MDNN:一种用于药物-药物反应预测的多模态深度神经网络
目录背景介绍模型描述模型架构展示计算对象介绍方法DKG通道HF通道双模态融合实验结果背景介绍模型来自文章:“MDNN: A Multimodal Deep Neural Network for Predicting Drug-Drug Interaction Events”,文章提出了一个用于DDI(药物-药物反应,drug-drug interaction)预测的多模态深度神经网络MDNN,即M
背景介绍
模型来自文章:“MDNN: A Multimodal Deep Neural Network for Predicting Drug-Drug Interaction Events”,文章提出了一个用于DDI(药物-药物反应,drug-drug interaction)预测的多模态深度神经网络MDNN,即Multimodal Deep Neural Network。文章设计了一个基于药物知识图(Drug Knowledge Graph,DKG)的通道和基于异质特征(Heterogeneous Feature,HF)的通道,通过这个双通道框架来获取药物的多模态特征表达。最后,通过一个多模态融合神经网络来探索药物多模态表征之间的互补关系。
背景:随着药物种类的快速增长,在多药联合治疗的情况下,药物安全管理变得尤为重要。在同时给药的情况下,经常发生药物-药物相互作用(drug - drug Interactions,DDI),这可能导致药物不良反应,造成伤害和巨大的医疗费用。因此,准确预测DDI成为临床重要任务,有助于临床医生做出有效决策,制定合适的治疗方案。目前已有许多基于人工智能的模型用于DDI预测。现有的研究方法较少关注DDI与target、酶(enzymes) 等多模态数据之间的潜在相关性。此外,它们也没有考虑到多通道数据的互补性。
为了解决上述局限性,论文提出了一个多模态深度神经网络(MDNN)框架旨在针对DDI进行有效的多模态数据的联合表示学习。作者设计了一个基于药物知识图(DKG)和基于异质性特征(HF)的双通道框架来获取药物的多模态表征。受到图神经网络学习图结构信息的启发,作者提出了GNN层,通过从DKG中提取结构信息和语义关系来学习药物表示。最后,设计了一个多模态融合神经网络,通过探索药物多模态表征之间的互补关系来预测DDI。
模型描述
模型架构展示
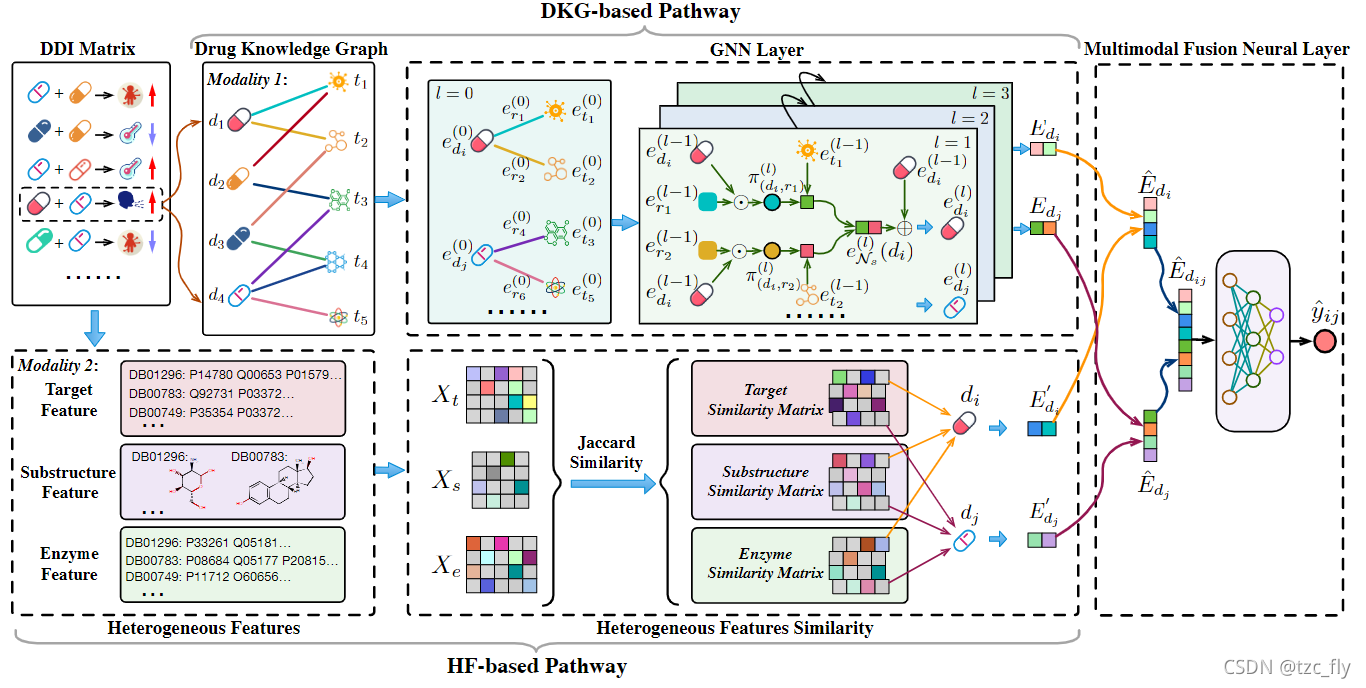
模型的架构如上图,由两个主要通道组成:基于DKG的通道和基于HF的通道。基于DKG的通道利用图神经网络在构建的药物知识图上提取药物之间的拓扑结构信息和语义关系。基于HF的通道旨在从不同的模式中提取预测信息,以提高学习模型的性能。采用多模态融合神经层有效地辅助结构信息和异质性特征的联合表示学习,以探索多模态数据的交叉互补性。
计算对象介绍
论文提出几个将在问题表述中使用的基本定义:
- DDI Matrix:将DDI event记录为 γ ∈ y i j N d × N d \gamma\in y_{ij}^{N_{d}\times N_{d}} γ∈yijNd×Nd, N d N_{d} Nd表示药物的数量, y i j ∈ { 0 , y 1 , . . . , y N } y_{ij}\in\left\{0,y_{1},...,y_{N}\right\} yij∈{0,y1,...,yN}代表药物 d i d_{i} di与 d j d_{j} dj混合后的反应属于哪一类,特别的,如果 y i j = 0 y_{ij}=0 yij=0则意味着两类药物不会有反应;
