机器学习基础整理(第六章) - 神经网络
文章目录总览神经元模型 (Models of a neuron)通用激活函数 (Common Activation Functions)阈值函数 (Threshold Function)逻辑函数 (Logistic Function)整流线性单元 (Rectified Linear Unit - ReLU)Softmax激活函数其他激活函数优点网络架构 (Network Architecture)
文章目录
总览
神经网络是一种 旨在模拟大脑执行特定任务或感兴趣的功能 的方式。
神经网络 是由简单的 处理单元组成的 大规模 并行分布式处理器 (parallel distributed processor),具有存储 经验知识 (experiential knowledge) 并使其可供使用的自然倾向。
神经网络在两个方面类似于大脑:
- 网络通过学习过程从其环境获取知识。
- 神经元之间连接强度,称为突触权重,用于存储获得的知识。
神经元模型 (Models of a neuron)
神经元是神经网络操作的基本信息处理单元。
其组成包括了:
- 突触 (synapse) 或 连接链接 (connecting links): 每个都以自身的权重 ( ω k j \omega_{kj} ωkj) 或强度 为特征。连接到 神经元 k k k 的 突触 j j j 输入端的信号 x j x_j xj 乘以突触权重 ω k j \omega_{kj} ωkj
- 加法器 (adder): 对 输入信号 ( x i x_i xi) 求和,由神经元各自的突触强度加权。
- 激活函数/挤压函数 (activation function/ squashing function): 限制神经元输出的幅度 (amplitude),将输出信号的允许幅度范围 (permissible amplitude range) 压缩到某个有限值。
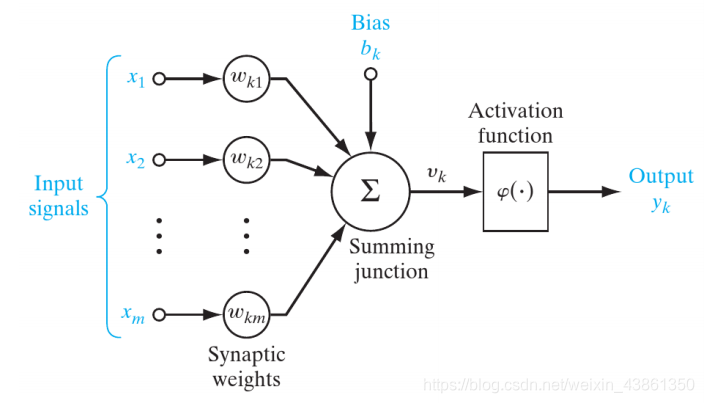
上图表示了带有 偏置 b k b_k bk 的神经元模型,它增加或降低了激活函数的净输入。
上图的神经元操作可以用以下数学表示:
u k = ∑ j = 1 m ω k j x j u_k = \sum_{j=1}^m\omega_{kj}x_j uk=j=1∑mωkjxj
y k = φ ( u k + b k ) y_k=\varphi(u_k+b_k) yk=φ(uk+bk)
其中:
x 1 , x 2 , . . . , x m x_1, x_2, ..., x_m x1,x2,...,xm 是输入信号 (input signals)。
ω 1 , ω 2 , . . . , ω m \omega_1, \omega_2, ..., \omega_m ω1,ω2,...,ωm 是神经元 k k k 各自的突触权重。
u k u_k uk 是 基于输入信号的线性组合输出。
b k b_k bk 是 偏置。
φ ( . ) \varphi(.) φ(.) 是 激活函数。
偏置 b k b_k bk 对线性组合器 (linear combiner) 的输出 u k u_k uk 应用仿射变换 (affine transformation)。
v k = u k + b k v_k = u_k + b_k vk=uk+bk
上面的公式可以进一步结合:
