kettle mysql日志同步_使用KETTLE从mysql同步增量数据到MySQL(1)
在线QQ客服:1922638专业的SQL Server、MySQL数据库同步软件初次使用ETL工具抽取并同步数据,搜索之后决定使用kettle,使用后感觉很方便。本次是基于一个很小的需求,需要把老系统的mysql数据在一段新老系统共存时期内产生的数据实时传输到新系统oracle中,因为实时性要求不算高,所以我没有做触发器这些对接,只单纯的使用kettle做了一个抽取转换传输,定时执行。下面记录一下

在线QQ客服:1922638
专业的SQL Server、MySQL数据库同步软件
初次使用ETL工具抽取并同步数据,搜索之后决定使用kettle,使用后感觉很方便。
本次是基于一个很小的需求,需要把老系统的mysql数据在一段新老系统共存时期内产生的数据实时传输到新系统oracle中,因为实时性要求不算高,所以我没有做触发器这些对接,只单纯的使用kettle做了一个抽取转换传输,定时执行。下面记录一下本次的操作,并写一下自己遇到的坑。
老系统mysql表很大,本次基于一个小的需求,只需要抽取其中的两个字段同步传输。两个字段均是varchar类型,相对比较简单。我尝试过传输mysql的int(11)和oracle的number,发现需要把oracle的number改为number(10),二者才能对的上号。
工具:kettle的pdi-ce-7.0.0.0-25,可去官网下载;mysql,oracle
思路:先将mysql老数据和oracle同步后的数据都查出来,转换字段统一整合交给kettle处理,kettle会依据关键字段