python dataframe取某行某列_Python数据分析基础
利用Python进行数据分析过程首先要学会写代码,通过代码将数据分析的思路一步步实现。
通过药店销售案例练习Python数据分析时常用代码:
一、提出问题
从销售数据中分析出以下业务指标:
1、月均消费次数
2、月均消费金额
3、客单价
4、消费趋势
二、理解数据
1、数据导入
由于药店销售数据的格式是excel,因此需要先安装一个读取excel文件的依赖包:xlrd,安装步骤如下:
- 先conda中进入当前notebook文件所在的python环境,命令为:activate py3
- 再在pyhon环境下安装xlrd包,命令为:conda install xlrd
数据导入过程及代码如下:
(1)导入数据包

(2)读取excel数据
- 先读取Excel数据,统一先按照字符串读入,之后转换;
- 再定义一个Excel文件,用xls.parse解析Sheet1的内容。

(3)检查数据正常与否
- 函数:head(),默认前5行;
- 打印出前5行,以确保数据运行正常。

2、理解数据
(1)数据大小
- 函数:shape(),数据大小(行数,列数)。

(2)列字段名称及数据类型
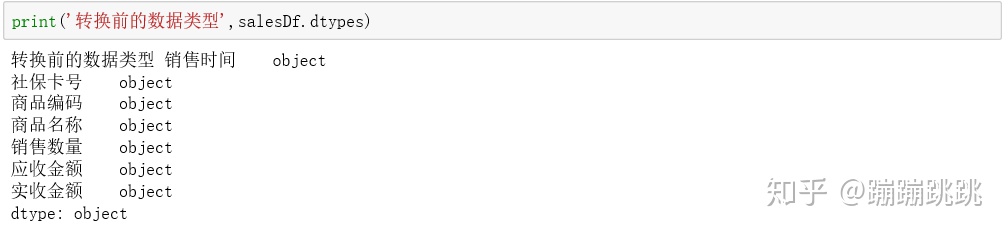
- 函数:dtypes,查看每一列的数据类型。

三、数据清洗
数据分析过程中数据清洗过程如下:

(1)选择子集(切片)
该案例不需要选择子集。

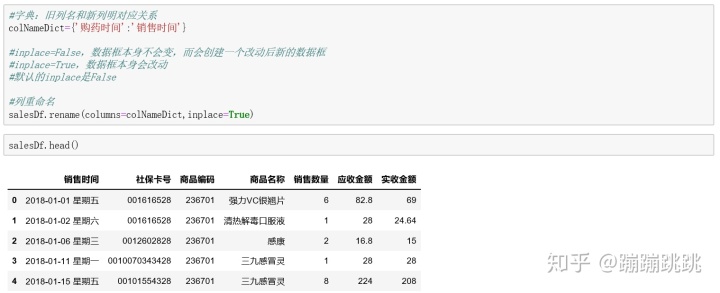
(2)列重命名
- 函数:colNameDict={A:B}(字典),将A用B进行替换;
- 函数:inplace,默认是False,inplace=False说明数据框本身不会变,而会创建一个改动后新的数据框;inplace=True,说明数据框本身会改动。
- 函数rename:重命名函数
(3)缺失数据处理
- 函数:dropna,删除缺失值,详细使用网址如下:
pandas.DataFrame.dropna - pandas 0.23.4 documentation
- 删除列(销售时间,社保卡号)中为空的行代码如下:

注意:运行数据时,如果遇到u错误:说什么foloat错误,那就是有缺失值,需要处理的。
Python缺失值有3种,None、NA、NaN:
1)Python内置的None;
2)在pandas中,将缺失值表示为NA,表示不可用not available;
3)对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据;
(4)数据类型转换
- astype函数:字符串转换成数值(浮点型)
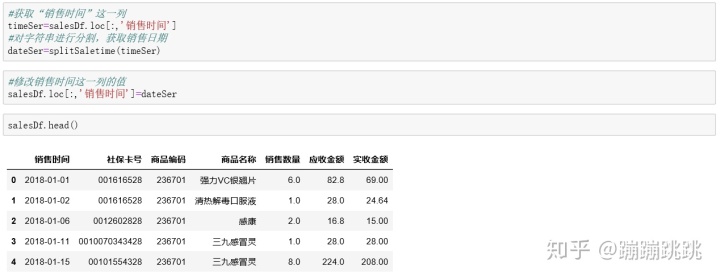
- split函数:字符串分隔,字符串转换为日期数据类型
①字符串转换为数值(浮点型)

