北京理工大学python课程嵩天老师笔记_python-数据分析与展示(Numpy、matplotlib、pandas)---3...
笔记内容整理自mooc上北京理工大学嵩天老师python系列课程数据分析与展示,本人小白一枚,如有不对,多加指正0.pandas基于Numpy实现的,前者注重应用,后者注重结构1.Series类型(索引和数据组合的类型,也就是个带索引的narray)1.11.2apipd.Series.index/value支持切片1.3 。。。。。2.DataFrame类型(共用相同索引的多维Seri...
笔记内容整理自mooc上北京理工大学嵩天老师python系列课程数据分析与展示,本人小白一枚,如有不对,多加指正
0.pandas基于Numpy实现的,前者注重应用,后者注重结构
1.Series类型(索引和数据组合的类型,也就是个带索引的narray)
1.1

1.2api
pd.Series.index/value 支持切片
1.3 。。。。。
2.DataFrame类型(共用相同索引的多维Series类型)

2.1 .index() .column() .values()
2.2 .reindex(index/column = )重排行或列
2.3 index是索引类型(行跟列的表头都是index类型)

2.4
 一轴是x轴
一轴是x轴
3.总结

4.数据排序和统计操作
4.1 对索引进行排序dataframe.sort_index() 对数据进行排序dataframe.sort_values()
4.2
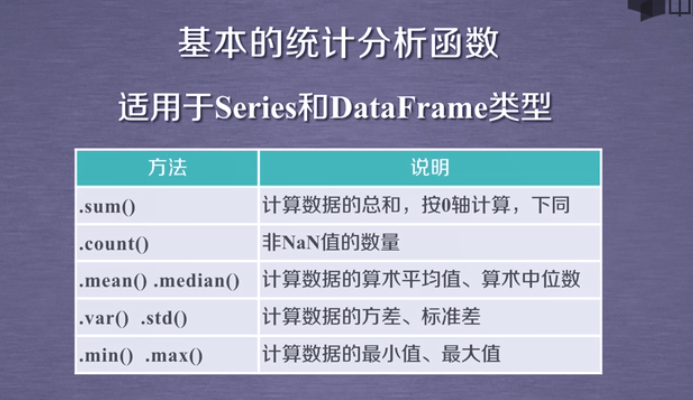


4.3累计统计函数
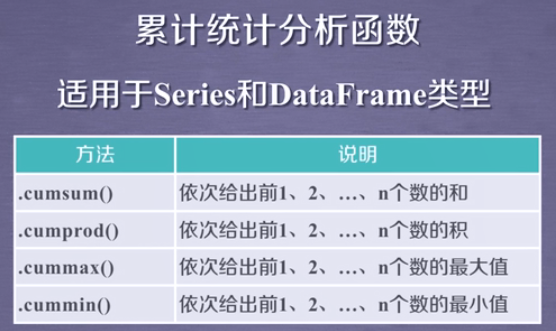
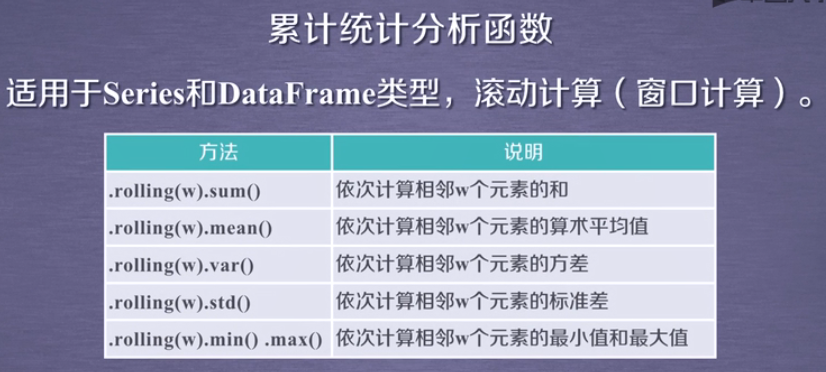
前者的累计统计函数不同于后者的滚动统计函数,后者是小范围的累计统计函数,范围由rolling(w)中w参数指定
5.数据的相关分析



协方差描述并不准确跟严谨,所以提出了pearson相关系数等描述两个事物或随机变量的相关性

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)