和时间戳来判断来自mysql的数据对oracle来讲,是新增、更新、删除还是无任何操作,并分别标注标识位,后续一步步判断标识位,最后转换成oracle字段,插入/更新/删除数据库数据。
整个流程使用kettle分为两部分,一部分是一个转换,是流程执行的主要战场;另一个是一个作业,用来循环执行上一个转换,达到定时执行的效果。
转换步骤图:
作业流程图:

作业流程图很简单,主要是循环定时执行转换,忽略不计。本次主要讲的是转换。
转换首先要建立数据库连接,最后再讲。
步骤一:从mysql和oracle中查询所有数据,传送给下一步。
mysql是每次同步的源头,oracle是每次同步的目标。之所以两处都要查出来,是因为要在下一步中比对二者的数据,判断哪些是增量数据。
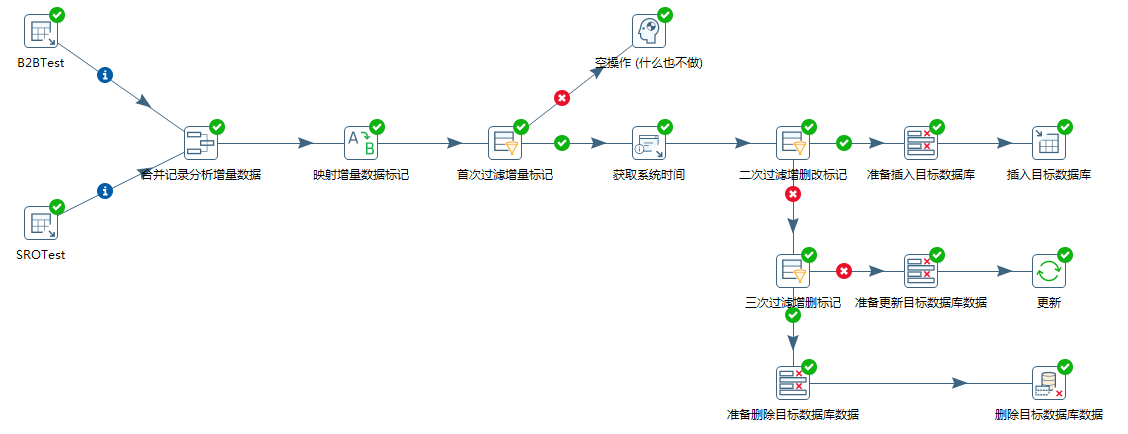
