【读书笔记】github 课程-Python-100-Days
骆昊大佬的教程链接day2:计算机的硬件系统通常由五大部件构成,包括:运算器、控制器、存储器、输入设备和输出设备。其中,运算器和控制器放在一起就是我们通常所说的中央处理器,它的功能是执行各种运算和控制指令以及处理计算机软件中的数据。在程序设计中,变量是一种存储数据的载体。计算机中的变量是实际存在的数据或者说是存储器中存储数据的一块内存空间,变量的值可以被读取和修改,这是所有计算和控制的基础。变量命
骆昊大佬的教程链接
day2:
- 计算机的硬件系统通常由五大部件构成,包括:运算器、控制器、存储器、输入设备和输出设备。其中,运算器和控制器放在一起就是我们通常所说的中央处理器,它的功能是执行各种运算和控制指令以及处理计算机软件中的数据。
- 在程序设计中,变量是一种存储数据的载体。计算机中的变量是实际存在的数据或者说是存储器中存储数据的一块内存空间,变量的值可以被读取和修改,这是所有计算和控制的基础。
- 变量命名规则:由字母、数字和下划线构成,数字不能开头
- 比较运算符有的地方也称为关系运算符,包括==、!=、<、>、<=、>=,唯一需要提醒的是比较相等用的是==,请注意这个地方是两个等号,因为=是赋值运算符,我们在上面刚刚讲到过,==才是比较相等的比较运算符。比较运算符会产生布尔值,要么是True要么是False。
- Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索
- str2 = ‘abc123456’
从字符串中取出指定位置的字符(下标运算)
print(str2[2]) # c
字符串切片(从指定的开始索引到指定的结束索引)
print(str2[2:5]) # c12取第3个数到第5个数
print(str2[2:]) # c123456取第2个到最后
print(str2[2::2]) # c246取第二个到最后,每隔2步·
print(str2[::2]) # ac246取全部,每隔2步
print(str2[::-1]) # 654321cba取全部,倒序
print(str2[-3:-1]) # 45取倒数第三和第二
`在这里插入代码片list1 = [1, 3, 5, 7, 100]
# 添加元素
list1.append(200)
list1.insert(1, 400)
# 合并两个列表
# list1.extend([1000, 2000])
list1 += [1000, 2000]
print(list1) # [1, 400, 3, 5, 7, 100, 200, 1000, 2000]
print(len(list1)) # 9
# 先通过成员运算判断元素是否在列表中,如果存在就删除该元素
if 3 in list1:
list1.remove(3)
if 1234 in list1:
list1.remove(1234)
print(list1) # [1, 400, 5, 7, 100, 200, 1000, 2000]
