spark进阶(二):Idea创建spark项目
·
环境:
scala:2.12.0
java:1.8
spark:3.1.2
一、Idea创建scala项目
Idea新建一个新的项目,选择通过maven创建:
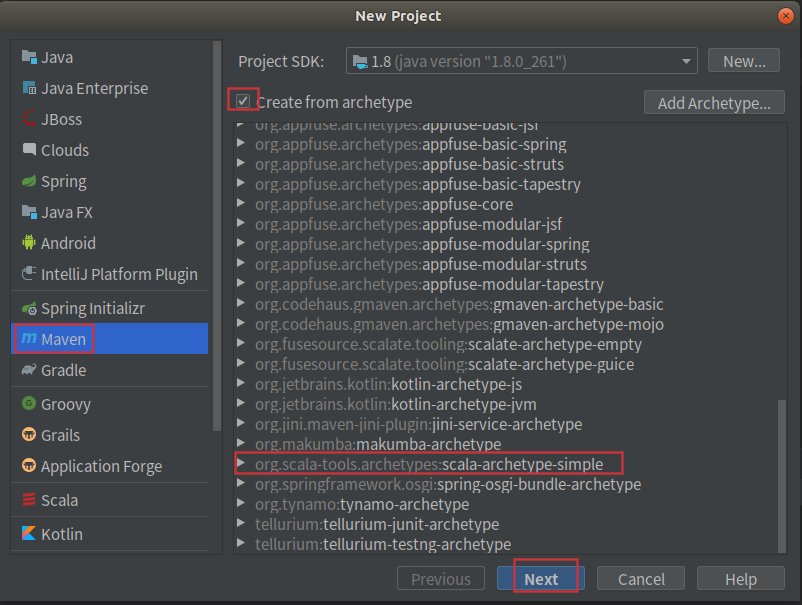
给项目起个名字,设置版本:
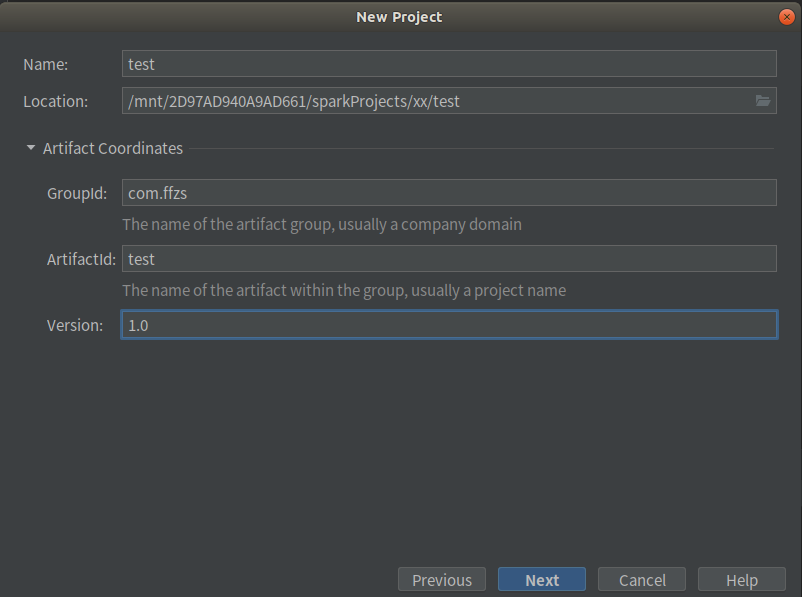
maven选项,如果有本地maven的话用本地的,没有的话建议下一个,不行用这个默认的也可以:
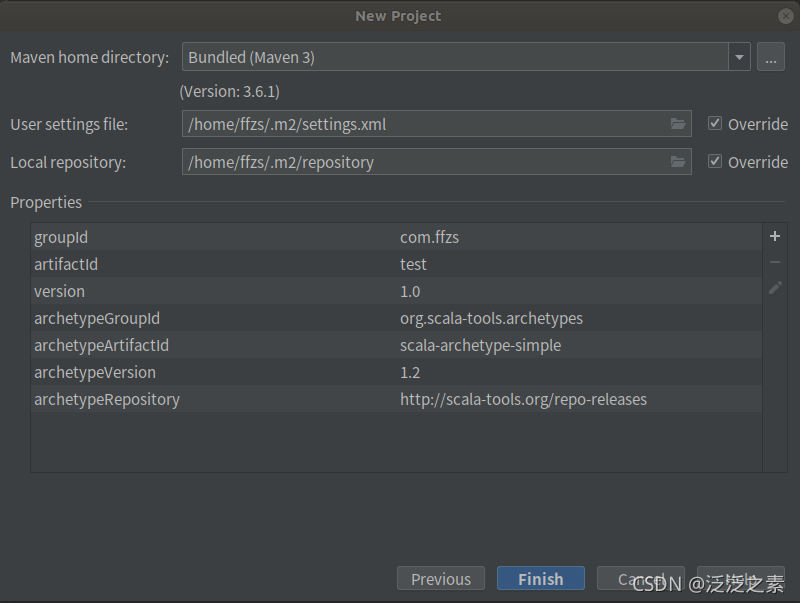
设置maven源为aliyun,上面的setting目录创建对应的setting.xml文件:
(base) [~/softwares]$ cat /home/ffzs/.m2/settings.xml
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
</settings>
这里创建的scala项目中默认使用的是scala 2.7.0版本,需要将pom.xml中的版本号换成你是用的版本:
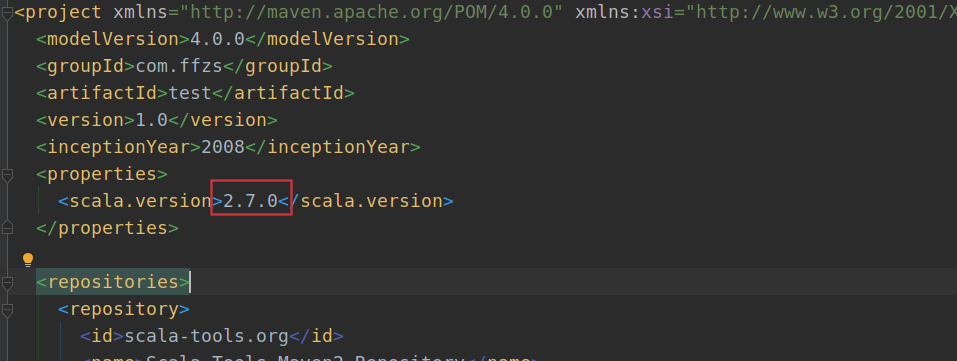
我的改成2.12.12,同时添加spark相关依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.12.12</scala.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.12</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
测试:
object RDDGroupTopN {
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
//设置应用程序名称,可以在Spark WebUI中显示