v k = ∑ j = 0 m ω k j x j v_k = \sum_{j=0}^m \omega_{kj}x_j vk=j=0∑mωkjxj
y k = φ ( v k ) y_k = \varphi(v_k) yk=φ(vk)
在结合的公式中,一个新的突触被添加了,即输入:
x 0 = + 1 x_0 = +1 x0=+1
以及权重:
ω k 0 = b k \omega_{k0}=b_k ωk0=bk
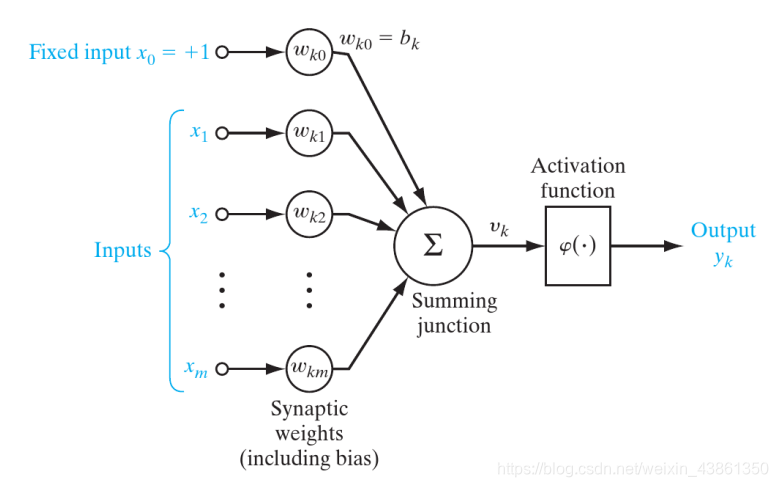
上图表示了合并了 偏置 之后的神经元模型。
神经元的信号流模型在某些分析或可视化中可能有用。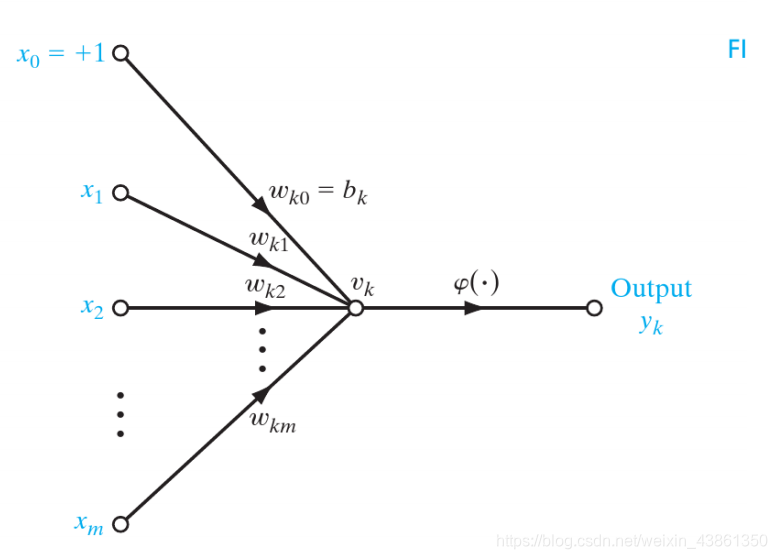
通用激活函数 (Common Activation Functions)
v k = ∑ j = 1 m ω k j x j + b k v_k=\sum_{j=1}^m\omega_{kj}x_j+b_k vk=j=1∑mωkjxj+bk
阈值函数 (Threshold Function)
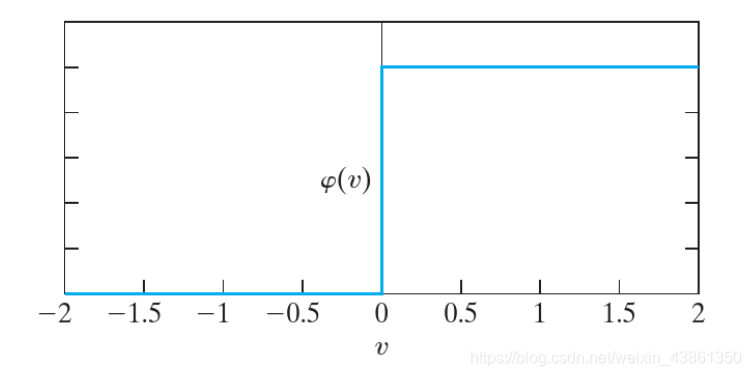
如上图的阈值函数 (Threshold Function) 可以被写为: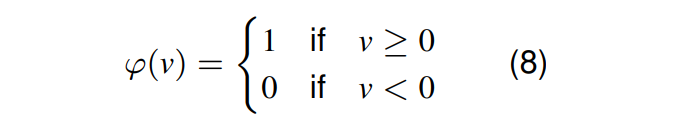
神经元 k k k 的输出,使用了阈值函数之后是: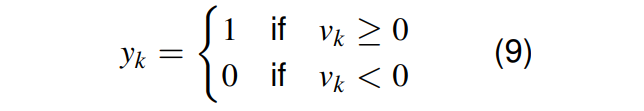
逻辑函数 (Logistic Function)
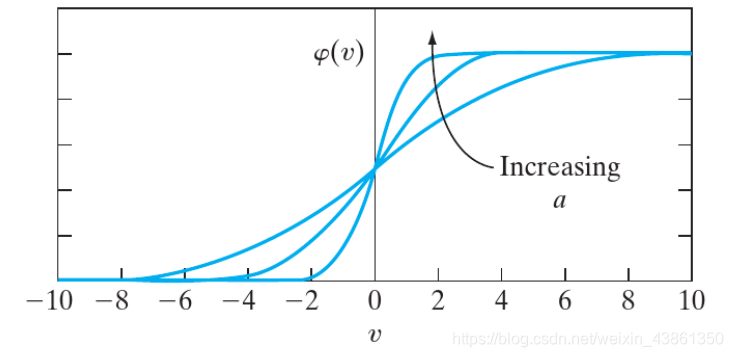
如上图的逻辑函数 (例子中为 Sigmoid function) 可以被写为:
φ ( v ) = 1 1 + e x p ( − a v ) \varphi(v) = \frac{1}{1 + exp(-av)} φ(v)=1+exp(−av)1
斜率参数 (slope parameter) a a a 决定形状,如上图。
请注意,逻辑函数是可微的 (differentiable),而阈值函数不是。
整流线性单元 (Rectified Linear Unit - ReLU)
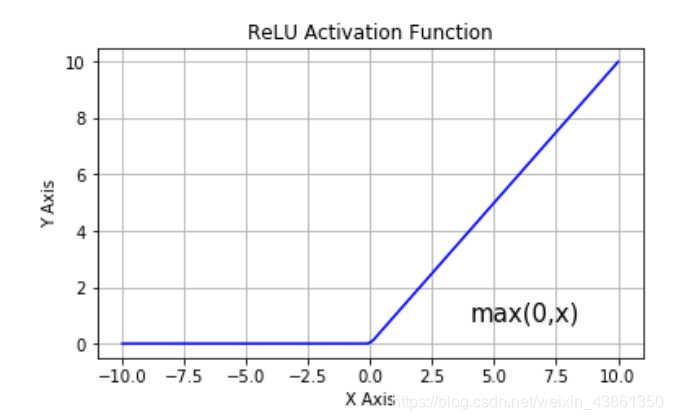
上图即是ReLU激活函数,该函数的使用非常受欢迎。
其输出是一个输入的非线性函数 (non-linear function)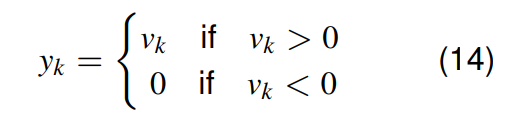
Softmax激活函数

Softmax激活函数 将 每个输入 挤压成 0 到 1 之间的数值。
输出相当于一个分类概率分布 (categorical probability distribution)。
图类似于逻辑函数,但通常用于为分类任务中的输出提供 概率解释 (probabilistic interpretation)。
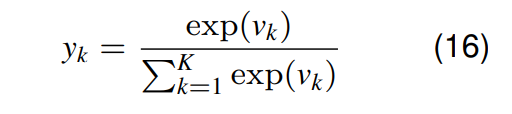
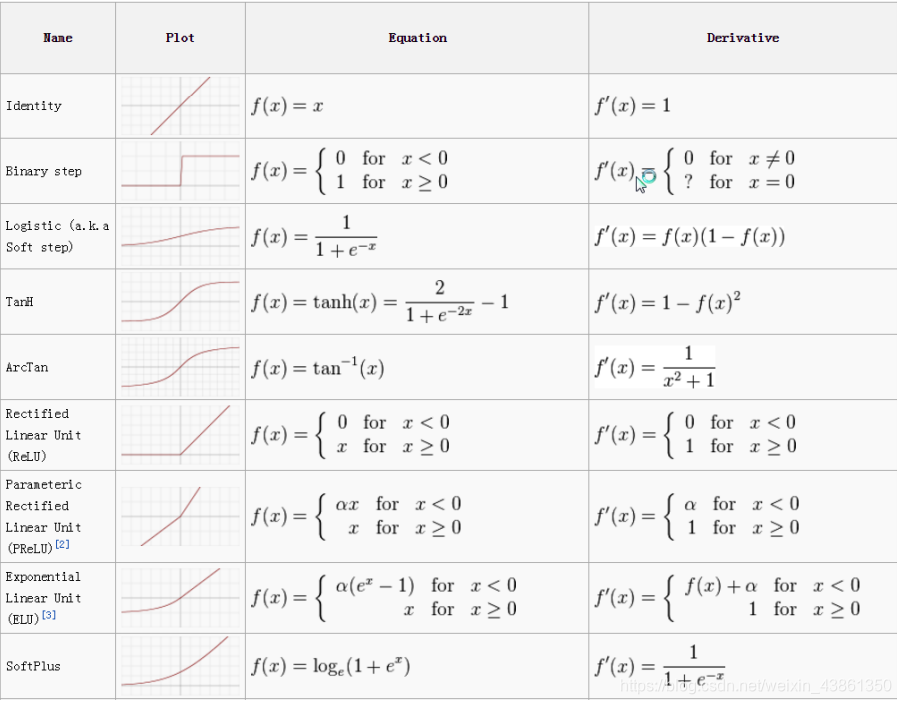
其他激活函数
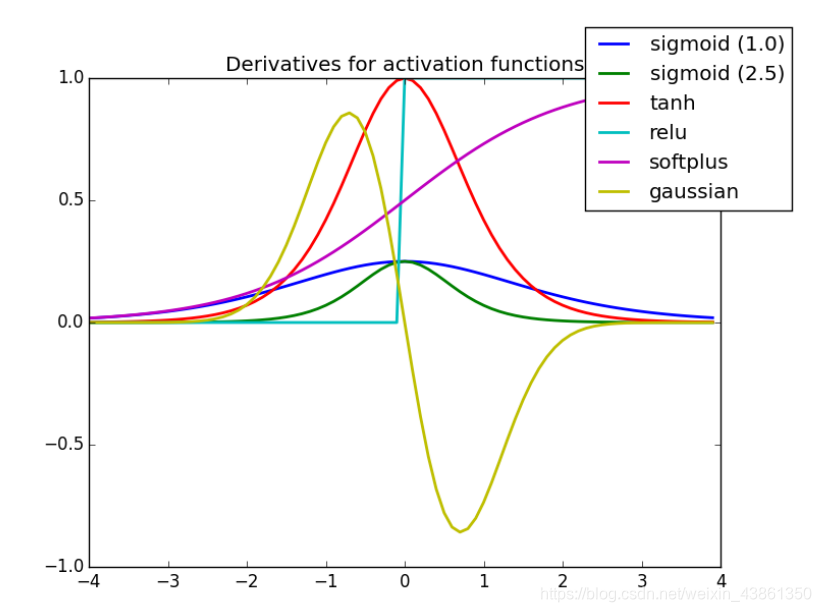
上图表示 激活函数的导数 (derivative)。
优点
激活函数有哪些不错的特性?
