【kubernetes】k8s的job和cronjob详细说明【job、cronjob(cj)、descheduler(pod均衡)】
文章目录说明说明
文章目录
说明
-
官方介绍
jobs -
运行一次性容器
容器按照持续运行的时间可分为两类:- 服务类容器
服务类容器通常持续提供服务,需要一直运行,比如 http server,daemon 等。 - 工作类容器
工作类容器则是一次性任务,比如批处理程序,完成后容器就退出。- Kubernetes 的 Deployment、ReplicaSet 和 DaemonSet 都用于管理服务类容器;
- 对于工作类容器,我们用 Job。
- 服务类容器
-
RestartPolicy:
job pod的template的RestartPolicy只能指定Never或OnFailure,当job未完成的情况下:- 如果RestartPolicy指定Never,则job会在pod出现故障时创建新的pod,且故障pod不会消失。.status.failed加1。
- 如果RestartPolicy指定OnFailure,则job会在pod出现故障时其内部重启容器,而不是创建pod。.status.failed不变。
-
任务主要包含两种:
- Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
- job3是基于调度的Job执行将会自动产生多个job,调度格式参考Linux的cron系统。
环境准备
- 首先需要有一套集群
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 58d v1.21.0
node1 Ready <none> 58d v1.21.0
node2 Ready <none> 58d v1.21.0
[root@master ~]#
- 然后我们创建一个文件用来放后面的测试文件,创建一个命名空间,后面测试都在这个命名空间做
[root@master ~]# mkdir job
[root@master ~]# cd job/
[root@master job]# kubectl create ns job
namespace/job created
[root@master job]# kubens job
Context "context" modified.
Active namespace is "job".
[root@master job]#
[root@master job]# kubectl get pods
No resources found in job namespace.
[root@master job]#
job
介绍
-
Job,我们在日常的工作中经常都会遇到一些需要进行批量数据处理和分析的需求,当然也会有按时间来进行调度的工作,在Kubernetes集群中为我们提供了Job和job3两种资源对象来应对这种需求。
-
Job负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。而job3则就是在Job上加上了时间调度。
常用命令
唉 懒得单独列了 直接看下面使用的吧 该用的都用到了 都是kubectl的语法规则 只是换成了job而已。
创建job的yaml文件
kubectl create job --help是可以查看帮助的,创建的命令也可以在这里获取到- 现在获取一个job1的配置文件
我们在最后面跟上了一个command,如果不需要,需要将-- sh -c "date ; sleep 10"全删掉哦
[root@master job]# kubectl create job job1 --image=busybox --dry-run=client -o yaml -- sh -c "date ; sleep 10" > job1.yaml
[root@master job]# ls
job1.yaml
[root@master job]#
# 增加一行镜像获取规则
[root@master job]# cat job1.yaml
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: null
name: job1
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- sh
- -c
- date ; sleep 10
image: busybox #node节点上得有这个镜像啊
imagePullPolicy: IfNotPresent
name: job1
resources: {}
#RestartPolicy仅支持Never和OnFailure两种,不支持Always
restartPolicy: Never
status: {}
[root@master job]#
- 注意Job的RestartPolicy仅支持Never和OnFailure两种,不支持Always, Job就相当于来执行一个批处理任务,执行完就结束了,如果支持Always的话会陷入了死循环了。
- Nerver 只要任务没有完成,就会删除pod并新创建pod运行,直到job完成【会产生多个pod】
- OnFailure 只要pod没有完成,则会重启pod,直到job完成
创建job并常规测试
说明注意看下面
# 创建
[root@master job]# kubectl apply -f job1.yaml
job.batch/job1 created
[root@master job]#
# 羡慕CompLETIONS是0/1,是因为job还没创建,
#需要等待seelp 10 以后,就是10 秒以后才会创建
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job1 0/1 5s 5s
[root@master job]#
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job1 0/1 11s 11s
[root@master job]#
# 10秒以后创建了,状态也成0/0了
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job1 1/1 13s 22s
