数据分析笔记
认识常见的数据指标DAU & MAU数据统计系统的定义DAU & MAUDAU(Daily Active User),日活跃用户数量;MAU(Monthly Active User),月活跃用户人数。DAU结合MAU一起使用,用来衡量服务的用户粘性以及服务的衰退周期。数据统计系统的定义预制报表的统计系统(友盟、百度统计、GA…)都是基于 事件上报 进行统计。(1)今天上报事件 →
数据分析
- 一、认识常见的数据指标
- 二、选好数据指标的通用理论(具体问题具体分析)
- 三、数据工具
- 四、数据分析
- 五、数据采集
写在前面:这些笔记是我在网络上看视频而记下的。
一、认识常见的数据指标
1.DAU & MAU
-
DAU(Daily Active User),日活跃用户数量;
MAU(Monthly Active User),月活跃用户人数。 -
DAU结合MAU一起使用,用来衡量服务的用户粘性以及服务的衰退周期。
数据统计系统的定义
- 预制报表的统计系统(友盟、百度统计、GA…)都是基于 事件上报 进行统计。
(1)今天上报事件 → 这个用户是活跃的
例如:1.用户访问页面,页面加载成功后会向统计系统上报Page View事件;
2 . 用户点击app按钮,按钮被点击,上报onclick事件。
(2)注意事件不一定来自用户主动操作,可能存在其他影响 - 业务上的定义
(1)用户执行了关键事件 → 这个用户是活跃的
(2)存在***维护成本***(需不断维护日活事件列表)和***沟通成本***(团队内外对【活跃】的认识需统一)
2.如何定义新增
2.1选择合适的节点,定义【增】
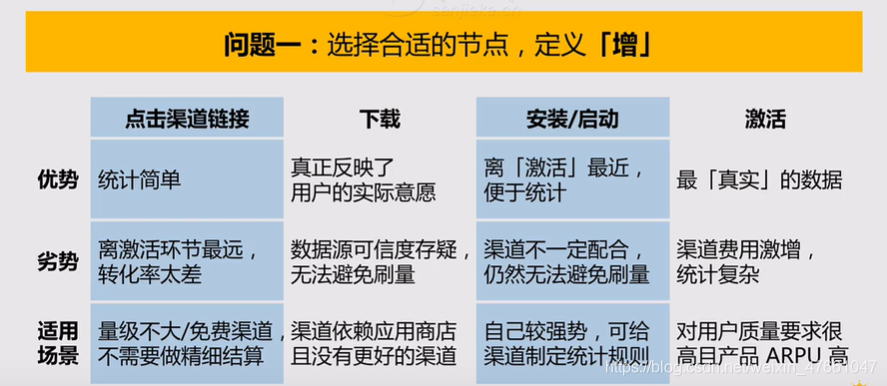
2.2用适当的方法,判别【新】

3.用户留存
3.1 为什么要看留存
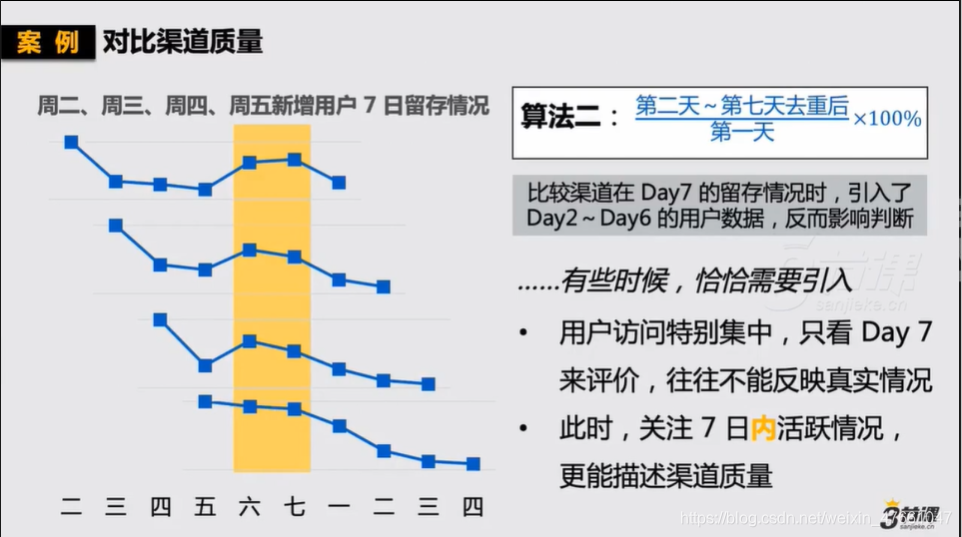
- 了解某一个渠道的质量——日留存
(1)以日为单位,衡量这个渠道来的用户当下&接下来的表现。
(2)以【x日日留存】作为比标准时,可以避免其他日数据的干扰。
2.观察整个大盘——周留存/月留存
(1)以周/月为单位,衡量产品的健康情况,观察用户在平台上的黏性。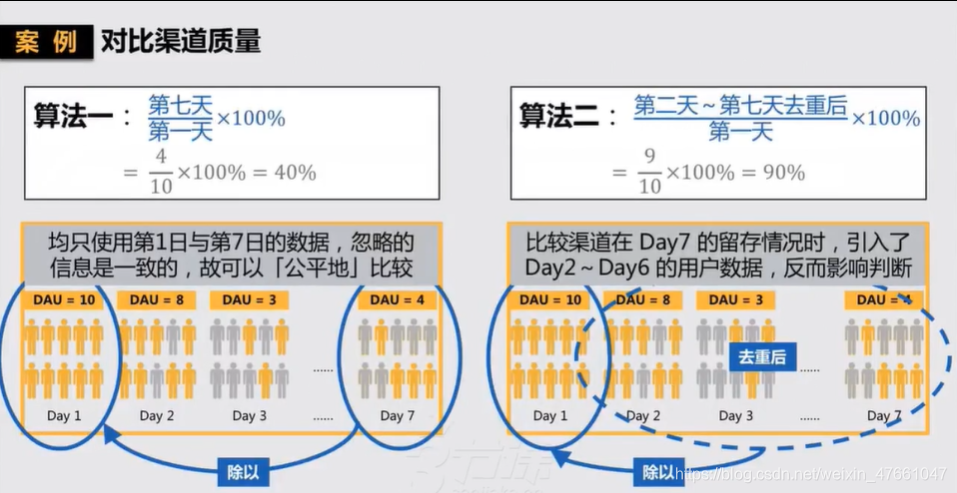