- DKG:本文考虑了一种用于DDI预测的特殊知识图,称为药物知识图: G = { ( d , r d t , t ) ∣ d ∈ D , r d t ∈ R , t ∈ T , D ∩ T = ⊘ } G=\left\{(d,r_{dt},t)|d\in D,r_{dt}\in R,t\in T,D\cap T=\oslash\right\} G={(d,rdt,t)∣d∈D,rdt∈R,t∈T,D∩T=⊘}其中, D D D和 T T T分别表示药物集合,以及与药物相关的尾部实体(tail entities)的集合; R R R表示药物和尾部实体之间的关系集;
- HF:异构特征包括目标特征、子结构特征和酶特征。 表示如下: X d = { X t , X s , X e } ∈ R N d × ( N t + N s + N e ) X_{d}=\left\{X_{t},X_{s},X_{e}\right\}\in R^{N_{d}\times(N_{t}+N_{s}+N_{e})} Xd={Xt,Xs,Xe}∈RNd×(Nt+Ns+Ne)其中, X t ∈ R N d × N t X_{t}\in R^{N_{d}\times N_{t}} Xt∈RNd×Nt, X s ∈ R N d × N s X_{s}\in R^{N_{d}\times N_{s}} Xs∈RNd×Ns, X e ∈ R N d × N e X_{e}\in R^{N_{d}\times N_{e}} Xe∈RNd×Ne, N t , N s , N e N_{t},N_{s},N_{e} Nt,Ns,Ne分别表示目标特征、子结构特征和酶特征的维数;
- DDI Events Prediction:给定DDI events matrix γ \gamma γ,DKG G G G,与HF X d X_{d} Xd,我们的目标是预测DDI,换言之,我们的目标是计算: y ^ i j = Γ ( d i , d j ∣ Θ , γ , G , X d ) \widehat{y}_{ij}=\Gamma(d_{i},d_{j}|\Theta,\gamma,G,X_{d}) y ij=Γ(di,dj∣Θ,γ,G,Xd)其中, y ^ i j \widehat{y}_{ij} y ij表示药物 d i d_{i} di与 d j d_{j} dj反应出现事件的概率, Θ \Theta Θ表示模型 Γ \Gamma Γ的参数。
方法
DKG通道
GNN层被用来捕获药物知识图中的药物拓扑结构和语义关系。药物知识图 G G G的初始表达矩阵为: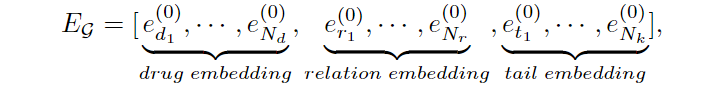
N d , N r , N k N_{d},N_{r},N_{k} Nd,Nr,Nk分别是药物,关联,尾部实体的数量; e d 0 , e r 0 , e t 0 e_{d}^{0},e_{r}^{0},e_{t}^{0} ed0,er0,et0分别是药物,关联,尾部实体的初始特征。