②字符串格式的日期转换为数值型日期

注意:①因为Excel中的空的cell读入pandas中是空值(NaN),这个NaN是个浮点类型,一般当作空值处理,所以要先去除NaN再进行分隔字符串。
②上述第3步尤为重要,一定要记得将原始数据字符串格式日期转换成正常的数据日期,否则会影响后面建模。
(5)数据排序
- 函数:.sort(),排序
- ascending=True 表示升序排列
- ascending=False表示降序排列
- na_position='First'表示排序的时候,把空值放到前列,这样可以比较清晰的看到哪些地方有空值
- 函数:by(),按哪几列排序
Pandas官网sort函数学习网址:pandas.DataFrame.sort_values - pandas 0.23.4 documentation
排序代码如下:
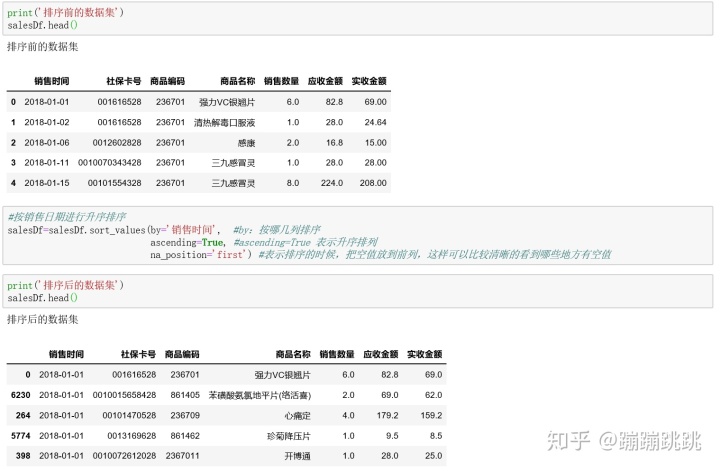
注意:由于排序后的列索引值是之前的行号,需要修改成从0到N按顺序的索引值,因此重命名行名(index)代码如下:
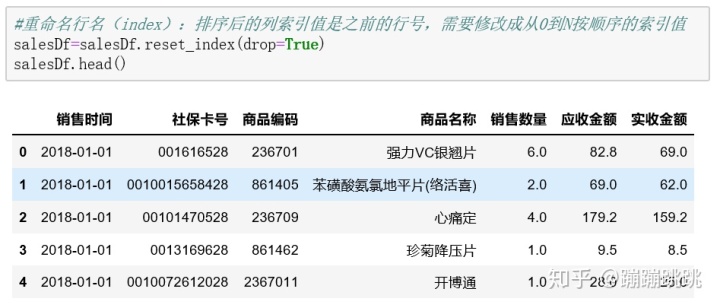
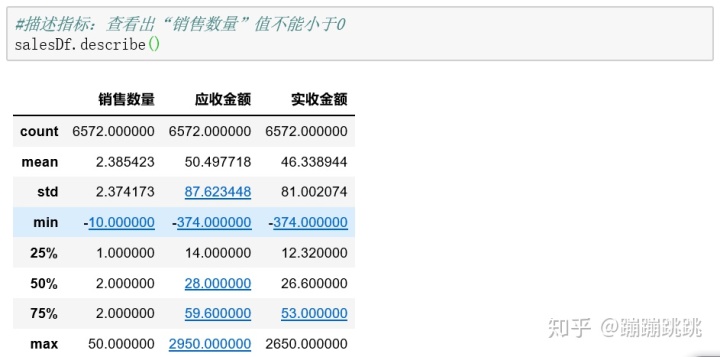
(6)异常值处理
- 函数:describe(),描述指标,查看出“销售数量”值不能小于0
①查询异常值
②删除异常值

四、构建模型
1、业务指标:月均消费次数=总消费次数 / 月份数
- 总消费次数:同一天内,同一个人发生的所有消费算作一次消费;
- 根据列名(销售时间,社区卡号),如果这两个列值同时相同,只保留1条,将重复的数据删除;
- 函数:drop_duplicates,对DataFrame格式的数据,删除重复行。

