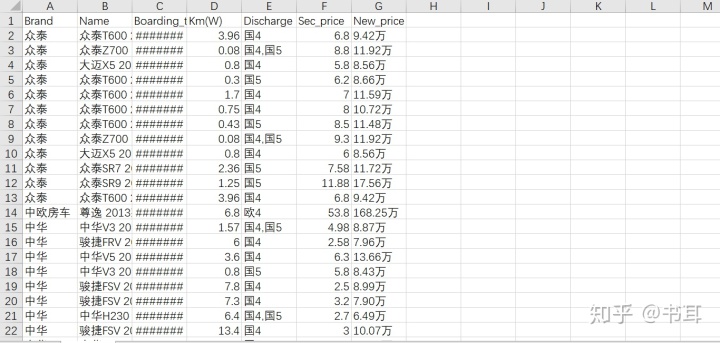
1)读取数据
import pandas as pd
import numpy as np
e1=pd.read_csv('sec_cars.csv')
e1.head()
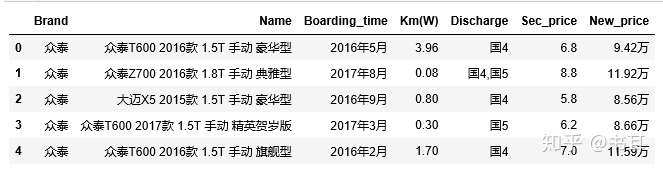
2)数据信息查看
#查看字段类型
e1.info()
#查找国4车
e2=e1[e1.Discharge =='国4']
e2.head()
#查找国4众泰车
e3=e1[(e1.Brand =='众泰')&(e1.Discharge=='国4')]
e3.head()3)数据清洗
#更改数据类型(boarding_time->datetime;new_price->float)
e1['Boarding_time']=pd.to_datetime(e1['Boarding_time'],format='%Y年%m月')
e1.dtypes
# 处理新车价格列,变为浮点型
e1=e1[e1.New_price !='暂无'] # 筛选出来价格为非暂无的数据
#三种方法
#e1['New_price']=e1['New_price'].apply(lambda x:x.replace(x[-1],'')).astype(np.float64)
# e1['New_price']=e1['New_price'].str[:-1].astype(np.float64)
e1['New_price']=e1['New_price'].apply(lambda x:x.split('万')[0]).astype(np.float64)
e1.dtypes
##添加月份列
e1['month'] = e1.Boarding_time.dt.month
e1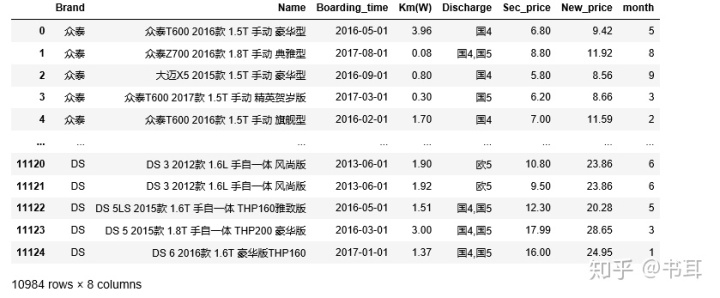
##把月份改为季节
def gen_season(x):
if x in set([11,12,1,2]):
return '冬季'
elif x in set([3,4,5]):
return '春季'
elif x in set([6,7,8,9]):
return '夏季'
else:
return '秋季'
e1['season'] = e1.month.apply(gen_season)
e1.head()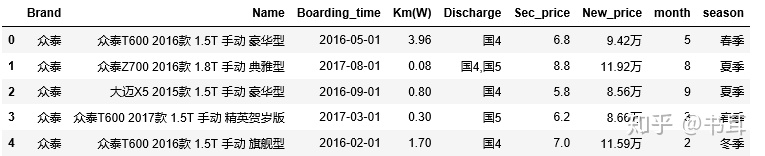
##对月份绘图
import matplotlib.pyplot as plt # 导入画图包,matplotlib
plt.rcParams['font.sans-serif'] = ['SimHei'] #设置参数--字体
#e1.season.value_counts().plot(kind='pie') #饼图
e1.season.value_counts().plot(kind='bar') #条形图
plt.show()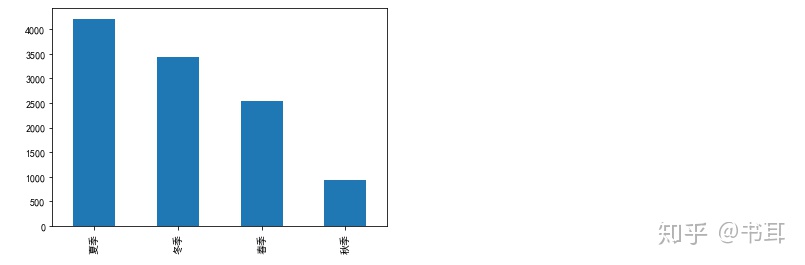
##筛选出不是字符串类型的所有数据
num_variables=e1.columns[e1.dtypes!='object'] #代表列里面的数据和列名无关
e1[num_variables] ##e1.describe(include=['object'])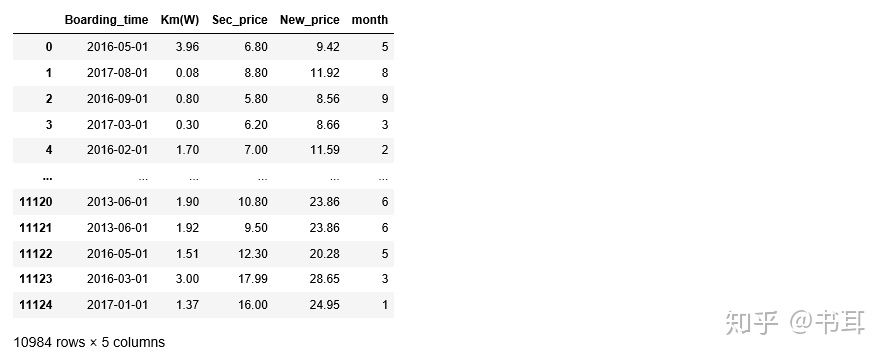
csv文件:
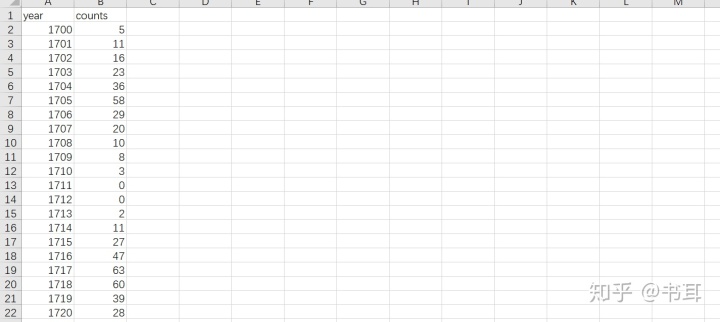
1)读取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
sunspots=pd.read_csv('sunspots.csv')
sunspots2)异常值指标
1.标准差
xbar=sunspots.counts.mean()
xstd=sunspots.counts.std()
print('标准差法异常值上限检测:n',any(sunspots.counts>xbar+3*xstd))#bool类型
print('标准差法异常值下限检测:n',any(sunspots.counts<xbar-3*xstd))
2.箱线图法
Q1=sunspots.counts.quantile(q=0.25)
Q3=sunspots.counts.quantile(q=0.75)
IQR=Q3-Q1
