wiredtiger java_mongodb数据库损坏,丢失WiredTIger.wt等meta文件,通过collection*.wt恢复数据...
mongodb 恢复wiredtiger数据Backgroundmongodb是一款开源NoSQL非关系型数据库,通过database, collection组织存储数据文件,其中在每个collection中,每条数据被存储为一个document,而每个document为一组键值对。 此外,mongodb默认使用WiredTiger作为数据存储引擎,WiredTiger为数据管理提供了不同粒度的并
mongodb 恢复wiredtiger数据
Background
mongodb是一款开源NoSQL非关系型数据库,通过database, collection组织存储数据文件,其中在每个collection中,每条数据被存储为一个document,而每个document为一组键值对。

此外,mongodb默认使用WiredTiger作为数据存储引擎,WiredTiger为数据管理提供了不同粒度的并发控制和压缩机制,能够为不同种类的应用提供了最好的性能和存储效率,其中,WiredTiger支持lz4, nop, snappy, zlib, zstd等压缩方式。其中,mongodb默认采用snappy。Github地址: https://github.com/wiredtiger/wiredtiger
从mongodb的数据存储目录中不难发现以下文件,
collection****.wt
index****.wt
_mdb_catalog.wt
sizeStorer.wt
storage.bson
WiredTiger
WiredTiger.lock
WiredTiger.turtle
WiredTiger.wt
其中,
collection-xxx.wt和index-xxx.wt是数据库中集合所对应的数据文件和索引文件。
_mdb_catalog.wt存储的是集合表名与磁盘上数据文件和索引文件间的对应关系。
sizeStorer.wt存储所有集合的容量信息,如集合中包含的文档数、总数据大小。
storage.bson是一个BSON格式的二进制文件,其内容与WiredTiger存储引擎的配置有关,可以通过MongoDB提供的bsondump命令工具查看其内容。
WiredTiger存储的是WiredTiger存储引擎的版本号,编译时间等信息。
WiredTiger.lock这是WiredTiger运行实例的锁文件,防止多个进程同时连接同一个Wiredtiger实例。
WiredTiger.turtle存储的是WiredTiger.wt这个文件的checkpoint数据信息。
WiredTiger.wt存储的是所有集合(包含系统自带的集合)相关数据文件和索引文件的checkpoint信息。
更多详细介绍可参考 https://mongoing.com/archives/74064
Scenario
由于数据库迁移,本人实验用的mongodb数据库丢失了WiredTiger.wt这一关键数据库目录信息,因此无法采用目前主流的wt工具修复方式,如所有以上相关文件仍然存在,可以采用官方提供的wt工具进行修复 (可参考 https://www.cnblogs.com/skying555/p/6046980.html)。
WT_BLOCK
参考大神的blog (https://blog.csdn.net/wangmingshuaiguo/article/details/92631162),采用逆向二进制数据文件的方式反向抽取被损坏的数据。
首先,每个collection*.wt数据文件的前4096字节是该wt文件的元数据信息,wt数据文件从4096开始依次存储数据库记录,每条记录是由n*4096的记录块(WT_block)组成。
针对单一一个记录块,前32个字节为WT_block头部,如下示例所示:
00 00 00 00 00 00 00 00 42 48 01 00 00 00 00 00
74 CF 01 00 86 00 00 00 07 05 00 00 00 70 00 00
其中,根据源码猜测,头部主要由三部分组成
(1) WT_BLOCK_DESC: file description, 16 bytes
00-03: Magic number
04-05: Major version
06-07: Minor version
08-11: Description block checksum
12-15: Padding
(2) WT_BLOCK_HEADER: block header, 12 bytes
16-19: on-disk page size
20-23: checksum
24: flags
25-27: unused padding
(3) Block size: 28-31, little-endian, 比如 ’‘00 70 00 00’‘表明block size 为 0x7000 = 28672字节。
解析完头部之后,可以通过block size得到对应记录块。
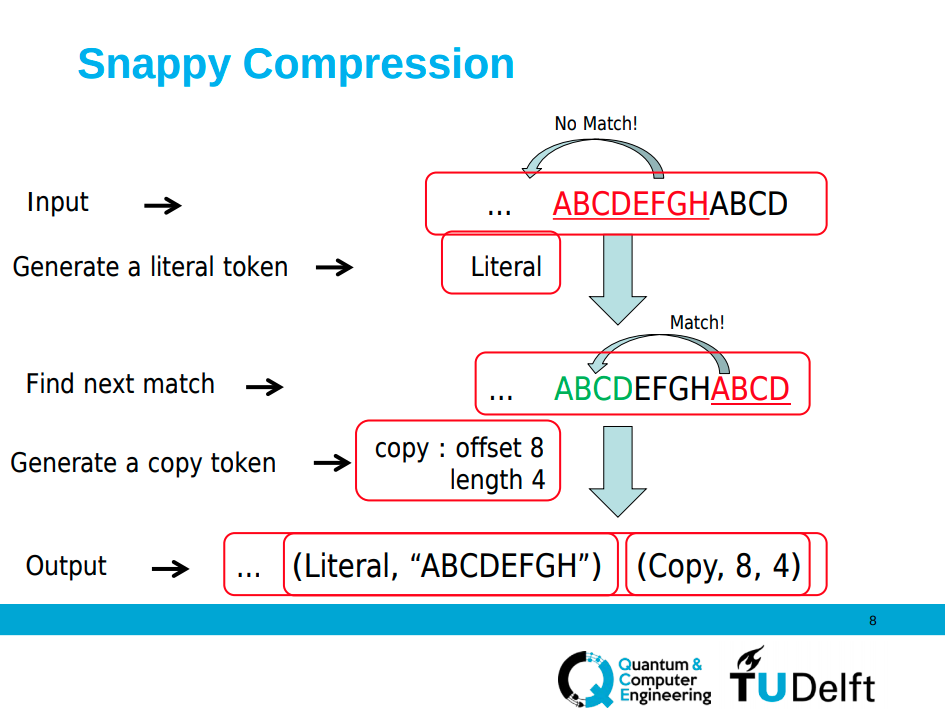
Snappy Compression