4.PV、UV、转化率、访问深度
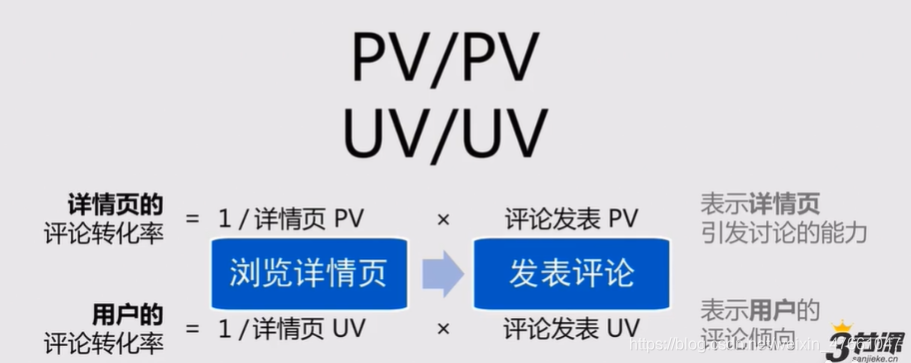
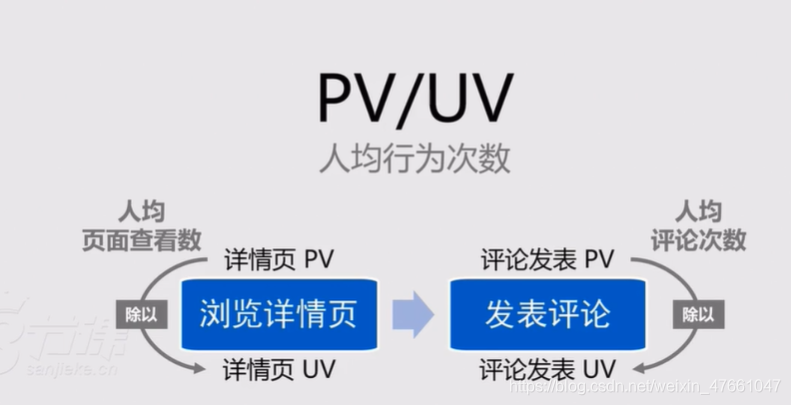
4.1Page View:页面浏览量(次数)
4.2Unique Visitors:独立访问数(人数)
4.3转化率
4.4访问深度:用户对产品的了解程度
4.4.1算法一:用户对某些关键行为的访问次数
4.4.2算法二:将网站内容/功能分成几个层级,以用户本次访问过最深的一级计算
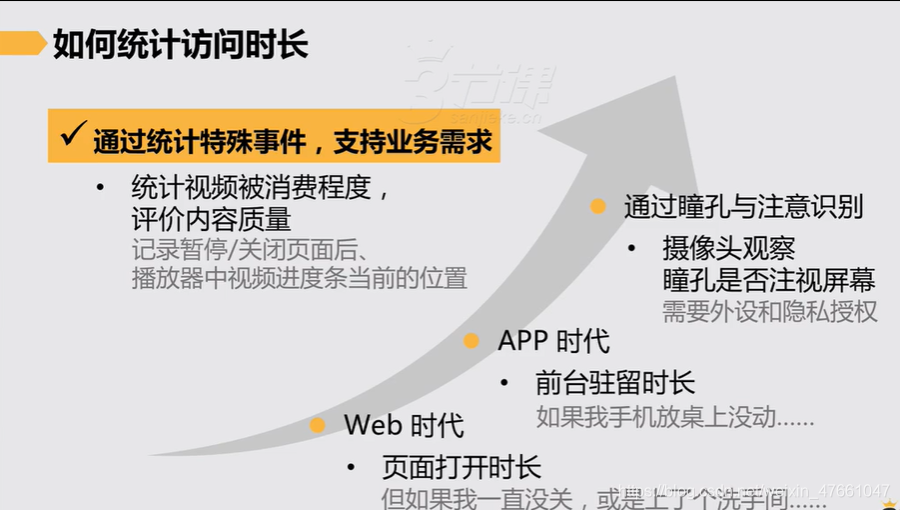
5.访问时长
5.1为何统计访问时长
5.1.1 通过统计特殊事件,支持业务需求
1.统计视频被消费程度,评价内容质量(记录暂停/关闭页面后、播放器中视频进度条当前的位置)
5.2如何统计访问时长
6.弹出率
基于单次会话,定义用户来了立马就离开,没有进行任何操作。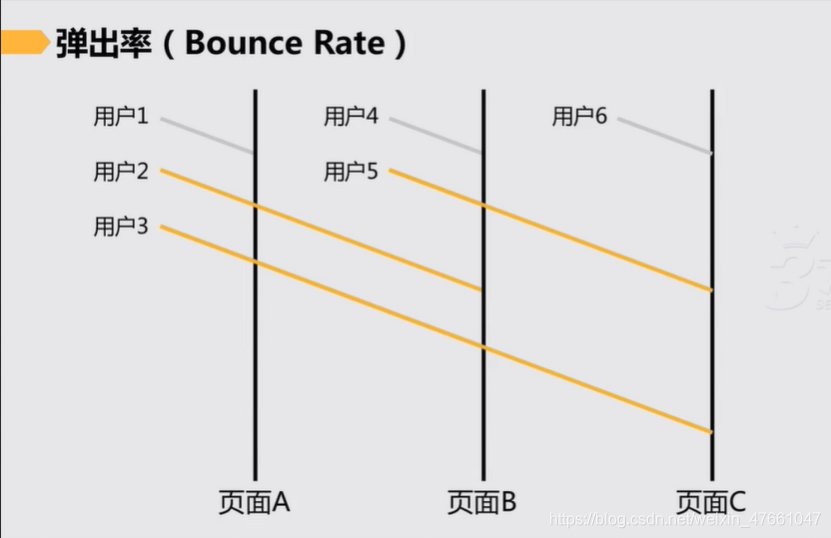
如图所示:用户1、用户4、用户6是被弹出的
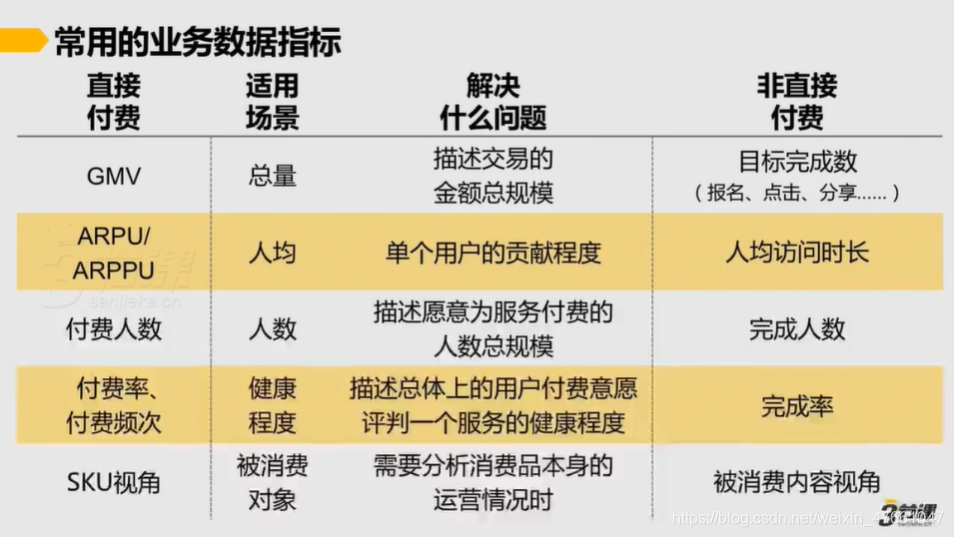
7.业务相关的数据指标
二、选好数据指标的通用理论(具体问题具体分析)
1.从业务的最终目的出发——梳理业务模块
1.1常见的拆解角度
(1)如何搞大/搞频繁(手段)
(2)往往有什么困难,我们通过什么特色方式解决的(工具)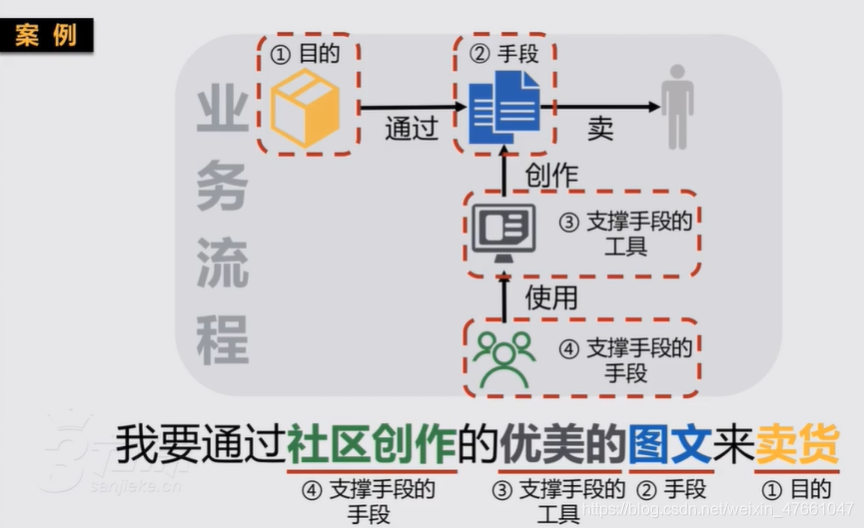
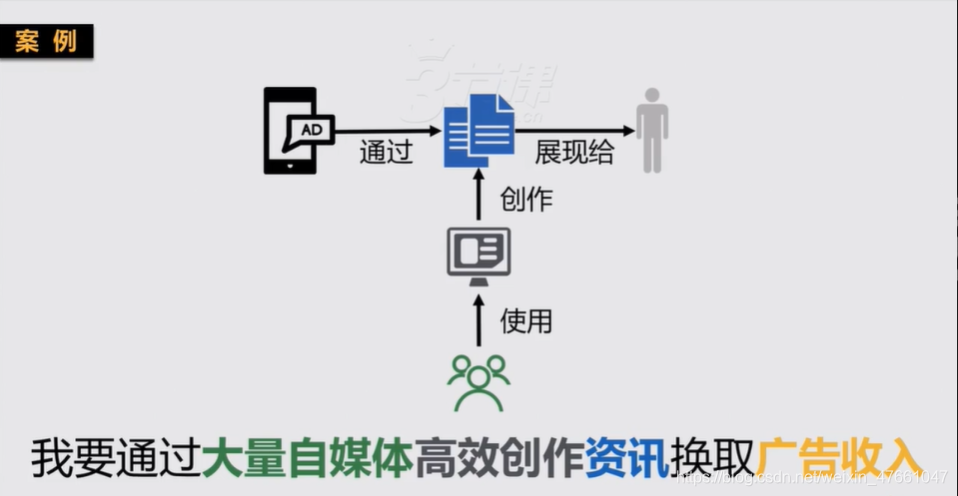
2.判断业务模块所属类型
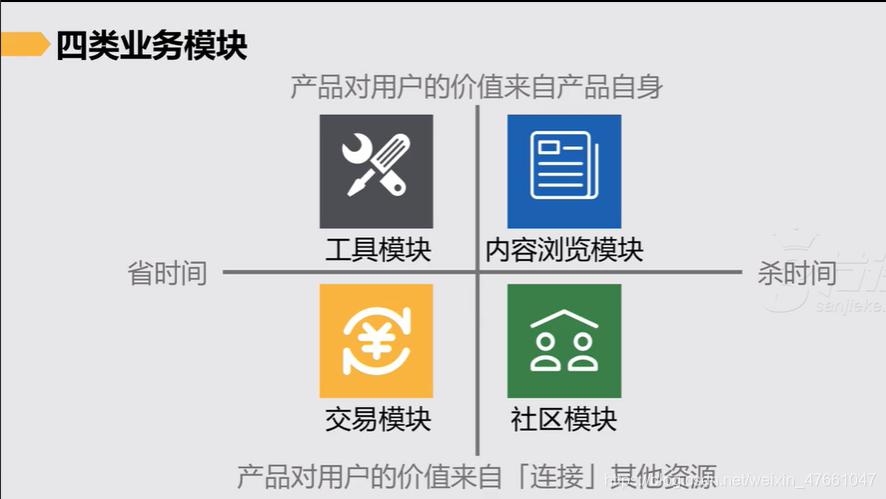
3.根据业务模块所属类型——选择数据指标
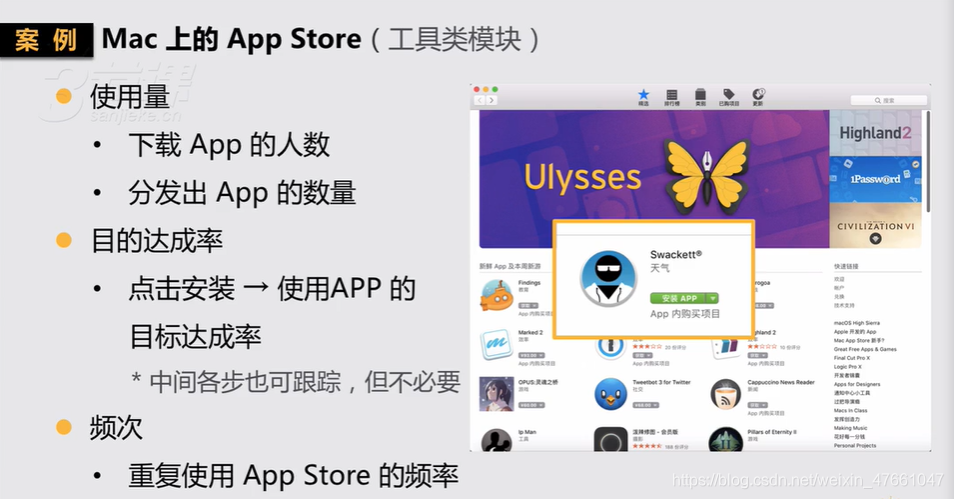
3.1 工具类模块 关心的指标