# 创建成功以后pod状态也就成 completed了【10秒以前状态是Running】,不会再创建了
# 也就是说该pod也就是失效了 可以删除了
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job1-rll96 0/1 Completed 0 28s
[root@master job]#
[root@master job]# kubectl delete pod job1-rll96
pod "job1-rll96" deleted
[root@master job]#
增加job任务次数测试
主要有3个参数
-
spec:【下面参数是放在spec下面的】
backoffLimit: 4
如果job失败,则重试几次completions: 6
job结束需要成功运行的Pod个数,即状态为Completed的pod数【也就是job任务总次数】parallelism: 2
一次性运行N个pod,这个值不会超过completions的值。
-
现在我们将上面参数加到yaml文件并测试
[root@master job]# cat job2.yaml
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: null
name: job2
spec:
backoffLimit: 4
completions: 6
parallelism: 2
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- sh
- -c
- date ; sleep 10
image: busybox
imagePullPolicy: IfNotPresent
name: job2
resources: {}
restartPolicy: Never
status: {}
[root@master job]#
# 创建job2,可以看到job2一共有6个任务
[root@master job]# kubectl apply -f job2.yaml
job.batch/job2 created
[root@master job]#
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job1 1/1 13s 15m
job2 0/6 5s 5s
[root@master job]#
# job一次创建2个,可以看到pod确实有2个生成
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-7rp99 1/1 Running 0 11s
job2-xkjd4 1/1 Running 0 11s
[root@master job]#
# 因为一次执行2个,所以2个执行完呢状态就会为completed了,又会重新生成2个新pod执行
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-7rp99 0/1 Completed 0 22s
job2-fmbdp 1/1 Running 0 8s
job2-kxtqg 1/1 Running 0 8s
job2-xkjd4 0/1 Completed 0 22s
[root@master job]#
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job1 1/1 13s 15m
job2 4/6 27s 27s
[root@master job]#
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-7rp99 0/1 Completed 0 29s
job2-fmbdp 0/1 Completed 0 15s
job2-kxtqg 0/1 Completed 0 15s
job2-nqf48 1/1 Running 0 3s
job2-ttmxb 1/1 Running 0 3s
job2-xkjd4 0/1 Completed 0 29s
[root@master job]#
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job1 1/1 13s 15m
job2 4/6 34s 34s
# 直到6个任务分3次执行完且状态全部为completed为止哦。
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-7rp99 0/1 Completed 0 35s
job2-fmbdp 0/1 Completed 0 21s
job2-kxtqg 0/1 Completed 0 21s
job2-nqf48 1/1 Running 0 9s
job2-ttmxb 1/1 Running 0 9s
job2-xkjd4 0/1 Completed 0 35s
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job1 1/1 13s 15m
job2 6/6 38s 39s
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-7rp99 0/1 Completed 0 41s
job2-fmbdp 0/1 Completed 0 27s
job2-kxtqg 0/1 Completed 0 27s
job2-nqf48 0/1 Completed 0 15s
job2-ttmxb 0/1 Completed 0 15s
job2-xkjd4 0/1 Completed 0 41s
[root@master job]#
将刚才创建的2个job都删了吧
[root@master job]# kubectl delete jobs.batch job1
job.batch "job1" deleted
[root@master job]# kubectl delete jobs.batch job2
job.batch "job2" deleted
[root@master job]#
[root@master job]# kubectl get pods
No resources found in job namespace.