对任意药物 d i d_{i} di,随机抽取其固定数量的邻居 N s ( d i ) N_{s}(d_{i}) Ns(di),为将关联的语义信息纳入药物的表达,论文定义 d i d_{i} di与第 n n n个尾部实体 t n t_{n} tn(两者由关联 r i , n r_{i,n} ri,n联系)之间的特征为: π d i , r i , n ( l ) = s u m [ ( e d i ( l − 1 ) ⊙ e r i , n ( l − 1 ) ) W 1 ( p ) + b 1 ( p ) ] \pi_{d_{i},r_{i,n}}^{(l)}=sum[(e_{d_{i}}^{(l-1)}\odot e_{r_{i,n}}^{(l-1)})W_{1}^{(p)}+b_{1}^{(p)}] πdi,ri,n(l)=sum[(edi(l−1)⊙eri,n(l−1))W1(p)+b1(p)]其中, e d i ( l − 1 ) , e r i , n ( l − 1 ) e_{d_{i}}^{(l-1)},e_{r_{i,n}}^{(l-1)} edi(l−1),eri,n(l−1)分别是 d i d_{i} di和 r i , n r_{i,n} ri,n在第 l − 1 l-1 l−1层GNN后的特征。 W 1 ( p ) , b 1 ( p ) W_{1}^{(p)},b_{1}^{(p)} W1(p),b1(p)分别是权重矩阵和偏置, ⊙ \odot ⊙表示element-wise乘积。
通过聚合函数获得 d i d_{i} di的邻域信息: e N s ( d i ) ( l ) = ∑ t n ∈ N s ( d i ) π d i , r i , n ( l ) e t n ( l − 1 ) e_{N_{s}(d_{i})}^{(l)}=\sum_{t_{n}\in N_{s}(d_{i})}\pi_{d_{i},r_{i,n}}^{(l)}e_{t_{n}}^{(l-1)} eNs(di)(l)=tn∈Ns(di)∑πdi,ri,n(l)etn(l−1)然后得到 d i d_{i} di基于DKG的特征: E d i = e d i ( l ) = σ ( ( e d i ( l − 1 ) ⊕ e N s ( d i ) ( l ) ) W 2 + b 2 ) E_{d_{i}}=e^{(l)}_{d_{i}}=\sigma((e^{(l-1)}_{d_{i}}\oplus e_{N_{s}(d_{i})}^{(l)})W_{2}+b_{2}) Edi=edi(l)=σ((edi(l−1)⊕eNs(di)(l))W2+b2)其中, σ \sigma σ是一个激活函数, ⊕ \oplus ⊕表示拼接向量。
HF通道
在HF通道中,使用异质性特征来计算药物相似性。异质特征包括target特征、substructure特征和enzyme特征。每种特征对应一组描述符,因此药物可以用二进制特征向量表示,其每个维(1或0)表示对应描述符的存在或不存在。为了使药物节点表示更加密集,提高向量的精度,本文使用主成分分析方法(PCA)对特征进行压缩,降低稀疏性,并使用Jaccard相似性度量方法从特征向量中计算成对的药物相似度(杰卡德相似度是指两个集合的交集元素个数在并集中所占的比例);
原文使用了杰卡德相似度,但我觉得有些描述不清,所以直接用降维后的矩阵代替