3.2 交易类模块 关心的指标


3.3 内容浏览类模块 关心的指标

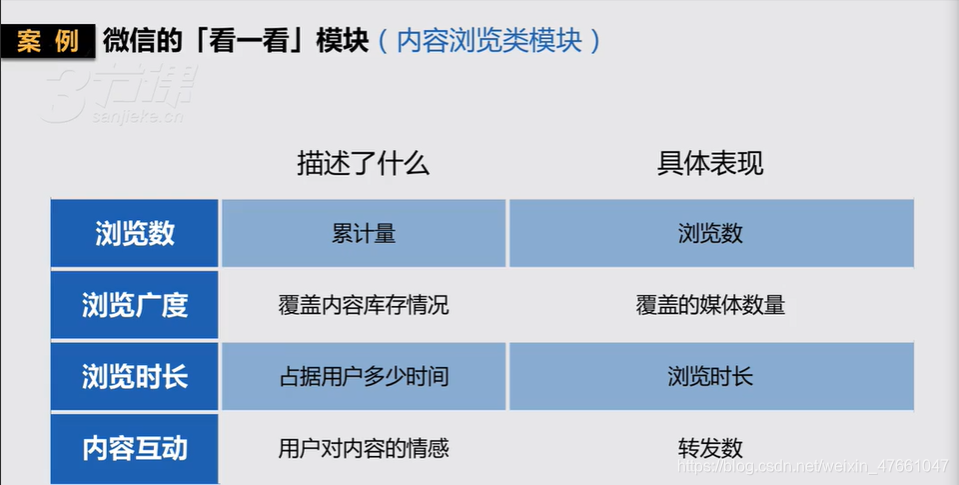
3.4 社区/社交类模块 关心的指标


4.iMoney 数据指标选取

5.咸鱼关注的数据指标

C2C是电子商务的专业用语,意思是个人与个人之间的电子商务,其中C指的是消费者,因为消费者的英文单词是Customer(Consumer),所以简写为C,又因为英文中的2的发音同to,所以C to C简写为C2C,C2C即 Customer(Consumer) to Customer(Consumer)。 比如一个消费者有一台电脑,通过网络进行交易,把它出售给另外一个消费者,此种交易类型就称为C2C电子商务。
6.土巴兔关注的数据指标(早年)
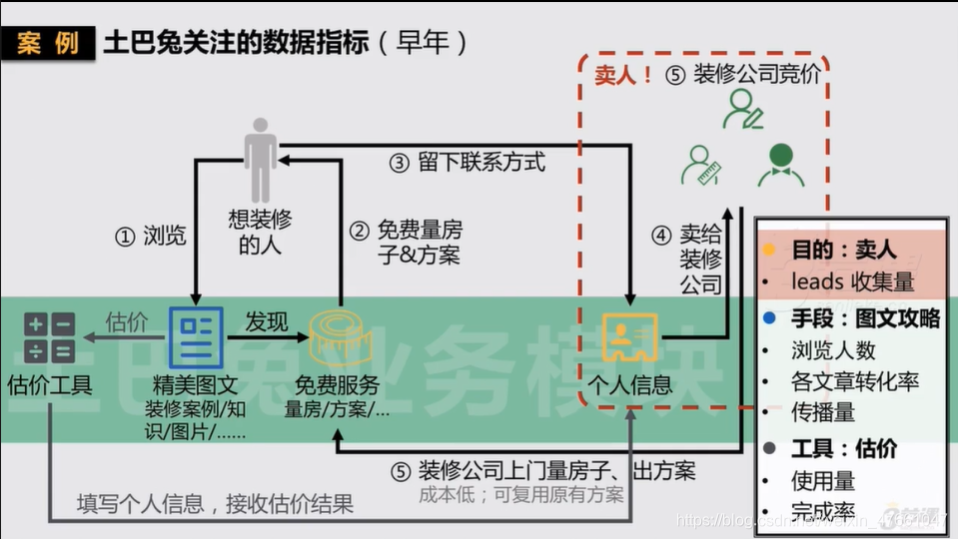
7.小结

三、数据工具
1.选择数据工具的核心逻辑
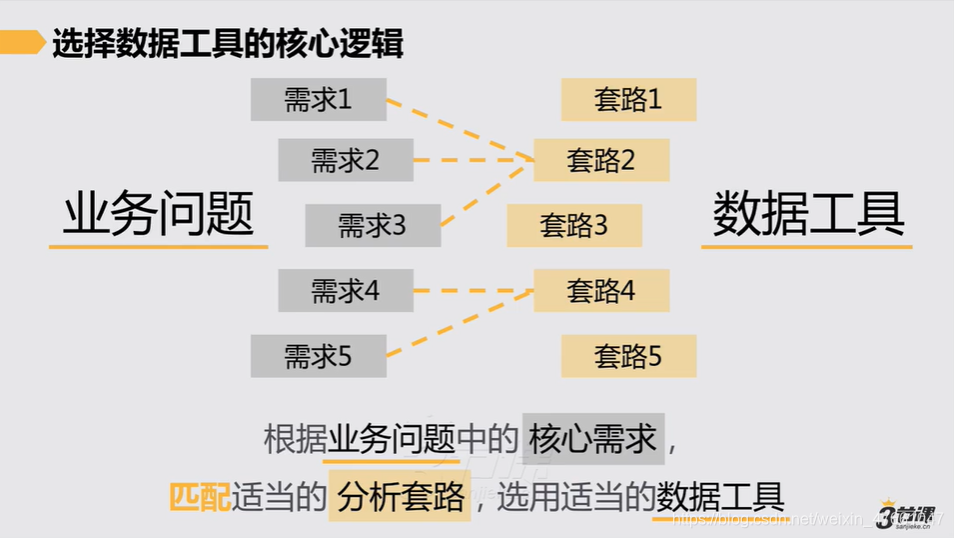
2.如何选择合适的数据工具
(1)数据工具能解决什么问题?
计数、流量、内容、用户、业务
2.1根据业务核心划分——公司缺了啥,最要命?
(1)案例1:社区类产品
懂球帝:用户导向 ——球迷长期留存
百度贴吧:内容导向——创作的文章成为百度搜索的内容来源
(2)案例:电商类产品
天猫、PDD、JD:规模化电商——流量快速变现
寺库:奢侈品电商——用户导向
(3)案例:视频类产品
优酷、爱奇艺:内容/流量导向
a站、b站:用户导向
2.2根据公司阶段划分
公司不同阶段关注的业务重点不同,需不同的数据工具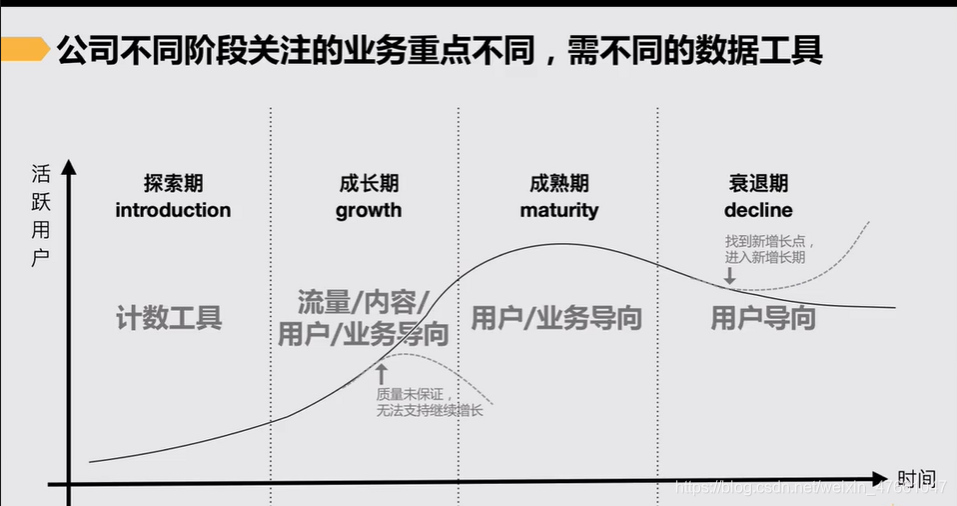
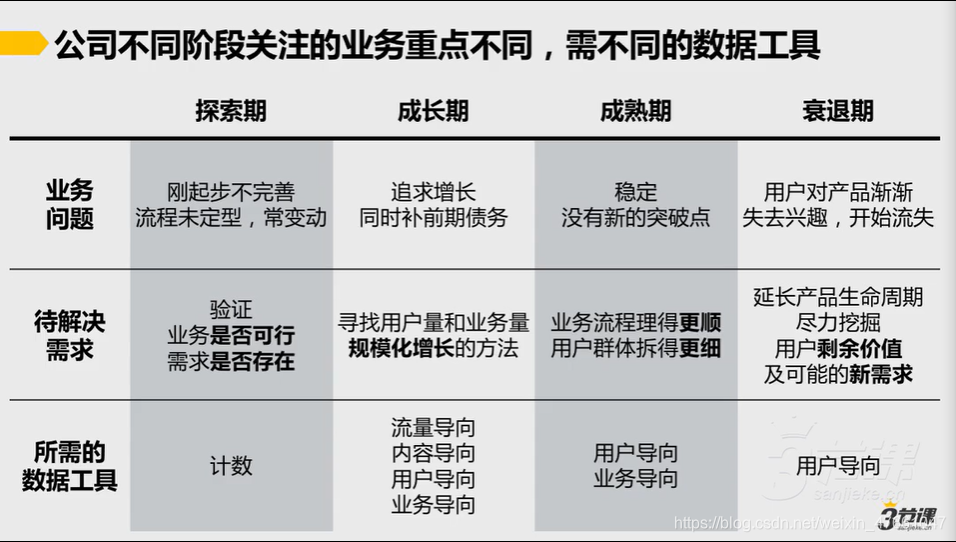
3.计数统计:快速验证
3.1解决的问题
计数,特别基本的一些分析功能
3.2优势
快,计算逻辑简单
4.流量导向:渠道依赖
4.1解决的问题
(1)谁来了?
(2)从哪来的?
(3)来了干什么?
(4)有没有达成目标?
4.2Google Analytics
自动化数据邮件日报、周报等
分享电子邮件发送
定时
预警功能
设置自定义提醒、备注功能
5.内容导向:质量第一
5.1解决的问题
以内容为核心资源的,如媒体、视频网站
5.2优势
能从内容的视角描述其表现
6.用户导向:用户为王
6.1解决的问题
(1)用户来了干什么?
(2)用户还会不会再来?
(3)用户在哪流失了?
(4)用户都是啥样的?
6.2优势
从用户视角描述单个用户的行为轨迹
7.业务导向:商业本质
6.1解决的问题
业务逻辑复杂,需要跟踪周期长
6.2优势
从商业逻辑上去还原整个业务流程,可接入线上-线下
四、数据分析
1.数据分析的价值
问题:
- 新购的这批视频到底有没有产生价值?
- 浏览到消费的转化率一直不超过1%,产品到底该优化哪儿?
2.如何进行对比分析
2.1比什么
(1)绝对值——本身具备【价值】的数字
- 销售金额
- 阅读数
- 不易得知问题的严重程度
(2)比例值——在具体环境中看比例才具备对比价值
- 活跃占比
- 注册转化率
- 易受到极端值影响
2.2怎么比
(1)环比:与当前时间范围相邻的上一个时间范围对比。
- 对短期内具备连续性的数据进行分析
- 需要根据相邻时间范围的数字对当前时间范围的指标进行设定
(2)同比:与当前时间范围上层时间范围的前一范围中同样位置数据对比。(当前时间:9月7日,上层时间:8月7日)。
- 观察更为长期的数据集
- 观察的时间周期里有较多干扰,希望某种程度上消除这些干扰
2.3和谁比
(1)和自己比:
- 从时间维度(连续数值:日活,月活…)
- 从不同业务线
- 从过往经验估计
(2)和行业比
- 是 自身因素,还是 行业趋势
- 都涨——能否比同行涨的多?
- 都跌——能否比同行跌的少?
3.如何进行多维度分析——数分的本质:用不同的视角去拆分、观察同一个数据指标
3.1案例:对【APP启动事件】的分析