- 非线性函数,否则神经网络只能解决简单的问题。
- 没有激活,神经网络相当于线性回归。
- 好的导数使得学习过程变得容易。
- 激活函数为 有界输入 (bounded input) 提供有界输出 (bounded output)。
- 选择正确的激活函数既是科学也是艺术。
- 与正确的 成本函数 (cost function) 一起,激活函数使训练神经网络成为可能。
网络架构 (Network Architecture)
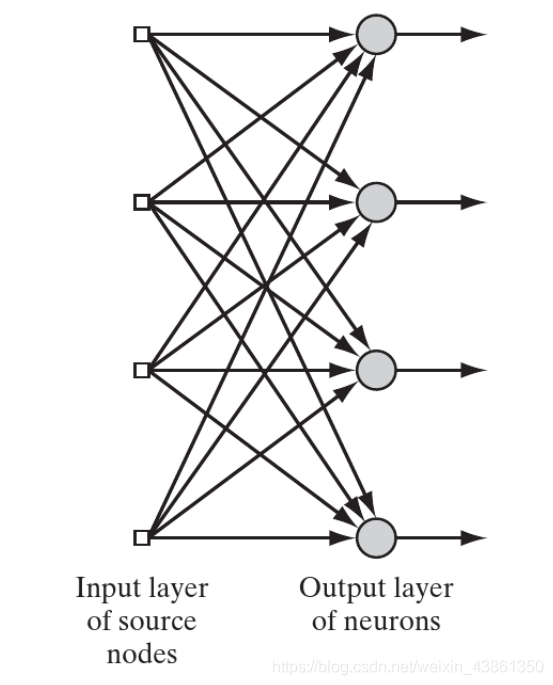
单层前馈网络 (Single Layer Feedforward Networks)
源节点的输入层 (input layer) 直接投影 到神经元的 输出层 (output layer)。
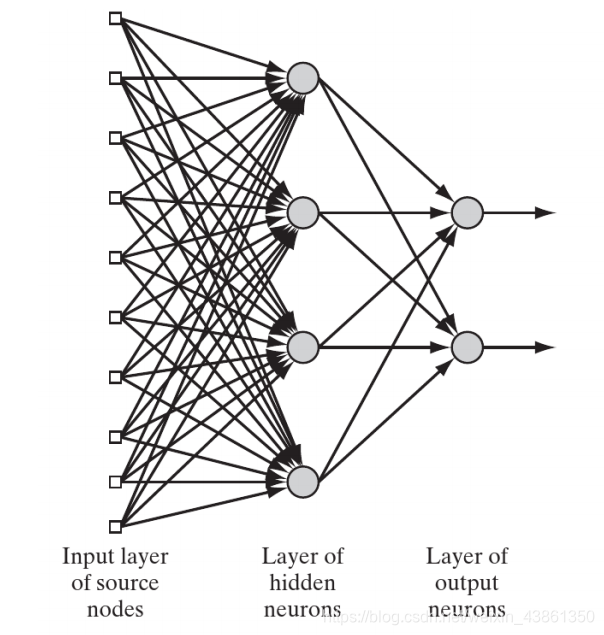
多层前馈网络 (Multilayer Feedforward Networks)
源节点的输入层 直接投射到 隐藏层 (hidden layer) 的一组神经元上。
可能有一个或多个隐藏层,每一层的输出形成下一层的输入,添加一个或多个隐藏层允许网络从输入数据中提取高阶统计信息 (higher-order statistics)。
如果每层中的每个节点都连接到相邻前向层 (adjacent forward layer) 中的每个节点,则网络是完全连接的 (fully connected)。
循环网络 (Recurrent Networks)
与 前馈网络 不同,循环网络 引入 从输出到输入的反馈,多层反馈也可以在层之间存在。
反馈回路 (feedback loops) 和 非线性激活函数 允许 神经网络对 非线性动态系统 (nonlinear dynamic systems) 进行建模。
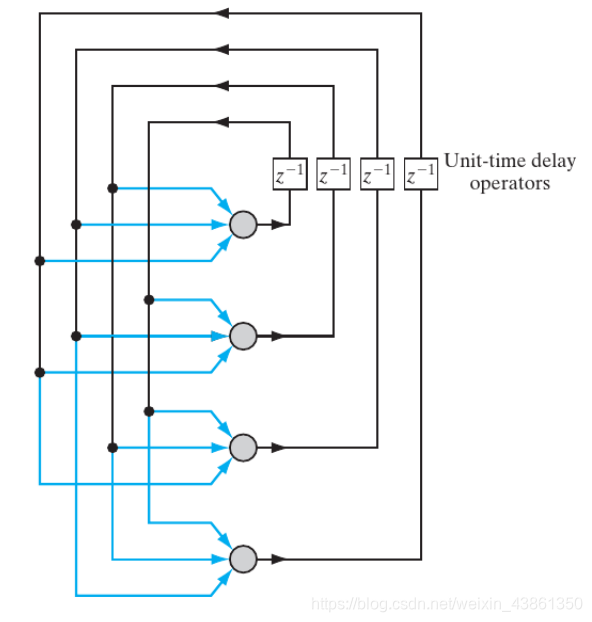
上图表示单层循环神经网络 (Single Layer Recurrent Neural Network)
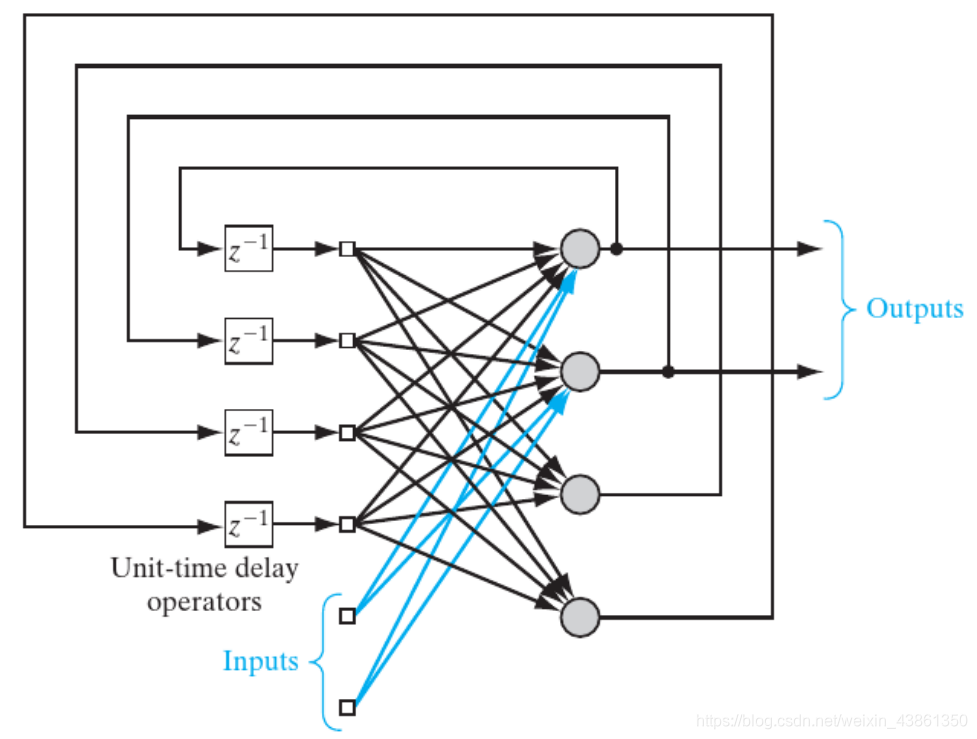
上图表示 带隐藏层 的循环神经网络。
训练过程
训练类型
- 监督式学习 (Supervised learning): 根据给定的输入向量预测输出。
- 强化学习 (Reinforcement learning): 选择能最大化一些定义好的奖励 (payoff) 的行为。
- 非监督学习 (Unsupervised learning): 探索好的数据内部表示 (internal representation)。
监督式学习
每一个 训练案例 都包含了 一个 输入向量 x x x 和 目标输出 t t t
- 回归问题: 目标输出是一个实数或者一整个实数向量。
- 分类问题: 目标输出是一个类标签。
通常我们希望通过 权重向量 ω \omega ω 学习从 输入向量 x x x 到某个输出 y y y 的映射:
y = f ( ω , x ) y=f(\omega, x) y=f(ω,x)
从而使预测实际值时发生的误差 (或损失/成本函数) 最小化。
对于回归问题,成本函数:
J ( ω , b ) = − E l o g p m o d e l ( y ∣ x ) J(\omega, b) = -\Epsilon \space log \space p_{model}(y|x) J(ω,b)=−E log pmodel(y∣x)
它是对 训练数据 计算的负条件对数似然 (negative conditional log-likelihood) 的期望,也就是 训练数据和模型分布之间的 交叉熵 (cross-entropy)。
上式的成本函数 通常在优化过程 梯度下降 (gradient descent) 中被最小化。
梯度下降
基于梯度的优化:
- 考虑一个函数 y = f ( x ) y=f(x) y=f(x),其中 x x x 和 y y y 均是 实数。
- y = f ( x ) y=f(x) y=f(x) 的导数, f ′ ( x ) f^{'}(x) f′(x),在点 x x x 上提供了 f ( x ) f(x) f(x) 的斜率 (slope)。
- 重要的是,其告诉我们如何 在输入 缩放微小变化 以获得 相应的输出变量 (这是由于泰勒展开 Taylor expansion)
f ( x + ϵ ) ≈ f ( x ) + ϵ f ′ ( x ) f(x+\epsilon) \approx f(x) + \epsilon f^{'}(x) f(x+ϵ)≈f(x)+ϵf′(x)
对于足够小的 ϵ \epsilon ϵ, f ( x − ϵ s i g n ( f ′ ( x ) ) ) < f ( x ) f(x - \epsilon sign(f^{'}(x))) \lt f(x) f(x−ϵsign(f′(x)))<f(x)
因此我们可以通过用导数的 相反符号 (opposite sign) 以小步移动 x x x 来减少 f ( x ) f(x) f(x) - 该技术被称为梯度下降。
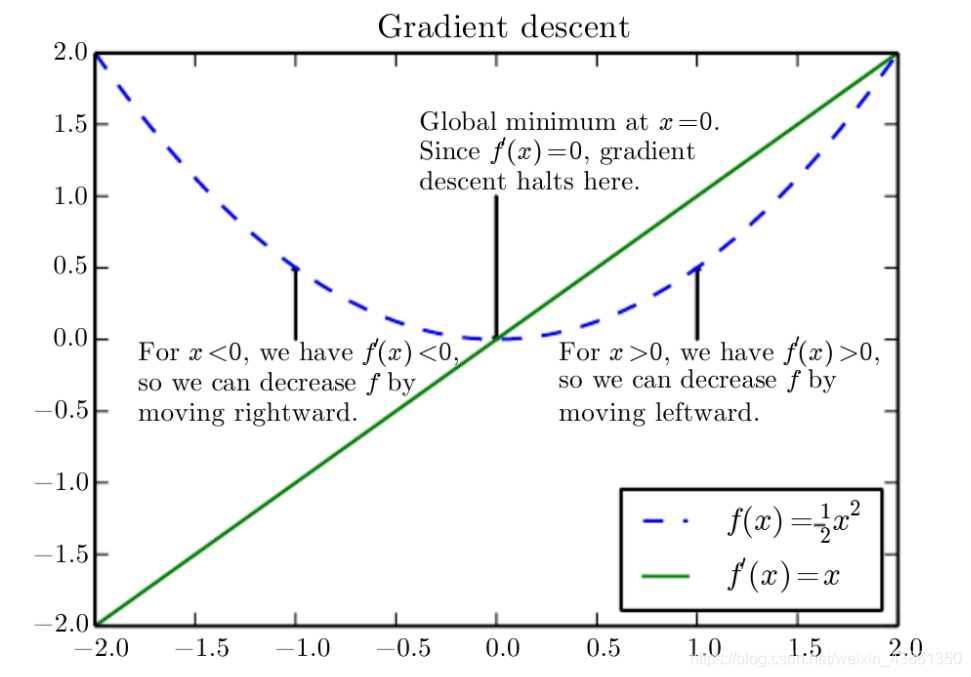
上图是梯度下降算法的展示。
一维空间中的梯度下降
考虑在曲线 f ( x ) = 1 2 x 2 f(x) = \frac{1}{2}x^2 f(x)=21x2 (如上图) 上的一个点 x = − 1 x = -1 x=−1,还有步长 (step size) ϵ = 0.1 \epsilon=0.1 ϵ=0.1
f ( − 1 ) = 1 2 ; f ′ ( x ) = x ; f ′ ( − 1 ) = − 1 f(-1) = \frac{1}{2};f^{'}(x)=x;f^{'}(-1)=-1 f(−1)=21;f′(x)=x;f′(−1)=−1
因此:
x n e w = x − ϵ f ′ ( x ) = − 1 − 0.1 × ( − 1 ) = − 0.9 x^{new} = x - \epsilon f^{'}(x) = -1 - 0.1 \times (-1) = -0.9 xnew=x−ϵf′(x)=−1−0.1×(−1)=−0.9
搜索最小值使得我们到达了 x = − 1 x = -1 x=−1 的右边。此时看新点的值, f ( − 0.9 ) = 0.405 f(-0.9) = 0.405 f(−0.9)=0.405,其比 f ( − 1 ) = 0.5 f(-1) = 0.5 f(−1)=0.5 小。
同理,若我们使得 x = 1.5 x = 1.5 x=1.5
x n e w = 1.5 − 0.1 × 1.5 = 1.35 x^{new} = 1.5 - 0.1 \times 1.5 = 1.35 xnew=1.5−0.1×1.5=1.35
这使得我们移动到了 x = 1.5 x = 1.5 x=1.5 的左边以及 朝向最小值点 移动,比较 f ( 1.5 ) = 1.125 f(1.5) = 1.125 f(1.5)=1.125 以及 f ( 1.35 ) = 0.911 f(1.35) = 0.911 f(1.35)=0.911