print('箱线图法异常值上线检测:n',any(sunspots.counts>Q3+1.5*IQR)) #bool类型
print('箱线图法异常值下线检测:n',any(sunspots.counts<Q1-1.5*IQR))
3.箱线图的绘制
sunspots.counts.plot(kind='box')
plt.show()
2.read_excel()
excel文件:
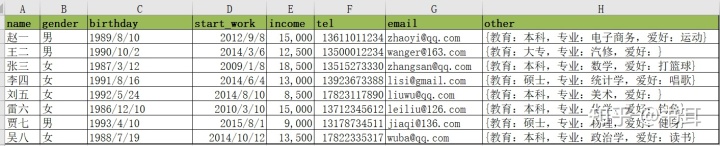
1)读取数据
e3=pd.read_excel('data_test03.xlsx')
e3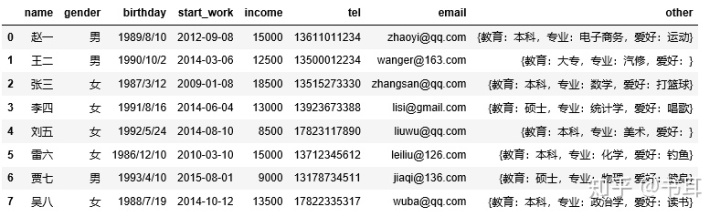
2)数据信息查看
(1)
e3.info()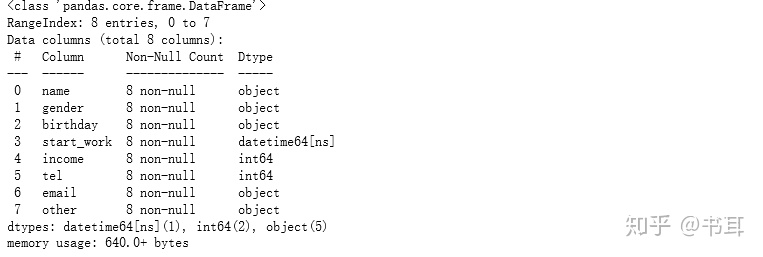
(2)查看、判断空值并计算空值个数
e3.isnull()
e3.isnull().sum() #按照列方向判断
e3.isnull().any()
(3)统计学的一些信息
e3.describe() 
3)数据清洗
1.将birthday变量转换为日期型
e3['birthday']=pd.to_datetime(e3['birthday'])
e3['birthday']
2.将手机号变成字符串
e3['tel']=e3['tel'].astype('str')
print(e3['tel'].dtype)
3.根据时间添加新列
time=pd.datetime.today() #获取当前时间
time.year
time.month
time.day
##添加年月日三列
e3['year']=e3['birthday'].dt.year
e3['month']=e3['birthday'].dt.month
e3['day']=e3['birthday'].dt.day
e3
##删除年月日,原数据更改(比较drop_duplicates())
e3.drop('year',inplace=True,axis=1)
e3
e3.drop(['month','day'],inplace=True,axis=1)
e3
ps:
frame.drop(
labels=None,axis=0,
index=None,columns=None,
level=None, inplace=False,errors='raise',
) #labels可以是单列也可以是多列都要添加一个列表[]
frame.drop_duplicates(
subset: Union[Hashable, Sequence[Hashable], NoneType] = None,
keep: Union[str, bool] = 'first',
inplace: bool = False,
ignore_index: bool = False,
) subset可以是单列也可以是多列,单列可添加列表[]也可以不用,多列用[]
frame.sort_values(
by, axis=0, ascending=True,
inplace=False, kind='quicksort',
na_position='last',ignore_index=False,
)by单列不用[],多列要用[]
##新增年龄和工龄两列pd.datetime.today().year现在的年份
e3['age']=pd.datetime.today().year-e3['birthday'].dt.year
e3['workage']=pd.datetime.today().year-e3['start_work'].dt.year
e3
4.apply函数的应用
##将手机号中间四位隐藏起来
e3['tel']=e3['tel'].apply(lambda x:x.replace(x[3:7],'****'))
e3['tel']
#取出邮箱的域名
e3['email_domain'] = e3['email'].apply(lambda x:x.split('@')[1])
e3['email_domain']3)其他数据读取方式
(1)从文本文件读取数据
- read()
file_name = 'text.txt'
with open(file_name, 'r') as f:
lines = f.read() # 把文件里所有的内容都一起读到内存里
print(lines)
- readlines()
with open(file_name, 'r') as f:
lines = f.readlines()