下面降维后得到目标的特征 E t ∈ R N d × k , E s ∈ R N d × k , E e ∈ R N d × k E^{t}\in R^{N_{d}\times k},E^{s}\in R^{N_{d}\times k},E^{e}\in R^{N_{d}\times k} Et∈RNd×k,Es∈RNd×k,Ee∈RNd×k, k k k是降维后的维数。因此,可以得到药物 d i d_{i} di对应的特征 e d i t ∈ E t , e d i s ∈ E s , e d i e ∈ E e e^{t}_{d_{i}}\in E^{t},e^{s}_{d_{i}}\in E^{s},e^{e}_{d_{i}}\in E^{e} edit∈Et,edis∈Es,edie∈Ee。拼接后作为 d i d_{i} di的异构特征: E d i ′ = e d i t ⊕ e d i s ⊕ e d i e E'_{d_{i}}=e^{t}_{d_{i}}\oplus e^{s}_{d_{i}}\oplus e^{e}_{d_{i}} Edi′=edit⊕edis⊕edie
双模态融合
基于DKG的通道和基于HF的通道提供互补的信息。为了更好地利用这两种途径的信息,作者在多模态神经融合层中考虑它们的一致性和互补性。将 d i d_{i} di基于DKG的特征 E d i E_{d_{i}} Edi和基于HF的特征 E d i ′ E'_{d_{i}} Edi′拼接作为 d i d_{i} di的最终特征: E ^ d i = E d i ⊕ E d i ′ \widehat{E}_{d_{i}}=E_{d_{i}}\oplus E'_{d_{i}} E di=Edi⊕Edi′同理可以得到 d j d_{j} dj的最终特征 E ^ d j \widehat{E}_{d_{j}} E dj,将 d i d_{i} di和 d j d_{j} dj的特征向量拼接后通过全连接网络得到概率: y ^ i j = ρ ( ( E ^ d i ⊕ E ^ d j ) W 3 ( q ) + b 3 ( q ) ) \widehat{y}_{ij}=\rho((\widehat{E}_{d_{i}}\oplus \widehat{E}_{d_{j}})W_{3}^{(q)}+b_{3}^{(q)}) y ij=ρ((E di⊕E dj)W3(q)+b3(q))其中, ρ \rho ρ表示激活函数。
实验结果
结果表明,MDNN在真实数据集上的DDI预测性能最好。论文认为是该模型既探索了药物知识图中的药物拓扑嵌入表示,又探索了多模态数据的跨模态嵌入表示。此外,通过与其他先进方法的比较研究表明,MDNN获得了最稳定的性能,这可能是由于:
- (1)MDNN引入了GNN模型,利用药物知识图中的拓扑结构信息和语义关系;
- (2) MDNN利用多模态数据的交叉模态互补信息。

为了探究基于DKG和基于HF的通道如何改善所提出模型的性能,作者对以下 M D N N MDNN MDNN变体进行了研究。 M D N N d k g MDNN_{dkg} MDNNdkg只考虑拓扑结构和语义关系,从DKG中学习药物对的嵌入。 M D N N h f MDNN_{hf} MDNNhf仅使用异质性特征探索药物对的跨模态嵌入。由于 M D N N h f MDNN_{hf} MDNNhf只考虑药物-药物的多模态属性特征,因此在所有指标上的表现都比 M D N N MDNN MDNN和 M D N N d k g MDNN_{dkg} MDNNdkg差。下图显示了对比结果,验证了 M D N N MDNN MDNN模型中每个通道的贡献,表明将邻域的拓扑表示与DKG和异构特征的语义关系相结合,有利于提高DDI的预测性能。从结果可以看出, M D N N MDNN MDNN在所有指标上都优于两种变体。
在论文中,涉及了3个重要的参数:领域样本的大小 N s N_{s} Ns,GNN的层数 l l l,DKG初始表达矩阵 E G E_{G} EG的维数 d d d(即矩阵的行数)。