B2BTest节点和SROTest节点:
从二者查出来的数据,统一归整成两个字段,TASKNO和SAPNO,然后推入下一个节点。
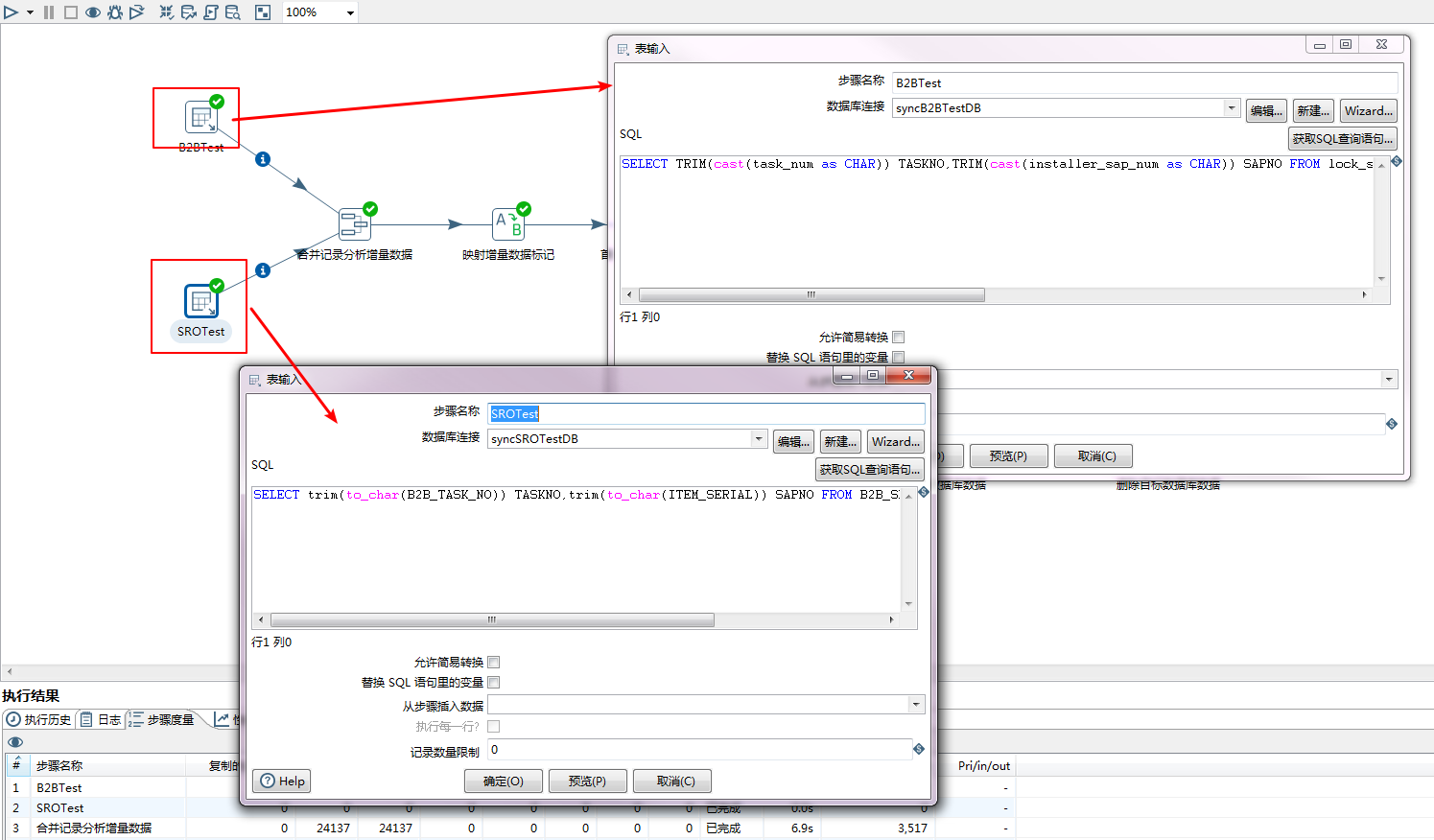
步骤二:合并上一步的记录,并分析增量数据,ETL会自动给每条数据都打上标记flagfield
关键字段指的是用来分析增量数据的依据性字段,数据字段指的是所有需要合并整理的字段,标记打在flagfield上。
因为是从Mysql同步到oracle,所以旧数据源选择oracle的,新数据源选择mysql的
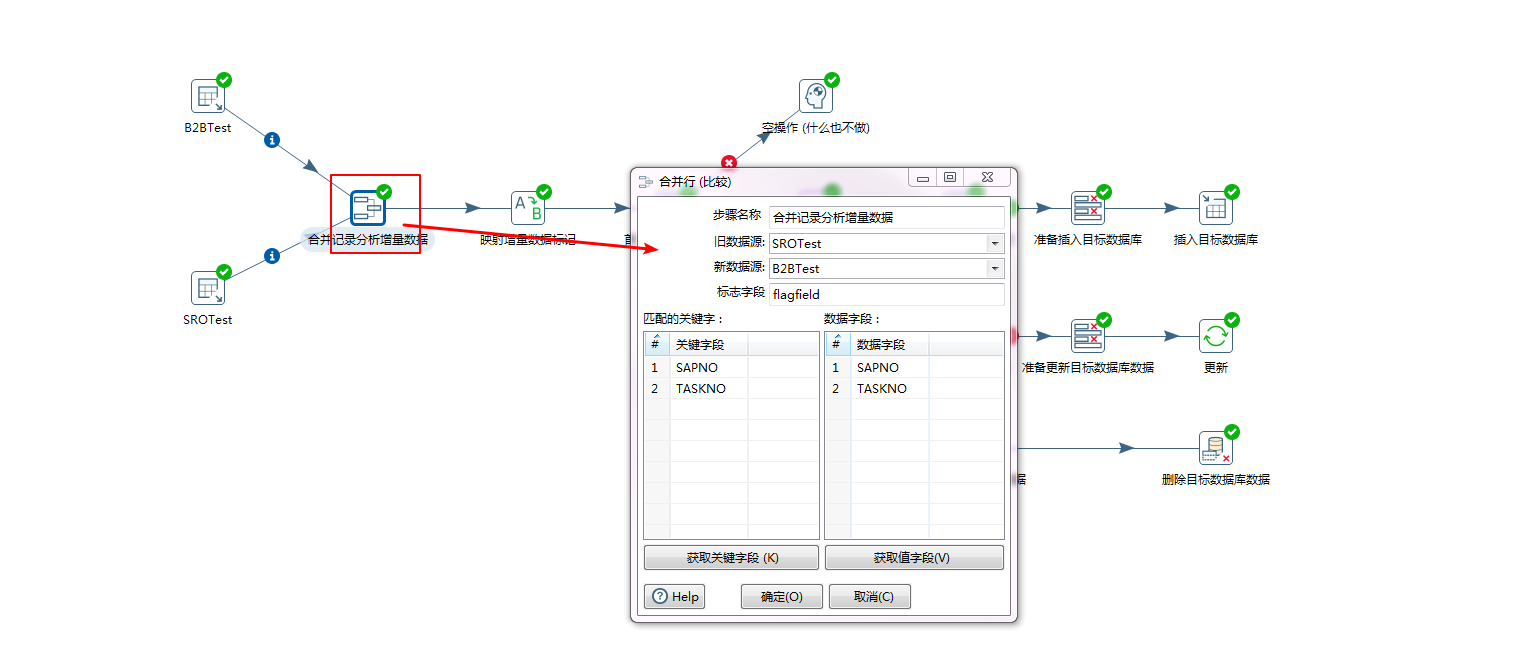
步骤三:将标记和数据进一步处理,映射一下增量数据标记
