hive olap 数据仓库_电商复购分析建模hive+spark使用案例
前言
记得10年前看过本书《数据仓库与数据挖掘》,反正文字很多,也没记得多少,那就是数据库和数据仓库之类的介绍,我们大部分时候比较难接触,然后传统数据仓库还没摸到,好吧大数据时代来了,多了非常多新鲜概念,当然这时候也很多都是各方的技术,也有不少开源的,也给我们学习和应用提供了便利。要是现在这本书应该会非常厚了。 不过还是先抄点废话吧,整体把握下就好数据库
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作。——百度百科
数据集市
是企业级数据仓库的一个子集,他主要面向部门级业务,并且只面向某个特定的主题,按照多维的方式进行存储,包括定义维度需要计算的指标维度的层次等,生成面向决策分析需求的数据立方体。——wikipedia
数据仓库
是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合用于支持管理决策。其主要功能是将组织透过资讯系统之联机事务处理(OLTP)经年累月所积累的大量资料,透过数据仓库理论所特有的资料存储架构,作一有系统的分析整理,以利各种分析方法如联机分析处理(OLAP)、数据挖掘(Data Mining)之进行,并进而支持如决策支持系统(DSS)、主管资讯系统(EIS)之创建,帮助决策者能快速有效的自大量资料中,分析出有价值的资讯,以利决策拟定及快速回应外在环境变动,帮助构建商业智能(BI)。——《Building the data warehouse》W.H.Inmon
数据湖
数据湖是以其自然格式存储的数据的系统或存储库,同行是对象blob或文件。数据湖通常是企业所有数据的单一存储,包括源系统数据的原始副本,以及用于报告、可视化、分析和机器学习等任务的转换数据。数据湖可以包括来自关系数据库(行和列)的结构化数据,半结构化数据(CSV,日志,XML,JSON),非结构数据(电子邮件、文档、PDF)和二进制数据(图像、音频、视频)。——wikipedia
数据中台
“以全域大数据建设为中心,技术上覆盖整个大数据从采集、加工、服务、消费的全链路的各个环节,对内对外提供服务。丰富的大数据生态组件,构成了阿里的核心数据能力,通过大数据生态组件,可以迅速的提升数据应用的迭代能力,人人都有可能成为大数据专家。”——《阿里巴巴全域数据建设》,阿里巴巴数据技术及产品部高级技术专家张磊,2017杭州云栖大会-阿里大数据分论坛
“数据中台是聚合和治理跨域数据,将数据抽象封装成服务,提供给前台以业务价值的逻辑概念。”——《数据中台已成下一风口,它会颠覆数据工程师的工作吗?》,ThoughtWorks数据和智能总监史凯
数据仓库和数据集市
数据集市一般是面向某个主题域,比如营销主题,那么会关联某几个部门,数据集市一般使用维度建模。

数据仓库VS数据湖
数据湖是较为新的概念,也是新技术,架构也在实践中不断演变,数据湖主要是为了适合大数据时代带来的多样和多种类型数据带来的问题,数据湖存储任何形式(包括结构化和非结构化)和任何格式(包括文本、音频、视频和图像)的原始数据。根据定义,数据湖不会接受数据治理,但专家们都认为良好的数据管理对预防数据湖转变为数据沼泽不可或缺。数据湖在数据读取期间创建模式。与数据仓库相比,数据湖缺乏结构性,而且更灵活;它们还提供了更高的敏捷性。值得一提的是,数据湖非常适合使用机器学习和深度学习来执行各种任务,比如数据挖掘和数据分析,以及提取非结构化数据等。

数据仓库VS数据中台

离线数据仓库hive
hive英文是蜂箱的意思,也是指仓储地方,忙碌的地方,这里比喻的是数据仓库是数据的集中地方,而且很多查询报表都在这里进行,相当繁忙。

hive是基于Hadoop的离线数据仓库,底层是将数据存储在Hadoop的HDFS上,一般Hadoop编程需要进行mapper reduce 将查询语句转为分布式查询,hive就是简化和封装了这一个过程,使得我们应用开发者可以直接使用类似SQL的查询语句,hive做中间转换,然后转给Hadoop,Hadoop将查询结果返回hive。
首先我们了解下数据仓库,数据仓库与数据库不同的是不满足第三范式,也就是有很多冗余,因为是为了数据挖掘做的。数据挖掘可以很好地直接调取里面的宽表,也很容易在上面进行多维分析,探索分析等。
数据仓库里主要分为事实表和维度表,事实表比如一个销售数据,一个订单数据,维度表就是看问题的角度,就像用户窗口,比如你可以关注用户维度,也可以看地区,也可以关注产品或是时间维度。
hive是基于大数据Hadoop平台的,所以类似很多大数据平台特点,不善于update,主要是查询,也符合数据仓库的特点。所以它主要为数据仓库的管理提供了许多功能:数据 ETL (抽取、转换和加载)工具、数据存储管理和大型数据集的查询和分析能力。
Hive 体系结构
hive是Hadoop大家庭的一员,架构主要由以下组成

用户接口,包括 CLI, JDBC/ODBC, WebUI
元数据存储,通常是存储在关系数据库如 MySQL, Derby 中
另外核心驱动引擎有四个组成
解释器:主要将hiveSQL转为抽象语法树(AST)
编译器:将语法树转为逻辑执行计划(类似oracle等数据库执行计划)
优化器:主要优化逻辑执行计划
执行器:执行器就是最终执行者,调用底层框架执行执行计划。
