pandas 只保留日期_数据分析pandas时间序列
1,获取当前时刻的时间2,指定日期和时间的格式3,字符串和时间格式相互转换4,获取某个日期之前/后或时间区间的数据5,获取当前时间及前一天时间6,时间运算7,重采样8,滑动窗口一,获取当前时刻的时间1,返回当前时刻的日期和时间,使用函数now代码如下:2,分别返回当前时刻的年,月,日3,返回当前时刻的周数二,指定日期和时间的格式1,使用data()函数将日期设置成只展示日期2,使用tim...
1,获取当前时刻的时间
2,指定日期和时间的格式
3,字符串和时间格式相互转换
4,获取某个日期之前/后或时间区间的数据
5,获取当前时间及前一天时间
6,时间运算
7,重采样
8,滑动窗口
一,获取当前时刻的时间
1,返回当前时刻的日期和时间,使用函数now
代码如下:

2,分别返回当前时刻的年,月,日

3,返回当前时刻的周数

二,指定日期和时间的格式
1,使用data()函数将日期设置成只展示日期
2,使用time()函数将日期设置成只展示时间

借助strftime()函数可以自定义日期格式和时间格式

应用如下:

三,字符串和时间格式相互转换
1,将时间格式转换为字符串
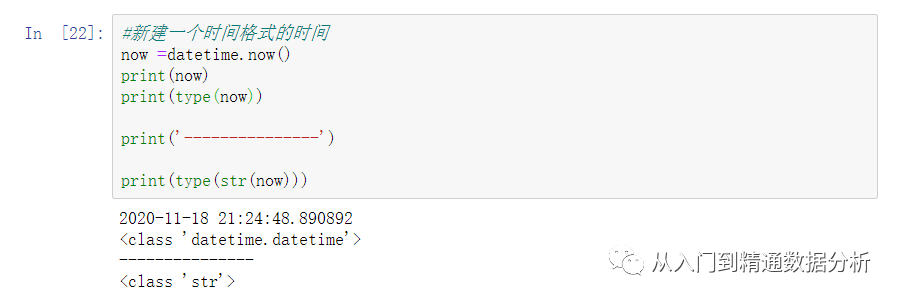
2,使用parse()函数将字符串格式转换为时间格式
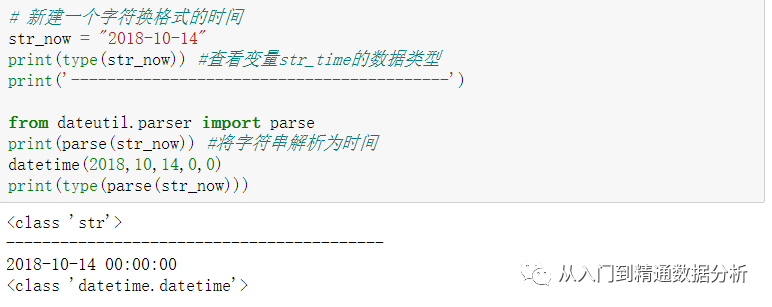
3,还可以使用pd.to_datetime将其它类型转换为时间类型
df['列名']= pd.to_datetime(df['列名'])
4,小技能:提取全日期字段中的日期和时间项
data["订单生成时间"]= pd.to_datetime(data["订单生成时间"]) #转换为时间格式
data["时间"]= data["订单生成时间"].dt.hour #提取时间
data["日期"]= data["订单生成时间"].dt.date #提取日期
四,获取某个日期之前/后或时间区间的数据
dataframe中的.truncate()函数可以截取某个时期之前或之后的数据,或者某个时间区间的数据,进行统计分析。注意事项:
使用.truncate()函数对df进行数据集截取,遇到截取数据不符合预期,且若时间序列无序会抛出异常解决措施:
在使用.truncate()函数对df进行数据集截取之前,需要先使用 df=df.sort_values(‘date’)‘date’列按时间先后进行排序, 然后使用df = df.set_index('date'),将“date”设置为index,最后再使用df_last=df.truncate(after=‘2019-05-22 16:00:00’)提取指定时间节点之前的数据。
函数语法:
DataFrame.truncate(before=None, after=None, axis=None, copy=True)
参数说明:
before:取值范围:date,string,int,是指截断此索引值之前的所有行after:取值范围:date,string,int,是指截断此索引值后的所有行axis:取值范围:{0或’index’,1或’columns’}(可选),是指轴截断。默认情况截断索引(行)。copy:取值范围:boolean,默认为True,返回截断部分的副本
常见用法:
1,获取2020年以后的数据
print(df.truncate(before='2020').head())
2,获取2020-11月之前的数据,用after
print(df.truncate(after='2020-11').head()
3,获取指定时间区间的数据
df=df['2020-01-01':'2020-11-1'] #就是切片
五,获取当前时间及前一天时间
import datetime
from pandas.tseries.offsets
import Day
#获取当前时间
now_time =datetime.datetime.now()
#变成指定格式
yes_time = (now_time -1*Day()).strftime('%Y-%m-%d')
print(yes_time)
六,时间运算
1,两个时间之差
在python中两个时间做差会返回一个timedelta对象,该对象中包含天数,秒,微秒三个级别,如果要获取小时,分钟,则需要进行换算。
import datetimeimport timedelta
#修改“订单生成时间”的数据类型
df[‘订单生成日期’]=pd.to_datetime(df[‘订单生成日期’])df[‘订单生成日期’]+datetime.timedelta(days=1) #后一天的日期df[‘订单生成日期’]-datetime.timedelta(days=3) #前3天的日期