# 从指定的位置删除元素
list1.pop(0)
list1.pop(len(list1) - 1)
print(list1) # [400, 5, 7, 100, 200, 1000]
# 清空列表元素
list1.clear()
print(list1) # []`
- 把一组数据结构和处理它们的方法组成对象(object),把相同行为的对象归纳为类(class),通过类的封装(encapsulation)隐藏内部细节,通过继承(inheritance)实现类的特化(specialization)和泛化(generalization),通过多态(polymorphism)实现基于对象类型的动态分派。"
- 类是对象的蓝图和模板,而对象是类的实例。这个解释虽然有点像用概念在解释概念,但是从这句话我们至少可以看出,类是抽象的概念,而对象是具体的东西。在面向对象编程的世界中,一切皆为对象,对象都有属性和行为,每个对象都是独一无二的,而且对象一定属于某个类(型)。当我们把一大堆拥有共同特征的对象的静态特征(属性)和动态特征(行为)都抽取出来后,就可以定义出一个叫做“类”的东西。
- 举个程序例子:
class Student(object):
# __init__是一个特殊方法用于在创建对象时进行初始化操作
# 通过这个方法我们可以为学生对象绑定name和age两个属性
def __init__(self, name, age):
self.name = name
self.age = age
def study(self, course_name):
print('%s正在学习%s.' % (self.name, course_name))
def watch_movie(self):
if self.age < 18:
print('%s只能观看《熊出没》.' % self.name)
else:
print('%s正在观看岛国爱情大电影.' % self.name)
def main():
# 创建学生对象并指定姓名和年龄
stu1 = Student('骆昊', 38)
# 给对象发study消息
stu1.study('Python程序设计')
# 给对象发watch_av消息
stu1.watch_movie()
stu2 = Student('王大锤', 15)
stu2.study('思想品德')
stu2.watch_movie()
if __name__ == '__main__':
main()
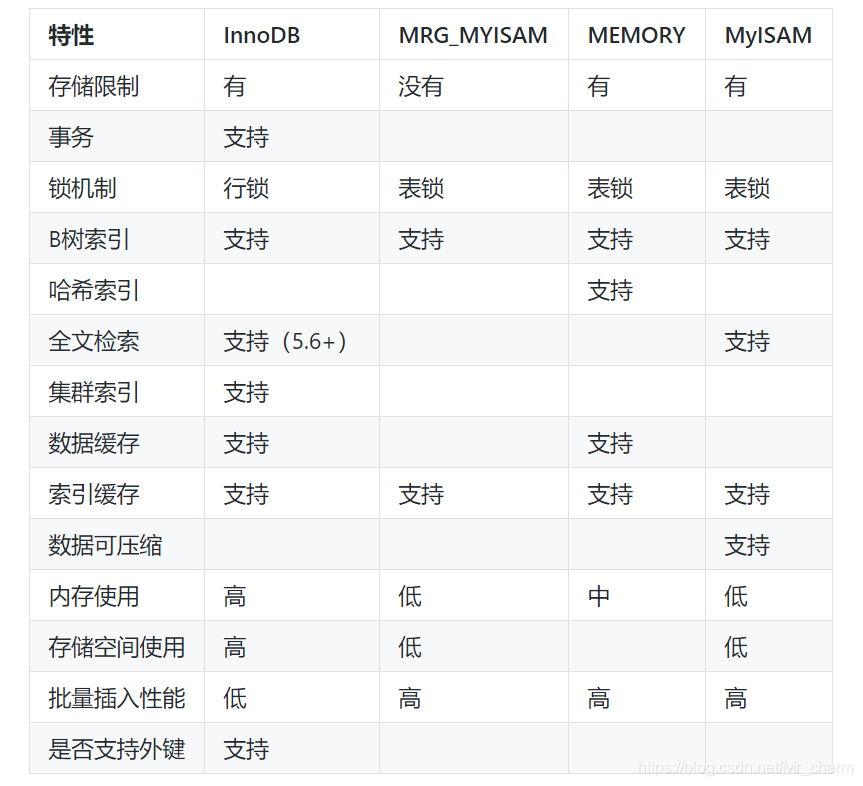
- 我们通常可以将SQL分为三类:DDL(数据定义语言)、DML(数据操作语言)和DCL(数据控制语言)。DDL主要用于创建(create)、删除(drop)、修改(alter)数据库中的对象,比如创建、删除和修改二维表;DML主要负责插入数据(insert)、删除数据(delete)、更新数据(update)和查询(select);DCL通常用于授予权限(grant)和召回权限(revoke)。