Hadoop, 用 HDFS 进行存储,利用 MapReduce 进行计算
所以学习前最好先学Hadoop HDFS 至少搭建好Hadoop集群并熟悉基本操作,然后还有基本了解Java可以看一些报错和一般的MapReduce程序。
hive应用场景
因为是基于Hadoop分布式文件系统,所以和数据库基于本地文件不同,
数据库主要是为了实时业务查询,而 Hive 则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致 Hive 的应用场景和关系数据库有很大的不同;而且hive有很好的扩展存储和计算能力。
Hive 并不提供实时的查询和基于行级的数据更新操作;
hive主要是在大规模批处理等场景,比如:网络日志分析,系统日志分析等。
还有海量结构化数据离线分析、多维分析等。
Hive 的数据存储
由于是在Hadoop文件系统上,hive没有特殊的数据格式也无法建立索引,但是可以方便的读取文本文件,通过分隔符解析数据,比如csv文件可以直接导入。
hive文件包括4种数据模型:表(table),外部表(external table ),分区(partition)以及桶(bucket)
在 Hive 中每个表都有一个对应的存储目录。而外部表指向已经在 HDFS 中存在的数据,也可以创建分区。Hive 中的每个分区都对应数据库中相应分区列的一个索引,但是其对分区的组织方式和传统关系数据库不同。桶在指定列进行 Hash 计算时,会根据哈希值切分数据,使每个桶对应一个文件。
Hive 的元数据存储
由于 Hive 的元数据可能要面临不断地更新、修改和读取操作,所以它显然不适合使用 Hadoop 文件系统进行存储。目前 Hive 把元数据存储在 RDBMS 中,比如存储在 MySQL, Derby 中。这点我们在上面介绍的 Hive 的体系结构图中,也可以看出。
docker 搭建集群
最简部署,Hadoop集群一个主一个数据节点,
docker-compose文件
version: "3"
services:
namenode: #Hadoop namenode节点
image: bde2020/hadoop-namenode:2.0.0-hadoop2.7.4-java8
volumes:
- namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop-hive.env
ports:
- "50070:50070"
datanode: #Hadoop DataNode节点
image: bde2020/hadoop-datanode:2.0.0-hadoop2.7.4-java8
volumes:
- datanode:/hadoop/dfs/data
env_file:
- ./hadoop-hive.env
environment:
SERVICE_PRECONDITION: "namenode:50070"
ports:
- "50075:50075"
hive-server:
image: bde2020/hive:2.3.2-postgresql-metastore
env_file:
- ./hadoop-hive.env
environment:
HIVE_CORE_CONF_javax_jdo_option_ConnectionURL: "jdbc:postgresql://hive-metastore/metastore"
SERVICE_PRECONDITION: "hive-metastore:9083"
ports:
- "10000:10000"
hive-metastore: #元数据服务
image: bde2020/hive:2.3.2-postgresql-metastore #使用postgresql存储元数据
env_file:
- ./hadoop-hive.env
command: /opt/hive/bin/hive --service metastore
environment:
SERVICE_PRECONDITION: "namenode:50070 datanode:50075 hive-metastore-postgresql:5432"
ports:
- "9083:9083"
hive-metastore-postgresql: #数据库服务
image: bde2020/hive-metastore-postgresql:2.3.0
presto-coordinator: #客户端 ,可以连接hive查询
image: shawnzhu/prestodb:0.181
ports:
- "8080:8080"
volumes: #存储卷先定义
namenode:
datanode:可参考 https://github.com/big-data-europe/docker-hive
导入数据到docker
docker cp /tmp/data docker-hive_hive-server_1:/opt/hive/登录hive查看
docker-compose exec hive-server bash/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000电商复购分析建模案例