2,时间偏移
之前说过timedelta只支持天,秒,和微秒单位的时间运算,如果是其他单位的时间运算,则需要换算成以上三种单位中的一种方可进行偏移
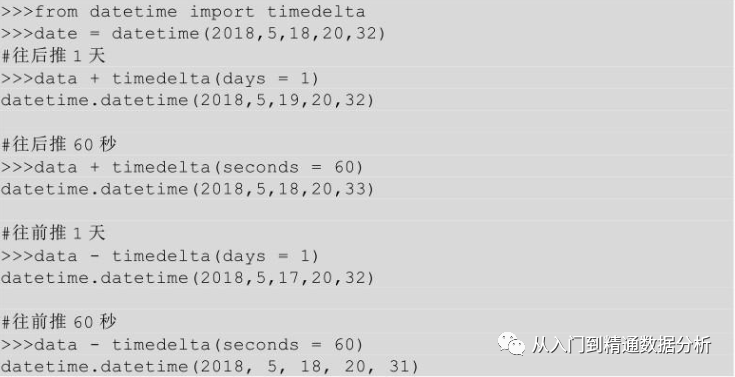 date offset可以直接实现天,小时,分钟单位的时间偏移,不需要换算,相比timedelta要方便一些
date offset可以直接实现天,小时,分钟单位的时间偏移,不需要换算,相比timedelta要方便一些
七,重采样
重采样是pandas时间序列中的一个特色操作,在有些连续时间记录需要按某一指定周期进行聚合统计时尤为有效,实现这一功能的函数主要是resample。这里resample意为重采样,具体又包括上采样和下采样:前者也叫升采样,意为着采样后频率升高,如从2小时一个周期变为1小时一个周期;而后者也叫降采样,采样后频率降低,如从1小时变为2小时采样。仍然以前述的时间索引记录为例,首先将其按4小时为周期进行采样,此时在每个4小时周期内的所有记录汇聚为一条结果,所以自然涉及到聚合函数的问题,包括计数、求均值、累和等等。
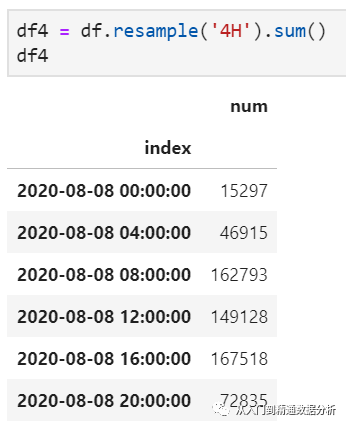
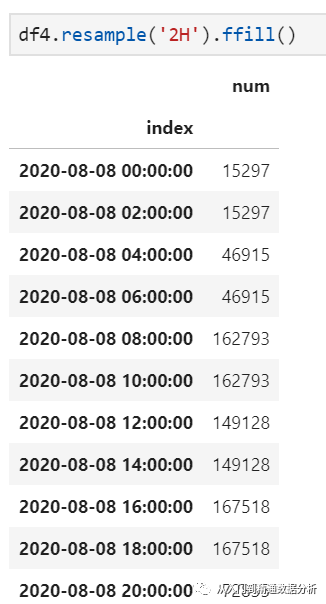
在完成4小时降采样的基础上,如果此时需要周期为2小时的采样结果,则就是上采样。直观来看,由于此时是将6条记录结果上升为12条记录结果,而这些数据不会凭空出现,所以如果说下采样需要聚合、上采样则需要空值填充,常用方法包括前向填充、后向填充等。这里我们结合业务实际,采取前向填充的方式,得到2小时采样结果如下:
关于pandas时间序列的重采样,再补充两点:
1.重采样函数可以和groupby分组聚合函数组合使用,可实现更为精细的功能,
2.重采样过程中,无论是上采样还是下采样,其采样结果范围是输入记录中的最小值和最大值覆盖的范围,所以当输入序列中为两段不连续的时间序列记录时,可能会出现中间大量不需要的结果,同时在上图中也可发现从4小时上采样为2小时后时间最大范围是20:00,而非22:00,也是这个原因。
八 滑动窗口
理解pandas中时间序列滑动窗口的最好方式是类比SQL中的窗口函数。实际上,其与分组聚合函数的联系和SQL中的窗口函数与分组聚合联系是一致的。常用的滑动窗口函数主要有3个:
-