WiredTiger默认采用snappy对数据进行压缩,snappy是一种基于字节的数据流压缩方式,压缩格式主要分为两部分,开头1~5个字节表示压缩数据解压后的长度,之后数据通过向前发现相同字段并用坐标表示替换重复字段的方式,达到压缩文件的目的。如下图所示:
![avatar]
 (图片来源 https://cdn.openpowerfoundation.org/wp-content/uploads/2018/10/Jian-Fang.A_High-BandwidtJian-Fang.Snappy_Decompressor_in_Reconfig.pdf)
(图片来源 https://cdn.openpowerfoundation.org/wp-content/uploads/2018/10/Jian-Fang.A_High-BandwidtJian-Fang.Snappy_Decompressor_in_Reconfig.pdf)
算法细节不在此赘述,可参考wikipedia, Kyle Kovacs(UCBerkeley)的论文A Hardware Implementation of the Snappy Compression Algorithm,以及Jian Fang (TU Delft)的slides (Decompressing Snappy Compressed Files at the Speed of OpenCAPI).
WiredTiger Snappy Decompression
依照WiredTiger源码中所述,在压缩过程中,block头部中的信息需要用来校验,因此不会进行压缩。为此,压缩过程会先跳过WT_BLOCK_COMPRESS_SKIP个字节,再对剩余数据进行压缩。从源码中得到WT_BLOCK_COMPRESS_SKIP为64字节。
We can only skip the header information when doing encryption, but we skip the first 64B when doing compression; a 64B boundary may offer better alignment for the underlying compression engine, and skipping 64B shouldn't make any difference in terms of compression efficiency.
依旧以此记录块为例,跳过64个字节(4行)后,第64~72个字节(0x40-0x47)为压缩后的字节长度,小端表示,即DB 62 00 00 00 00 00 00= 0x62DB = 25307字节。因此只需从0x48开始往后读取25307个字节,并使用snappy进行解压,再将未压缩的头部与解压后的数据拼接,即可得到压缩前的记录信息。
00 00 00 00 00 00 00 00 42 48 01 00 00 00 00 00
74 CF 01 00 86 00 00 00 07 05 00 00 00 70 00 00
99 50 01 EA 01 00 00 00 05 81 80 C0 3C BC 00 00
00 07 5F 69 64 00 5E 5B C7 92 37 82 63 61 A5 71
DB 62 00 00 00 00 00 00 B4 9E 07 D0 33 2A 02 61
72 74 69 66 61 63 74 5F 69 64 00 09 00 00 00 70
75 67 2D 6C 6F 61 64 00 04 64 65 70 65 6E 64 65
6E 63 69 65 73 00 5C 00 00 00 03 30 00 54 00 00
Extraction
在获取到压缩前的记录信息后,记录中除去需要抽取的bson数据,在每个bson object数据之间,仍穿插着部分非bson数据的bytes。按照wangming的策略,由于mongodb中每个document的第一个字段为_id,其二进制表示为07 5F 69 64 (如上例中第50~-53字节。注:与wangming的数据有偏差),而根据bson数据的格式,每个bson数据开头4个字节为小端表示的长度,其后每个键值对数据依次表示为类型,属性名,属性值。因此,此处只需找到每个_id字段,并向前读取4个字节获取长度后,再向后读取对应长度的数据存储到bson文件中即可。
需要注意的是,(1)同一文件的WT_block中的数据可能存在重复,因此,在获取到所有bson数据块后,需要再进一步去重。(2)并不是每个WT_block中都包含数据,部分WT_block中存储的是类似checkpoint的记录信息。
拼接生成后的bson文件可以使用mongodb自带的bsondump来检测其正确性。
bsondump xxx.bson
顺利生成的bson文件即可再次使用mongorestore导入到mongodb中。
mongorestore --host --port --db= --collection=

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)