[root@master job]#
RestartPolicy测试
-
前面说过
Job的RestartPolicy仅支持Never和OnFailure两种,不支持Always, Job就相当于来执行一个批处理任务,执行完就结束了,如果支持Always的话会陷入了死循环了。- Nerver 只要任务没有完成,就会删除pod并新创建pod运行,直到job完成【会产生多个pod】
- OnFailure 只要pod没有完成,则会重启pod,直到job完成
-
这2个参数呢,很直观了,一个删除重建,一个重启,我这只以Nerver来测试吧
首先要直到,什么情况pod才不会完成呢,比如,里面定义的command命令错误,这样的pod就不会成功,job就会认为这个任务是没有完成的。
[root@master job]# cat job2.yaml
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: null
name: job2
spec:
backoffLimit: 4
completions: 6
parallelism: 2
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- sh
- -c
# 我在下面seelp后面加了个x,没有这个命令的
- date ; sleepx 10
image: busybox
imagePullPolicy: IfNotPresent
name: job2
resources: {}
restartPolicy: Never
status: {}
[root@master job]#
- 现在开始测试
[root@master job]# kubectl apply -f job2.yaml
job.batch/job2 created
[root@master job]#
# 创建成功以后 job状态一直是 0/6 因为不会执行成功的
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job2 0/6 5s 5s
[root@master job]#
# pod数量这个就是 backoffLimit: 4 定义的,需要重复4次,一次2个,但状态都会为Error,全是失败的
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-76z75 0/1 Error 0 9s
job2-n52l6 0/1 Error 0 9s
job2-tr59f 0/1 Error 0 6s
job2-trtwd 0/1 Error 0 6s
[root@master job]#
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-76z75 0/1 Error 0 12s
job2-n52l6 0/1 Error 0 12s
job2-tr59f 0/1 Error 0 9s
job2-trtwd 0/1 Error 0 9s
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job2 0/6 15s 15s
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-76z75 0/1 Error 0 18s
job2-jn89q 0/1 Error 0 5s
job2-mv6z7 0/1 Error 0 5s
job2-n52l6 0/1 Error 0 18s
job2-tr59f 0/1 Error 0 15s
job2-trtwd 0/1 Error 0 15s
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job2 0/6 24s 24s
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-76z75 0/1 Error 0 26s
job2-jn89q 0/1 Error 0 13s
job2-mv6z7 0/1 Error 0 13s
job2-n52l6 0/1 Error 0 26s
job2-tr59f 0/1 Error 0 23s
job2-trtwd 0/1 Error 0 23s
# 理论上,一次2个,重复4次,一共有8次才对,但最终只有6次
# 所以 backoffLimit: 4定义的次数是不准的,这是正常的哈,我们不要去数,不要去较这个真
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job2-76z75 0/1 Error 0 29s
job2-jn89q 0/1 Error 0 16s
job2-mv6z7 0/1 Error 0 16s
job2-n52l6 0/1 Error 0 29s
job2-tr59f 0/1 Error 0 26s
job2-trtwd 0/1 Error 0 26s
# 可以用这个命令看到详细过程的哈
[root@master job]# kubectl describe job job2
Name: job2
Namespace: job
Selector: controller-uid=de313ff4-ec7a-49d8-a719-46e83ad25e4e
Labels: controller-uid=de313ff4-ec7a-49d8-a719-46e83ad25e4e
job-name=job2
Annotations: <none>
Parallelism: 2
Completions: 6
Start Time: Wed, 08 Sep 2021 12:23:59 +0800
Pods Statuses: 0 Running / 0 Succeeded / 6 Failed
Pod Template:
Labels: controller-uid=de313ff4-ec7a-49d8-a719-46e83ad25e4e
job-name=job2
Containers:
job2:
Image: busybox
Port: <none>
Host Port: <none>
Command:
sh
-c
date ; sleepx 10
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 4m10s job-controller Created pod: job2-76z75
Normal SuccessfulCreate 4m10s job-controller Created pod: job2-n52l6
Normal SuccessfulCreate 4m7s job-controller Created pod: job2-tr59f
Normal SuccessfulCreate 4m7s job-controller Created pod: job2-trtwd
Normal SuccessfulCreate 3m57s job-controller Created pod: job2-jn89q
Normal SuccessfulCreate 3m57s job-controller Created pod: job2-mv6z7
Warning BackoffLimitExceeded 2m37s job-controller Job has reached the specified backoff limit
[root@master job]#
将配置sleep改回去【后面如果要测试,怕不知道发生了啥】,并删了这个pod,此致,job就算完成了,下面开始看job3
[root@master job]# kubectl delete job job2
job.batch "job2" deleted
[root@master job]#
[root@master job]# kubectl get pods
No resources found in job namespace.
