试述hadoop生态系统以及每个部分的具体功能_Hadoop入门(一)
Hadoop是一个可靠,可扩展的分布式开源框架,提供海量数据的存储和计算。一般hadoop指的是hadoop生态圈。名字来源于 Doug Cutting 儿子的玩具大象Hadoop是Apache开源组织的一个分布式计算开源框架(http://hadoop.apache.org/),用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop框架中最核...

Hadoop是一个可靠,可扩展的分布式开源框架,提供海量数据的存储和计算。
一般hadoop指的是hadoop生态圈。
名字来源于 Doug Cutting 儿子的玩具大象
Hadoop是Apache开源组织的一个分布式计算开源框架(http://hadoop.apache.org/),用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop框架中最核心设计就是:HDFS和MapReduce,HDFS实现存储,而MapReduce实现原理分析处理,这两部分是hadoop的核心。数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Haddop的集群处理后得到结果,它是一个高性能处理海量数据集的工具 。
预科:
1.什么是分布式?
个人理解,就是将一个系统的功能模块分散部署在不同的服务器上,每个服务器上的系统分别对应一个模块功能,每个模块可能负责几种方法实例,是面向SOA架构(面向服务的架构)的概念,服务器之间通过RPC(Remote Procedure Call 远程过程调用)或者webserver进行交互。
2.什么是SOA架构?
1)面向服务架构,它可以根据需求通过网络对松散耦合的粗粒度应用组件进行分布式部署、组合和使用。服务层是SOA的基础,可以直接被应用调用,从而有效控制系统中与软件代理交互的人为依赖性。
2)从项目角度理解:
比如刚开始有一个项目很小,运作在一台服务器上,系统中包含6个模块,因为数据量很小,所以一台服务器的数据库就可以承载这些数据量。慢慢的,项目越做越大,数据量也越来越大,大到一台服务器的数据库只够装一个模块的数据。这时候就引出了SOA的概念,意思是原先一台服务器负责一个系统的6个模块,现在水平扩展到6台服务器,每台服务器负责一个模块。
3.那么服务器之间想要相互访问对方的模块,服务器之间是如何进行交互的呢?这里引申出RPC的概念(远程过程调用)
1)RPC翻译为远程过程调用,了解远程过程调用之前,需要先知道什么是本地调用。
2)本地调用:
A)从专业角度理解:
比如一个分布式系统中,有6个服务模块,模块1定义了一个计算器接口,实现了一个加法运算,当在模块1这new了一个计算器实例,这时模块1直接调用计算器实例的加法运算产生了一个结果。这个过程就是本地调用。因为计算器实例是创建在模块1的内存或空间地址里,直接通过方法栈或参数栈就能实现。
B)从生活角度理解:
一对情侣在家,女的想要洗衣服,那么只要把衣服丢进洗衣机,然后启动洗衣机就可以了。但是女的突然有事出门了,然后想洗衣服,可是不在家洗不了,但是男的在家,这时候女的就可以给男的打电话让他去洗衣服。这个过程就是RPC过程
补充:
1.RPC的特性
1)透明性:远程调用其他服务器上的程序,就像本地调用一样。不用关心底层的网络传输协议
2)高性能:RPC server服务能够并发处理多个来自client客户端的请求
3)可控性:hadoop有自定义的RPC框架
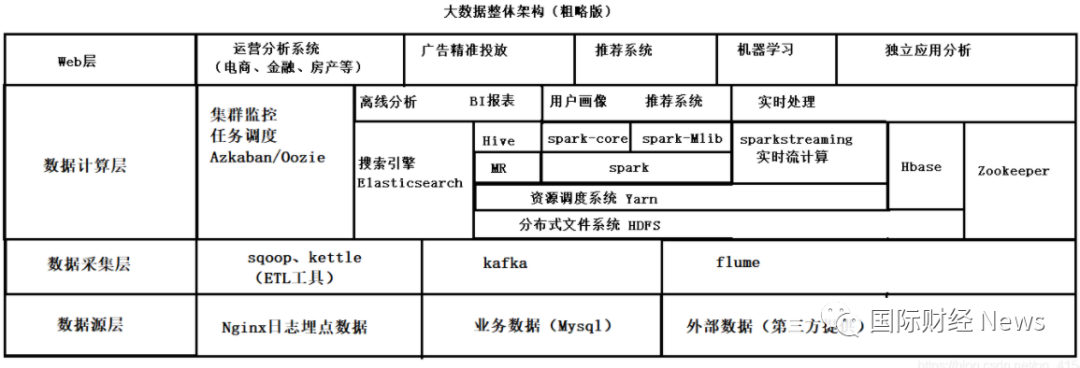
一、hadoop生态系统各个组件及作用
(1) hadoop核心组件:
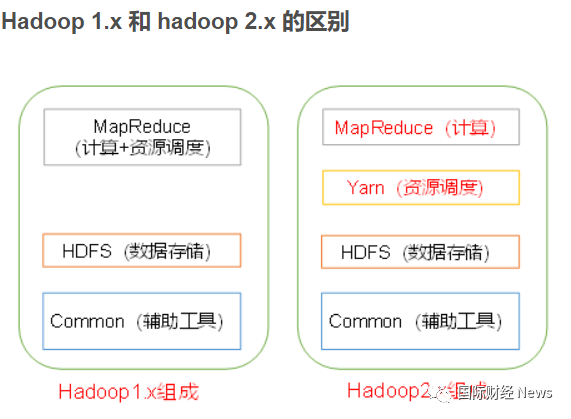
HDFS:高容错、高可靠性、高可扩展性、高吞吐率分布式文件存储系统。负责海量数据的存储。
Yarn:资源管理调度系统。负责hadoop生态系统中任务的调度和监控。
Mapreduce:基于HDFS,Yarn的分布式并行计算框架。负责海量数据的计算。
(2) hadoop其他辅助组件(这里只列举部分):
Flume:是一个分布式可靠的高可用的海量日志收集、聚合、移动的工具,通俗来说flume就是一个日志采集工具。