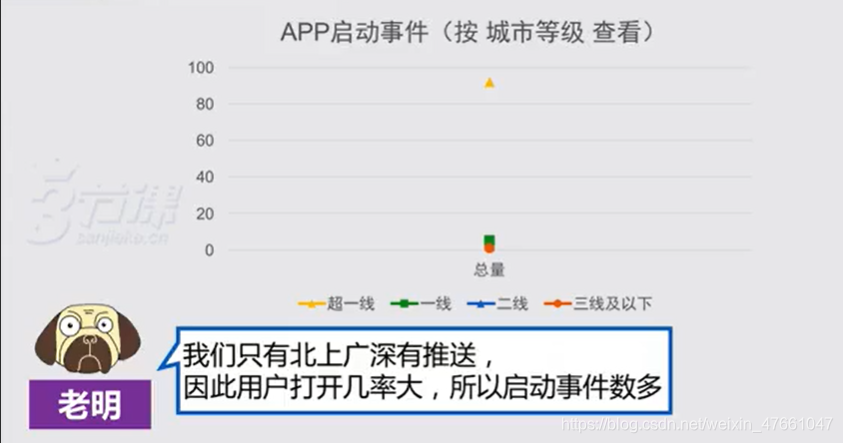
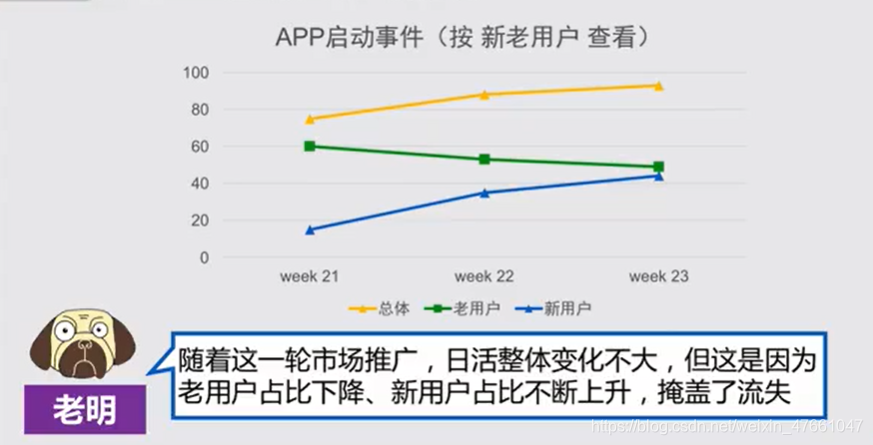

3.2对业务流程,拆解维度
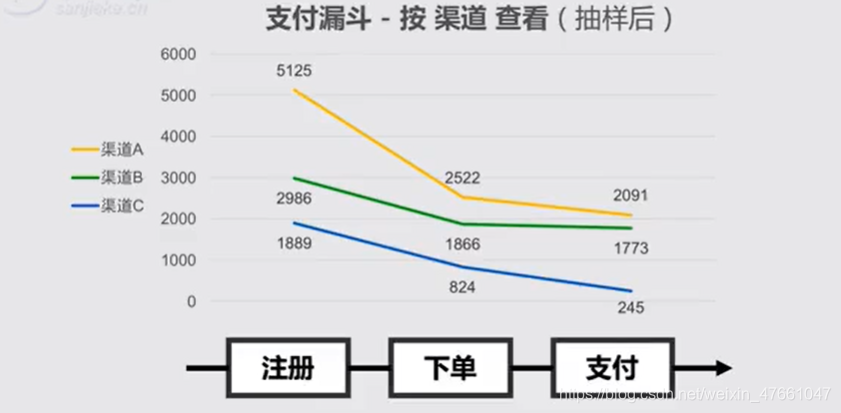
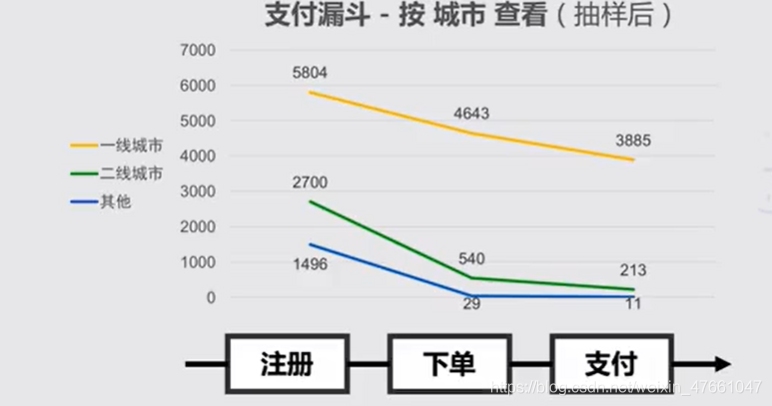
3.3多维度拆解的适用场景

4.数据涨跌异动如何处理
4.1案例1:对【收入跌10%】的应对
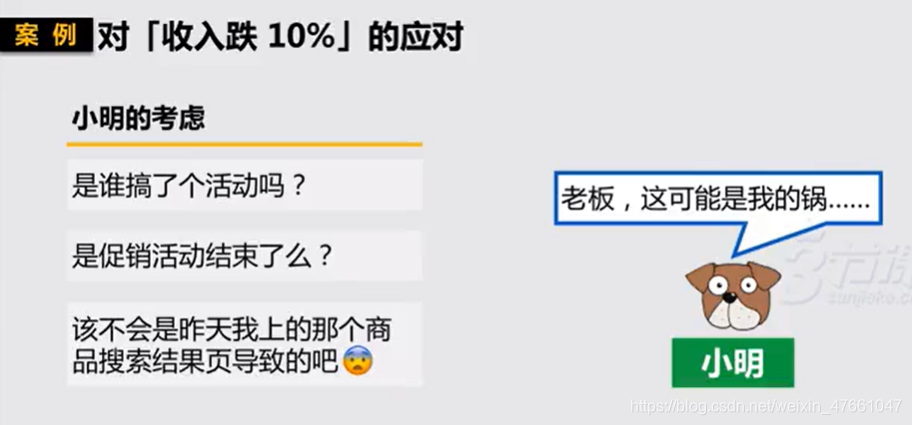
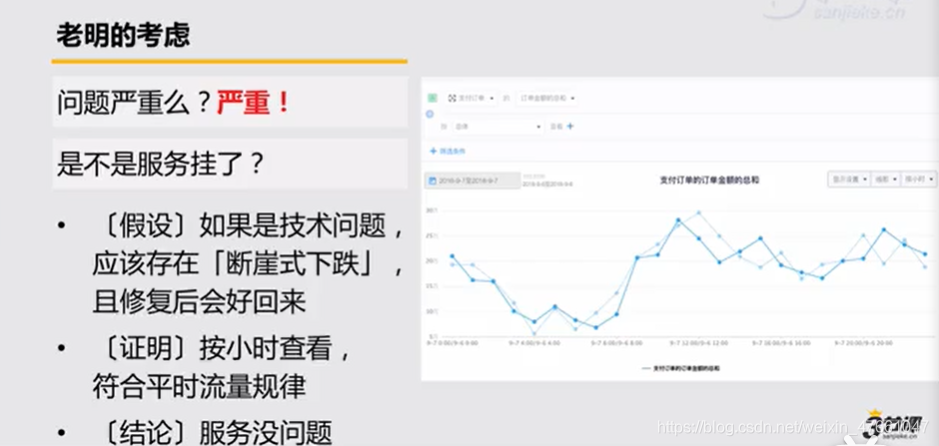
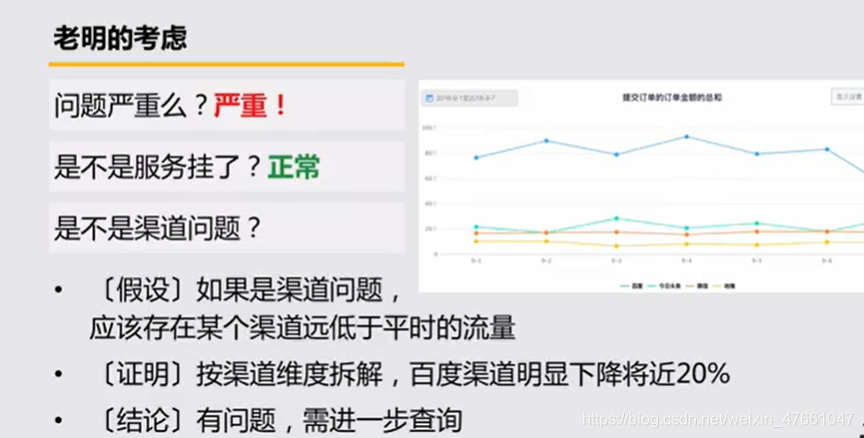
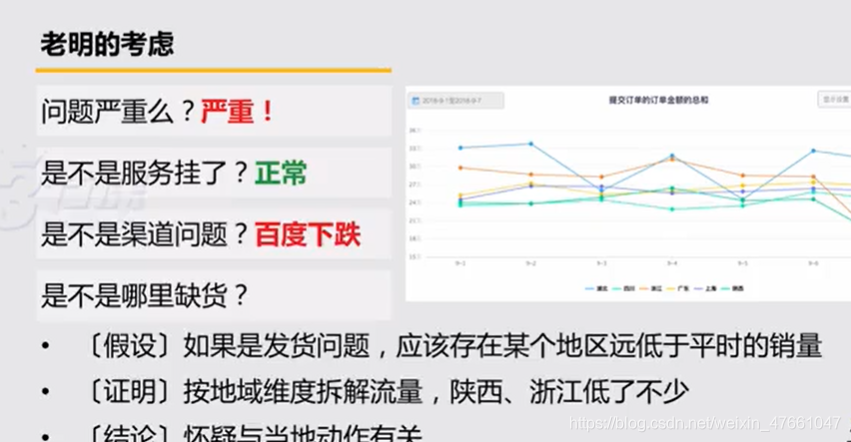