说明
根据给定数据,使用分布式集群进行建模分析,建模过程主要涉及组建为Hive和Spark,
案例是接近现有某大型电商平台用户购买数据,考虑存储在分布式系统里用大数据框架进行分析,要求从相关数据中分析并挖掘存在重复购买可能性的用户,即用户二次购买行为预测分析。同时,为了保证分析过程完整性,要求利用Hive进行一定程度的数据预处理和数据探索。
三份数据,数据名分别为users.csv,train.csv,test.csv, 字段如下:
-
User_id:买家ID
-
Item_id:商品ID
-
Cat_id:商品类别
-
Merchant_id:卖家ID
-
Brand_id:品牌ID
-
Month_id:交易月份
-
Day:交易日期
-
Action:交易行为,0表示点击、1表示加入购物车、2表示购买、3表示关注商品
-
Age_range:卖家年龄分段,1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知;
-
Gender:0表示女性、1表示男性,2和NULL表示未知
-
Province:收获地址省份
hive统计
先建数据库 cda2
/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000
0: jdbc:hive2://localhost:10000> create database if not exists shop;
建立user表
CREATE TABLE shop.users (user_id INT ,item_id INT ,cat_id INT ,merchant_id INT ,brand_id INT ,month INT ,day INT ,action INT ,age_range INT ,gender INT ,province STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE tblproperties("skip.header.line.count"="1");
中文编码
ALTER TABLE shop.users SET SERDEPROPERTIES ('serialization.encoding'='GBK');
导入数据
LOAD DATA LOCAL INPATH '/opt/hive/data/users.csv' OVERWRITE INTO TABLE shop.users;
查询前5行数据
select * from shop.users limit 5;
查询users.csv 表结构
desc shop.users;
+--------------+------------+----------+
| col_name | data_type | comment |
+--------------+------------+----------+
| user_id | int | |
| item_id | int | |
| cat_id | int | |
| merchant_id | int | |
| brand_id | int | |
| month | int | |
| day | int | |
| action | int | |
| age_range | int | |
| gender | int | |
| province | string | |
+--------------+------------+----------+
查表的详细信息
desc formatted shop.users;
查看数据总量
select count(*) from shop.users;
使用distinct方法查询不重复数据数量
select count(distinct user_id ,item_id,cat_id ,merchant_id,brand_id,month,day ,action,age_range,gender) from shop.users;
如果能用group by的就尽量使用group by,因为group by性能更好
查询双十一当天发生购买行为的顾客数量
Select count(distinct(user_id)) from shop.users where month=11 and day=11 and action =1;
spark应用建模
用spark写入hive
from pyspark import SparkConf, SparkContext
from pyspark.sql import HiveContext
spark = SparkSession\
.builder \
.appName("Spark to Hive") \
.master("spark://master:7077")\
.config("hive.metastore.uris", "thrift://*.*.*.*:9083") \ #这里用自己Ip
.enableHiveSupport()\
.getOrCreate()
#sparkSession.read.option("header", "true").csv("src/main/resources/scala.csv")