梯度下降数学
通常,函数 f f f 的输入是向量 x x x,因此我们考虑 f f f 导数的泛化, ∇ f \nabla f ∇f
使得 x = { x 1 , x 2 , . . . , x m } x = \{x_1, x_2, ..., x_m\} x={x1,x2,...,xm}
∇ f ( x ) = [ ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x m ] t \nabla f(x) = [\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_m}]^t ∇f(x)=[∂x1∂f,∂x2∂f,...,∂xm∂f]t
偏导数 ∂ f ∂ x i \frac{\partial f}{\partial x_i} ∂xi∂f 测量 f f f 是如何随着变量 x i x_i xi 在 x x x 点增加而变化的。
单位向量 u u u 的方向导数 (directional derivative) 是 f f f 在 u u u 方向的斜率。
方向导数 是 f ( x + α u ) f(x + \alpha u) f(x+αu) 相对于在 α = 0 \alpha = 0 α=0 处评估的 α \alpha α 的导数。
链式法则 (Chain Rule) 说给定一个函数 f ( u ) f(u) f(u) 和 u ( x ) u(x) u(x),会有
∂ f ∂ x = ∂ u ∂ x ∂ f ∂ u \frac{\partial f}{\partial x} = \frac{\partial u}{\partial x} \frac{\partial f}{\partial u} ∂x∂f=∂x∂u∂u∂f
因此,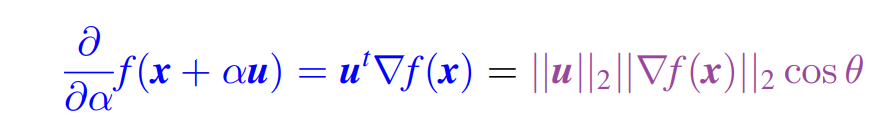
目标是找到 f f f 下降最快的方向来 最小化 f f f,通过 最小化方向导数 就可以做到这一点: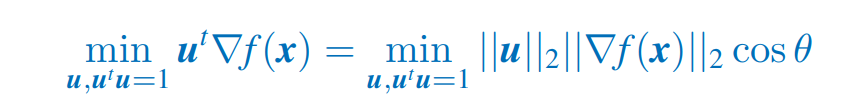
当 u u u 指向与 ∇ f ( x ) \nabla f(x) ∇f(x) 相反的方向,即 相隔 180 ° 180° 180°时,其达到最小值。
我们可以通过向 负梯度方向移动来减少 f f f,选择一个新点:
x ′ = x − ϵ ∇ f ( x ) x^{'} = x - \epsilon\nabla f(x) x′=x−ϵ∇f(x)其中 ϵ \epsilon ϵ 是步长。
感知机 (Perceptron)
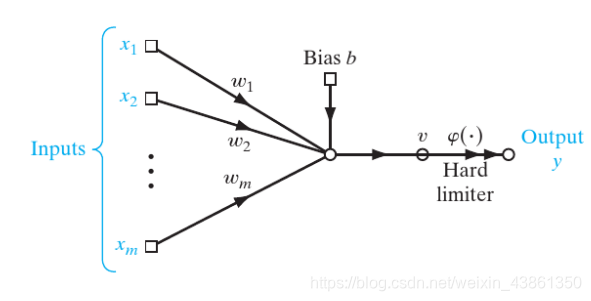
考虑上图展示的感知机,权重为 w i w_i wi 和 输入 x i x_i xi, i = { 1 , . . . , m } i = \{1, ..., m\} i={1,...,m},额外的偏置 b b b。
正确地将外界的输入分类为两个类别 C 1 C_1 C1 或 C 2 C_2 C2。
若 y = + 1 y = +1 y=+1,则分类为 C 1 C_1 C1。若 y = − 1 y = -1 y=−1,则分类为 C 2 C_2 C2。
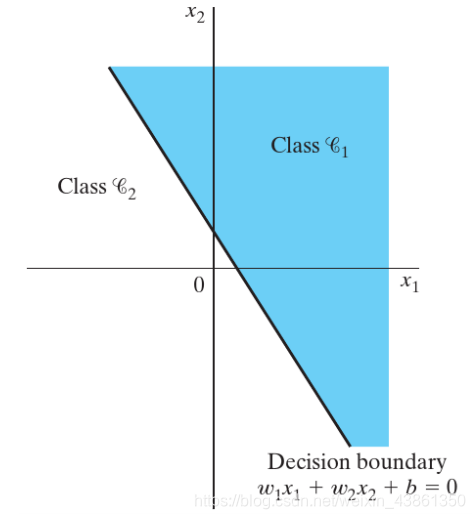
如上图,简单的感知机创建一个能区分两个区域的超平面 (hyperplane):
∑ i = 1 m w i x i + b = 0 \sum_{i=1}^m w_i x_i + b = 0 i=1∑mwixi+b=0
在训练样本表示的每次迭代中,感知机的权重会进行适应。方法是使用 纠错规则 (error-correction rule),感知机收敛算法 (perceptron convergence algorithm)。
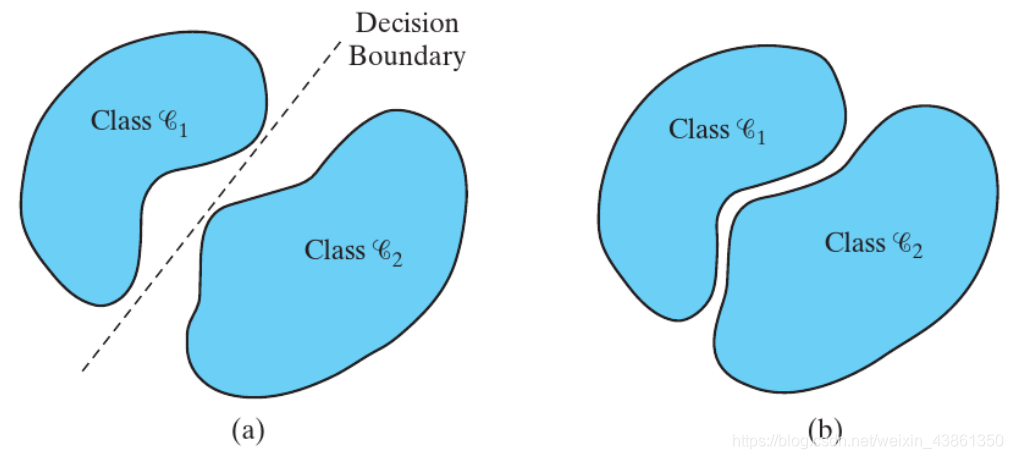
上图左边是线性可分模式 (linearly separable patterns),而右边是线性不可分模式 (linearly non-separable patterns)。
多层感知机 (Multilayer Perceptron)
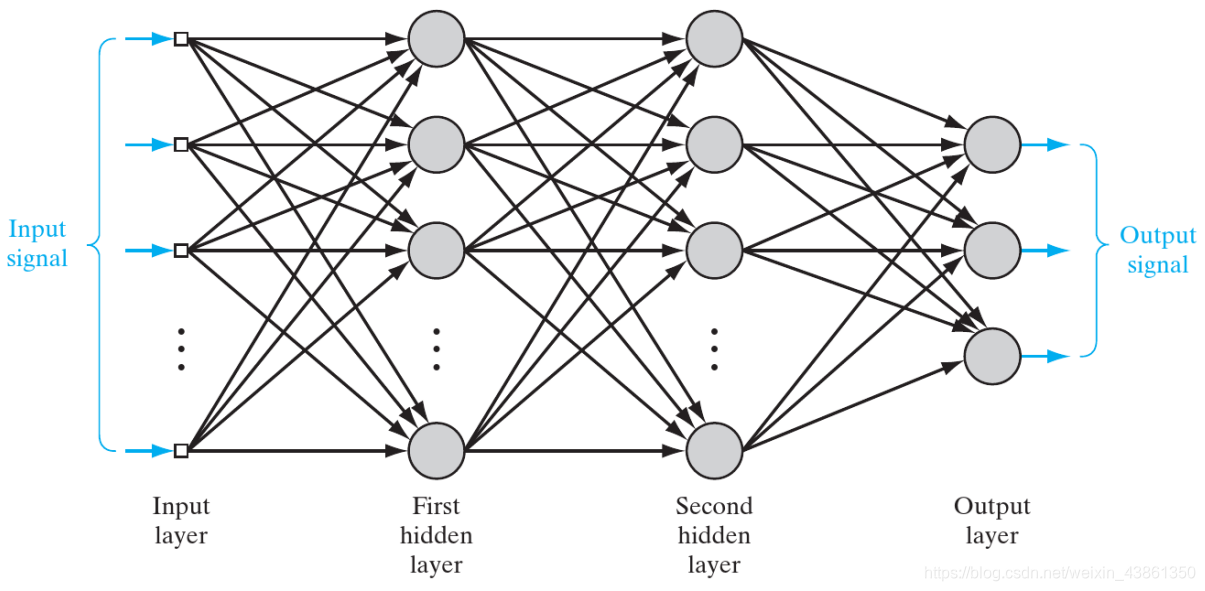
多层感知机基本特征:
- 网络中的每一个神经元都包含了一个 可差分的激活函数。
- 网络包含了一或多个 被输入和输出节点隐藏的 层。
- 网络表现出由 网络突触权重 决定的 高度连通性。
多层感知机通常被使用 反向传播 (back-propagation) 算法进行训练。
- 前向阶段 (forward phase): 网络权重是固定的,输入信号通过网络逐层传播,变换后的信号出现在输出端。
- 反向阶段 (backward phase): 通过比较 生成的输出 和 期望的响应 来计算误差信号 (error signal),误差信号通过网络向后和分层传播,此时会对网络权重进行连续调整。
每一个 隐藏层或输出层 神经元 执行下列计算:
- 每个神经元的输出表示为 输入信号 和 相关权重 的连续非线性函数。
- 训练的 反向阶段 所需的 梯度向量 (gradient vector) (误差面的梯度 gradient of error surface) 的估计。
隐藏层神经元 表现得像 特征探测器 (feature detectors),发现表征训练数据 的显著特征 (salient features)。
隐藏神经元 在 输入数据 中 应用 非线性变换 变成 一个新空间,即特征空间 (feature space)。
训练是一种 纠错学习形式 (error-correction learning),其将责任或功劳归于某个内部神经元,这是 信用分配问题 (credit assignment problem) 的一个例子。
反向传播算法 解决 多层感知机 的 信用分配问题。
反向传播算法
关键点:
- 多层感知机是一个通用的函数逼近器 (universal function approximator)。
- 可以使用 纠错学习 进行训练以获得最佳逼近。
- 如果我们可以最小化近似误差 (minimize approximation error),则可以获得最优值。
- 这相当于修改权重,使网络最小化 期望输出和网络响应 之间的误差。
- 梯度下降算法可用于通过 迭代 计算 导致目标函数最小化的调整 来找到目标函数的最小值。
- 反向传播是梯度下降的有效实现。
- 策略是计算要应用于每个权重 w w w 的调整量 Δ w \Delta w Δw。
- 从之前的公式可知,调整 与 目标函数的梯度成正比。这种情况下,是关于参数 w w w 的 ∇ E \nabla E ∇E ( E E E 是误差信号能量 error signal energy)。
每个输出神经元的误差信号 (error signal) 是:
e j ( n ) = d j ( n ) − y j ( n ) e_j(n) = d_j(n) - y_j(n) ej(n)=dj(n)−yj(n)
其中 y j y_j yj 是当刺激 x ( n ) x(n) x(n) 应用于输入时,神经元 j j j 的输出。而 d j ( n ) d_j(n) dj(n) 则是 期待输出。
其瞬时误差能量 (instantaneous error energy) 可以被写为:
E j ( n ) = 1 2 e j 2 ( n ) E_j(n) = \frac{1}{2}e_j^2(n) Ej(n)=21ej2(n)
总瞬时误差 (total instantaneous error) (输出层中所有神经元的总和) 为:
E ( n ) = ∑ j ∈ C E j ( n ) = 1 2 ∑ j ∈ C e j 2 ( n ) E(n) = \sum_{j\in C}E_j(n)=\frac{1}{2}\sum_{j \in C}e_j^2(n) E(n)=j∈C∑Ej(n)=21j∈C∑ej2(n)
误差计算可以是 批处理模式 (batch mode) 或 在线模式 (on-line mode),这会导致批处理模式 (所有训练样本的表示) 或在线 (一次仅一个训练样本的表示) 训练。
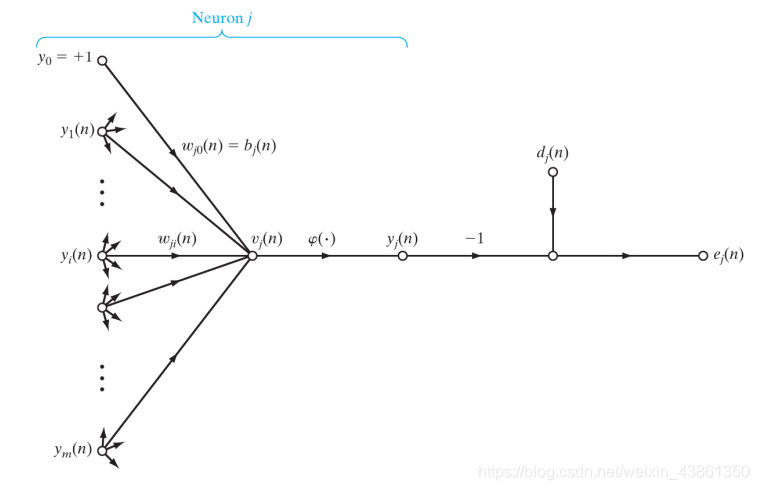
上图的信号流 突出显示 神经元 j j j 由左侧神经元的输出 馈送,神经元的诱导局部场 是 v j ( n ) v_j(n) vj(n),其也是激活函数 ϕ ( . ) \phi(.) ϕ(.) 的输入。
在 迭代 n n n 时 神经元 j j j 的 诱导局部场 (induced local field) 是:
v j ( n ) = ∑ i = 0 m w j i ( n ) y i ( n ) v_j(n) = \sum_{i=0}^m w_{ji}(n)y_i(n) vj(n)=i=0∑mwji(n)yi(n)
m m m 是 输入的总数。
在 迭代 n n n 时 出现在神经元 j j j 输出的 函数信号 y j ( n ) y_j(n) yj(n) 是:
y j ( n ) = ϕ ( v j ( n ) ) y_j(n) = \phi(v_j(n)) yj(n)=ϕ(vj(n))
我们需要计算 应用在 w j i ( n ) w_{ji}(n) wji(n) 的 调整(校正) Δ w j i ( n ) \Delta w_{ji}(n) Δwji(n) 。这与偏导数 (partial derivative) ∂ E ( n ) ∂ w j i ( n ) \frac{\partial E(n)}{\partial w_{ji}(n)} ∂wji(n)∂E(n) 成正比,并确定 w j i w_{ji} wji 在权重空间中的搜索方向。链式法则 告诉我们如何 从已知量中 计算 ∂ E ( n ) ∂ w j i ( n ) \frac{\partial E(n)}{\partial w_{ji}(n)} ∂wji(n)∂E(n)
∂ E ( n ) ∂ w j i ( n ) = ∂ E ( n ) ∂ e j ( n ) ∂ e j ( n ) ∂ y j ( n ) ∂ y j ( n ) ∂ v j ( n ) ∂ v j ( n ) ∂ w j i ( n ) \frac{\partial E(n)}{\partial w_{ji}(n)} = \frac{\partial E(n)}{\partial e_j(n)}\frac{\partial e_j(n)}{\partial y_{j}(n)}\frac{\partial y_j(n)}{\partial v_{j}(n)}\frac{\partial v_j(n)}{\partial w_{ji}(n)} ∂wji(n)∂E(n)=∂ej(n)∂E(n)∂yj(n)∂ej(n)∂vj(n)∂yj(n)∂wji(n)∂vj(n)
从前文可知, E j ( n ) = 1 2 e j 2 ( n ) E_j(n) = \frac{1}{2}e_j^2(n) Ej(n)=21ej2(n),因此
∂ E ( n ) ∂ e j ( n ) = e j ( n ) \frac{\partial E(n)}{\partial e_j(n)} = e_j(n) ∂ej(n)∂E(n)=ej(n)
从前文可知, e j ( n ) = d j ( n ) − y j ( n ) e_j(n) = d_j(n) - y_j(n) ej(n)=dj(n)−yj(n),因此
∂ e j ( n ) ∂ y j ( n ) = − 1 \frac{\partial e_j(n)}{\partial y_{j}(n)} = -1 ∂yj(n)∂ej(n)=−1
从前文可知, y j ( n ) = ϕ ( v j ( n ) ) y_j(n) = \phi(v_j(n)) yj(n)=ϕ(vj(n)),因此
∂ y j ( n ) ∂ v j ( n ) = ϕ ′ ( v j ( n ) ) \frac{\partial y_j(n)}{\partial v_{j}(n)} = \phi^{'}(v_j(n)) ∂vj(n)∂yj(n)=ϕ′(vj(n))
其中 ( ) ′ ()^{'} ()′ 表示微分
从前文可知, v j ( n ) = ∑ i = 0 m w j i ( n ) y i ( n ) v_j(n) = \sum_{i=0}^m w_{ji}(n)y_i(n) vj(n)=∑i=0mwji(n)yi(n),因此:
∂ v j ( n ) ∂ w j i ( n ) = y i ( n ) \frac{\partial v_j(n)}{\partial w_{ji}(n)} = y_i(n) ∂wji(n)∂vj(n)=yi(n)
结合以上式子,我们可以得到:
∂ E ( n ) ∂ w j i ( n ) = − e j ( n ) ϕ ′ ( v j ( n ) ) y i ( n ) \frac{\partial E(n)}{\partial w_{ji}(n)} = -e_j(n)\phi^{'}(v_j(n))y_i(n) ∂wji(n)∂E(n)=−ej(n)ϕ′(vj(n))yi(n)
应用在 w j i ( n ) w_{ji}(n) wji(n) 的 Δ w j i ( n ) \Delta w_{ji}(n) Δwji(n) 通过以下规则 (delta rule) 定义:
Δ w j i ( n ) = − η ∂ E ( n ) ∂ w j i ( n ) = η ( e j ( n ) ϕ ′ ( v j ( n ) ) ) y i ( n ) = η ( δ j ( n ) ) y i ( n ) \Delta w_{ji}(n) = -\eta \frac{\partial E(n)}{\partial w_{ji}(n)} = \eta (e_j(n) \phi^{'}(v_j(n))) y_i(n) \\ = \eta (\delta_j(n)) y_i(n) Δwji(n)=−η∂wji(n)∂E(n)=η(ej(n)ϕ′(vj(n)))yi(n)=η(δj(n))yi(n)