[root@master job]#
测试【计算圆周率2000位】
perl镜像获取
首先node节点上需要有perl这个镜像,我现在也没有,因为我集群是没有外网的,所以从外面倒过来的,这时候顺便简单重温一下这个镜像过程吧【之前有详细说明的,这就不做详细说明】【perl镜像800M,麻烦不说,还费时间,唉】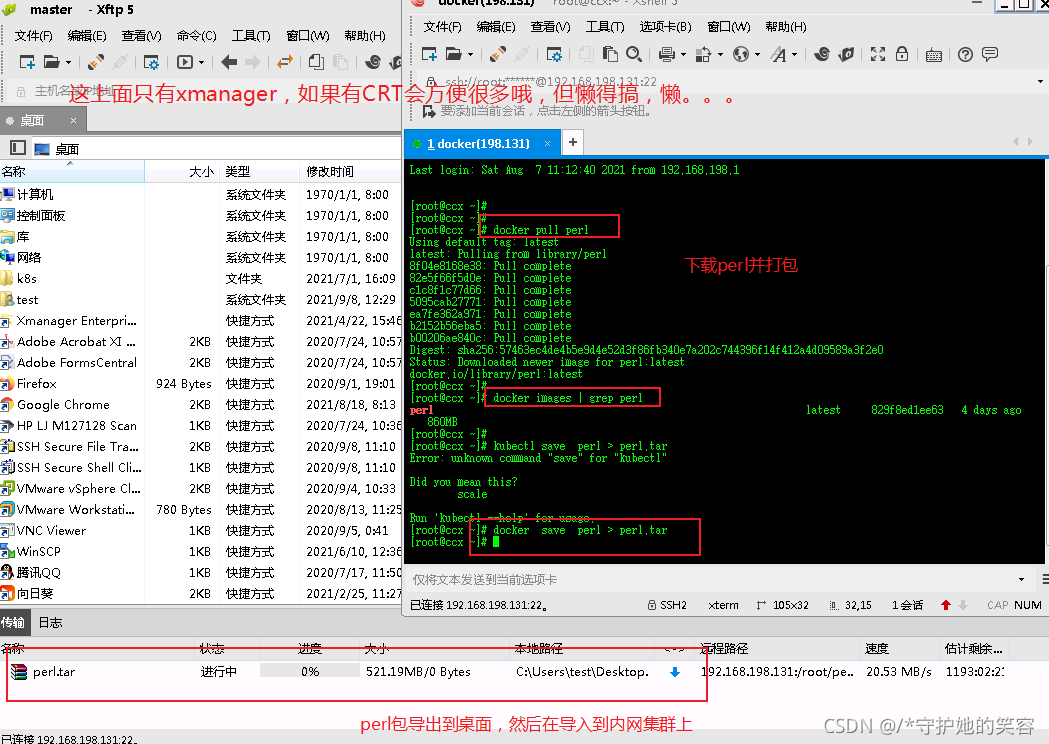
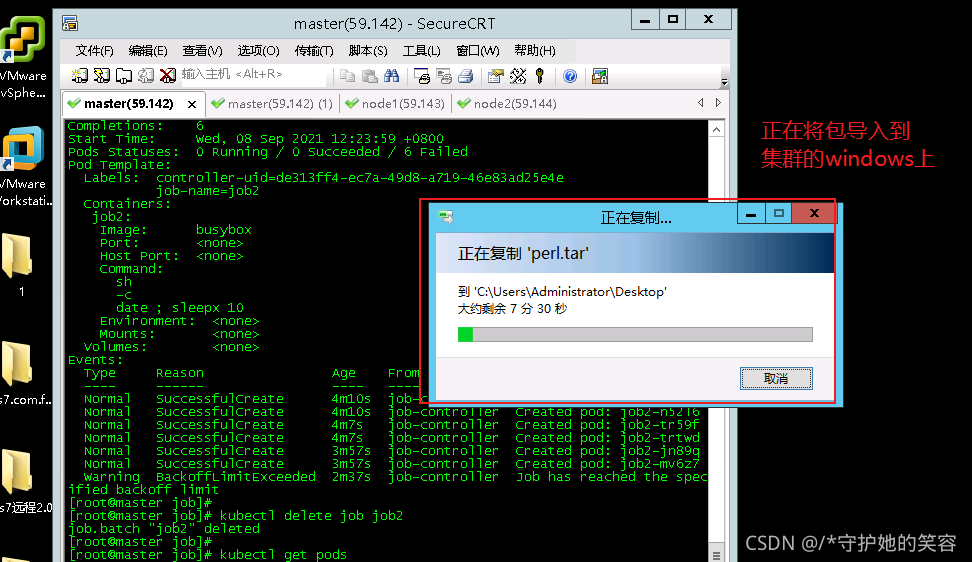
这推荐一个rz -E命令,贼方便,get起来吧。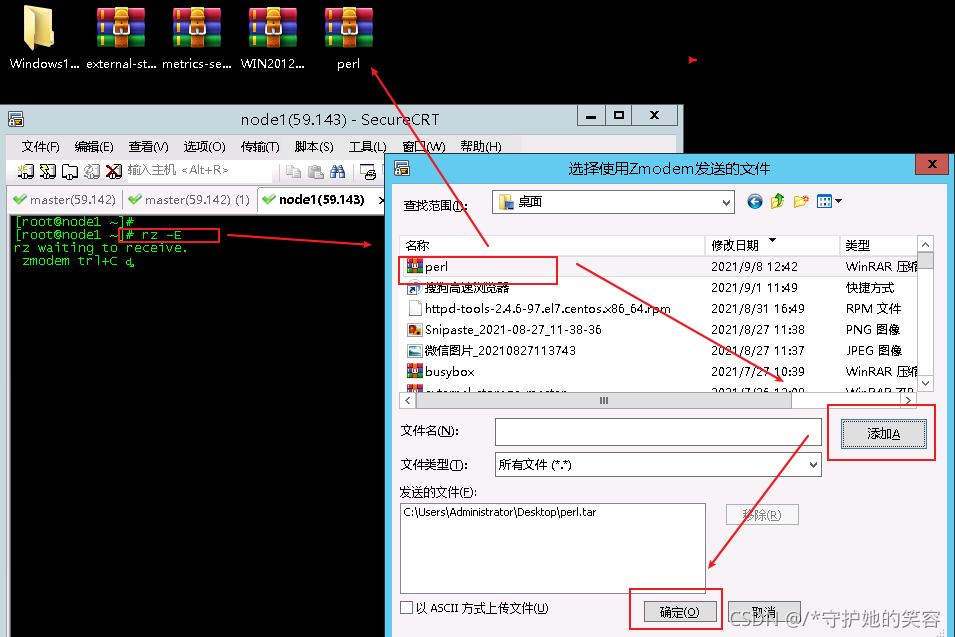
最后呢,在2个node节点导入该包就好了
[root@node1 ~]# rz -E
rz waiting to receive.
zmodem trl+C ȡ
100% 862399 KB 15399 KB/s 00:00:56 0 Errors
[root@node1 ~]# scp perl.tar node2:~
The authenticity of host 'node2 (192.168.59.144)' can't be established.
ECDSA key fingerprint is SHA256:+JrT4G9aMhaod/a9gBjUOzX5aONqQ7a4OX0Oj3Z978c.
ECDSA key fingerprint is MD5:7f:4c:cc:5c:10:d2:54:d8:3c:dd:da:39:48:30:12:59.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node2,192.168.59.144' (ECDSA) to the list of known hosts.
