spark初步学习遇到问题及注意事项
·
基础知识:
spark是基于内存的大数据框架,紧密集成、 时效高、可迭代。
spark是Scala写的,运行在JVM上。所以搭建spark环境需要安装jdk(1.7以上)、Scala、spark,hadoop环境不是必须的
下载的网址可以百度到,不再赘述。但是注意版本问题:(我的)spark-2.4 ----- scala-2.12
查看是否安装好
![]()
下载解压后需要配置环境变量
vi /etc/profile
export JAVA_HOME=/home/jdk1.8
export HADOOP_HOME=/home/hadoop-2.7.5
export SPARK_HOME=/home/spark
export SCALA_HOME=/home/scala
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$SCALA_HOME/bin注意刷新一下
source /etc/profile然后进入spark的conf文件 复制一份spark-env.sh.template 为 spark-env.sh 然后在后面添加环境变量
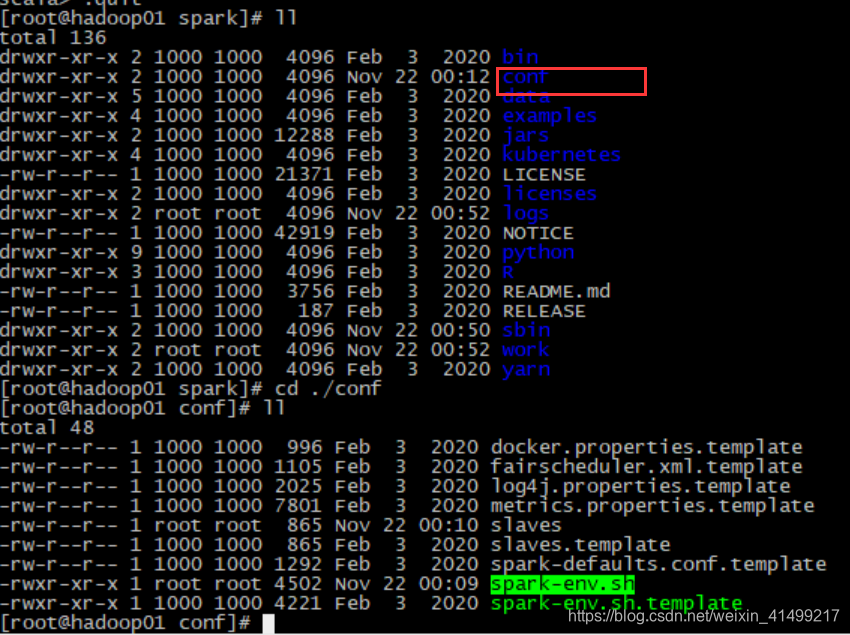
export JAVA_HOME=/home/jdk1.8
export HADOOP_HOME=/home/hadoop-2.7.5
export SCALA_HOME=/home/scala
export HADOOP_CONF_DIR=/home/hadoop-2.7.5/etc/hadoop
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1然后启动spark的start-all.sh 这个文件在spark的文件下
./sbin/start-all.shspark有两种shell:1)pyspark :python的shell 2)spark-shell :scala的shell
分别启动一下
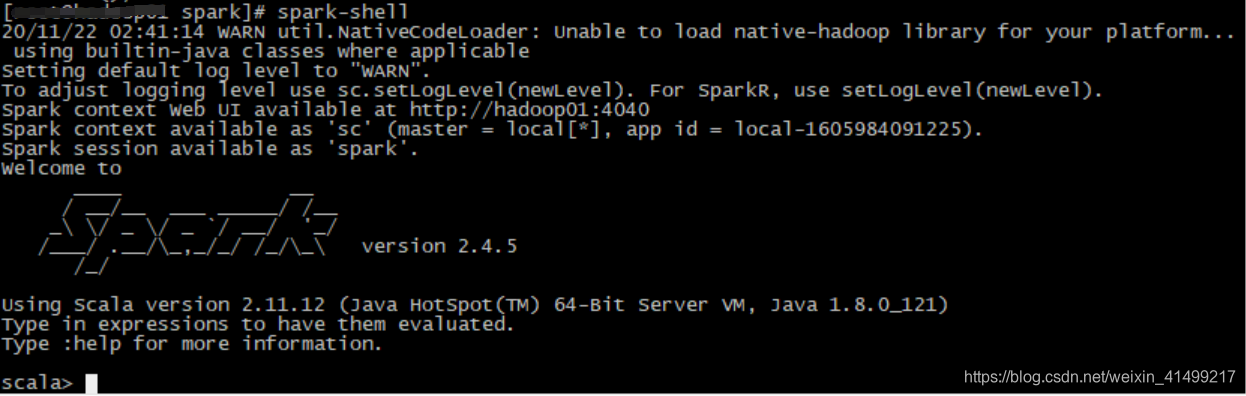
关于spark-shell的命令简单练习一下
scala> val lines = sc.textFile("123.txt")
lines: org.apache.spark.rdd.RDD[String] = 123.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count()
res0: Long = 4
scala> lines.first()
res1: String = hello java
scala>:quit

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)