其中 δ j ( n ) = e j ( n ) ϕ ′ ( v j ( n ) ) \delta_j(n) = e_j(n) \phi^{'}(v_j(n)) δj(n)=ej(n)ϕ′(vj(n)) 被定义为 神经元 j j j 的局部梯度 (local gradient)。
神经元 j j j 的局部梯度是 相应误差 e j ( n ) e_j(n) ej(n) 和 相关 激活函数的导数 ϕ ′ ( v j ( n ) ) \phi^{'}(v_j(n)) ϕ′(vj(n)) 的乘积
输出神经元的 误差 e j ( n ) e_j(n) ej(n) 容易被计算,我们可以使用 d j ( n ) d_j(n) dj(n) 以及 y j ( n ) y_j(n) yj(n)。但我们要如何计算隐藏层中的误差呢?它们并没有给定的 d j ( n ) d_j(n) dj(n)
整理下我们目前所得知的:
- 训练多层感知机 涉及 使用纠错学习范式中的 训练数据集来调整权重。
- 纠错学习 本质上等价于解决一个函数最小化问题。
- 要最小化的函数 是 对应于网络响应与期望响应之间 不匹配的误差面。
- 这可以使用 梯度下降算法 解决。
- 反向传播算法 是 多层感知机 梯度下降算法 的有效实现。
- 每次迭代对权重的修正 (或更新) 为:
Δ w j i ( n ) = η ( e j ( n ) ϕ ′ ( v j ( n ) ) ) y i ( n ) = η ( δ j ( n ) ) y i ( n ) \Delta w_{ji}(n) = \eta (e_j(n) \phi^{'}(v_j(n))) y_i(n) \\ = \eta (\delta_j(n)) y_i(n) Δwji(n)=η(ej(n)ϕ′(vj(n)))yi(n)=η(δj(n))yi(n)
这是 学习率 (learning rate) η \eta η,相关神经元的局部梯度 δ j ( n ) \delta_j(n) δj(n),以及 神经元的输入 y i ( n ) y_i(n) yi(n) 的乘积。
连接到 输出神经元 的权重更新为:
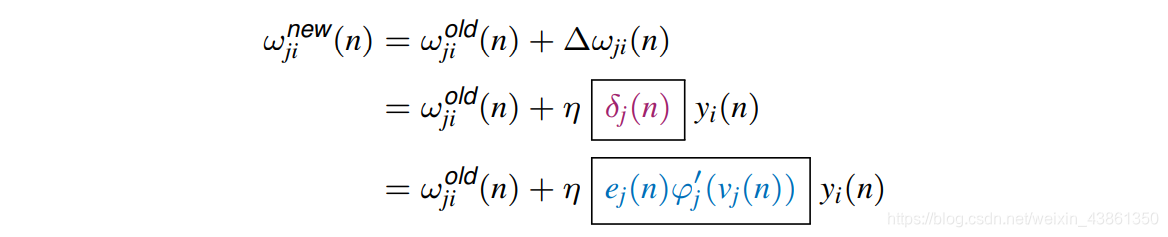
使用类似于我们如何导出输出 神经元权重的更新 的链式法则,我们将证明隐藏神经元 (hidden neuron) 的 权重更新 为: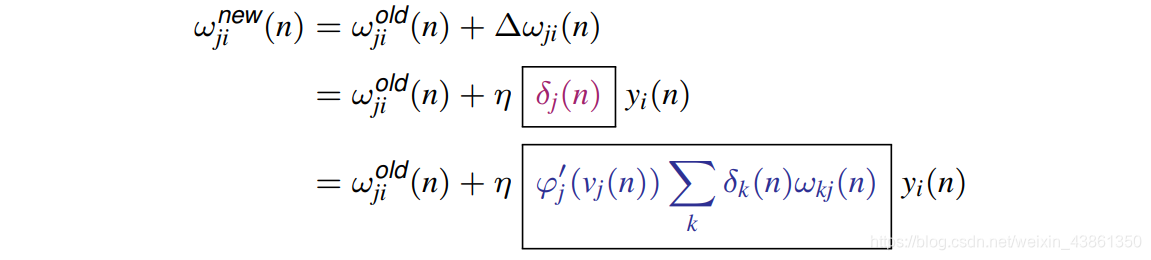
其中,神经元 j j j 是属于隐藏层的, ϕ j ′ ( v j ( n ) ) \phi_j^{'}(v_j(n)) ϕj′(vj(n)) 是相关激活函数的导数,而 δ k ( n ) \delta_k(n) δk(n) 与神经元 k k k 相关联,神经元 k k k 位于 神经元 j j j 的右侧并与之相连。 w k j ( n ) w_{kj}(n) wkj(n) 指的是这些连接的权重,如下图所示。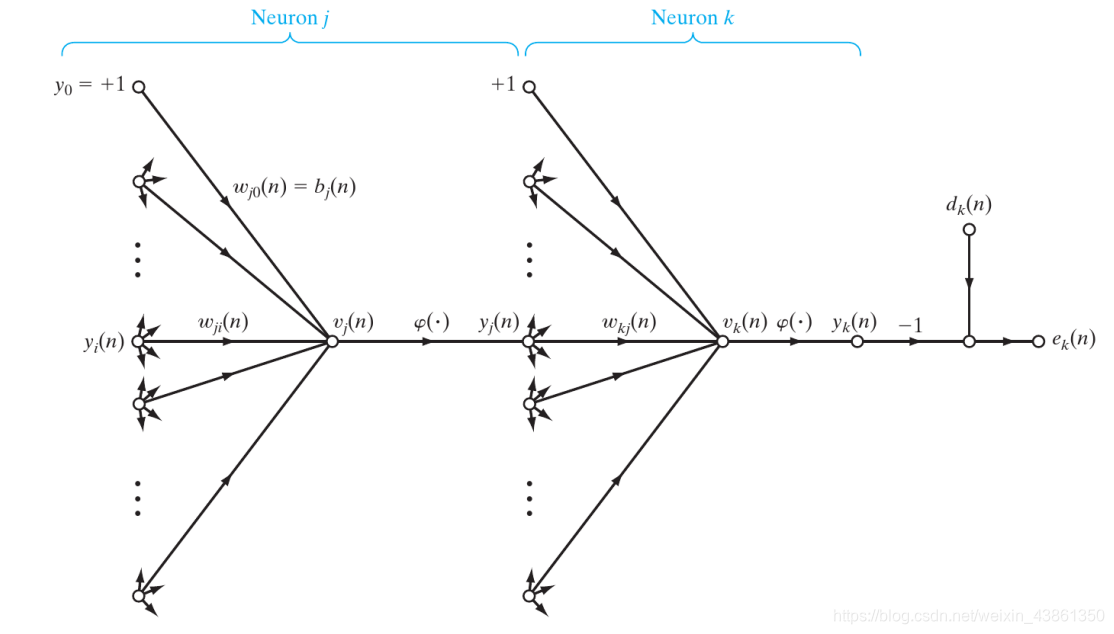
从上面的公式中,我们试着推导出:
δ j ( n ) = ϕ j ′ ( v j ( n ) ) ∑ k δ k ( n ) w k j ( n ) \delta_j(n) = \phi_j^{'}(v_j(n))\sum_k\delta_k(n)w_{kj}(n) δj(n)=ϕj′(vj(n))k∑δk(n)wkj(n)
首先,回顾下之前的公式:
∂ E ( n ) ∂ w j i ( n ) = ( ∂ E ( n ) ∂ e j ( n ) ∂ e j ( n ) ∂ y j ( n ) ∂ y j ( n ) ∂ v j ( n ) ) ∂ v j ( n ) ∂ w j i ( n ) \frac{\partial E(n)}{\partial w_{ji}(n)} = (\frac{\partial E(n)}{\partial e_j(n)}\frac{\partial e_j(n)}{\partial y_{j}(n)}\frac{\partial y_j(n)}{\partial v_{j}(n)})\frac{\partial v_j(n)}{\partial w_{ji}(n)} ∂wji(n)∂E(n)=(∂ej(n)∂E(n)∂yj(n)∂ej(n)∂vj(n)∂yj(n))∂wji(n)∂vj(n)
以及:
Δ w j i ( n ) = η ( e j ( n ) ϕ ′ ( v j ( n ) ) ) y i ( n ) = η ( δ j ( n ) ) y i ( n ) \Delta w_{ji}(n) = \eta (e_j(n) \phi^{'}(v_j(n))) y_i(n) \\ = \eta (\delta_j(n)) y_i(n) Δwji(n)=η(ej(n)ϕ′(vj(n)))yi(n)=η(δj(n))yi(n)
我们从中推理出, δ j ( n ) \delta_j(n) δj(n) 可以被写为:
δ j ( n ) = ∂ E ( n ) ∂ e j ( n ) ∂ e j ( n ) ∂ y j ( n ) ∂ y j ( n ) ∂ v j ( n ) \delta_j(n) = \frac{\partial E(n)}{\partial e_j(n)}\frac{\partial e_j(n)}{\partial y_{j}(n)}\frac{\partial y_j(n)}{\partial v_{j}(n)} δj(n)=∂ej(n)∂E(n)∂yj(n)∂ej(n)∂vj(n)∂yj(n)
从上图可得:
δ j ( n ) = − ∂ E ( n ) ∂ y j ( n ) ∂ y j ( n ) ∂ v j ( n ) = − ∂ E ( n ) ∂ y j ( n ) ϕ j ′ ( v j ( n ) ) \delta_j(n) = -\frac{\partial E(n)}{\partial y_j(n)}\frac{\partial y_j(n)}{\partial v_j(n)} \\ = -\frac{\partial E(n)}{\partial y_j(n)}\phi^{'}_j(v_j(n)) δj(n)=−∂yj(n)∂E(n)∂vj(n)∂yj(n)=−∂yj(n)∂E(n)ϕj′(vj(n))
从图像中还可知:
E ( n ) = 1 2 ∑ k ∈ C e k 2 ( n ) E(n) = \frac{1}{2} \sum_{k \in C} e_k^2(n) E(n)=21k∈C∑ek2(n)
其中 神经元 k k k 是输出节点。
将上式在两边对 y i y_i yi 进行微分:
∂ E ( n ) ∂ y j ( n ) = ∑ k e k ( n ) ∂ e k ( n ) ∂ y j ( n ) \frac{\partial E(n)}{\partial y_j(n)} = \sum_k e_k(n) \frac{\partial e_k(n)}{\partial y_j(n)} ∂yj(n)∂E(n)=k∑ek(n)∂yj(n)∂ek(n)
使用链式法则:
∂ e k ( n ) ∂ y j ( n ) = ∂ e k ( n ) ∂ v k ( n ) ∂ v k ( n ) ∂ y j ( n ) \frac{\partial e_k(n)}{\partial y_j(n)} = \frac{\partial e_k(n)}{\partial v_k(n)}\frac{\partial v_k(n)}{\partial y_j(n)} ∂yj(n)∂ek(n)=∂vk(n)∂ek(n)∂yj(n)∂vk(n)
代入:
∂ E ( n ) ∂ y j ( n ) = ∑ k e k ( n ) ∂ e k ( n ) ∂ v k ( n ) ∂ v k ( n ) ∂ y j ( n ) \frac{\partial E(n)}{\partial y_j(n)} = \sum_k e_k(n) \frac{\partial e_k(n)}{\partial v_k(n)}\frac{\partial v_k(n)}{\partial y_j(n)} ∂yj(n)∂E(n)=k∑ek(n)∂vk(n)∂ek(n)∂yj(n)∂vk(n)
从图中可得:
e k ( n ) = d k ( n ) − y k ( n ) = d k ( n ) − ϕ k ( v k ( n ) ) e_k(n) = d_k(n) - y_k(n) \\=d_k(n) - \phi_k(v_k(n)) ek(n)=dk(n)−yk(n)=dk(n)−ϕk(vk(n))
其中 神经元 k k k 是输出节点。
还要注意,神经元 k k k 的诱导局部场:
v k ( n ) = ∑ j = 0 m w k j ( n ) y j ( n ) v_k(n) = \sum_{j = 0}^m w_{kj}(n)y_j(n) vk(n)=j=0∑mwkj(n)yj(n)
其中 m m m 是 应用到神经元 k k k 中输入数量。
结合这些分量偏导数,我们可以得到:
∂ E ( n ) ∂ y j ( n ) = − ∑ k ( e k ( n ) ϕ k ′ ( v k ( n ) ) ) w k j ( n ) = − ∑ k ( δ k ( n ) ) w k j ( n ) \frac{\partial E(n)}{\partial y_j(n)} = - \sum_k (e_k(n) \phi_k^{'}(v_k(n)))w_{kj}(n) \\= - \sum_k (\delta_k(n))w_{kj}(n) ∂yj(n)∂E(n)=−k∑(ek(n)ϕk′(vk(n)))wkj(n)=−k∑(δk(n))wkj(n)
接着通过进一步结合上述公式,得到:
δ j ( n ) = ϕ j ′ ( v j ( n ) ) ∑ k δ k ( n ) w k j ( n ) \delta_j(n) = \phi_j^{'}(v_j(n))\sum_k \delta_k(n) w_{kj}(n) δj(n)=ϕj′(vj(n))k∑δk(n)wkj(n)
结合下式:
Δ w j i ( n ) = − η ∂ E ( n ) ∂ w j i ( n ) = η ( e j ( n ) ϕ ′ ( v j ( n ) ) ) y i ( n ) = η ( δ j ( n ) ) y i ( n ) \Delta w_{ji}(n) = -\eta \frac{\partial E(n)}{\partial w_{ji}(n)} = \eta (e_j(n) \phi^{'}(v_j(n))) y_i(n) \\ = \eta (\delta_j(n)) y_i(n) Δwji(n)=−η∂wji(n)∂E(n)=η(ej(n)ϕ′(vj(n)))yi(n)=η(δj(n))yi(n)
我们可以得到:
Δ w j i ( n ) = η ( ϕ j ′ ( v j ( n ) ) ∑ k δ k ( n ) w k j ( n ) ) y i ( n ) \Delta w_{ji}(n) = \eta (\phi_j^{'}(v_j(n))\sum_k \delta_k(n) w_{kj}(n)) y_i(n) Δwji(n)=η(ϕj′(vj(n))k∑δk(n)wkj(n))yi(n)
权重更新的规则就变成了:
w j i n e w ( n ) = w j i o l d ( n ) + Δ w j i ( n ) = w j i o l d ( n ) + η ( ϕ j ′ ( v j ( n ) ) ∑ k δ k ( n ) w k j ( n ) ) y i ( n ) w_{ji}^{new}(n) = w_{ji}^{old}(n) + \Delta w_{ji}(n) \\ = w_{ji}^{old}(n) + \eta (\phi_j^{'}(v_j(n))\sum_k \delta_k(n) w_{kj}(n)) y_i(n) wjinew(n)=wjiold(n)+Δwji(n)=wjiold(n)+η(ϕj′(vj(n))k∑δk(n)wkj(n))yi(n)
推导完毕。
多层感知机中反向传播回顾
- 训练可以是 在线的 (online) (在每个样本展示之后就更新权重) 或 批处理的 (batch) (在所有样本展示之后进行权重更新)。
- 反向传播 包括两个阶段,即 前向传播 (forward pass) 和 反向传播 (backward pass)。
- 前向传播: 网络权重固定,输入信号通过网络逐层传播,变换后的信号出现在输出端,每个神经元计算以下式子:
v j ( n ) = ∑ j = 0 m w j i ( n ) y i ( n ) ; y j ( n ) = ϕ j ( v j ( n ) ) v_j(n) = \sum_{j=0}^mw_{ji}(n)y_i(n); y_j(n) = \phi_j(v_j(n)) vj(n)=j=0∑mwji(n)yi(n);yj(n)=ϕj(vj(n)) - 反向传播: 误差通过网络向后传播以计算权重更新:
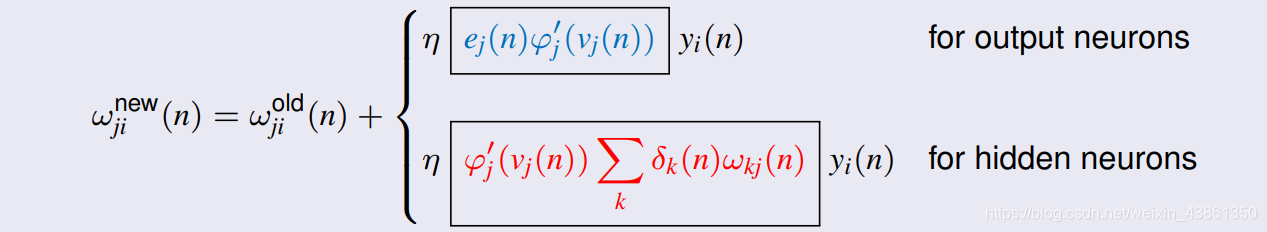
基础梯度下降的扩展
要提高学习系统的性能,我们可以:
- 改进模型的结构,如 添加更多层。
- 改进模型的初始化,如 建立大量的稀疏性 (sparsity)。
- 使用更强大的学习算法,如 改进的梯度下降。
基本梯度下降算法 (属于优化器) 的几个扩展提供了更快的收敛 (faster convergence)。流行的优化器包括了:
- Adam