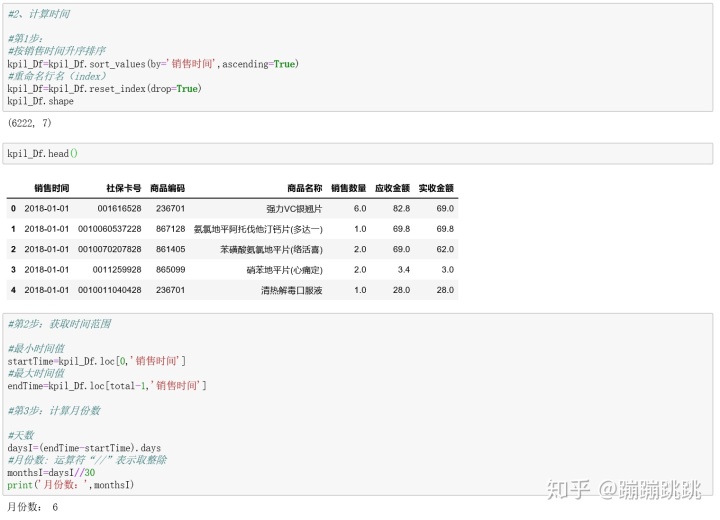

2、业务指标:月均消费金额 = 总消费金额 / 月份数

3、业务指标:客单价=总消费金额 / 总消费次数
客单价(per customer transaction)是指商场(超市)每一个顾客平均购买商品的金额,客单价也即是平均交易金额。