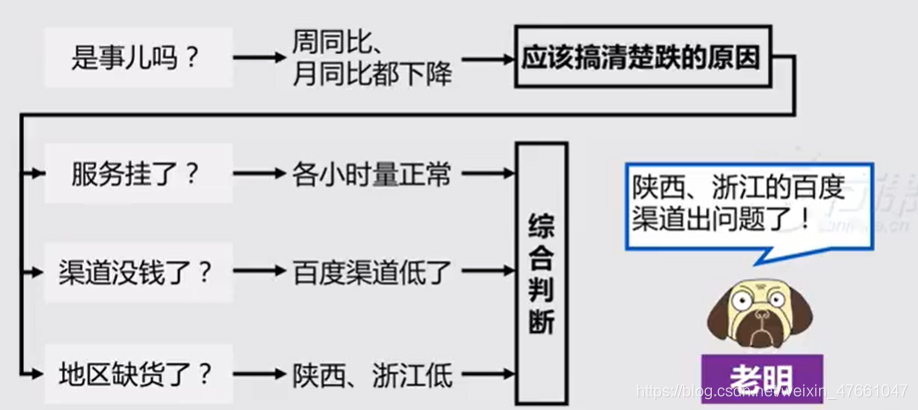
4.2常见的假设
- 活动的影响:查对应活动页面及对应动作的数据波动,关注活动是否有地域属性
- 版本发布:将版本号作为维度,区分查看
- 渠道投放:查看渠道来源变化
- 策略调整:策略上线时间节点,区分前后关键指标波动
- 服务故障:明确故障时间,按时间为维度进行小时或者分钟级别的拆分
4.3维度拆解分析是可以叠加的
案例:Web网页浏览量狂涨
按照浏览量来源拆分,发现未知来源;
异常用户按照地域划分,全来自北京;
按照浏览器拆分,大部分来自safari;
按浏览器版本拆解,safari用户无版本信息
4.4小结
发现异常——确定问题——确定原因——针对性解决问题——执行
5.漏斗观察的分析方法
5.1漏斗 = 一连串向后影响的用户行为
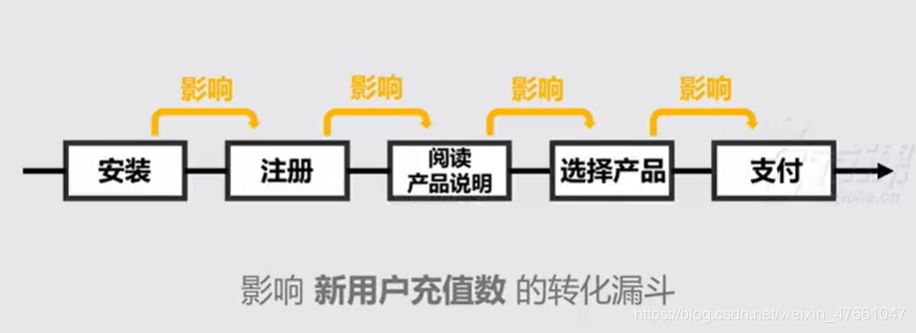
5.2 建立漏斗时容易掉的坑
- 漏斗一定是有时间窗口的
极端情况:
- 23:59分执行第一步,次日0:01执行第二步
- 用户在1月搜索商品,同年12月浏览了商品详情页
根据业务实际情况,选择对应的时间窗口
- 按天:对用户心智的影响只在短期内有效(如短期活动)
- 按周:业务本身复杂/决策成本高/多日才能完成(如理财/美股开户)
- 按月:决策周期更长(r如装修买房)
- 漏斗一定是有严格顺序的
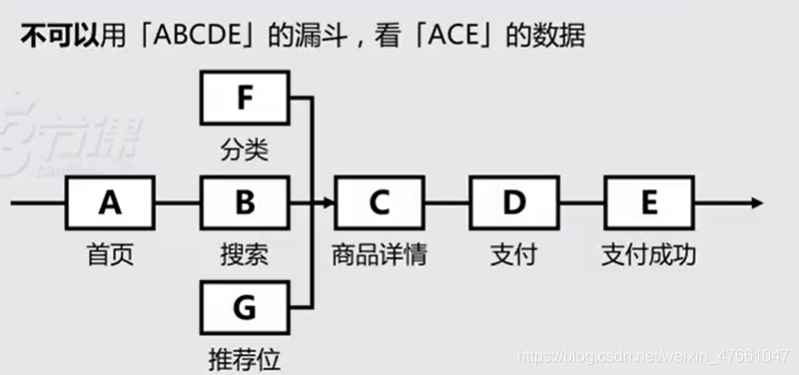
3.漏斗的计数单位可以基于【用户】、也可以基于【事件】
往往基于【用户】
- 三节课:
 * 关心整个业务流程的推动
* 关心整个业务流程的推动
也可以基于【事件】
- 关心某一步具体的转化率
- 无法获知事件流转的真实情况
- 结果指标的数据不符合预测
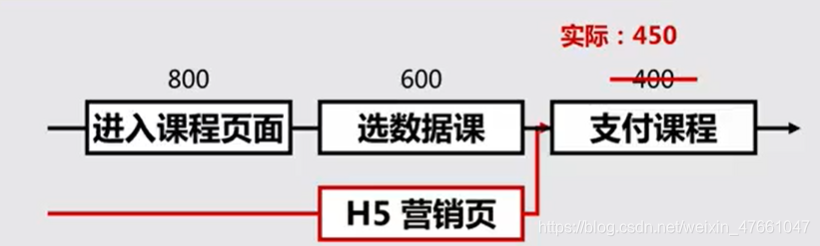
自查:是否只有一个漏斗能够到达最终目标
6.如何评估渠道质量,确定投放优先级
6.1常见的渠道划分方式

搜索引擎营销:英文Search Engine Marketing ,我们通常简称为“SEM”。简单来说,搜索引擎营销就是基于搜索引擎平台的网络营销,利用人们对搜索引擎的依赖和使用习惯,在人们检索信息的时候将信息传递给目标用户。搜索引擎营销的基本思想是让用户发现信息,并通过点击进入网页,进一步了解所需要的信息。企业通过搜索引擎付费推广,让用户可以直接与公司客服进行交流、了解,实现交易。
6.2渠道质量跟踪
1.选择关键事件
选取反映你产品目标人群会做的行为的数据
- ✔(电商)购买、(社区)发帖(可衡量各渠道来的用户是否为目标用户)
- ❌完成为期三个月的课程(门槛太高/流程太深,转化率极低,无区分度)
- ❌打开APP/访问首页(门槛太低,同样缺乏区分度)
2.查看产生关键事件的用户来源是哪
7.分布分析的方法
7.1分布情况
一个事件不仅只有累计数量这么一个可以观察的指标。
还可以从该事件在不同维度中的分布来观察。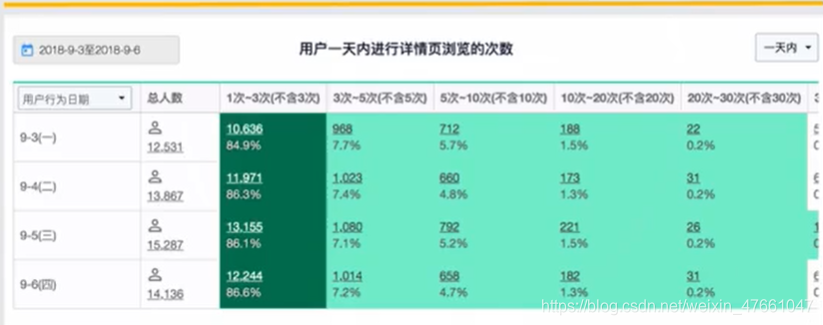
7.2常见的群体划分
- 事件频率
- 一天内的时间分布
- 消费金额的区间
7.3运作原理
- 从事件在不同维度中的分布来观察,以便理解该事件除了累计数量和频次外,更多维度的信息。
7.4适用场景
- 已知一群用户完成了指定事件,但需要对用户群体进行细分,按不同的维度和价值将他们划分为不同群体,分别进行后续的维护或分析。
- 已知单个事件的完成次数,希望知道这些次数拆分到不同维度上后的分布情况,以便更清晰地了解该事件的完成情况。
8.用户留存的分析方法
8.1适用场景
- 验证产品长期价值
- 评估产品功能粘性
8.2留存
1.一般的计算方式
- 将某一段时间段的用户ID与另一段时间段的用户ID做交叉去重
- 产品、运营、技术、市场每个环节都会对留存造成影响
2.精准留存
- 过滤进行过指定行为的用户ID,再计算
- 将用户分为不同的群体后,观察其之间留存的区别
9.功能内容上线后,如何评估?
9.1某批漫画对付费会员转化的效果评估

