深度学习常见概念整理(一)
目录
- 1.卷积(Convolution)卷积核(Kernel)过滤器(Filters)
- 2.池化(pooling)
- 3.通道(channel)
- 4.全连接层
- 5.全卷积网络
- 6.零填充(Zero-padding)
- 7.步长(Stride)
- 8.权重(weight)
- 9.偏差(bias)
- 10.激活函数(Activation Function)
- 11.多层感知机MLP
- 12.神经网络
- 13.正向传播(Forward Propagation)
- 14.反向传播(Backpropagation)
- 15.损失函数(loss function)
- 16.梯度下降(Gradient Descent)
- 17.学习率(Learning Rate)
- 18.优化器(Optimizer)
本博客参考部分博客进行摘录和补充。
1.卷积(Convolution)卷积核(Kernel)过滤器(Filters)
卷积:
可以看作是对某个区域的加权求和(作点积)卷积核:
如图中红框中橘色区域右下角数字组成33的卷积核,常见卷积核尺寸11 33 55过滤器:
单通道情况:过滤器=卷积核
多通道情况:过滤器是卷积核的集合(一个过滤器对应一个特征图)过滤器与卷积核区别:
卷积核就是由长和宽来指定的,是一个二维的概念。
而过滤器是是由长、宽和深度指定的,是一个三维的概念。
过滤器可以看做是卷积核的集合。
过滤器比卷积核高一个维度——深度。
详解https://blog.csdn.net/weixin_38481963/article/details/109906338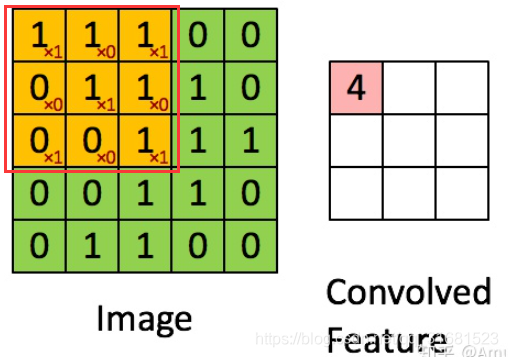
2.池化(pooling)
一般来说,卷积层后面都会加上一个池化层,它是对卷积层的进一步特征抽样,用于压缩数据与参数量,减小过拟合(Overfitting)。其具体操作与卷积层基本相同,但只取对应位置的最大值与平均值(最大池化、平均池化)。
池化过程强调特征不变性。尽可能保留图像的特征。
例如最大池化: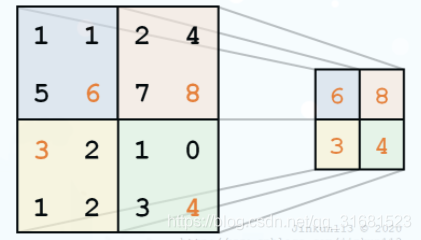
3.通道(channel)
无论是输入还是中间产生的特征图,通常并不是单一的二维图,而是多个图组成的,我们称每一张图为一个通道。
详细讲解:https://zhuanlan.zhihu.com/p/251068800
一个卷积核对应一个通道(channels)
(1)单通道卷积: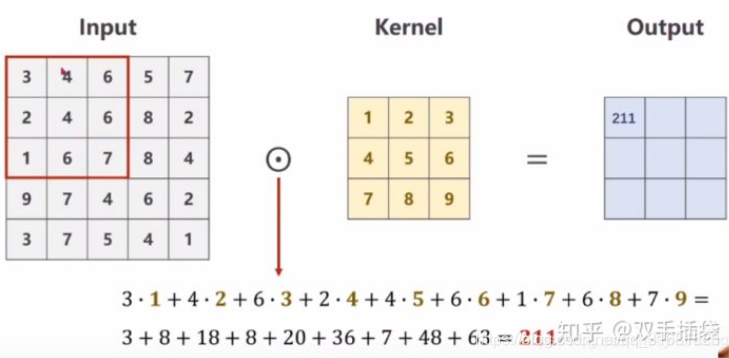
(2)多通道卷积(RGB三通道)
如果只要一个卷积核,则输出结果通道只有一个,为R、G、B三个颜色通道上卷积结果的累加;
增加卷积核数量到3,则输出结果有三个通道。
4.全连接层
将二维空间转化成一维向量,将全连接层的输出送入分类器或回归器来做分类和回归。
在卷积神经网络中,前面的卷积层的参数少但计算量大,后面的全连接层则相反,因此加速优化重心放在前面的卷积层,参数调优的重心放在后面的全连接层。
5.全卷积网络
将一般的卷积神经网络的全连接层替换成1x1的卷积层,使得网络可以接受任意大小的输入图像,网络输出的是一张特征图,特征图上的每个点对应其输入图像上的感受野区域。
多个3x3卷积比7x7卷积的优点在于:参数量减少并且非线性表达能力增强;
1x1卷积的作用在于:可以用于特征降维与升维,各通道特征融合,以及全卷积网络(支持任意输入图像大小)。
6.零填充(Zero-padding)
在输入矩阵的边缘使用零值进行填充,这样我们就可以对输入图像矩阵的边缘进行滤波。零填充的一大好处是可以让我们控制特征图的大小。使用零填充的也叫做泛卷积,不适用零填充的叫做严格卷积。
7.步长(Stride)
卷积核每次移动的距离叫做步长
8.权重(weight)
如果一个神经元有两个输入,则每个输入将具有分配给它的一个关联权重。我们随机初始化权重,并在模型训练过程中更新这些权重。训练后的神经网络对其输入赋予较高的权重,这是它认为与不那么重要的输入相比更为重要的输入。为零的权重则表示特定的特征是微不足道的。