- RMSProp
- AdaGrad
从之前的推导可知,梯度下降更新规则只是简单做了下面的事情:
w t = w t − 1 − η ∇ f ( w t − 1 ) w_t = w_{t-1} - \eta \nabla f(w_{t-1}) wt=wt−1−η∇f(wt−1)
其中 ∇ f ( w t − 1 ) \nabla f(w_{t-1}) ∇f(wt−1) 是 上一次迭代的梯度。
随机梯度下降 (Stochastic Gradient Descent)
g t ← ∇ f ( w t − 1 ) g_t \gets \nabla f(w_{t-1}) gt←∇f(wt−1)
w t ← w t − 1 − η g t w_t \gets w_{t-1} - \eta g_t wt←wt−1−ηgt
梯度下降可能会遭受 收敛缓慢 问题。
动量 (Momentum)
添加动量可以提供相当大的改进
g t ← ∇ f ( w t − 1 ) g_t \gets \nabla f(w_{t-1}) gt←∇f(wt−1)
m t ← μ m t − 1 + g t m_t \gets \mu m_{t-1} + g_t mt←μmt−1+gt (累积动量项)
w t ← w t − 1 − η m t w_t \gets w_{t-1} - \eta m_t wt←wt−1−ηmt
优点:
- 沿着梯度在训练步骤中保持相对一致的维度加速 梯度下降 学习。
- 在 梯度剧烈震荡 的 动荡维度 (turbulent dimensions) 上减慢 梯度下降 学习。
Nesterov加速梯度 (Nesterov’s accelerated gradient)
Nesterov加速梯度方法 在计算之前 将 动量项 添加到参数向量 (也就是权重) 中。
根据经验,对于困难的优化目标,该方法优于基本的 梯度下降 和 经典动量。
g t ← ∇ f ( w t − 1 − η μ m t − 1 ) g_t \gets \nabla f(w_{t-1} - \eta \mu m_{t-1}) gt←∇f(wt−1−ημmt−1)
m t ← μ m t − 1 + g t m_t \gets \mu m_{t-1} + g_t mt←μmt−1+gt
w t ← w t − 1 − η m t w_t \gets w_{t-1} - \eta m_t wt←wt−1−ηmt
AdaGrad
基于 范数 L 2 L_2 L2 的方法,其将学习率 η \eta η 除以所有先前梯度的 L 2 L_2 L2 范数,这可以提供改进。
这会使的算法 沿着已经发生显著变化的维度 减慢学习速度。
沿 仅略有变化的维度加速学习。
稳定 模型对共同特征 (common features) 的表示。
快速学习稀有特征 (rare features) 的表示。
问题: 梯度可能变得太大并导致学习停止
g t ← ∇ f ( w t − 1 ) g_t \gets \nabla f(w_{t-1}) gt←∇f(wt−1)
n t ← n t − 1 + g t 2 n_t \gets n_{t-1} + g_t^2 nt←nt−1+gt2
w t ← w t − 1 − η g t n t + ϵ w_t \gets w_{t-1} - \eta \frac{g_t}{\sqrt{n_t+\epsilon}} wt←wt−1−ηnt+ϵgt
RMSProp
为了解决之前提出的梯度增长 (growing gradient) 的问题 通过对 梯度项 进行加权 (weighting the gradient term) 来解决,RMSProp 就被提出来了。
g t ← ∇ f ( w t − 1 ) g_t \gets \nabla f(w_{t-1}) gt←∇f(wt−1)
n t ← v n t − 1 + ( 1 − v ) g t 2 n_t \gets v n_{t-1} + (1-v)g_t^2 nt←vnt−1+(1−v)gt2
w t ← w t − 1 − η g t n t + ϵ w_t \gets w_{t-1} - \eta \frac{g_t}{\sqrt{n_t+\epsilon}} wt←wt−1−ηnt+ϵgt
Adam
基于动量 (momentum-based) 和 基于范数 (norm-based) 的扩展组合激发了 自适应矩估计 (adaptive moment estimation - Adam)
衰减均值 (decaying mean) 代替经典动量中的衰减总和 (decaying sum)
g t ← ∇ f ( w t − 1 ) g_t \gets \nabla f(w_{t-1}) gt←∇f(wt−1)
m t ← μ m t − 1 + ( 1 − μ ) g t m_t \gets \mu m_{t-1} + (1 - \mu) g_t mt←μmt−1+(1−μ)gt
m t ‾ ← m t 1 − μ t \overline{m_t} \gets \frac{m_t}{1 - \mu^t} mt←1−μtmt
n t ← v n t − 1 + ( 1 − v ) g t 2 n_t \gets v n_{t-1} + (1-v)g_t^2 nt←vnt−1+(1−v)gt2
n t ‾ ← n t 1 − v t \overline{n_t} \gets \frac{n_t}{1 - v^t} nt←1−vtnt
w t ← w t − 1 − η m t ‾ n t ‾ + ϵ w_t \gets w_{t-1} - \eta \frac{\overline{m_t}}{\sqrt{\overline{n_t} + \epsilon}} wt←wt−1−ηnt+ϵmt
AdaMax
和 Adam 使用了 L 2 L_2 L2 不同,其使用了 L ∞ L_\infin L∞
g t ← ∇ f ( w t − 1 ) g_t \gets \nabla f(w_{t-1}) gt←∇f(wt−1)
m t ← μ m t − 1 + ( 1 − μ ) g t m_t \gets \mu m_{t-1} + (1 - \mu) g_t mt←μmt−1+(1−μ)gt
m t ‾ ← m t 1 − μ t \overline{m_t} \gets \frac{m_t}{1 - \mu^t} mt←1−μtmt
n t ← m a x ( v n t − 1 , ∣ g t ∣ ) n_t \gets max(vn_{t-1}, |g_t|) nt←max(vnt−1,∣gt∣)
w t ← w t − 1 − η m t ‾ n t + ϵ w_t \gets w_{t-1} - \eta \frac{\overline{m_t}}{n_t + \epsilon} wt←wt−1−ηnt+ϵmt

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)