kettle会自动在上一步打上标记,默认值是 deleted、new、changed、identical(什么也不做的意思,实际是打上null标记)。我们可以映射成我们自己的标记,用于下一步的处理。
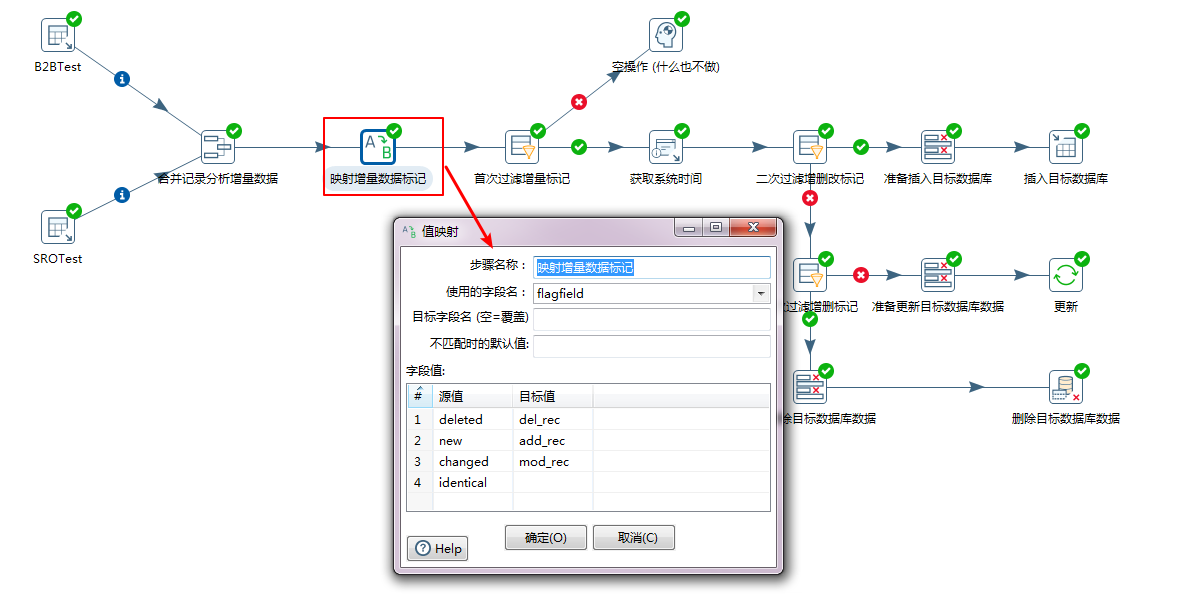
步骤四:第一次开始过滤增量标记,开始第一步分支流程处理。
本次过滤是将flagfield标记为null的,也就是identical指代的标记的数据,全部扔到空操作中。这些数据毫无变化,所以不必做任何操作。
需要下一步处理的变化数据,全都丢到下一步的获取系统时间中。
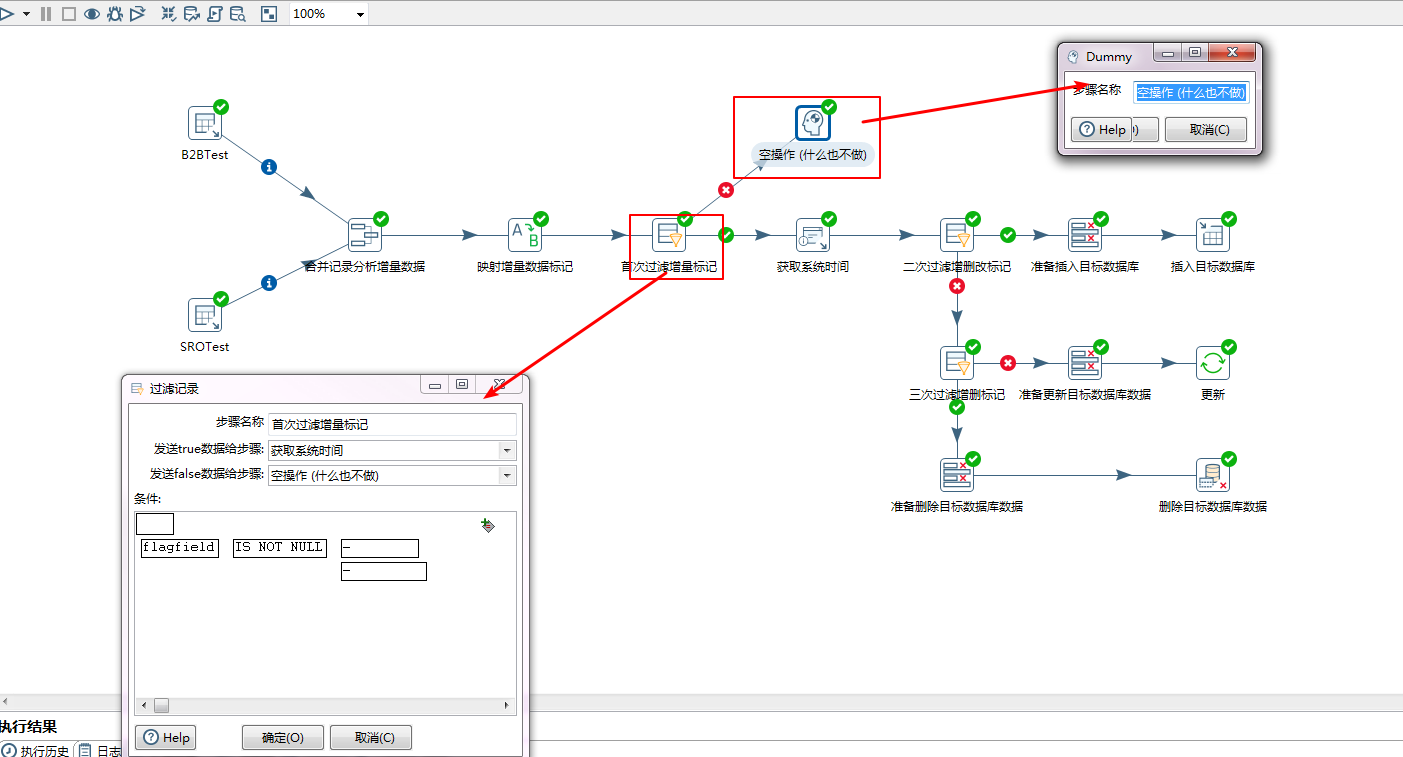
步骤五:获取系统时间