- 上线后的目标与价值清晰明确
1.借助漏斗对比(转化关系明确时)
2.借助用户分群对比(转化关系较复杂时)
9.2某一主播对产品价值的影响(以用户留存衡量)
难点:
- 某些功能不能带来直接的商业价值,但希望它能长期留住用户
- 留存是一个特别复杂的构成,谁都可能影响它
- 因此需要看精准留存——上线后关注其对产品价值的提升
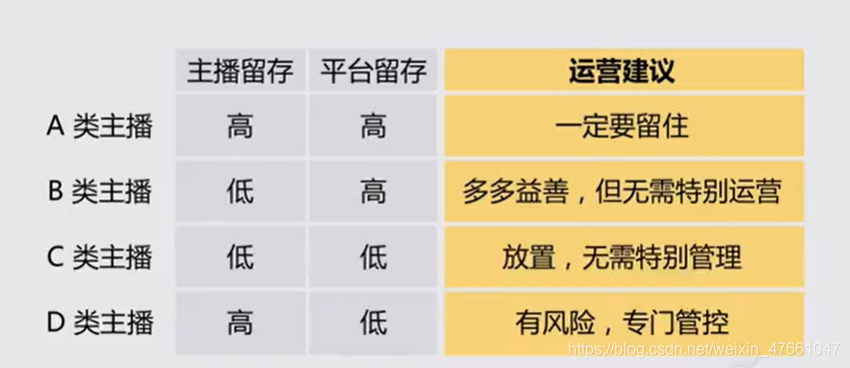
9.3一个功能/内容上线后,如何评估其对产品长期潜力的价值?
-
从对使用情况的促进作用来观察
- 某社交APP:本来一天只用一次,好友推荐功能发布后,一天用2~3天。
-
从占据用户一日时间段的角度来看观察
- 某播客产品:本来只在上下班通勤时使用,情感内容上线后,深夜段使用用户数提升。
-
上线以探索更长期的产品潜力
- 借助分布情况分析,对比其是否优化了使用频次/场景的分布
10.用户画像的分析方法
10.1用户画像
- 通过对用户各类特质进行标识,给用户贴上各类标签
- 通过这些标签将用户分为不同的群体,以便对不同的群体分别进行产品/运营动作
10.2标签

10.3标签从哪来
1.直接填写(注册时、兴趣标签、外卖快递地址、装修计算器)
2.通过用户自己的已有特质推得
- 何时需要?
- 做活动
- 简单的个性化运营
- 业务分析
- 用户研究(准备)
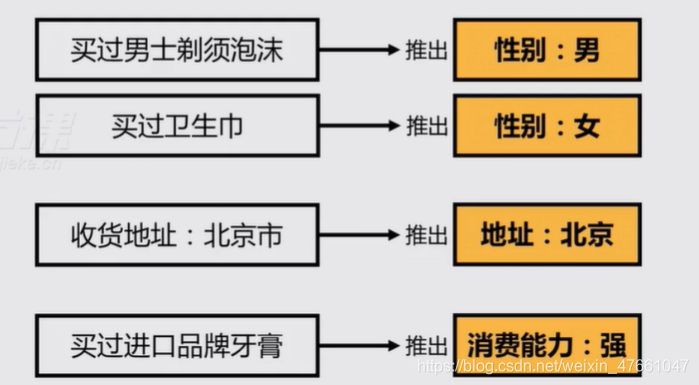
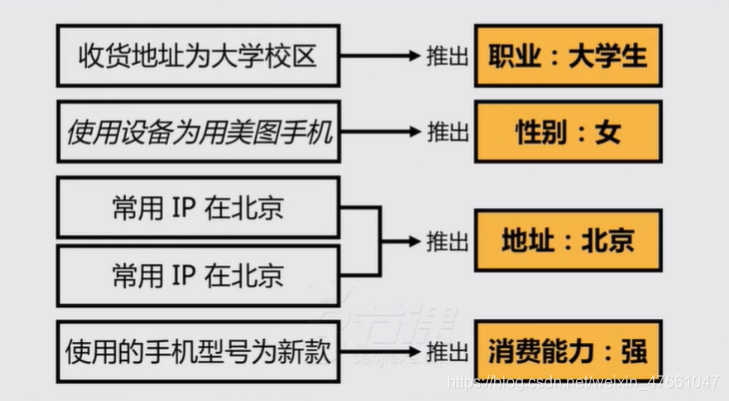
3.通过用户身边的人推断
- 距离相近
某些属性,周围的人都具备,用户大概率也具备 - 行为相似
通过协同过滤,找到行为相似的目标用户
10.4适用场景
市场营销、个性化运营、业务分析、用户研究
11.如何高质量拉新
11.1思路
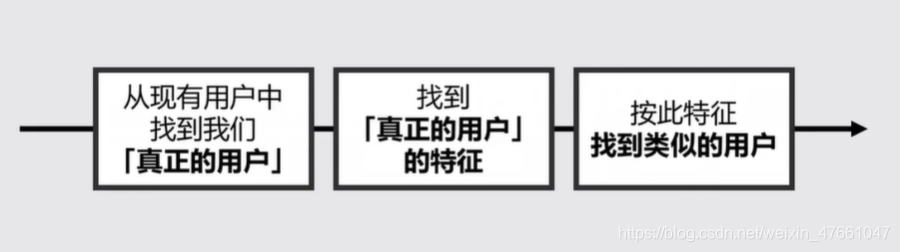
11.2从现有用户中找到我们【真正的用户】
- 高留存
- 核心行为频次、完成率高
11.3找到【真正的用户】的特征
- 是谁
- 例:通过他们买卖的书籍,倒推他们的年龄、受教育程度、地域、消费能力。
- 从哪儿来
- 例:通过电话访谈等方式,发现很多来自朋友推荐。
1.4按此特征,找到类似的用户
- 用户画像
- 高校、科研院所、知识密集型工作区域
- 消费倾向社科类书籍
- 渠道来源
- 用【人拉人】而非【广撒网】地投放
12.如何进行归因查找
12.1归因查找
找出事件发生的【主要原因】
12.1归因查找的适用场景
对业务中明确的业务目标(购买、留资料、冲资料)归因,便可…
- 将目标的达成拆分到各个模块,方便统计各模块的贡献
- 获悉当前指标达成的主要因素,获得如何提升业务指标的洞见
12.3方法
- 末次归因转化路径短,且事件间关联性强的场景

- 递减归因转化路径长,非目标事件差异不大,没有完全主导的

- 首次归因强流量依赖的业务场景,拉人比后续所有事都重要

13.如何精准运营推送
13.1精准运营
- 运营资源盘活
- 不同人在同一个运营资源位上得到不同的信息
- 需要在【千人千面】和【千人千面】之间找到ROI的平衡
- 推送内容与用户【有关】
- 基于用户真实的动作,调整推送内容;
使其感到推送是【因我而来】(而非自己是被批量推送的分母之一)
- 基于用户真实的动作,调整推送内容;
13.2运营资源盘活
- 常规做法 出台一套运营资源使用规则

- 推荐做法 精细化的用户分群运营
- 既能提升整个公司的可用资源,也能提升收到推送的用户自己的体验
13.3【千人?面】
- 理想:每个标签都去做不同的推送内容
- 【千人一面】运营力量有限:哪怕将用户精确地分成一千个群体,运营团队也很难每天都去编一千条不同的推送文案和页面
- 现实:在ROI找到一个平衡点,先选择容易出成绩的
- 容易出成绩的标签:如 电商的性别标签
- 容易出成绩的运营位:如 首页/每日推送
【千人十面】往往就已经解决了80%的问题,7~8个标签往往足矣
13.4如何选择最初的七八个标签
-
人口统计学意义上的标签,如性别、年龄或者地域
- 【电商】性别影响商品偏好
- 【k12教育】地域影响教育水平、教材的选择、考察的侧重点
-
业务相关的标签
- 【k12教育】年级影响所学的内容、关注的信息
- 【健身】BMI影响用户对功能和内容上的诉求
-
推送内容与用户

14.路径挖掘的分析方法
14.1原理
1.逐级展开某一事件的前一级(后一级)事件,观察其流向
14.2适用场景
- 有明确的起始场景
- 有明确的结果目标
3.局限:无法观察具体的个体的行为
15.行为序列的分析方法
15.1原理
将单一用户的所有行为以时间线形式排列
15.2适用场景
观察具体的行为特征
16.如何辅助产品设计
16.1辅助产品设计决策
- 谁
- 用户画像
- 在什么情况下
- 行为序列的属性
- 干什么&遇到什么问题
- 行为序列 or 屏幕录像
17.羊毛党盛行——如何快速查出是谁在薅
17.1抓作弊的方法

