python面试题大全
一、python基础面试题1.Python的特点Python是一种解释性语言【开发过程中没有了编译这个环节,类似于PHP或者Perl语言】Python是交互式语言【可以在一个Python提示符,直接互动执行程序】Python是面向对象语言【Python支持面向对象的风格或代码封装在对象的编程技术】Python是初学者的语言【Python对于初级程序员而言,是一种伟大的语言,他支持广泛的应用程序开发
一、python基础面试题
1.Python的特点
- Python是一种解释性语言【开发过程中没有了编译这个环节,类似于PHP或者Perl语言】
- Python是交互式语言【可以在一个Python提示符,直接互动执行程序】
- Python是面向对象语言【Python支持面向对象的风格或代码封装在对象的编程技术】
- Python是初学者的语言【Python对于初级程序员而言,是一种伟大的语言,他支持广泛的应用程序开发,从简单的文字处理到浏览器再到游戏】
- Python是跨平台的【它可以运行在Windows、Mac os或者Linux系统上,也就是说,在Windows上书写的Python程序,在Linux上也是可以运行的,类似于Java】
2.Python优缺点
优点:
易于学习【Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单】
易于阅读【Python代码定义的更清晰】
易于维护【Python的成功在于它的源代码是相当容易维护的】
一个广泛的标准库【Python的最大优势之一是丰富的库,跨平台的,在nuix、weindows和mac os上的兼容性很好】
互动模式【互动模式的支持,可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片段】
可移植性【基于其开发源代码的特性,Python已经被移植到许多平台】
可扩展性【如果需要一段运行很快的关键代码,或者想要编写一些不愿开发的算法,可以使用C或者C++完成那部分程序,然后从你的Python程序中调用】
数据库【Python提供所有主要的商业数据库的接口】
GUI编程(图形化界面)【Python支持GUI可以创建和移植到许多系统调用】
可嵌入性【可以将Python嵌入到C或者C++程序,让你程序的用户获得“脚本化”的能力】
点:
运行速度慢【和C程序相比非常慢,因为Python是解释型语言,代码在执行时会一行一行的翻译成CPU能理解的机器码,这个翻译过程非常耗时,所以很慢,而C程序是运行前直接编译成CPU能执行的机器码,所以非常快】
代码不能加密【如果要发布Python程序,实际上就是发布源代码,这一点跟C语言不通,C语言不用发布源代码,只需要把编译后的机器码(就是windows上常见的xxx.exe)发布出去,要从机器码反推出C代码是不可能的,所以,凡是编译型的语言,都没有这个问题,而解释型的语言,则必须把源码发布出去】
3.Python应用场景
Web开发【通过mod_wsgi模块,Apache可以运行用Python编写的Web程序。Python定义了WSGI标准应用接口来协调Http服务器与基于Python的Web程序之间的通信。一些Web框架,如Django,TurboGears,web2py,Zope等,可以让程序员轻松地开发和管理复杂的Web程序】
操作系统管理、服务器运维的自动化脚本【在很多操作系统里,Python是标准的系统组件。 大多数Linux发行版以及NetBSD、OpenBSD和Mac OS X都集成了Python,可以在终端下直接运行Python。Python编写的系统管理脚本在可读性、性能、代码重用度、扩展性几方面都优于普通的shell脚本】
网络爬虫【Python有大量的HTTP请求处理库和HTML解析库,并且有成熟高效的爬虫框架Scrapy和分布式解决方案scrapy-redis,在爬虫的应用方面非常广泛】
科学计算(数据分析)【NumPy、SciPy、Pandas、Matplotlib可以让Python程序员编写科学计算程序】
桌面软件【PyQt、PySide、wxPython、PyGTK是Python快速开发桌面应用程序的利器】
服务器软件(网络软件)【Python对于各种网络协议的支持很完善,因此经常被用于编写服务器软件、网络爬虫。第三方库Twisted支持异步网络编程和多数标准的网络协议(包含客户端和服务器),并且提供了多种工具,被广泛用于编写高性能的服务器软件】
游戏【很多游戏使用C++编写图形显示等高性能模块,而使用Python或者Lua编写游戏的逻辑、服务器。相较于Python,Lua的功能更简单、体积更小;而Python则支持更多的特性和数据类型】
搜狐、豆瓣、腾讯、网易、百度、阿里、淘宝、土豆、新浪等都在内部大量的使用Python
4.标识符
概念:计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系
合法标识符的命名规则:
- 只能由数字,字母和下划线组成
- 不可以是除了下划线之外的其他特殊字符
- 开头不能是数字或者空格
- 不能是Python的关键字
- 严格区分大小写 age Age
标识符的命名规范:
- 尽量做到见名知意【具有描述性】:尽量使用简单的英文单词表示
- 遵守一定的命名规范
- Python官方推荐的命名方式:变量名,函数名和文件名全小写,使用下划线连接,如:stu_name check_qq
- 驼峰命名法:不同的单词之间使用首字母大写的方式进行分隔,又分为大驼峰和小驼峰,比如:stuName就是小驼峰,StuName就是大驼峰,小驼峰常用于变量或者函数的命名,大驼峰常用于类的命名
5.打包pack和拆包unpack