4、业务指标:消费趋势,画图-折线图
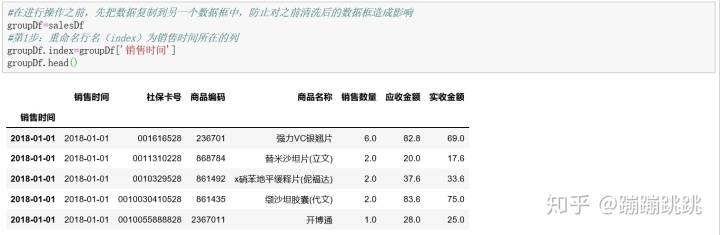
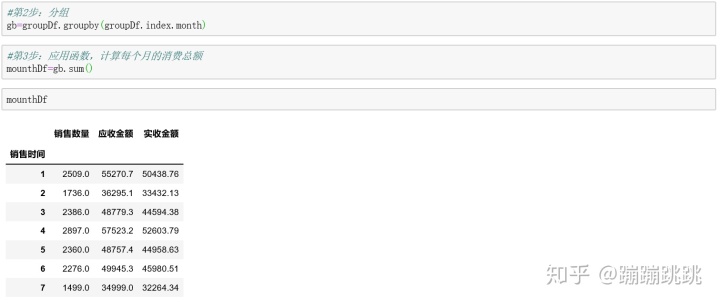
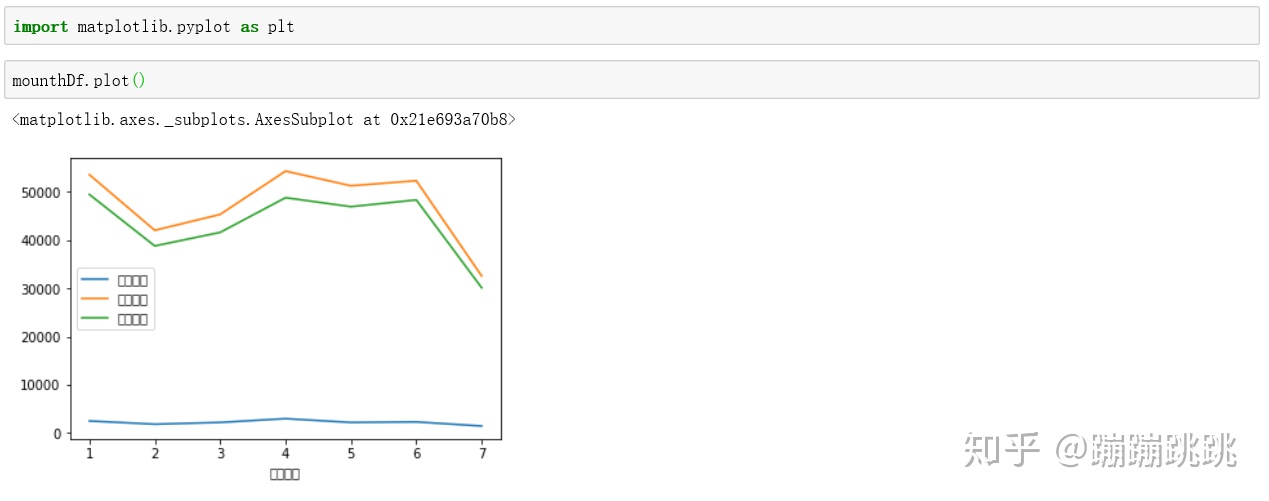
接下来对Python数据分析过程中常用的基础知识总结如下:
一、一维数组
(一)numpy处理一维数组(Array)
(1)定义
a=np.array([1,2,3,4,5])
(2)多种查询方式
A.单个序号查询——a[num]
B.切片范围序号查询——a[num1:num2] (查询从num1到num2范围之间的数值)
C.数据类型dtype查询——a.dtype
(3)for i in a 循环
(4)numpy数组和列表的区别
1)可进行统计参数计算
——可计算Mean、std、max、min值(不能计算count)
2)可进行向量化计算
a=np.array([1,2,3,4,5])
b=np.array([1,2,3,4,5])
c=a*b (可使用各项add/sub/mul/div计算)
(二)pandas处理一维数组(Series)
(1)定义(Index为索引)
stockS=pd.Series([num1,num2,num3],
index=[‘name1’,’name2’,’name3’])
输出dtype数据类型映射的是数值类型(int/float),而非Index数据类型
(2)获取描述统计信息(与上一关pandas包使用相同)
stockS.describe()
(3)iloc属性用于根据数值序号获取数值(i表示interger,loc表示location)
stockS.iloc[num]
(4)loc属性用于根据索引获取值
stockS.loc[‘name1’]
(5)向量化计算(可适用于加减乘除-add,sub,mul,div)
涉及:删除索引不符的缺失值 s3.dropna()
将缺失值进行填充 s3=s1.add(s2,fill_value=0)
(将s1,s2中相应缺失值均赋值为0, 之后相加)二、二维数组
(一)numpy处理二维数组(Array)
(1)定义
a=np.array([[1,2,3],[4,5,6],[7,8,9]]
(2)多种查询方式
A. 单个数据查询——a[row,column]
B. 某行数据查询——a[row,:]
C. 某列数据查询——a[:,column]
(3)数轴参数
按轴计算:axis=0为按列计算,axis=1为按行计算
例如:a.mean(axis=1) (按行计算均值)
(二)pandas处理二维数组(DataFrame)
(1)定义数据框
1)先定义一个无序字典(salesDict),映射列名和值
2)导入有序字典,从无序转化成有序
salesOrderedDict=OrderedDict(salesDict)
3)定义数据框
salesDf=pd.DataFrame(salesOrderedDict)
(2)用iloc属性获取值
A.单个查询salesDf.iloc[row,column]
B.某行查询salesDf.iloc[row,:]
C.某列查询salesDf.iloc[:,column]
(3)用loc属性根据索引获取值
A.单个查询salesDf.loc[row,’映射名称’]
B.某行查询salesDf.loc[row,:] (同iloc一样,因为此时name:0序号即为映射行名称)
C.某列查询salesDf.loc[:,’映射列名称’] 或salesDf.loc[‘映射列名称’]
D.多列查询salesDf[[’映射列名称1’,’映射列名称2’]]
E.切片查询salesDf.loc[row1:row2,’映射列名称1’:’映射列名称2’] (获取名称1到2范围内的列, row1到row2范围的行)
(4)条件筛选
1)构建查询条件
[In] querySer=salesDf.loc[:,’销售数量’]>1
[In] type(querySer)
[Out] #显示pandas一维数组形式series
pandas.core.series.Series
[In] querySer
[Out] #输出该列的每一个数值是否符合条件判断,用布尔值表现(True/False)
Name:销售数量(映射列名)
2)应用条件查询