例如输入为a,其关联权重为w,则最终输入为a*w
9.偏差(bias)
除了权重之外,另一个被应用于输入的线性分量被称为偏差。它被加到权重与输入相乘的结果中。基本上添加偏差的目的是来改变权重与输入相乘所得结果的范围的。
10.激活函数(Activation Function)
一旦将线性分量应用于输入,将会需要应用一个非线性函数。这通过将激活函数应用于线性组合来完成。激活函数将输入信号转换为输出信号。应用激活函数后的输出看起来像 f(a *W1+ b),其中 f()就是激活函数。如下图。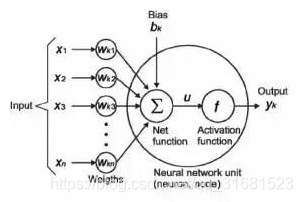
常见激活函数机器优缺点:
https://blog.csdn.net/tyhj_sf/article/details/79932893
(1)sigmoid
(2)tanh
(3)Relu
(4)Leaky ReLU
(5)ELU (Exponential Linear Units)
(6)MaxOut
11.多层感知机MLP
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构。多层感知机层与层之间是全连接的。如下图: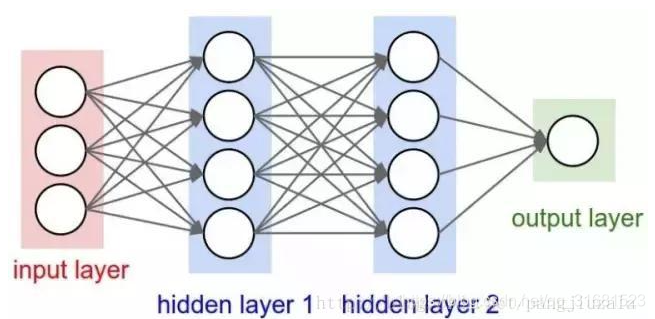
12.神经网络
它由相互联系的神经元形成。神经网络的目标是找到一个未知函数的近似值。
一个很好的神经网络定义:
神经网络由许多相互关联的概念化的人造神经元组成,它们之间传递相互数据,并且具有根据网络"经验"调整的相关权重。神经元具有激活阈值,如果通过其相关权重的组合和传递给他们的数据满足这个阈值的话,其将被解雇;发射神经元的组合导致"学习"。
神经网络分为输入层 隐藏层 输出层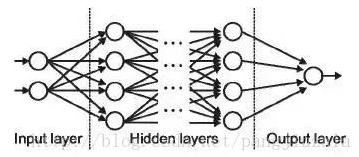
13.正向传播(Forward Propagation)
正向传播是指输入通过隐藏层到输出层的运动。在正向传播中,信息沿着一个单一方向前进。输入层将输入提供给隐藏层,然后生成输出。这过程中是没有反向运动的。
14.反向传播(Backpropagation)
当我们定义神经网络时,我们为我们的节点分配随机权重和偏差值。一旦我们收到单次迭代的输出,我们就可以计算出网络的错误。然后将该错误与成本函数的梯度一起反馈给网络以更新网络的权重。 最后更新这些权重,以便减少后续迭代中的错误。使用成本函数的梯度的权重的更新被称为反向传播。
在反向传播中,网络的运动是向后的,错误随着梯度从外层通过隐藏层流回,权重被更新。
15.损失函数(loss function)
详解及总结https://zhuanlan.zhihu.com/p/58883095
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
(1)0-1损失函数(zero-one loss)
(2)绝对值损失函数
(3)log对数损失函数
(4)平方损失函数
(5) 指数损失函数(exponential loss)
(6)Hinge 损失函数
(7)感知损失(perceptron loss)函数
(8)交叉熵损失函数 (Cross-entropy loss function)
多分类和二分类损失函数选取:
详解https://blog.csdn.net/weixin_33796177/article/details/88022703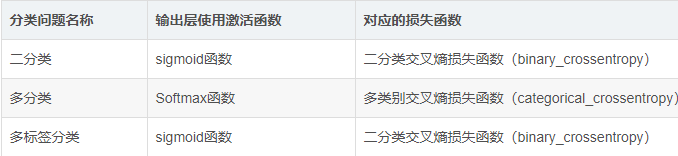
16.梯度下降(Gradient Descent)
详解https://www.cnblogs.com/pinard/p/5970503.html
梯度下降是一种最小化成本的优化算法。要直观地想一想,在爬山的时候,你应该会采取小步骤,一步一步走下来,而不是一下子跳下来。因此,我们所做的就是,如果我们从一个点 x 开始,我们向下移动一点,即Δh,并将我们的位置更新为 x-Δh,并且我们继续保持一致,直到达到底部。考虑最低成本点。