Sqoop:用于hadoop和结构化数据存储(如关系型数据库,mysql,oracle等RDBMS)之间高效传输批量数据。是一个数据传输工具(也是ETL工具之一)。
(3)服务类:
Zookeeper:分布式协调服务。就是为用户的分布式应用程序提供协调服务,如:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务等等。
(4)离线和实时类:
Hive:基于hdfs,结合类SQL引擎,底层执行MR任务,用于OLAP分析查询的数据仓库。
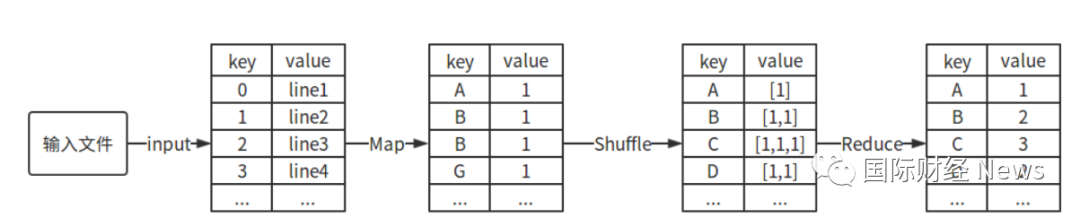
MR : map-reduce思想 先分再合 分而治之
-
map:负责分,所谓的分指的是把大的复杂的任务划分成小的任务,然后并行处理提高效率。
(如果任务不可以拆分或者任务内部存在着依赖关系 这样不适合分而至之) -
reduce:负责合 ,所谓的合指的是把上步分成的小任务结果聚合成最终的结果
两步加起来就是MapReduce思想的体现。
OLAP : 联机分析处理OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。其中F是快速性(Fast),指系统能在数秒内对用户的多数分析要求做出反应;A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部 分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对数据分析的多维视图和分析;I是信息性(Information),指能及时获得信息,并且管理大容量信息。
Hbase:基于hdfs,高可靠性、高性能、列存储、可伸缩、实时读写nosql的数据库系统。
NoSQL:最常见的解释是“non-relational”, “Not Only SQL”也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。
ACID:是指在数据库管理系统(DBMS)中事务所具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
Phoenix:基于hadoop的OLTP业务数据分析SQL引擎。相当于一个Java中间件,提供jdbc连接,操作hbase数据表。
On-Line Transaction Processing联机事务处理过程(OLTP),也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。
(4)任务调度类:
Azkaban:简单来说就是执行任务脚本的调度工具。是在LinkedIn上创建的用于运行Hadoop作业的批处理工作流作业调度程序。通过工作依赖性解决订购问题,并提供易于使用的Web用户界面来维护和跟踪您的工作流程。
Oozie:是一个可靠且可扩展的工作流调度程序系统,用于管理Apache Hadoop作业。
(5)数据分析类:
Kylin:是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,能够在亚秒级查询巨大的Hive表,并支持高并发。
Presto:是一个开放源代码的分布式SQL查询引擎,用于对大小从GB到PB的各种数据源运行交互式分析查询。
Zepplin:基于Web界面组合多个大数据分析引擎的处理能力的大数据交互分析服务软件。
(6)计算引擎类:
Mapreduce(分布式计算):基于HDFS,Yarn的分布式并行计算框架。负责海量数据的计算。
Tez(DAG计算):基于Yarn,允许使用复杂的有向无环图来处理数据的计算引擎。计算速度高于Mapreduce。
Spark(内存计算):是一个快速的,通用的集群计算系统。它对 Java,Scala,Python 和 R 提供了的高层 API,并有一个经优化的支持通用执行图计算的引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的 Spark SQL,用于机器学习的 MLlib,用于图计算的 GraphX 和 Spark Streaming。计算速度高于Mapreduce。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)