print(lines)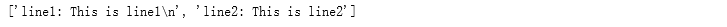
- readline()
with open(file_name, 'r') as f:
line = f.readline()
print(line)
with open(file_name, 'r') as f:
print(f.tell()) # 输出指针位置
line = f.readline() # 读取一行
while line:
print(f.tell())# 输出指针位置
print(line)
line = f.readline()# 读取下一行
ps:
r (默认值)表示从文件读取数据
w 表示要向文件写入数据,并截断以前的内容
a 表示要向文件写入数据,但是添加到当前内容尾部
r+ 表示对文件进行读写操作(删除以前的所有数据)
r+a 表示对文件进行读写操作(添加到当前内容尾部)
b 表示要读写二进制数据(2)从关系型数据库MySQL读取数据
# 配置信息
config = {'host': 'localhost', # 默认localhost == 127.0.0.1
'user': 'root', # 用户名
'password': '******', # 密码
'port': 3306, # 端口,默认为3306
'database': 'rr', # 数据库名称
'charset': 'utf8' # 字符编码
}
# 查询语句
sql = "SELECT * FROM xx" # SQL语句
# 导入pymysql包 需要在命令行窗口写 pip install pymysql
import pymysql
import pandas as pd
# 1. 使用配置参数创建连接
conn = pymysql.connect(**config)
# 2. 用连接获得游标
cursor = conn.cursor()
# 3. 用游标执行sql语句
cursor.execute(sql)
# 4. 通过fetchall方法获得数据
data = cursor.fetchall()
# 5. 遍历数据的前5条
df = pd.DataFrame(list(data))
print(df)
# 6.关闭游标
cursor.close()
# 7.关闭连接
conn.close() (3)获取并解析json数据
import requests # 导入库
# 定义地址
add = '北京市'
# 创建访问应用时获得的AK
ak = 'DdOyOKo0VZBgdDFQnyhINKYDGkzBkuQr'
# 请求URL
url = 'http://api.map.baidu.com/geocoder/v2/?address=%s&output=json&ak=%s'
# 获得返回请求
res = requests.get(url % (add, ak))
# 返回文本信息
add_info = res.text
print(add_info)
import json
add_json = json.loads(add_info)
lng_lat = add_json['result']['location']
print(lng_lat)(4)获取并解析xml数据
import requests # 导入库
# 定义地址
add = '北京市'
# 创建访问应用时获得的AK
ak = 'DdOyOKo0VZBgdDFQnyhINKYDGkzBkuQr'
url = 'http://api.map.baidu.com/geocoder/v2/?address=%s&output=xml&ak=%s'
res = requests.get(url % (add, ak))
add_info = res.text
print(add_info)
# 导入xml中的ElementTree方法
import xml.etree.ElementTree as Etree
# 获得add_info.xml的根节点
root = Etree.fromstring(add_info)
lng = root[1][0][0].text # 获得lng数据
lat = root[1][0][1].text # 获得lat数据
print('lng: %s' % lng) # 格式化打印输出
print('lat: %s' % lat) # 格式化打印输出
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)