沿着梯度向量相反的方向,梯度减少最快,也就是更加容易找到函数的最小值。
梯度下降的相关概念:
1. 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。
2.特征(feature):指的是样本中输入部分
3. 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数
比如对于单个特征的m个样本(x(i),y(i))(i=1,2,...m),可以采用拟合函数如下: hθ(x)=θ0+θ1x。
4.损失函数(loss function):为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。
17.学习率(Learning Rate)
学习率被定义为每次迭代中成本函数中最小化的量。简单来说,我们下降到成本函数的最小值的速率是学习率。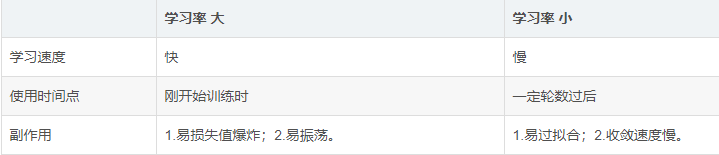
18.优化器(Optimizer)
详解https://zhuanlan.zhihu.com/p/261695487
动图https://blog.csdn.net/weixin_41417982/article/details/81561210
优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。
常用优化器:
(1) 随机梯度下降法(Stochastic Gradient Descent,SGD)
(2)SGD with Momentum
(3)SGD with Nesterov Acceleration
(4)AdaGrad(自适应学习率算法)
(5)AdaDelta / RMSProp
(6)Adam
(7)Nadam
优化器选择策略:
(1)首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑SGD+Nesterov Momentum或者Adam。
(2)选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。
(3)充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
(4)根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
(5)先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
(6)考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。切换策略可以参考本文介绍的方法。
(7)数据集一定要充分的打散(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
(8)训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
(9)制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。
其余参考文章:
深度学习入门必须理解这25个概念 https://blog.csdn.net/hzp666/article/details/76070346
深度学习常见的基本概念整理 https://blog.csdn.net/hzp666/article/details/76070346
[深度学习] 基本概念介绍汇总 https://www.cnblogs.com/jinkun113/p/14186132.html
青古の每篇一歌
《你的眼神》
淡淡然掠过
神秘又美丽
她仿似骤来的雨

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)