df = spark.read.csv("data/train.csv") # 把csv读成dataframe
## 其他参数
# schema – an optional pyspark.sql.types.StructType for the input schema.
# header:默认值是false。就是把第一行当做数据,改为false,第一行就变为字段;
# sep:默认情况下,CSV是使用英文逗号分隔的,其他分隔符号可修改此选项;
# 拼接一个字段类型字符串
str_s = 'label String,'
for i in range(len(df.columns)-1):
str_s += 'pixel%s INT,' % i
# 拼接SQL语句
sql_str = "create table shop.train ({})".format(str_s[:-1])
spark.sql(sql_str) # 执行SQL
df.write.insertInto('shop.train', overwrite=False) # 将dataframe写入到指定hive表开始的SparkConf和SparkContext,HIveContext,SQLContext都是2.0之前的上下文环境对象,也就是spark要先建立这些上下文对象,使得可以使用对应的API操作集群资源。
2.0的sparksession相当于对这些对象的封装,使得大家不要再显示调用这些上下文,最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与Spark交互。
数据预处理
#读取数据
from pyspark.sql import SparkSession
spark=SparkSession.builder.appName("dataframe").getOrCreate()
sc = SparkContext.getOrCreate()
train = spark.read.csv(r"data/train.csv",header=True,inferSchema=True)
test = spark.read.csv(r"data/test.csv",header=True,inferSchema=True)
train.show(5)
+-------+---------+------+-----------+-----+
|user_id|age_range|gender|merchant_id|label|
+-------+---------+------+-----------+-----+
| 34176| 6| 0| 944| -1|
| 34176| 6| 0| 412| -1|
| 34176| 6| 0| 1945| -1|
| 34176| 6| 0| 4752| -1|
| 34176| 6| 0| 643| -1|
+-------+---------+------+-----------+-----+
only showing top 5 rows
train.printSchema()
root
|-- user_id: integer (nullable = true)
|-- age_range: integer (nullable = true)
|-- gender: integer (nullable = true)
|-- merchant_id: integer (nullable = true)
|-- label: integer (nullable = true)
train.groupBy('age_range').count().show()
+---------+-------+
|age_range| count|
+---------+-------+
| null| 19380|
| 1| 286|
| 6| 655922|
| 3|1913722|
| 5| 752927|
| 4|1459923|
| 8| 20290|
| 7| 124493|
| 2| 731938|
| 0|1351842|
+---------+-------+train.groupBy('gender').count().show()
+------+-------+
|gender| count|
+------+-------+
| null| 61712|
| 1|1618110|
| 2| 249171|
| 0|5101730|
+------+-------+train.groupBy('merchant_id').count().show()
+-----------+-----+
|merchant_id|count|
+-----------+-----+
| 4818| 3707|
| 496| 1149|
| 3749| 1157|
| 1580| 3298|
| 1645| 432|
| 471| 3524|
| 4519| 828|
| 3918| 1894|
| 148| 3058|
| 1238| 967|
| 3997| 3762|
| 1342| 1262|
| 3794| 553|
| 1088| 1032|
| 2122| 1162|
| 1591| 724|
| 833| 299|
| 3175| 1312|
| 2366| 1022|
| 463| 851|
+-----------+-----+
only showing top 20 rowstrain.groupBy('label').count().show()
+-----+-------+
|label| count|
+-----+-------+
| -1|6769859|
| 1| 15952|
| 0| 244912|
+-----+-------+
train.filter(isnull('merchant_id')).show()
+-------+---------+------+-----------+-----+