root@node2's password:
perl.tar 100% 842MB 20.5MB/s 00:41
[root@node1 ~]#
[root@node1 ~]# docker load -i perl.tar
4dd0c5812fd4: Loading layer 119.3MB/119.3MB
6680d5caa699: Loading layer 17.18MB/17.18MB
1c721e0a3622: Loading layer 17.87MB/17.87MB
f36cbdef5e3a: Loading layer 150MB/150MB
6db3d1445d34: Loading layer 520.8MB/520.8MB
08180df9d29e: Loading layer 3.584kB/3.584kB
2517a95647ad: Loading layer 57.91MB/57.91MB
Loaded image: perl:latest
[root@node1 ~]#
[root@node1 ~]# docker images | grep perl
perl latest 829f8ed1ee63 4 days ago 860MB
[root@node1 ~]#
[root@node1 ~]# ssh node2
root@node2's password:
Last login: Thu Sep 2 16:48:37 2021 from 192.168.59.1
[root@node2 ~]# docker load -i perl.tar
4dd0c5812fd4: Loading layer 119.3MB/119.3MB
6680d5caa699: Loading layer 17.18MB/17.18MB
1c721e0a3622: Loading layer 17.87MB/17.87MB
f36cbdef5e3a: Loading layer 150MB/150MB
6db3d1445d34: Loading layer 520.8MB/520.8MB
08180df9d29e: Loading layer 3.584kB/3.584kB
2517a95647ad: Loading layer 57.91MB/57.91MB
Loaded image: perl:latest
[root@node2 ~]# docker images | grep perl
perl latest 829f8ed1ee63 4 days ago 860MB
[root@node2 ~]#
配置文件编辑并测试
[root@master job]# cat job3.yaml
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: null
name: job3
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- sh
- -c
- perl -Mbignum=bpi -wle 'print bpi(2000)'
image: perl
imagePullPolicy: IfNotPresent
name: job3
resources: {}
restartPolicy: Never
status: {}
[root@master job]#
[root@master job]# kubectl apply -f job3.yaml
job.batch/job3 created
[root@master job]#
# 因为计算任务没完成,所以job是0/1,pod是running
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job3 0/1 5s 5s
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job3-4dn4c 1/1 Running 0 12s
# 计算完成以后,job1/1,pod成了completed
[root@master job]# kubectl get job
NAME COMPLETIONS DURATION AGE
job3 1/1 12s 16s
[root@master job]#
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
job3-4dn4c 0/1 Completed 0 80s
[root@master job]#
# 我们可以通过日志的方式看输出哦
[root@master job]# kubectl logs job3-4dn4c
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
[root@master job]#
最后删除这个job
[root@master job]# kubectl delete jobs.batch job3
job.batch "job3" deleted
[root@master job]#
Cronjob【cj】
介绍
-
cronjob其实就是在Job的基础上加上了时间调度,我们可以:在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。这个实际上和Linux中的crontab就非常类似了。
-
一个cronjob对象其实就对应crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。
-
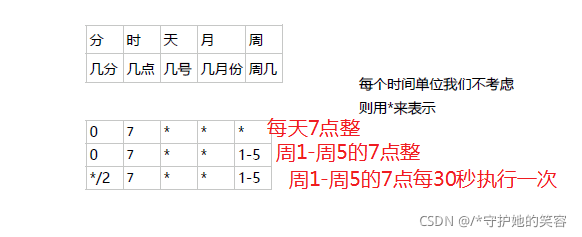
crontab的格式如下:
分 小时 日 月 周 要运行的命令
#第1列分钟(0~59)
#第2列小时(0~23)
#第3列日(1~31)
#第4列月(1~12)
#第5列星期(0~7)(0和7表示星期天)
#第6列要运行的命令
# 不考虑具体时间的话,可以用* 【和linux的crontab一样】
常用命令
唉 懒得单独列了 直接看下面使用的吧 该用的都用到了 都是kubectl的语法规则 只是换成了cj而已。
创建cj的yaml文件
-
kubectl create cj --help可以查看帮助 -
下面创建的schedule后面的看不懂就看上面介绍哈,时间规则。【node上需要有busybox镜像哈,没有的先导入】
[root@master job]# kubectl create cronjob mycj --image=busybox --schedule="*/1 * * * *" --dry-run=client -o yaml -- sh -c "date ; sleep 10" > cj1.yaml
[root@master job]# cat cj1.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
creationTimestamp: null
name: mycj
spec:
jobTemplate:
metadata:
creationTimestamp: null
name: mycj
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- sh
- -c
- date ; sleep 10
image: busybox
name: mycj
resources: {}
restartPolicy: OnFailure
# */1 其实就是每分钟哈
schedule: '*/1 * * * *'
status: {}
[root@master job]#
创建cj并常规测试
编辑文件并创建
[root@master job]# cat cj1.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
creationTimestamp: null
name: mycj
spec:
jobTemplate:
metadata:
creationTimestamp: null
name: mycj
spec:
template:
metadata:
creationTimestamp: null
spec:
terminationGracePeriodSeconds: 0
containers:
- command:
- sh
- -c
- date ; sleep 10
image: busybox
imagePullPolicy: IfNotPresent
name: mycj
resources: {}
restartPolicy: OnFailure
schedule: '*/1 * * * *'
status: {}
[root@master job]#
[root@master job]# kubectl apply -f cj1.yaml