获取系统时间的目的是给数据打上时间戳并存入目标数据库,如果不方便存入目标数据库,放入一个中间表也行的。反正下次整理数据的时候要能搞到这个值。这里也是我不明白的一点,我并没有从目标数据库中查询这个时间戳,ETL如何找到这个时间戳,并知道哪些是该增加还是不该,哪些是该更新还是不该的。这个没有想明白,因为如果不加系统时间,你会发现ETL会全量删除,全量增加目标数据库的数据。加上这个时间,就会少量更新、删除、添加。如果有谁能看到这篇日志记录,烦请告知。
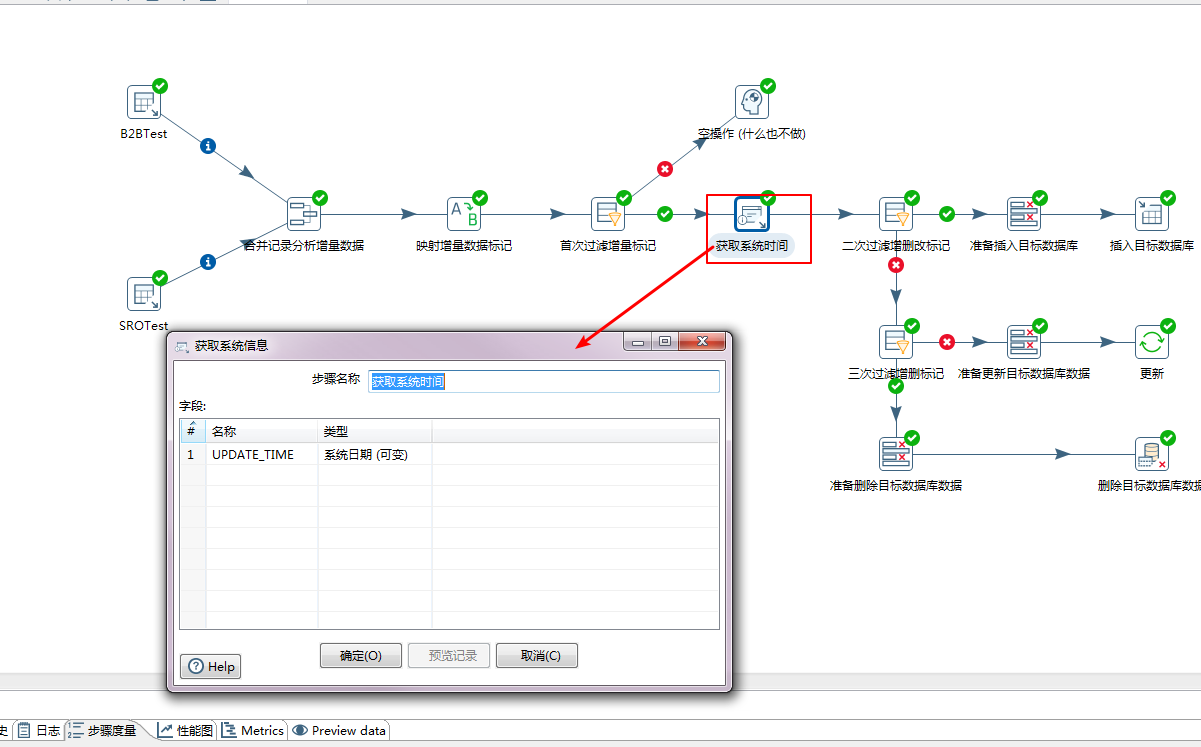
步骤六:第二次过滤增量数据标记。
本次会分离需要新增的数据出来,交给后续处理入库;更新和删除的数据,需要继续下一步的过滤。
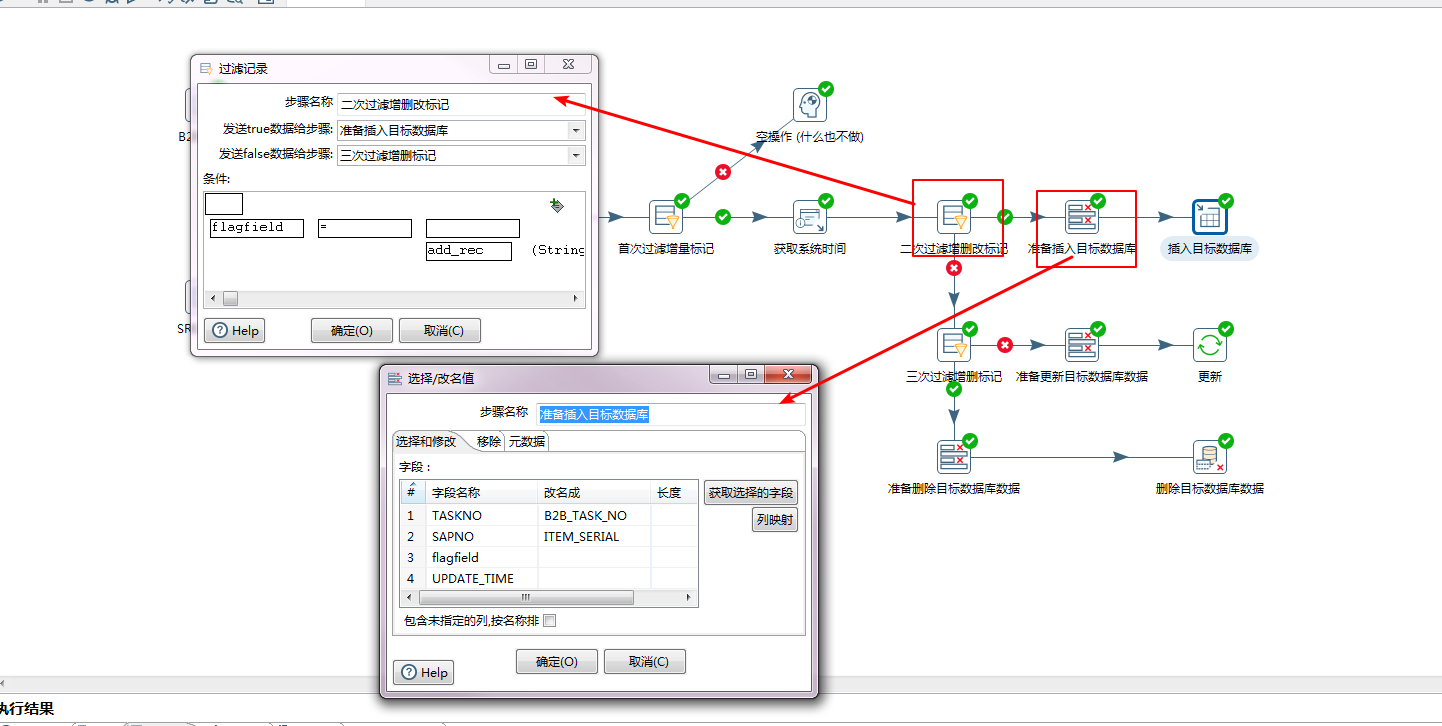