[In] salesDf.loc[querySer,:] #按行进行判断,所以querySer写在行数上
[Out] #显示出符合筛选条件的salesDf完整数据(而不仅仅是映射列)
(5)数据集描述统计信息
1)读取Excel数据:pd.ExcelFiles+parse
2)查看数据前几行 salesDf.head(num) (num表示前多少行)
3)查看某列的数据类型 salesDf.dtype()
4)查看行数,列数 salesDf.shape(输出:(行数,列数))
5)每一列的统计数 salesDf.describe()三、数据分析的基本过程
1)提出问题 (目的)
2)理解数据 (理解+描述)
3)数据清洗 (预处理)
4)构建模型 (业务指标/机器学习训练模型)
5)数据可视化 (图表展示)
(1)提出问题(略)
(2)理解数据
1)读取Excel数据:pd.ExcelFiles+parse(统一按string读入,后期进行转换,
dtype=’object’)
2)查看数据前几行 salesDf.head(num) (num表示前多少行)
3)查看某列的数据类型 salesDf.dtype()
4)查看行数,列数 salesDf.shape (输出:(行数,列数))
5)每一列的统计数 salesDf.describe()
(3)数据清洗
1)选择子集 (使用loc切片功能筛选范围/子集)
2)列名重命名
(设置旧列名和新列名的映射关系colNameDict,使用salesDf.rename(columns=colNameDict,inplace=True) True为数据库本身会改动,False则不会
3)缺失数据处理 (有删除/机器差值处理两种处理方式)
salesDf.dropna(subset=[‘映射列1’,’映射列2’],how=’any’)
(subset为删除制定列的列表,how指定如何删除数据,how=’any’只要在给定的列表中有缺失则删除数据)
4)数据类型转换
A.字符串转换为数值浮点数 salesDf[‘映射列’].astype(‘float’)
B.字符串分割 ‘Str str’.split(‘ ‘) (即用空格 分割字符串)
C.定义函数完成所有函数的数据类型转换
C-1: 分割字符串
#通过自定义函数splitsaletime批量将所有销售时间字符串分割 timeSer=salesDf['销售时间'] dateSer=splitSaletime(timeSer)
timeSer=salesDf.loc[:,’销售时间’] #获取销售时间这一列字符串数据
dateSer=splitSaletime(timeSer) #使用自定义函数splitSaletime分割字符串
salesDf.loc[:,’销售时间’]=dateSer #将原来带星期的值更换为不带星期的值dateSer
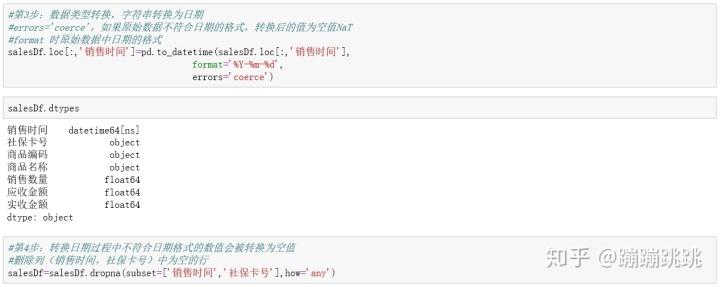
C-2: 字符串转为日期浮点数据类型
salesDf.loc[:,’销售时间’]=pd.to_datetime(salesDf.loc[:,’销售时间’],
format=’%Y-%m-%d’,errors=’coerce’)
#使用pd.to_datetime来转换数据格式
#errors=’coerce’ 表示如果原始数据不符合日期格式,转换后的值将变为NaN
#format是原始数据中日期的格式’%Y-%m-%d’
salesDf=salesDf.dropna(subset=[’销售时间’,社保卡号’],how=’any’)
#转换日期过程中不符合日期格式的数值会被转换为空值,
这里删除列(销售时间,社保卡号)中为空的行
#dtypes之后日期数据转换成datetime64[ns]
5)数据排序
salesDf=salesDf.sort_values(by=’销售时间’,ascending=True)
#by:按哪行进行排序
#ascending=True表示降序排列,第一行为最前的日期,=False表示升序排列
salesDf=salesDf.reset_index(drop=True)
#对行号索引进行重命名
#drop=True表示会丢弃原来的索引而设置新的从0开始的索引
6)异常值处理
A.通过描述统计量来判断异常
B.通过条件判断筛选出数据
(4)构建模型(略)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)