cronjob.batch/mycj created
[root@master job]#
理论上呢,这个会每分钟执行一次,执行一次呢,pod会持续10秒左右
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 0 <none> 6s
[root@master job]#
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mycj-27184800-2tq92 1/1 Running 0 5s
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 1 10s 54s
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mycj-27184800-2tq92 1/1 Running 0 12s
[root@master job]#
我们可以新打开一个窗口执行:watch -n 0.5 kubectl get pods【动态查看,0.5秒刷新一次】
理论上会1-2分钟创建一个pod
[root@master job]# watch -n 0.5 kubectl get pods
Every 0.5s: kubectl get pods Wed Sep 8 16:03:46 2021
NAME READY STATUS RESTARTS AGE
mycj-27184801-l9dxk 0/1 Completed 0 2m46s
mycj-27184802-w4ln2 0/1 Completed 0 106s
mycj-27184803-vftp5 0/1 Completed 0 46s
下面可以看到6分钟了创建第4个pod并在运行
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mycj-27184803-vftp5 0/1 Completed 0 3m2s
mycj-27184804-wx6fz 0/1 Completed 0 2m2s
mycj-27184805-5vqlw 0/1 Completed 0 62s
mycj-27184806-vvzbs 1/1 Running 0 2s
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 1 10s 6m54s
[root@master job]#
查看详细
[root@master job]# kubectl describe cj mycj
Name: mycj
Namespace: job
Labels: <none>
Annotations: <none>
Schedule: */1 * * * *
Concurrency Policy: Allow
Suspend: False
Successful Job History Limit: 3
Failed Job History Limit: 1
Starting Deadline Seconds: <unset>
Selector: <unset>
Parallelism: <unset>
Completions: <unset>
Pod Template:
Labels: <none>
Containers:
mycj:
Image: busybox
Port: <none>
Host Port: <none>
Command:
sh
-c
date ; sleep 10
Environment: <none>
Mounts: <none>
Volumes: <none>
Last Schedule Time: Wed, 08 Sep 2021 16:08:00 +0800
Active Jobs: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 8m34s cronjob-controller Created job mycj-27184800
Normal SawCompletedJob 8m22s cronjob-controller Saw completed job: mycj-27184800, status: Complete
Normal SuccessfulCreate 7m34s cronjob-controller Created job mycj-27184801
Normal SawCompletedJob 7m22s cronjob-controller Saw completed job: mycj-27184801, status: Complete
Normal SuccessfulCreate 6m34s cronjob-controller Created job mycj-27184802
Normal SawCompletedJob 6m22s cronjob-controller Saw completed job: mycj-27184802, status: Complete
Normal SuccessfulCreate 5m34s cronjob-controller Created job mycj-27184803
Normal SawCompletedJob 5m23s cronjob-controller Saw completed job: mycj-27184803, status: Complete
Normal SuccessfulDelete 5m23s cronjob-controller Deleted job mycj-27184800
Normal SuccessfulCreate 4m34s cronjob-controller Created job mycj-27184804
Normal SawCompletedJob 4m22s cronjob-controller Saw completed job: mycj-27184804, status: Complete
Normal SuccessfulDelete 4m22s cronjob-controller Deleted job mycj-27184801
Normal SuccessfulCreate 3m34s cronjob-controller Created job mycj-27184805
Normal SawCompletedJob 3m22s cronjob-controller Saw completed job: mycj-27184805, status: Complete
Normal SuccessfulDelete 3m22s cronjob-controller Deleted job mycj-27184802
Normal SuccessfulCreate 2m34s cronjob-controller Created job mycj-27184806
Normal SawCompletedJob 2m22s cronjob-controller Saw completed job: mycj-27184806, status: Complete
Normal SuccessfulDelete 2m22s cronjob-controller Deleted job mycj-27184803
Normal SuccessfulCreate 94s cronjob-controller Created job mycj-27184807
Normal SawCompletedJob 82s cronjob-controller Saw completed job: mycj-27184807, status: Complete
Normal SuccessfulDelete 82s cronjob-controller Deleted job mycj-27184804
Normal SuccessfulCreate 34s cronjob-controller Created job mycj-27184808
Normal SawCompletedJob 22s cronjob-controller Saw completed job: mycj-27184808, status: Complete
Normal SuccessfulDelete 22s cronjob-controller Deleted job mycj-27184805
[root@master job]#
现在删除这个cj吧
[root@master job]# kubectl delete cj mycj
cronjob.batch "mycj" deleted
[root@master job]#
[root@master job]# kubectl get pods
No resources found in job namespace.