- 建索引:
create index idx_student_name on tb_student(stuname)- MySQL中还允许创建前缀索引,即对索引字段的前N个字符创建索引,这样的话可以减少索引占用的空间(但节省了空间很有可能会浪费时间,时间和空间是不可调和的矛盾),如下所示。
create index idx_student_name_1 on tb_student(stuname(1));
- 删除索引:`alter table tb_student drop index idx_student_name;
- drop index idx_student_name on tb_student;`
我们简单的为大家总结一下索引的设计原则:
最适合索引的列是出现在WHERE子句和连接子句中的列。
索引列的基数越大(取值多重复值少),索引的效果就越好。
使用前缀索引可以减少索引占用的空间,内存中可以缓存更多的索引。
索引不是越多越好,虽然索引加速了读操作(查询),但是写操作(增、删、改)都会变得更慢,因为数据的变化会导致索引的更新,就如同书籍章节的增删需要更新目录一样。
使用InnoDB存储引擎时,表的普通索引都会保存主键的值,所以主键要尽可能选择较短的数据类型,这样可以有效的减少索引占用的空间,利用提升索引的缓存效果。
事务:一系列对数据库进行读/写的操作,这些操作要么全都成功,要么全都失败。
事务的ACID特性
原子性:事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行
一致性:事务应确保数据库的状态从一个一致状态转变为另一个一致状态
隔离性:多个事务并发执行时,一个事务的执行不应影响其他事务的执行
持久性:已被提交的事务对数据库的修改应该永久保存在数据库中
数据分析
工作内容
负责各部门相关的报表。
建立和优化指标体系。
监控数据波动和异常,找出问题。
优化和驱动业务,推动数字化运营。
找出潜在的市场和产品的上升空间。
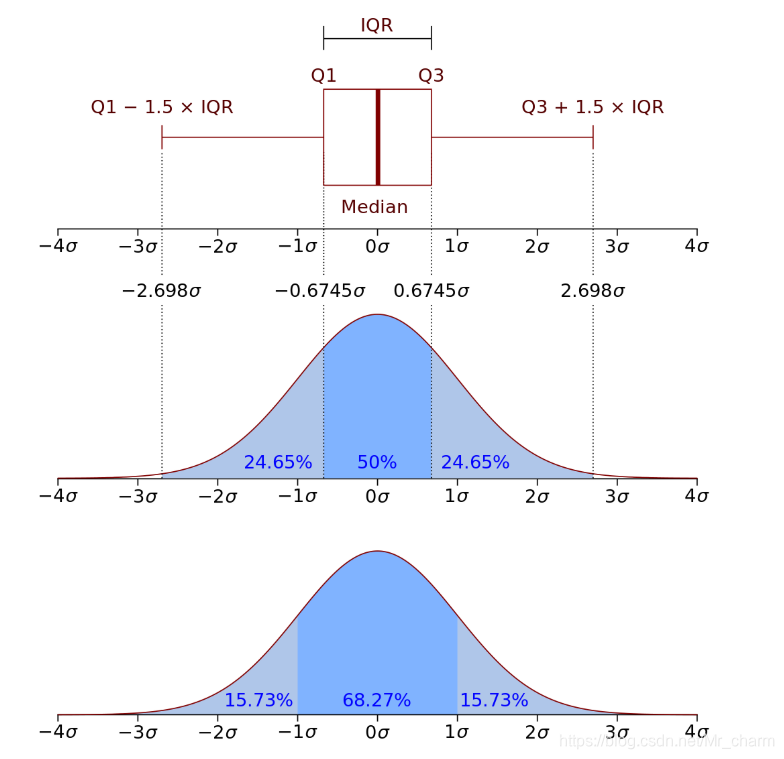
- 峰态:峰态就是概率分布曲线的峰值高低,是尖峰、平顶峰,还是正态峰。
- 偏度:偏度就是峰值与平均值的偏离程度,是左偏还是右偏。
离散型分布:如果随机发生的事件之间是毫无联系的,每一次随机事件发生都是独立的、不连续的、不受其他事件影响的,那么这些事件的概率分布就属于离散型分布。
- 二项分布:n个独立的实验中成功的次数的离散分布,事件只有成功1和失败0两种结果。
- 泊松分布:适合于描述单位时间内随机事件发生的次数的概率分布。如:某服务设施在一定事件内收到的服务请求次数,汽车站台的候客人数、自然灾害的发生次数。参数是单位时间内随机事件的平均发生率。
连续型分布: - 正态分布(高斯分布):
- 卡方分布
大数定律:样本数量越多,则其算术平均值就有越高的概率接近期望值。
中心极限定理:如果统计对象是大量独立的随机变量,那么这些变量的平均值分布就会趋向于正态分布,不管原来它们的概率分布是什么类型