上图有两步,从flagfield中过滤出来需要新增的数据,然后抛给分支”准备插入目标数据库”,在这个子流程节点,会将流中的字段(字段名称),转换成数据库中的字段(改名称成),有两个字段flagfield和UPDATE_TIME无需转换,本来就是这个字段,所以无需添加”改名成”列。
之后就是插入数据库。这里有个坑,不要使用”插入”操作功能,要使用表输出。不知道为什么,使用插入操作功能,总会出现少量数据的误差。
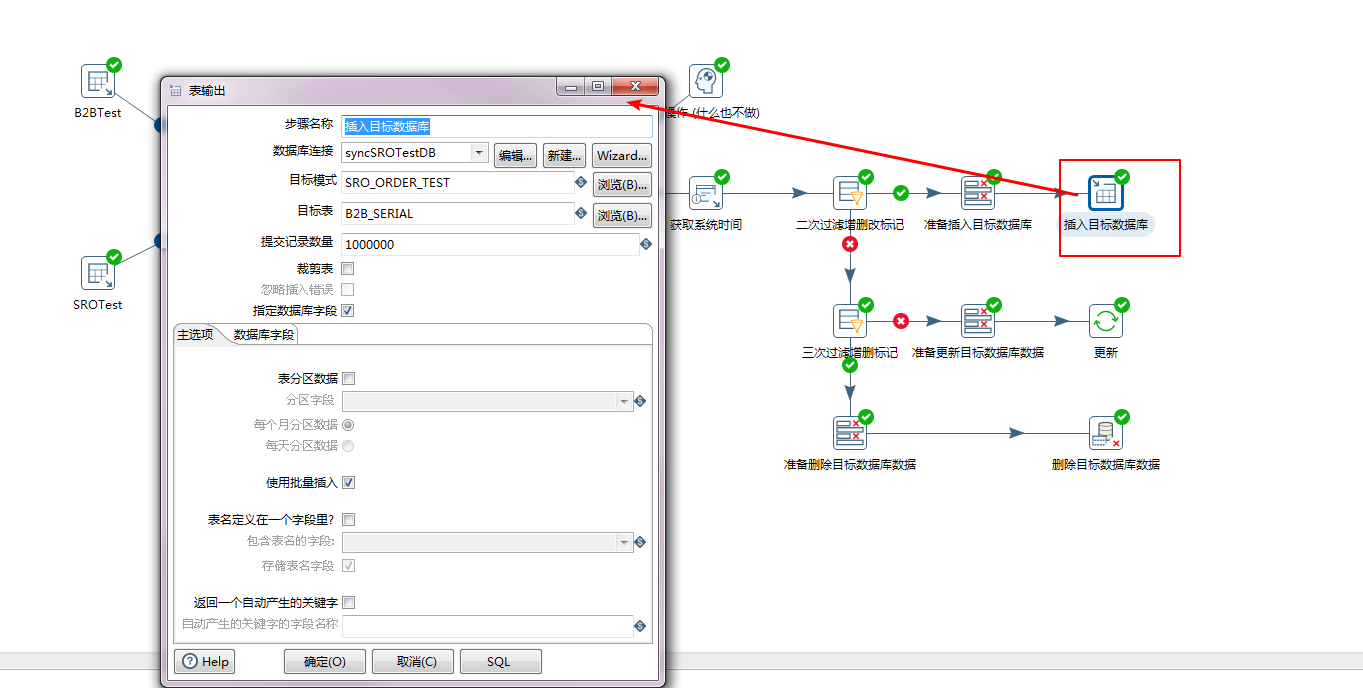
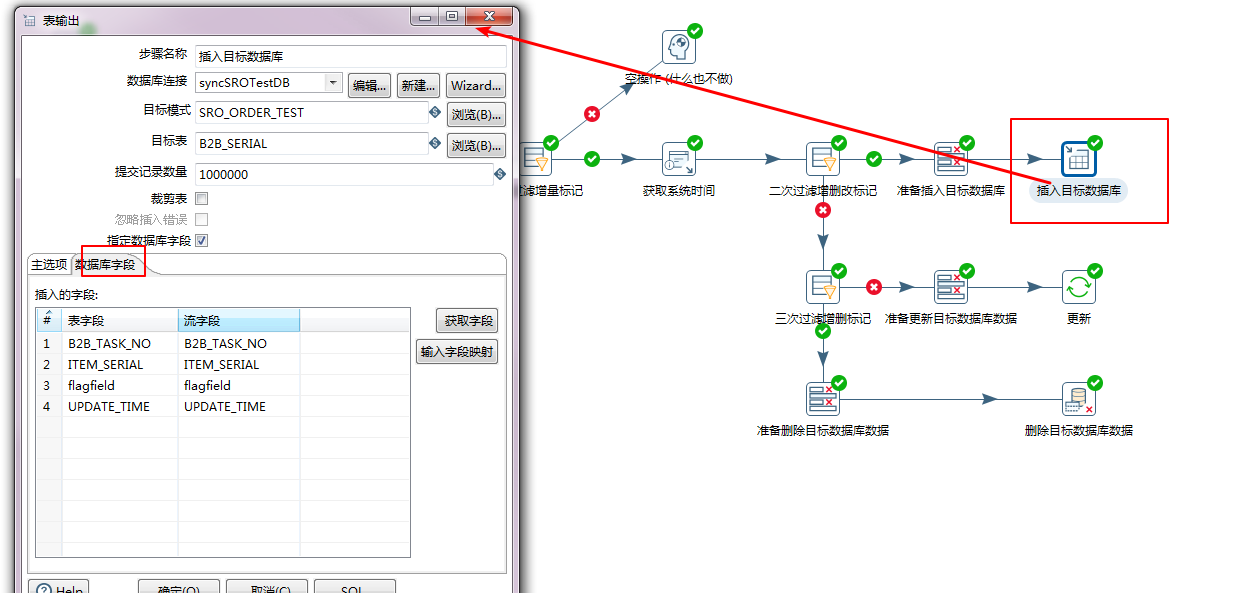
步骤七:第三次过滤增量数据标记
本次过滤的是剩下的更新和删除,这两种标记的数据均会被推入数据库中。
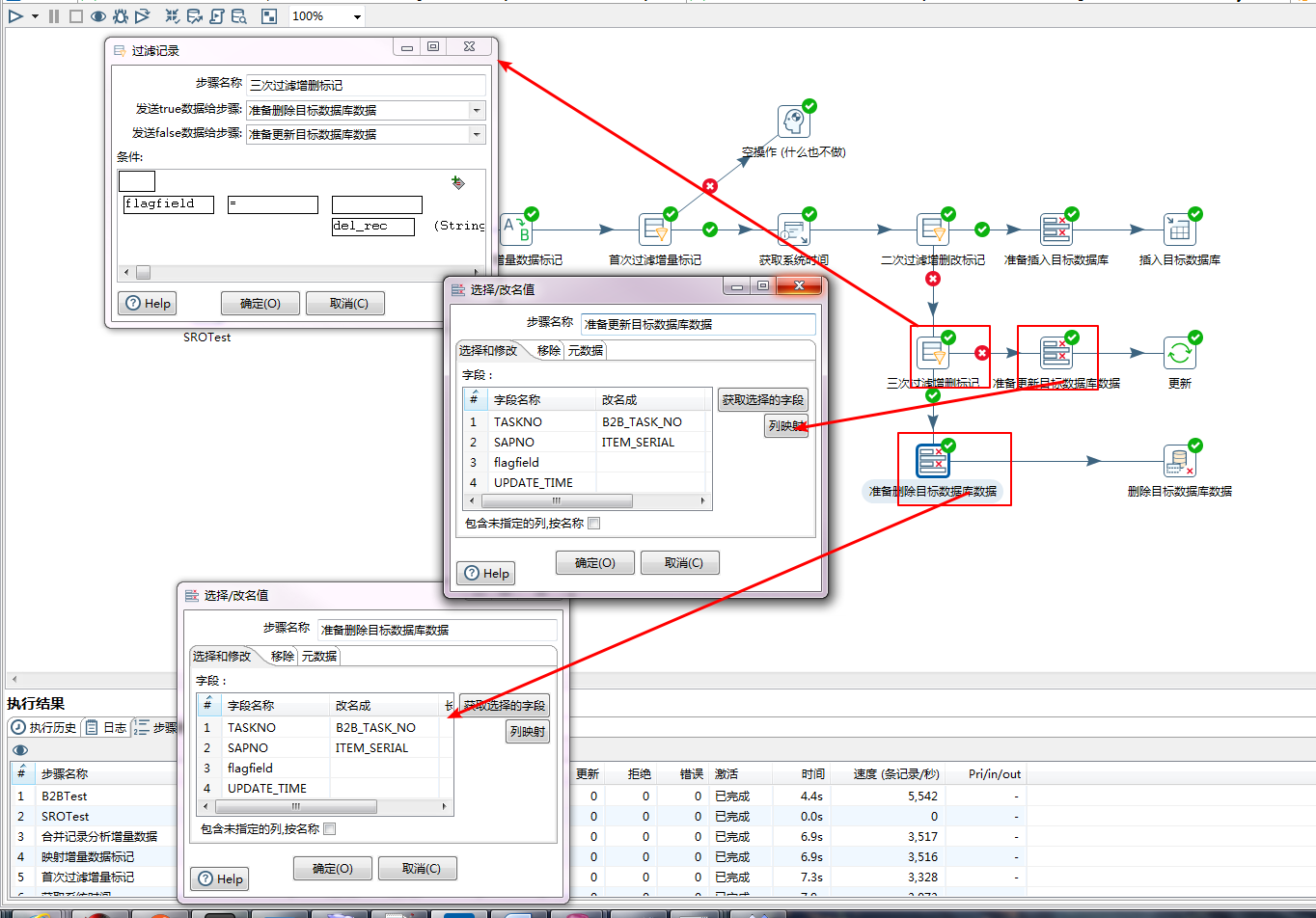
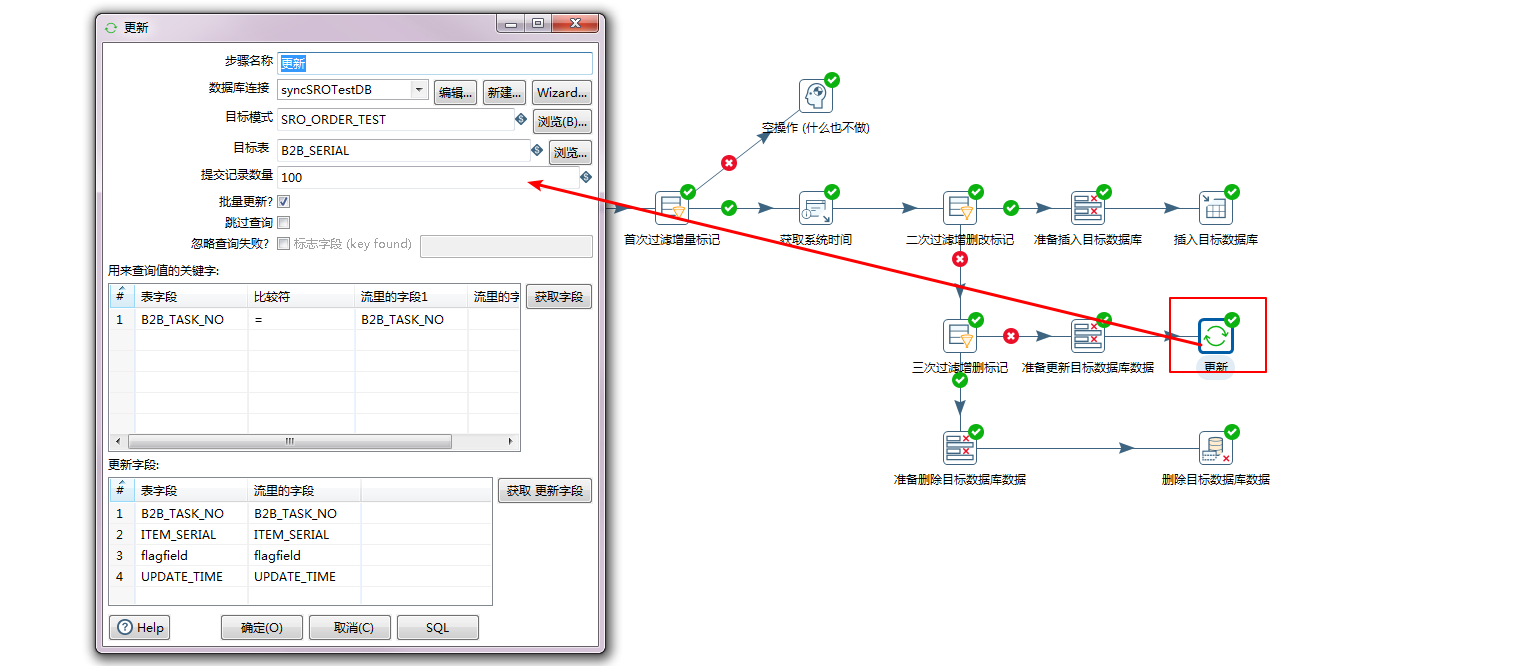