- 找到【1】位
- 发现数据异常
- 异常且无理由的流量
- 工作人员观察
- 人工举报
- 发现数据异常
- 找到模式
- 明确其目的
- 刷量
- 薅羊毛
- spam
- 观察其特质
- 机刷
- 人肉刷
- 多:显著与普通用户相异的的动作,如通过商家变现、发布特定内容等。
- 少:留存低、非核心业务(如帮助界面)几乎不访问
- 明确其目的
- 找到【N】
- RD爬取并人工审核
- 一网打尽
- 封
- 封禁/封禁权限/屏蔽/定向屏蔽
- 提高关键成本
- 前:注册7日后方可发帖
- 中:减少存在bug的商品的库存
- 后:提高提现的审核力度/周期
- 不做处理
- 封
五、数据采集
1.数据埋点与数据需求文档
1.1数据埋点:线上数据采集
- 困境一:自己理不清
- 要啥数据
- 有啥属性
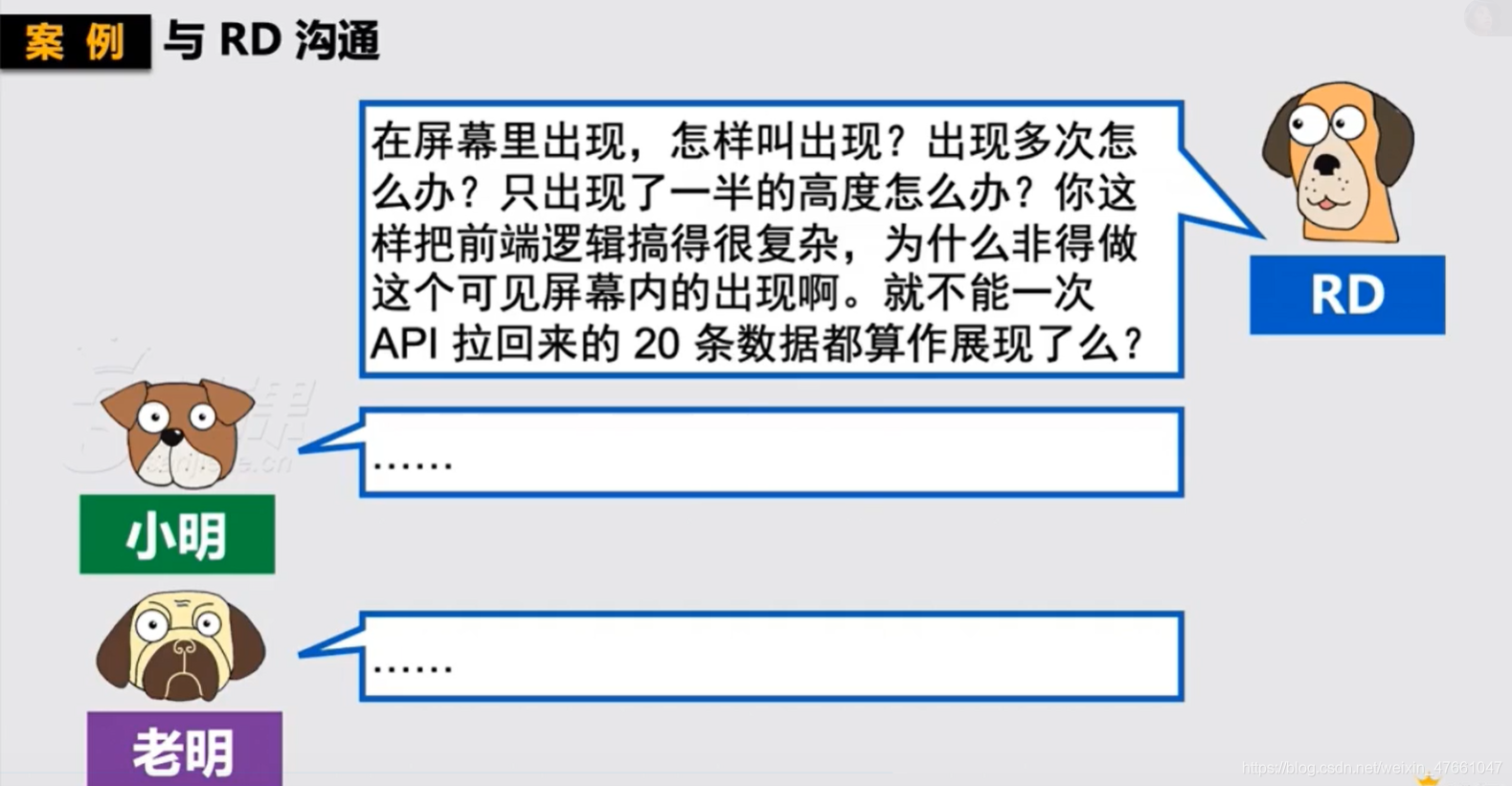
- 困境二:RD听不懂
- 前端采集 or 后端采集?
- 跨越前 —— 后端取值?
1.2数据需求文档(DRD)
1.埋点需求
2.埋点实施过程中的细节
2.明确埋点需求
2.1 归纳需求


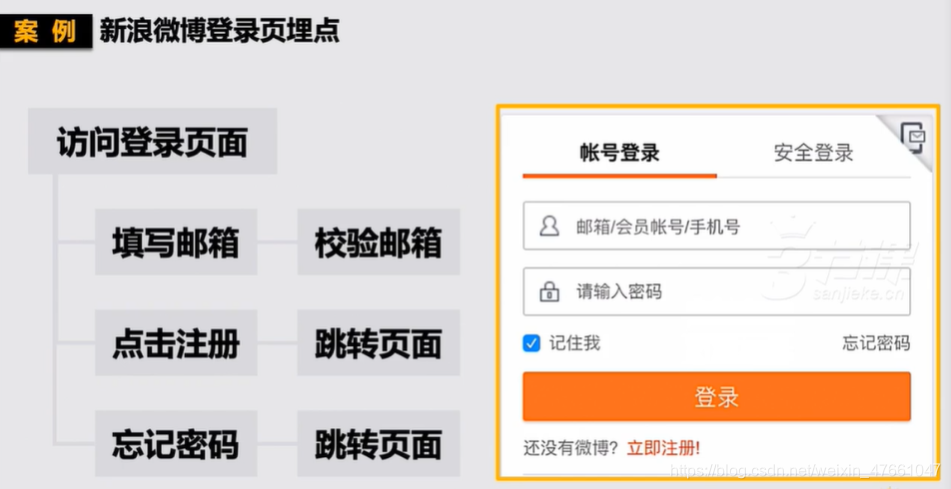
2.2选择适当的埋点属性
- 依据经验,预先按分析维度设计属性
- 较为依赖分析经验
- 频繁添加埋点,则需要RD密切配合
- 根据套路,预先设计埋点属性

1.Who
- 认设备
- web:cookie
- ios:UUID、IDFV、IDFA
- Androdi:UUID、Android ID
- 认人
- 线上:UID、微信等第三方 Union ID / Open ID、手机号、身份证
- 线下:手机号、身份证
2.When
- 问题一:哪个节点的时间

- 问题二:哪个时区的时间
- 上报时间时,带时区
- 使用Unix时间戳
3.Where
- GPS:往往还需通过API取得详细地址信息(国家/省/市/街道)
- IP:统一分配给运营商,相对比较粗略,可通过三方反查所属地
- 自主填写:相比用户真实位置,更关心用户希望在哪儿(如:装修买房)
4.How
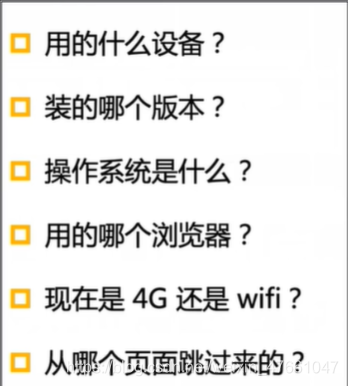
5.What
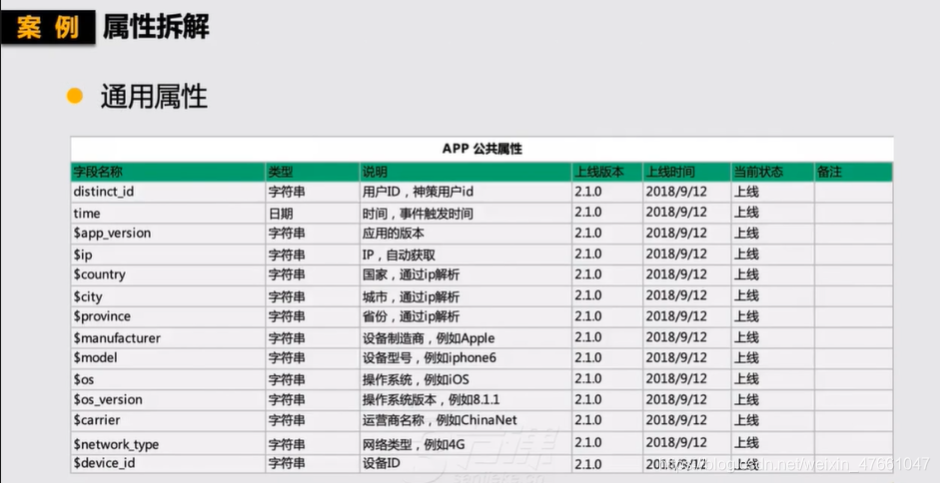
2.3公共属性
公共属性部分统一取值、维护
2.4事件聚类
3.形成需求文档
3.1埋点位置选择
除非某个行为只在前端发生
否则,建议永远在后端采集
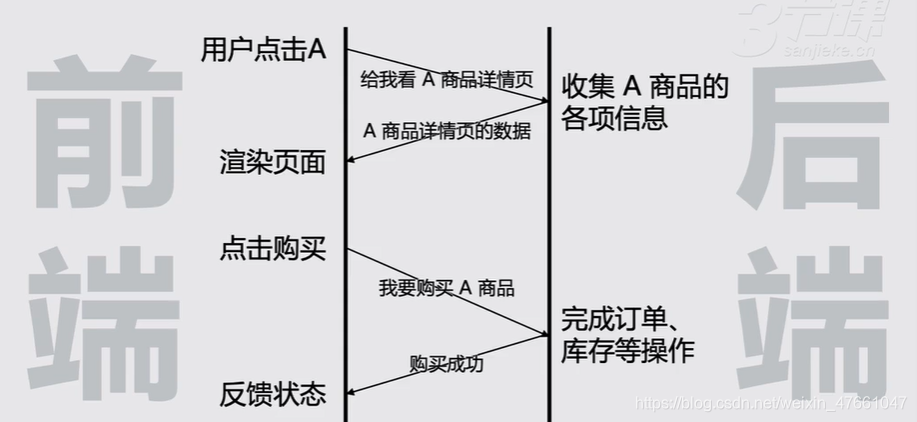
3.1.1前端埋点的弊端
- 某些属性前端没有
- (where/)what/how的许多信息,往往只存在于后端
- 改动依赖产品发版
- AppStore需审核、web发版也有排期,响应速度不如后端
- 事件上报时机略尴尬
- 需要在省流量/省电和及时性之间取舍
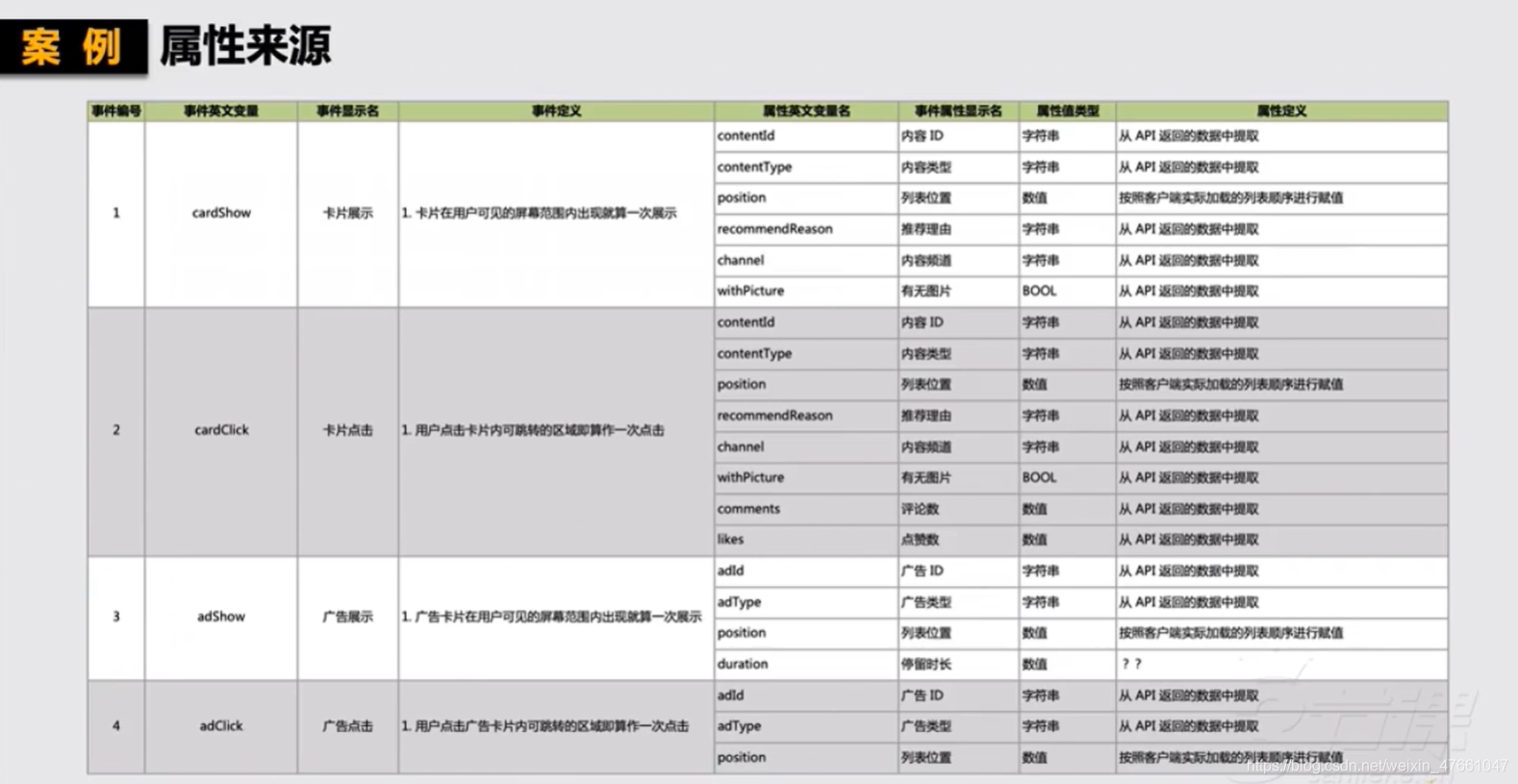
3.2埋点属性的来源