shift,向前或向后取值
-
diff,向前或向后去差值
-
rolling,一段滑动窗口内聚合取值
仍以前述时间序列数据为例,为了便于比较,首先再次给出数据序列
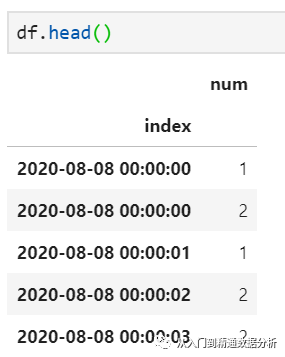
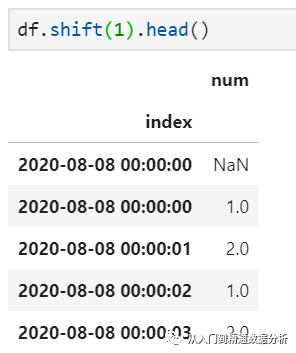
1.shift完成向前或向后滑动取值,periods参数设置滑动长度,freq设置滑动参考周期,默认为空,此时仅仅是向后读取一条记录
设置freq=10T,向后滑动10分钟后取值。
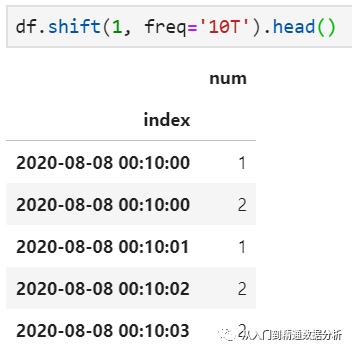
值得指出,这里的滑动取值可以这样理解:periods参数为正数时,可以想象成索引列不动,数据列向后滑动;反之,periods参数为负数时,索引列不动,数据列向前滑动。进一步的,当freq参数为None时,则仅仅是滑动指定数目的记录,而不管索引实际取值;而当freq设置有效参数时,此时要求索引列必须为时间序列,并根据时间序列滑动到指定周期处,并从此处开始取值(在上图中,体现为10T之前的记录不再保留)。
2.在理解shift操作的基础上,diff函数用于取差值就容易得多,且比其更为简单的是diff操作只支持记录间的差值,而不支持指定周期。接受参数主要是periods:当其为正数时,表示当前值与前面的值相减的结果;反之,当其未负数时,表示当前值与后面的值相减。
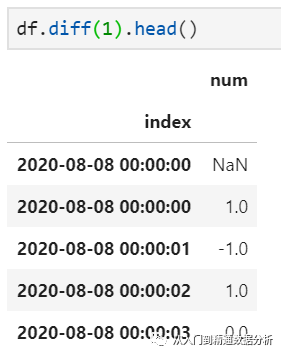
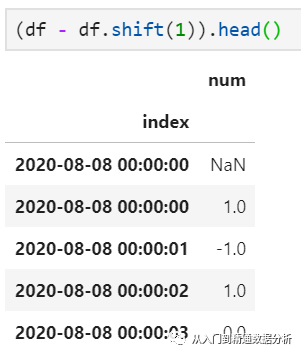
以差值窗口长度=1为例,实际上此时只是简单的执行当前值与其前一个值的差,其应用shift的等价形式即为:
3.rolling,这是一个原原本本的滑动窗口,适用场景是连续求解一段时间内的某一指标。例如,求解连续3条记录的均值,则可简单实现如下:
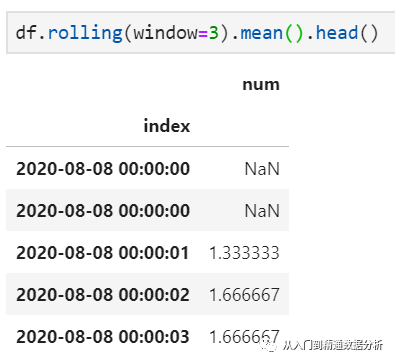
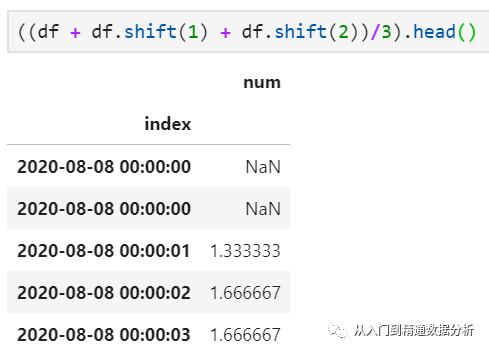
注意到由于窗口长度设置为3,前两条记录因为"向前凑不齐"3条,所以结果为空值。当然,就这一特定需求而言,也可由shift函数实现:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)