动手学深度学习之数据增广
数据增广数据增强增加一个已有的数据集,使得有更多的多样性在语言里面加入各种不同的背景噪音改变图片的颜色和形状使用增强数据训练一般的情况下是做随机的增强,然后生成图片,然后再进行训练常见的增强的方式几十种其他的办法总结代码实现%matplotlib inlineimport torchimport torchvisionfrom torch import nnfrom d2l import torc
·
数据增广
数据增强
- 增加一个已有的数据集,使得有更多的多样性
- 在语言里面加入各种不同的背景噪音
- 改变图片的颜色和形状

使用增强数据训练
- 一般的情况下是做随机的增强,然后生成图片,然后再进行训练
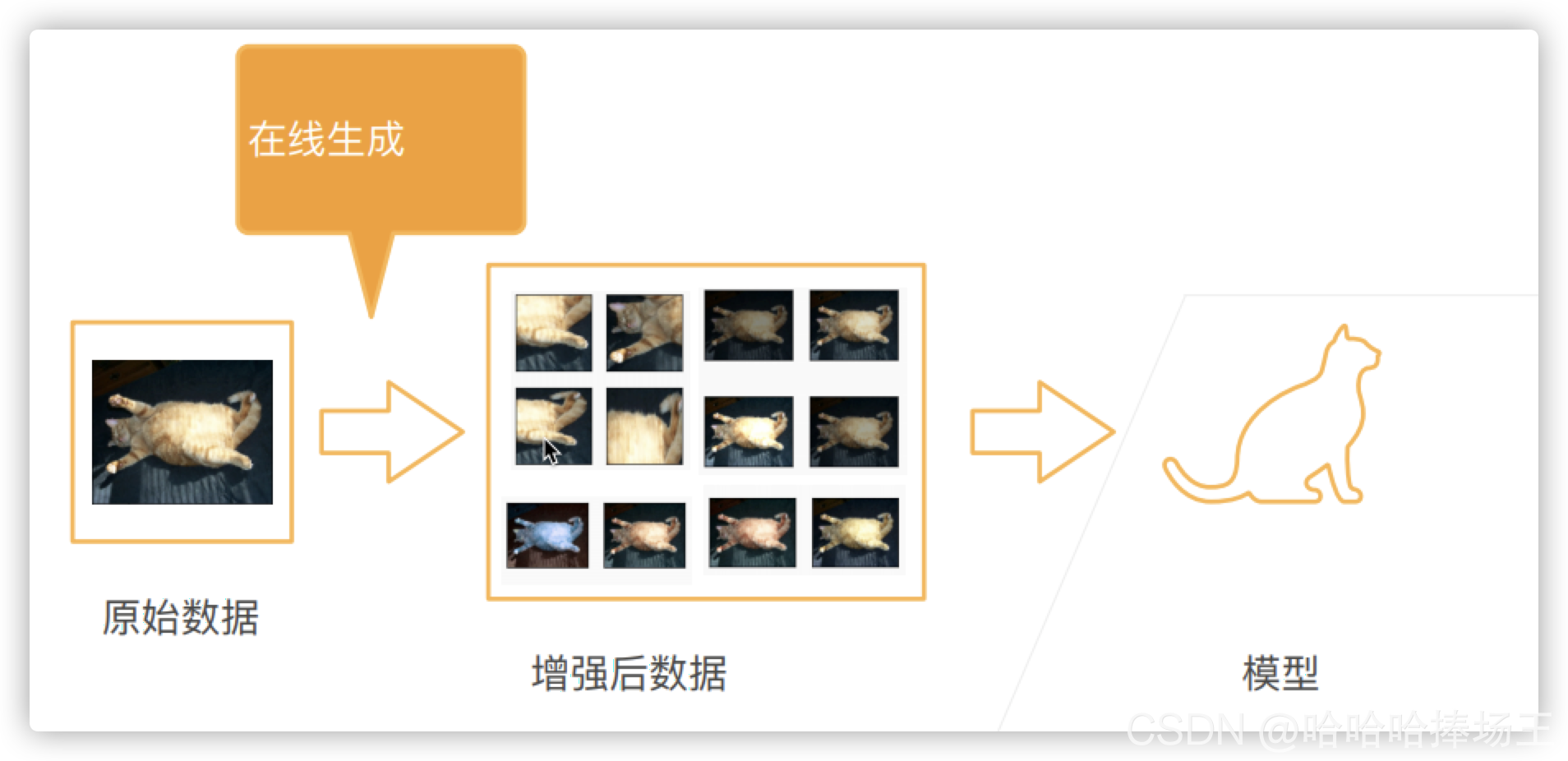
常见的增强的方式



- 几十种其他的办法

总结

代码实现
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.Image.open("/Users/tiger/Desktop/study/机器学习/d2l-zh/pytorch/img/cat1.jpg")
d2l.plt.imshow(img);
# img: 图片,aug:数据增广的方式,
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
# 左右翻转图像
apply(img, torchvision.transforms.RandomHorizontalFlip()) # RandomHorizontalFlip()函数的作用就是在水平方向随机的翻转
# 上下翻转
apply(img, torchvision.transforms.RandomVerticalFlip()) # RandomVerticalFlip()函数的作用就是在垂直方向随机翻转
# 随机剪裁
# RandomResizedCrop函数的作用就是随机裁剪一个然后在Resize,参数一:最后的输出大小,参数二:随机裁剪的大小区间,参数三:裁剪的高宽比
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)
# 随机更改图像的亮度
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0, saturation=0, hue=0)) # 亮度、对比度、饱和度、色调
# 随机更改图像的色调
apply(img, torchvision.transforms.ColorJitter(
brightness=0, contrast=0, saturation=0, hue=0.5)) # 亮度、对比度、饱和度、色温
# 随机更改图像的亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)
color_aug = torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5,
saturation=0.5, hue=0.5)
apply(img, color_aug)
# 结合多种图像增广方法
# Compose
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
color_aug, shape_aug
])
apply(img, augs)
# 使用图像增广进行训练
all_images = torchvision.datasets.CIFAR10(train=True, root="../data/", download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
99.9%
# 只是用最简单的随机左右翻转
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()
])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# 定义一个辅助函数,以便读取图像和应用图像增广
def load_cifar10(is_train, sugs, batch_size):
dataset = torchvision.datasets.CIFAR10(
root="../data/", train=is_train,
transforms=augs, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers=0)
return dataloader
# 定义一个函数使用多GPU对模型进行训练
def train_batch_ch13(net, X, y, loss, trainer, devices):
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(net, features, labels, loss, trainer,
devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(
epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3], None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
# 定义train_with_data_aug 函数,使用图像增广来训练模型
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.Adam(net.parameters(), lr=lr) # Adam可以理解为一个平滑的SGD
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
train_with_data_aug(train_augs, test_augs, net)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)