作者固定其他参数,调整其中某个参数实验得到以下结果:
从结果看出:
- 当 N s N_{s} Ns过小时,模型不能捕捉到更完整的结构信息,但如果 N s N_{s} Ns过大,又会容易引入噪声误导结果;
- GNN层从1层开始增加,各项指标都在下降,因为层数的增加容易带来噪声影响,说明增加节点的跳数不会带来效果的改善;
- 最后,我们需要适当大小的维数 d d d,适当大小的维数足够编码药物与尾部实体,以及关联的信息,但维数过多会容易使模型过拟合。
最后,论文在两个不同的任务上检验模型,将所涉及的药物随机分成五个子集,其中四个作为训练药物集,其余一个作为测试药物集,以评估模型的有效性。对于任务A,作者以训练集中的DDI训练模型,然后对训练集药物与测试集药物之间的DDI进行预测。对于任务B, MDNN对测试集药物之间的DDI进行预测。
从上表中可以看出,MDNN在两个任务中的实验结果都优于其他方法。这有效地说明了无论是在已知药物还是新药之间,利用结构信息和异构特征都提高了DDI的预测精度。
后续思考
第一方面
论文中关于HF通道的处理比较简单,且在杰卡德相似度计算部分描述不够清楚,重点应当还是编码问题,当我们面对异质性特征(靶标target,子结构substructure,酶enzyme)时,它们都是二进制编码形式,属于比较稀疏的表达方式,我们也许也不需要经过杰卡德相似度的计算过程;
首先有人会想到基于BERT获得embedding表达,但是BERT和ELMo类似,每个词没有固定的词向量,它是根据词的上下文环境来动态产生当前词的词向量,这与word2vec以及glove等通用词向量模型是不同的。个人认为各种药物在排列上不存在上下文关系,所以使用BERT是一种没有意义的操作。
我们或许可以先将这些原始的二进制编码先处理成低维向量embedding的形式,然后通过一层简单的多头注意力层来进行特征的变换。我没有考虑使用Transformer,Transformer的编码器部分本质是多头注意力与全连接变换的堆叠,过多的层容易引入HF通道中的噪声反而降低性能,我们就用少量的层还可以提高计算效率。
当我们使用多头注意力层时,可以学习到不同药物在异质性特征上对应的重要程度,多头注意力相当于给出了注意力层的多个"表示空间",即融合了不同角度的自注意力信息,能确保某个药物在异质性特征上获得更全面的表达。
第二方面
在此之前,我想到一个问题,关于DDI,可能存在两组相似的(drug-drug),但其导致的反应是不一样的,这有些类似于语义分割问题中的现象:两块区域,像素有所相似,但其对应的对象是不同的;在最近的研究中,来自中科院大学的一位博士提出了像素近邻损失,强迫模型学会区分某些特殊的相似像素。
或许我们可以借鉴近邻像素的思想,将其用于改进这篇文章,我们可以先根据数据集,通过简单计算药物特征相似度(比如计算第 i i i组的(drug-drug)与第 j j j组的(drug-drug)),获取到相似的几组(drug-drug)并组成集合,它们导致的反应是不同的。我们为这个集合保持更多注意,也就是说在训练中,当某个drug-drug在这个集合中,我们就要刻意增加它的损失,强迫模型学会区分它们。
或者更简单粗暴地,我们直接把DKG通道的GNN换成图注意力网络,但那样会使模型丧失一部分可解释性(关于区分相似drug-drug组合的可解释性)。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)