pyspark config设置、增加配置、限制_success文件生成;spark-submit 集群提交参数
·
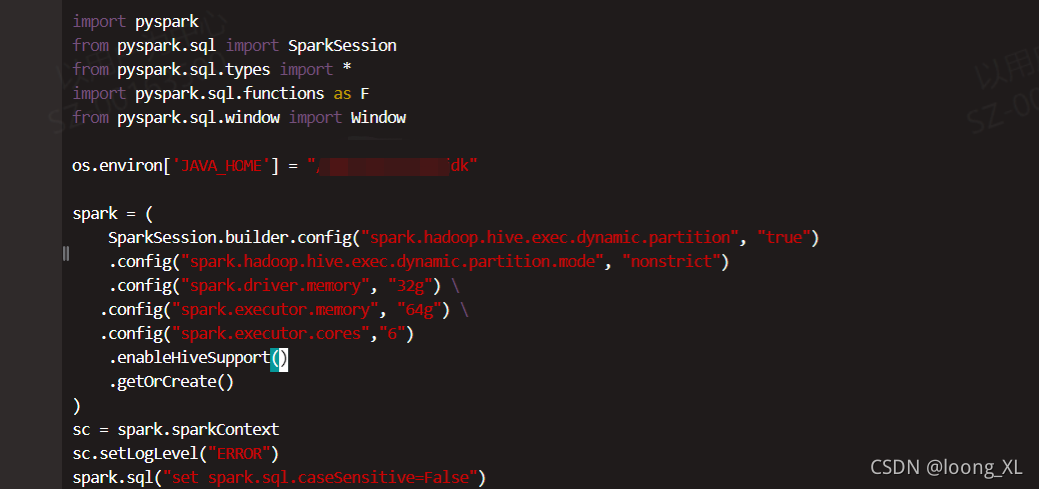
1、pyspark增加config设置
java heap错误增加内存
spark = (
SparkSession.builder.config("spark.hadoop.hive.exec.dynamic.partition", "true")
.config("spark.hadoop.hive.exec.dynamic.partition.mode", "nonstrict")
.config("spark.driver.memory", "32g") \
.config("spark.executor.memory", "64g") \
.config("spark.executor.cores","6")
.enableHiveSupport()
.getOrCreate()
)
sc = spark.sparkContext
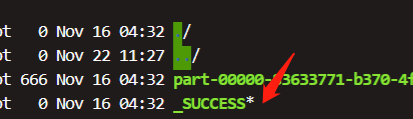
*****限制_success生成文件
spark = SparkSession \
.builder \
.config("spark.hadoop.mapreduce.fileoutputcommitter.marksuccessfuljobs","false") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
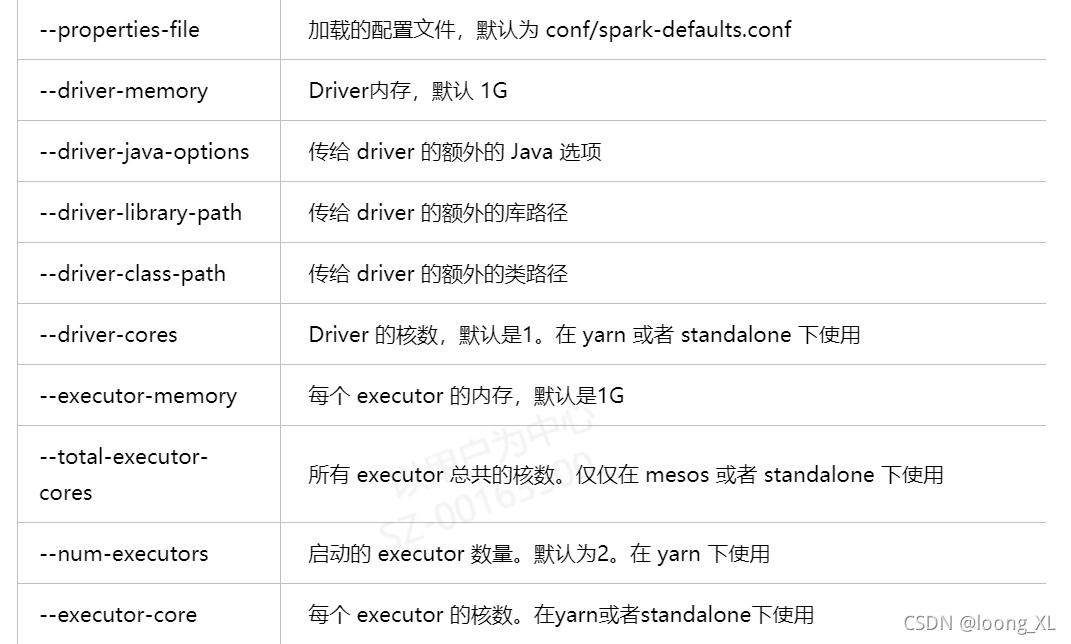
2、spark-submit 参数
参考:https://www.cnblogs.com/weiweifeng/p/8073553.html
nohup spark-submit --class com.tcl.video.search.recommend.SparkQueryApplication --executor-memory 6G --num-executors 6 --master yarn /tmp/java-applic****-spark.jar >> /tmp/java-applicati****ta-spark.log 2>&1 &
spark-submit --class com.tcl.video.search.recommend.SparkQueryApplication --executor-memory 6G --num-executors 6 --master yarn *******st.py --date 20211117

查看集群执行log:
yarn logs -applicationId applic******id值**0_77969

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)