|user_id|age_range|gender|merchant_id|label|
+-------+---------+------+-----------+-----+
+-------+---------+------+-----------+-----+
这里看基本都是处理好的数据,为了简化age_range ,gender只用确定的,空值不用,merchant都是相当于分好类的特征, 而label我们看是不平衡的数据 ,为简化直使用逻辑回归。
train.where(train['age_range']>0).count()
5659501
train1 = train.where(train['age_range']>0)
train2 = train1.where(train1['gender']<2)
train3 = train2.where(~(train2['label']==-1))
#特征
features = list(set(train.columns)-set(['label','user_id']))
features
['gender', 'age_range', 'merchant_id']
from pyspark.ml.feature import OneHotEncoder
from pyspark.ml import Pipeline
##创建OneHotEncoder对象,设定输入输出参数
categoryFeaturesIndex = ['age_range','merchant_id']
pipeline = Pipeline(stages=[
OneHotEncoder(inputCol=c, outputCol='{}_vec'.format(c))
for c in categoryFeaturesIndex
])
onehot = pipeline.fit(train3)
encodeData = onehot.transform(train3)
encodeData.show()
#去除无用特征列
print(encodeData.columns)
use_data = encodeData.select([ 'age_range_vec', 'merchant_id_vec', 'gender','label'])
use_data.printSchema()
'user_id', |-- label: integer (nullable = true)#特征归并到一列
from pyspark.ml.feature import VectorAssembler #一个 导入VerctorAssembler 将多个列合并成向量列的特征转换器,即将表中各列用一个类似list表示,输出预测列为单独一列。
assembler = VectorAssembler(inputCols=['age_range_vec', 'merchant_id_vec', 'gender'],outputCol="features")
trainset = assembler.transform(use_data)
trainset.printSchema()
trainset.show(10,False)
root
|-- age_range_vec: vector (nullable = true)
|-- merchant_id_vec: vector (nullable = true)
|-- gender: integer (nullable = true)
|-- label: integer (nullable = true)
|-- features: vector (nullable = true)
+-------------+-------------------+------+-----+----------------------------------+
|age_range_vec|merchant_id_vec |gender|label|features |
+-------------+-------------------+------+-----+----------------------------------+
|(8,[6],[1.0])|(4993,[3906],[1.0])|0 |0 |(5002,[6,3914],[1.0,1.0]) |
|(8,[6],[1.0])|(4993,[121],[1.0]) |0 |0 |(5002,[6,129],[1.0,1.0]) |
|(8,[6],[1.0])|(4993,[4356],[1.0])|0 |1 |(5002,[6,4364],[1.0,1.0]) |
|(8,[6],[1.0])|(4993,[2217],[1.0])|0 |0 |(5002,[6,2225],[1.0,1.0]) |
|(8,[4],[1.0])|(4993,[2618],[1.0])|1 |0 |(5002,[4,2626,5001],[1.0,1.0,1.0])|
|(8,[5],[1.0])|(4993,[2051],[1.0])|0 |0 |(5002,[5,2059],[1.0,1.0]) |
|(8,[5],[1.0])|(4993,[3828],[1.0])|0 |1 |(5002,[5,3836],[1.0,1.0]) |
|(8,[5],[1.0])|(4993,[2124],[1.0])|0 |0 |(5002,[5,2132],[1.0,1.0]) |
|(8,[4],[1.0])|(4993,[1168],[1.0])|1 |0 |(5002,[4,1176,5001],[1.0,1.0,1.0])|
|(8,[4],[1.0])|(4993,[4270],[1.0])|1 |0 |(5002,[4,4278,5001],[1.0,1.0,1.0])|
+-------------+-------------------+------+-----+----------------------------------+