[root@master job]#
指定pod运行时间测试
-
上面呢,一个pod默认是10秒钟,但因为种种原因,一个pod存在时间可能不止10秒钟,现在呢,我们就指定该pod时间,比如只允许生成的pod运行5秒钟,那么pod到5秒钟的时候就会强制完成【删除】
-
实现这个呢实际上就是一行参数罢了:
activeDeadlineSeconds: 5【5是存在时间,单位是秒】 -
现在我们修改配置文件并创建该pod
[root@master job]# cat cj2.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
creationTimestamp: null
name: mycj
spec:
jobTemplate:
metadata:
creationTimestamp: null
name: mycj
spec:
activeDeadlineSeconds: 5
template:
metadata:
creationTimestamp: null
spec:
terminationGracePeriodSeconds: 0
containers:
- command:
- sh
- -c
- date ; sleep 10
image: busybox
imagePullPolicy: IfNotPresent
name: mycj
resources: {}
restartPolicy: OnFailure
schedule: '*/1 * * * *'
status: {}
[root@master job]# kubectl apply -f cj2.yaml
cronjob.batch/mycj created
[root@master job]#
加了这个参数创建的cj,可以看到多了一项LAST SCHEOULE,这个呢就是该新一轮pod从创建到删除的时间【可以看到这个时间不会超过1分钟】
但是pod的话只能有5秒,5秒后就删了,所以我们很难看到这个pod的存在
新打开一个窗口执行:watch -n 0.5 kubectl get pods【动态查看,0.5秒刷新一次】在这里面是可以看到pod存在5秒然后被删除的哈
[root@master job]#
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 0 <none> 17s
[root@master job]#
[root@master job]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mycj-27184814-6q575 0/1 ContainerCreating 0 0s
[root@master job]#
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 0 5s 25s
[root@master job]#
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 0 12s 32s
[root@master job]# kubectl get pods
No resources found in job namespace.
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 0 44s 64s
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 0 27s 107s
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 0 49s 2m9s
[root@master job]# kubectl get pods
No resources found in job namespace.
[root@master job]# kubectl get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
mycj */1 * * * * False 1 0s 2m20s
[root@master job]# kubectl get pods
No resources found in job namespace.
[root@master job]#
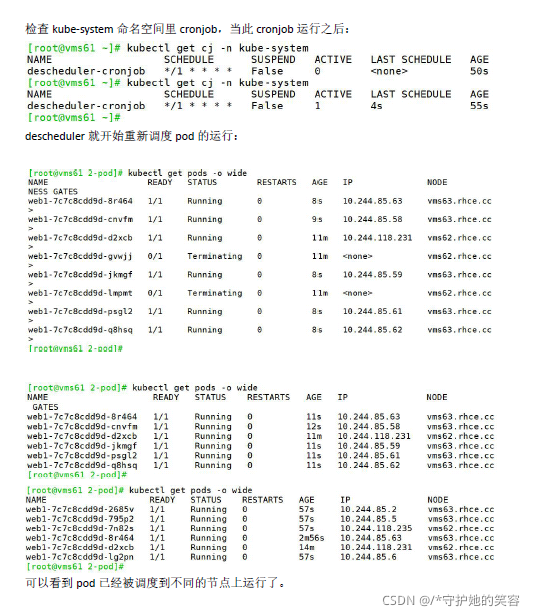
cj的特殊用法【descheduler均衡pod】
- 场景说明:
比如,deploy现在有10ge 副本,运行在node1和node2上- 问:新增一个node3节点之后,在其他节点运行的pod会被调度到新节点上,以均衡负载吗?
- 答案:不能 【如果要实现的话,必须先删除node1和node2上的pod】
但是呢,我们可以通过用descheduler来实现这个呢实际上就是使用到了cj
这个流程呢,不算复杂,我不做演示,感兴趣的可以自行测试哦。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)