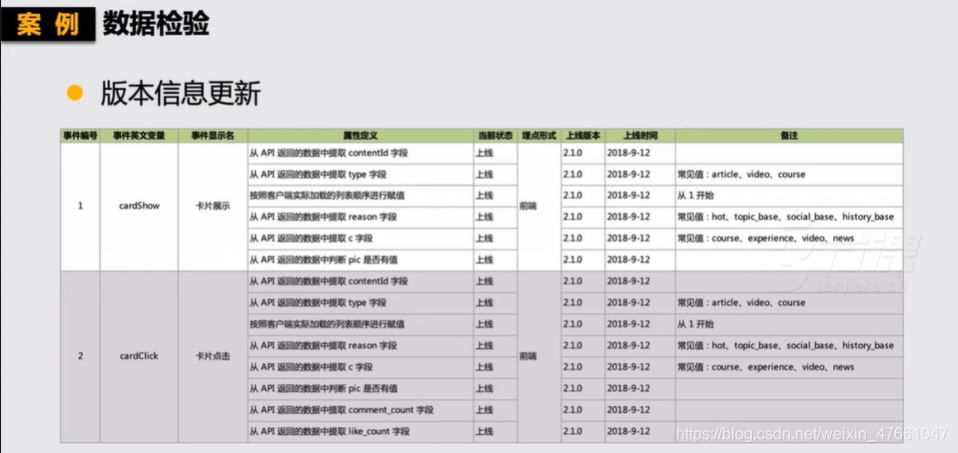
3.3埋点有效性的检验

3.4埋点文档的维护
- 是否在线
- 上线时间
- 下线时间
- 修改备注
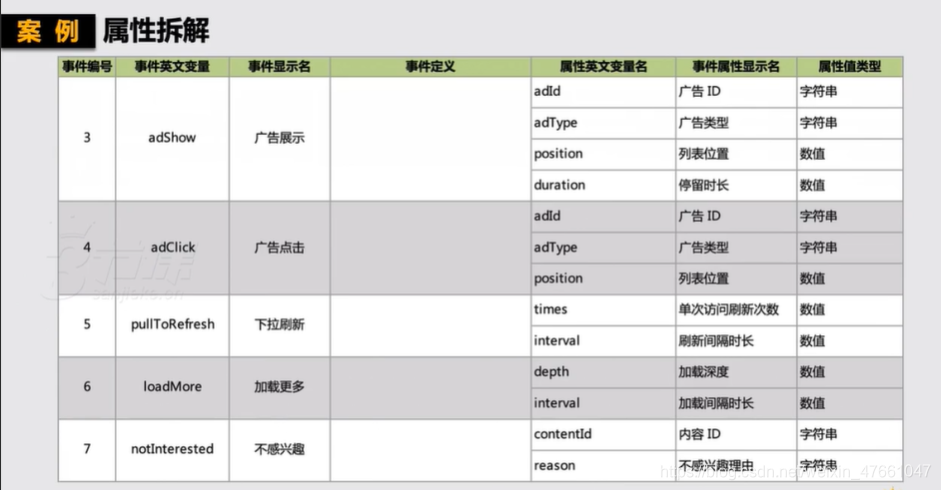
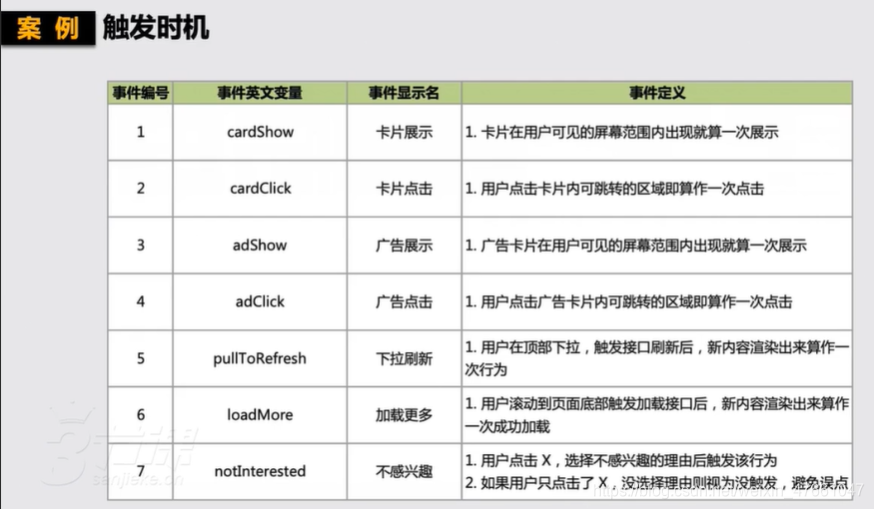
4.数据采集实战












5.其他类型的数据采集方法
5.1全埋点/无埋点 = 把所有的浏览和点击行为都记录下来
- 适用场景
- 分析需求简单(只需要统计PV和点击)
- 开发限制因素多(临时活动,没有时间/资源部署埋点)
- 业务流程简单(不涉及更多信息,只需要点击、跳转)
技巧:可通过将本来能在一页完成的流程拆分为多页,实现采集
- 限制
- 非浏览和点击事件无法采集,无法采集到what/how类的信息
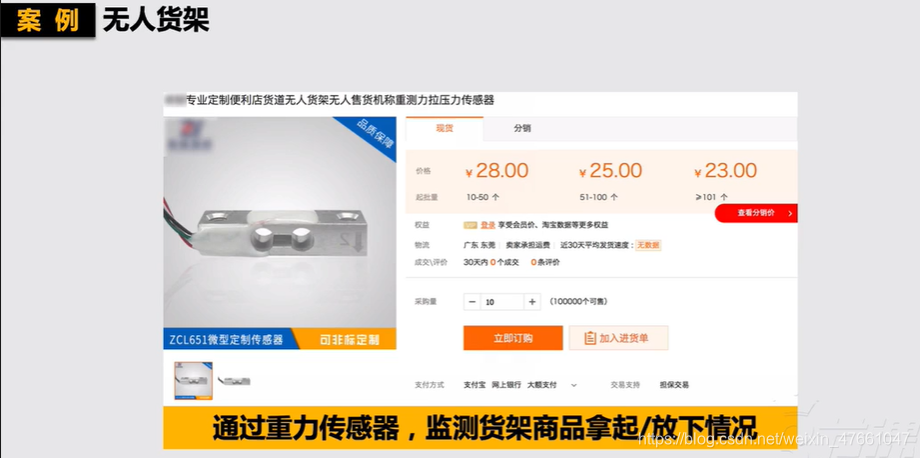
5.1.1案例



腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)