only showing top 10 rowsspark特点是所有转换是新增的,无法更新,同时建模需要将所有有效特征压缩到最后一列features列,以便建模。
logistics回归建模
逻辑回归是一个流行的二分类问题预测方法。它是Generalized Linear models 的一个特殊应用以预测结果概率。它是一个线性模型如下列方程所示,其中损失函数为逻辑损失:
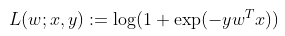
对于二分类问题,算法产出一个二值逻辑回归模型。给定一个新数据,由x表示,则模型通过下列逻辑方程来预测:
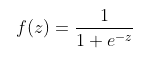
其中
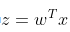
。默认情况下,如果
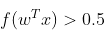
,结果为正,否则为负。
逻辑回归优点:
1.便于理解和实现,可以观测样本的概率分数
2.训练速度快
3.由于经过了sigmoid函数的映射,对数据中小噪声的鲁棒性较好
4.不受多重共线性的影响(可通过正则化进行消除)
缺点:
1.容易欠拟合
2.特征空间很大时效果不好
3.由于sigmoid函数的特性,接近0/1的两侧概率变化较平缓,中间概率敏感,波动较大;导致很多区间特征变量的变化对目标概率的影响没有区分度,无法确定临界值。
使用pyspark的ml
spark ml和mllib
spark ml和mllib都是机器学习库,不过mllib是基于rdd,而ml是基于DataFrame,也就是更高级的数据结构,类似pandas的DataFrame数据框,也就是表格的结构,更接近程序员而不是底层。所以官方推荐ml,因为更灵活,未来会主要支持。
ml在DataFrame上操作,抽象级别高,数据和操作耦合度低
DataFrame是dataset的子集,也就是Dataset[Row], 而DataSet是对RDD的封装,对SQL之类的操作做了很多优化。
ml中的操作可以使用pipeline, 跟sklearn一样,可以把很多操作(算法/特征提取/特征转换)以管道的形式串起来,然后让数据在这个管道中流动。大家可以脑补一下Linux管道在做任务组合时有多么方便。
ml中无论是什么模型,都提供了统一的算法操作接口,比如模型训练都是fit;不像mllib中不同模型会有各种各样的trainXXX。
ml里的重要组成
-
Transformer:是可以将一个DataFrame变换成另一个DataFrame的算法。例如,一个训练好的模型是一个Transformer,通过transform方法,将原始DataFrame转化为一个包含预测值的DataFrame
-
Estimator:是一个算法,接受一个DataFrame,产生一个Transformer。例如,一个学习算法(如PCA,SVM)是一个Estimator,通过fit方法,训练DataFrame并产生模型Transformer
# 创建评估器
import pyspark.ml.classification as cl
logistic = cl.LogisticRegression(
maxIter=10,
regParam=0.01,
labelCol='label')
print ('logistic:', logistic)
Pipeline将多个Transformers和Estimators连接起来组合成一个机器学习工作流程
# 创建一个管道# fit 0.7, # 运行管道,评估模型。'features',test_model: DataFrame[age_range_vec: vector, merchant_id_vec: vector, gender: int, label: int, features: vector, rawPrediction: vector, probability: vector, prediction: double]
test_model.take(1): [Row(age_range_vec=SparseVector(8, {}), merchant_id_vec=SparseVector(4993, {67: 1.0}), gender=0, label=0, features=SparseVector(5002, {75: 1.0}), rawPrediction=DenseVector([3.1645, -3.1645]), probability=DenseVector([0.9595, 0.0405]), prediction=0.0)]
# 评估模型性能,这里略过搜索和tune
import pyspark.ml.evaluation as ev
evaluator = ev.BinaryClassificationEvaluator(
rawPredictionCol='probability',
labelCol='label')
print(evaluator.evaluate(test_model,
{evaluator.metricName: 'areaUnderROC'}))
print(evaluator.evaluate(test_model, {evaluator.metricName: 'areaUnderPR'}))这里略去了交叉验证和tune过程,可以查看API使用
来源
https://www.shiyanlou.com/courses/38
https://edu.cda.cn/

练习
大数据引擎的性能优化手段,包含下面____
A:计算引擎的任务调度时,尽量本地化计算,减少数据网络输出
B:数据以流的方式在不同stage传输,减少物化到磁盘
C:采取数据列式存储,包括轻量级压缩数据、延迟解压、向量化引擎技术
D:MPP架构采取细粒度容错,解决落后节点影响整个查询性能

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)