假设检验:
假设检验就是通过抽取样本数据,并且通过小概率反证法去验证整体情况的方法。假设检验的核心思想是小概率反证法(首先假设想推翻的命题是成立的,然后试图找出矛盾,找出不合理的地方来证明命题为假命题),即在原假设(零假设,null hypothesis)的前提下,估算某事件发生的可能性,如果该事件是小概率事件,在一次研究中本来是不可能发生的,现在却发生了,这时候就可以推翻原假设,接受备择假设(alternative hypothesis)。如果该事件不是小概率事件,我们就找不到理由来推翻之前的假设,实际中可引申为接受所做的无效假设。
假设检验会存在两种错误情况,一种称为“拒真”,一种称为“取伪”。如果原假设是对的,但你拒绝了原假设,这种错误就叫作“拒真”,这个错误的概率也叫作显著性水平 α \alpha α,或称为容忍度;如果原假设是错的,但你承认了原假设,这种错误就叫作“取伪”,这个错误的概率我们记为 β \beta β。
条件概率与贝叶斯定理:
P ( A ∣ B ) P(A|B) P(A∣B)是已知B发生后,A的条件概率,也称为A的后验概率。
P ( A ) P(A) P(A)是A的先验概率(也称为边缘概率),是不考虑B时A发生的概率。
P ( B ∣ A ) P(B|A) P(B∣A)是已知A发生后,B的条件概率,称为B的似然性。
P ( B ) P(B) P(B)是B的先验概率。
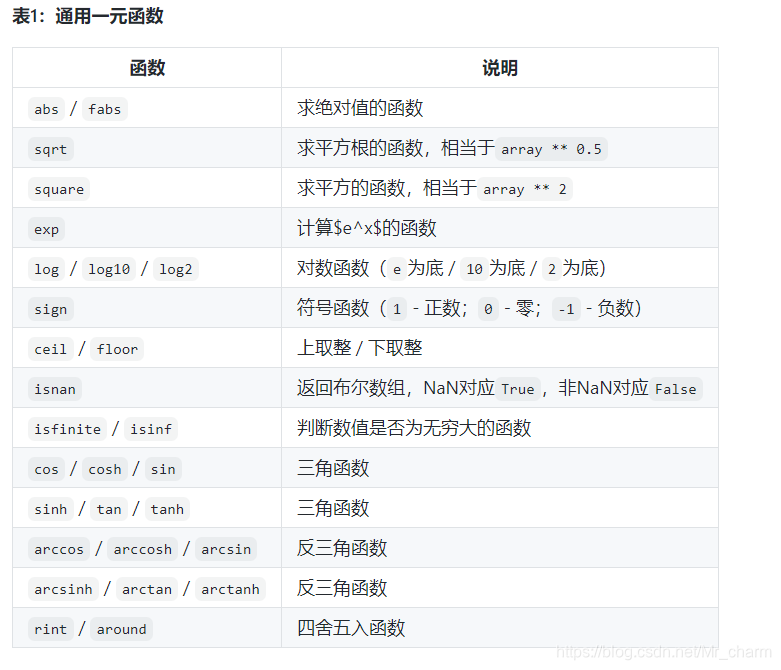
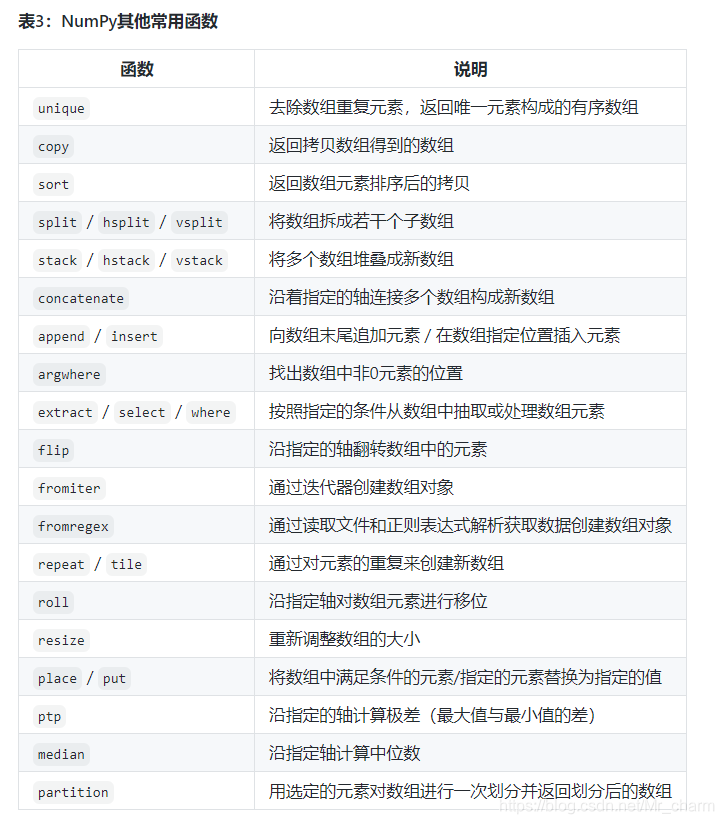
numpy:
使用numpy.random模块的函数生成随机数创建数组对象,产生10个 [ 0 , 1 ) [0, 1) [0,1)范围的随机小数,代码:
array4 = np.random.rand(10)
array4
产生10个 [ 1 , 100 ) [1, 100) [1,100)范围的随机整数,代码:
array5 = np.random.randint(1, 101, 10)
array5
通过reshape将一维数组变成二维数组
代码:
array12 = np.array([1, 2, 3, 4, 5, 6]).reshape(2, 3)
array12
求和、求平均、求标准差、求方差、找最大、找最小、求累积和
array28 = np.array([1, 2, 3, 4, 5, 5, 4, 3, 2, 1])
print(array28.sum())
print(array28.mean())
print(array28.max())
print(array28.min())
print(array28.std())
print(array28.var())
print(array28.cumsum())
保持渴求,不要沉寂


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)