spark读取shp文件_Spark本地环境实现wordCount单词计数
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6814778610788860424/编写类似MapReduce的案例-单词统计WordCount要统计的文件为Spark的README.md文件分析逻辑:1. 读取文件,单词之间用空格分割2. 将文件里单词分成一个一个单词3. 一个单词,计数为1,采用二元组计数word ->(word,1)4. 聚合统计每

注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6814778610788860424/
编写类似MapReduce的案例-单词统计WordCount
要统计的文件为Spark的README.md文件

分析逻辑:
1. 读取文件,单词之间用空格分割
2. 将文件里单词分成一个一个单词
3. 一个单词,计数为1,采用二元组计数word ->(word,1)
4. 聚合统计每个单词出现的次数
RDD的操作
1.读取文件:
sc.textFile("file:///opt/modules/spark/README.md")注意:textFile里面的路径,如果没有指定schema,那么默认的话是从HDFS文件系统读取数据,如果不加file://就是/opt/modules/spark/README.md的路径,是从HDFS对应目录下读取
接收变量是res0

res0方法查看
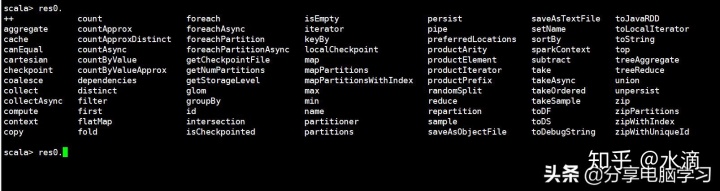
可以用一个变量接收

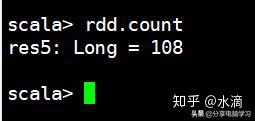
rdd.count-->统计RDD里有多少条数据
rdd.first--> 取RDD的第一条数据
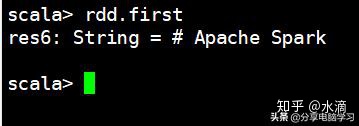
可以对比源文件看到第一条数据
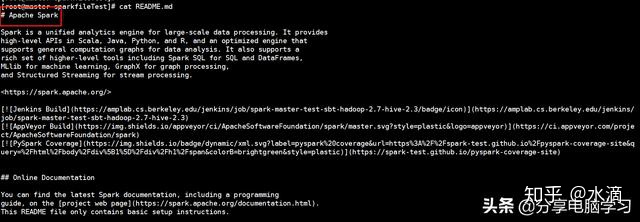
rdd.take(10)--> 取RDD的前10条数据,也可以对比源文件查看

2. 将文件中的数据分成一个一个的单词
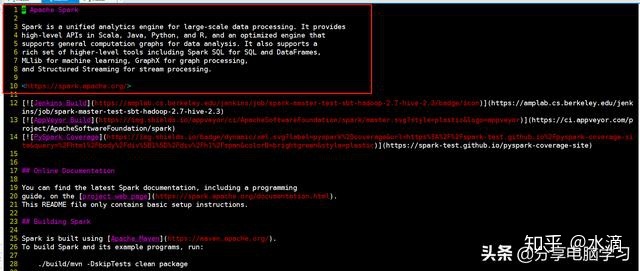
map和flatMap返回类型不一致,返回结果类型是RDD[String]和RDD[Array[String]]
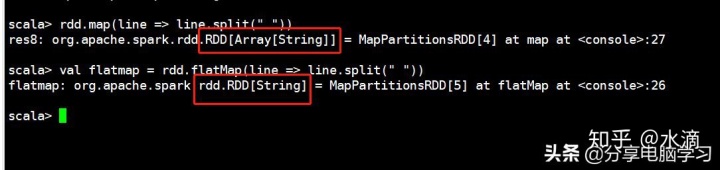
可以使用collect方法,查看结果
变量名
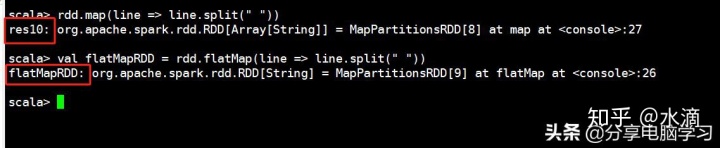
collect方法
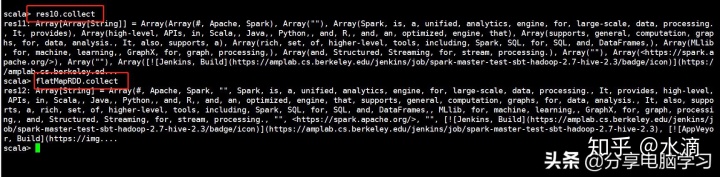
map和flatMap返回结果的不同之处:flatMap会进行扁平化操作
mapRDD = rdd.map(line => line.split(" "))
第一个元素:Array("#","Apache","spark")

第三个元素:Array("Spark","is")

flatmapRDD = rdd.flatMap(line => line.split(" "))
第一个元素:"#"

所以我们选择flatMap,而不是map
val flatMapRDD = rdd.flatMap(line => line.split(" "))
//flatMapRDD: org.apache.spark.rdd.RDD[String]
去除空的字符串的操作
flatMapRDD.filter(word => word.nonEmpty)
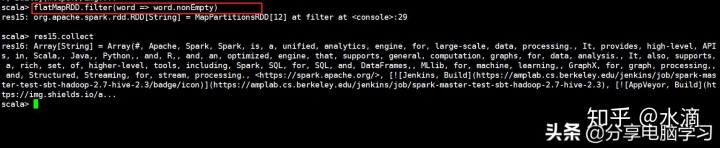
3. 将每个单词进行计数
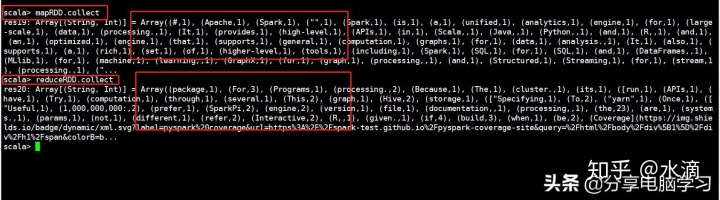
val mapRDD = flatMapRDD.map(word => (word,1))

返回类型//mapRDD: org.apache.spark.rdd.RDD[(String, Int)]

4.将相同的单词放在一起进行value值得聚合
val reduceRDD = mapRDD.reduceByKey((a,b) => a + b)
//reduceRDD: org.apache.spark.rdd.RDD[(String, Int)]

查看对比下(reduceByKey前后两个变量的collect)
链式编程写法:
val result = sc.textFile("file:///opt/modules/o2o23/spark/README.md").flatMap(line => line.split(" ")).filter(word => word.nonEmpty).map(word => (word,1)).reduceByKey((a,b) => a + b).collect
链式编程简化写法:
val result1 = sc.textFile("file:///opt/modules/o2o23/spark/README.md").flatMap(_.split(" ")).filter(_.nonEmpty).map((_,1)).reduceByKey(_+_).collect

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)