在后面就是更新和删除数据库了:
更新数据库:
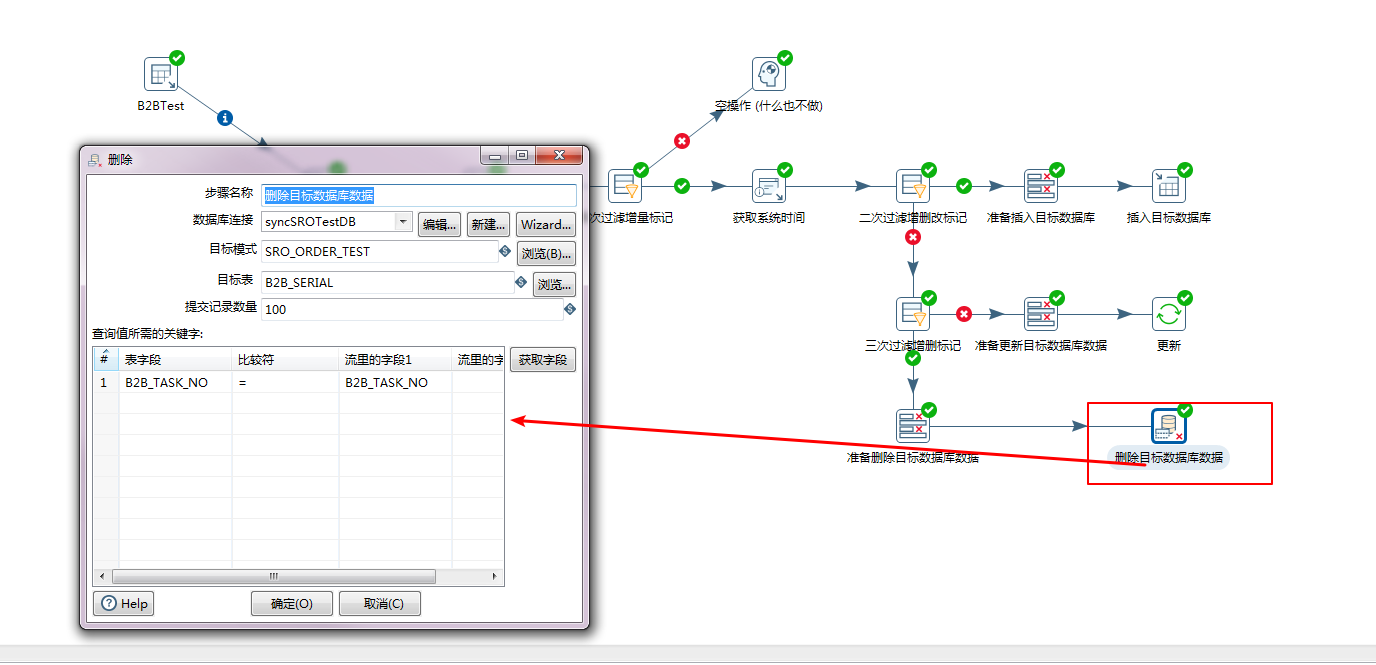
删除数据库:
以上就是一个流程的执行,如果要循环执行,则要开启一个作业,调用转换,设定定时循环的时间条件即可。
数据库的建立:
数据库的建立比较简单,需要将对应的连接jar放入目录下,百度一搜一大堆。只是在oracle上有点坑就是了。mysql连接比较简单,忽略不讲,oracle里,数据库名称实际指的是数据库对应的 sid,可以到oracle里查询,如果没有权限,建议你从数据库名称开始,后面加0、1、2等,基本上都会试出来。
OVER

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)