conf.setAppName("RDDGroupTopN")
//设置集群Master节点访问地址,此处为本地模式
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
//1. 加载本地数据
val linesRDD: RDD[String] = sc.textFile("data.txt")
//2. 将RDD元素转为(String,Int)形式的元组
val tupleRDD:RDD[(String,Int)]=linesRDD.map(line=>{
val name=line.split(",")(0)
val score=line.split(",")(1)
(name,score.toInt)
})
//3. 按照key(姓名)进行分组
val top5=tupleRDD.groupByKey().map(groupedData=>{
val name:String=groupedData._1
//每一组的成绩降序后取前3个
val scoreTop3:List[Int]=groupedData._2
.toList.sortWith(_>_).take(3)
(name,scoreTop3)//返回元组
})
//4. 循环打印分组结果
top5.foreach(tuple=>{
println("姓名:"+tuple._1)
val tupleValue=tuple._2.iterator
while (tupleValue.hasNext){
val value=tupleValue.next()
println("成绩:"+value)
}
println("*******************")
})
}
}
运行结果:
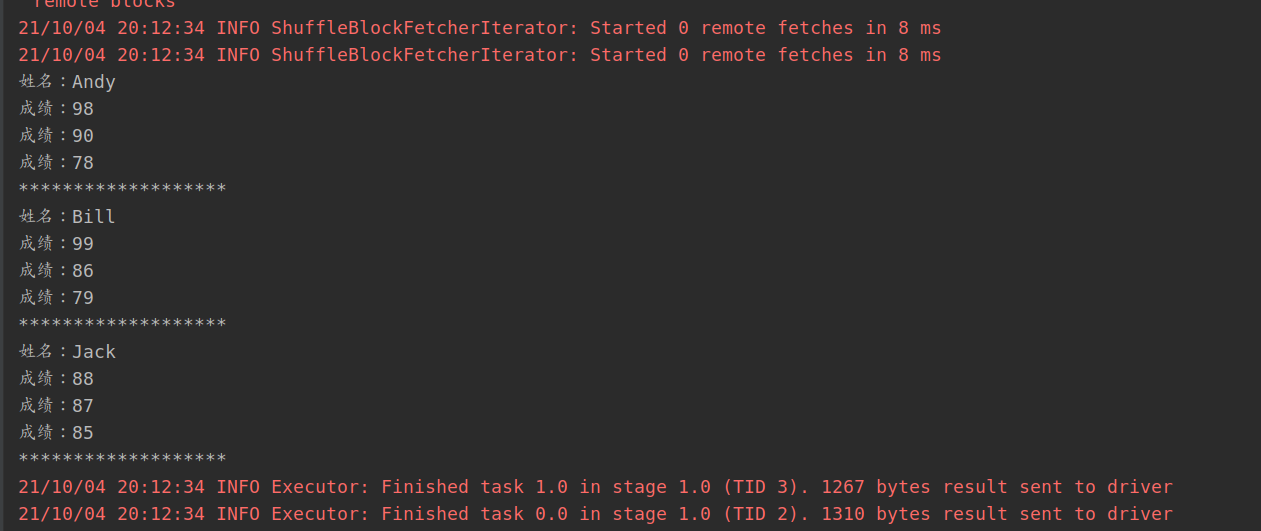

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)