*:所有 m1,m2,*m3 = 34,56,2,56,56,67,68,8,89 print(m1,m2,m3) m1,*m2,m3 = 34,56,2,56,56,67,68,8,89 print(m1,m2,m3) *m1,m2,m3 = 34,56,2,56,56,67,68,8,89 print(m1,m2,m3) m1,m2,*m3 = 34,56,2,56,56,67,68,8,89 print(m1,m2,*m3) m1,*m2 = [34,5,6,7,8] print(m1,m2)
6.变换两个变量的值
# 方式一:定义第三方变量 a = 10 b = 20 temp = a a = b b = temp print(a,b) # 方式二 ****** a = 10 b = 20 a,b = b,a print(a,b) # 方式三:加减法 a = 10 b = 20 a = a + b # a = 30 b = a - b # b = 10 a = a - b # a = 20 print(a,b) # 方式四:异或^ #原理:一个数异或另一个数两次,结果是该数本身 # print(56 ^ 3 ^ 3) a = 10 b = 20 a = a ^ b # a = 10 ^ 20 b = a ^ b # b = 10 ^ 20 ^ 20 = 10 a = a ^ b # a = 10 ^ 20 ^ 10 = 20 print(a,b) # 7.常量:值不能发生改变的标识符 # 常量命名法:所有英文单词全部大写,不同单词之间使用下划线相连 PI = 3.1415 print(PI)
7.可变数据类型和不可变数据类型
可变数据类型:list dict set
不可变数据类型:int float bool str tuple
8.说明is和==的区别和联系
a.==比较的是内容
b.is比较的是地址
c.如果两个变量的内容相同,他们的地址不一定相同,如果两个变量的地址相同,则他们的内容一定相同
9.切片特点
切片:根据指定的区间,通过某种规律在列表,元组或者字符串中进行截取,形成一个新的列表,元组或字符串
语法:列表[start🔚step]
start:开始索引,可以省略,默认为0,不省略的情况下包含在内
end:结束索引,可以省略,默认为最后一个【正数或负数】,不省略的情况下不包含在内
step:步长,可以省略,默认为10 1 2 3 4 5 6 7 8
-9 -8 -7 -6 -5 -4 -3 -2 -1注意:
a.只要切片的语法正确,哪怕获取不到元素,都不会报错
b.切片之后会得到一个新的列表,对原列表没有任何影响
10.append和extend的区别
append和extend都作为向列表中添加元素的功能,有什么区别和联系
相同点:
a.元素都会出现在列表的末尾
b.都可以添加单个或多个元素
c.都是在原列表的基础直接操作的
不同点:
a.append可以追加任意类型的数据,而extend只能添加可迭代对象
b.如果向列表中添加一个可迭代对象,append会将可迭代对象整体添加,而extend只会添加可迭代对象中的元素
11.列表拷贝
1.引用赋值 结论:列表使用引用赋值,两个列表指向同一份内存空间, 不管是几维列表,只要其中一个列表中的元素发生修改,则访问另一个列表,其中的元素会随着修改 2.浅拷贝 浅拷贝结论: 一维列表:会将拷贝的列表开辟一份新的内存空间,所以其中一个列表中的元素修改,对另一个列表没有影响 多维列表:本质是一个浅拷贝,只会拷贝最外层的地址,所以如果一个列表修改内层列表的元素,另一个列表会随着修改 3.深拷贝 深拷贝结论:两个列表指向不同的内存空间, 不管是几维列表,所有的内容都会被重新拷贝,其中一个列表中的元素发生修改,则访问另一个列表,没有任何影响
11.1列表拷贝面一
a = [1,2,3] b = [4,5] c = [a,b] d = c e = c.copy() a.append(6) print(c,d,e) """ c:[[1,2,3,6],[4,5]] d:[[1,2,3,6],[4,5]] e:[[1,2,3,6],[4,5]] """ a = [1,2,3] b = [4,5] c = [a,b] d = c e = c.copy() c.append(6) print(c,d,e) """ c:[[1,2,3],[4,5],6] d:[[1,2,3],[4,5],6] e:[[1,2,3],[4,5]] """
11.2列表拷贝面二
a = [1,2,['a','b']] b = a c = copy.deepcopy(a) a[-1].append(3) print(a,b,c) """ a:[1,2,['a','b',3]] b:[1,2,['a','b',3]] c:[1,2,['a','b']] """
11.3列表拷贝面三
a = [1,2,['a','b']] b = a c = copy.copy(a) a.append(3) print(a,b,c) """ a:[1,2,['a','b'],3] b:[1,2,['a','b'],3] c:[1,2,['a','b']] """
12.冒泡排序
排序思路:比较两个相邻的下标对应的元素,如果符合条件就交换位置
# 冒泡排序 # 以升序为例 list1 = [45,6,8,9,2,56,68,98,100,56,4,19] # 外层循环:控制比较的轮数 for i in range(len(list1) - 1): # 内层循环:控制的是每一轮比较的次数,兼顾参与比较的下标 for j in range(len(list1) - 1 - i): # 相邻两个元素比较大小 # 如果下标小的元素 > 下标大的元素,则交换位置 if list1[j] > list1[j + 1]: list1[j],list1[j + 1] = list1[j + 1],list1[j] print(list1) # 以降序为例 list1 = [45,6,8,9,2,56,68,98,100,56,4,19] # 外层循环:控制比较的轮数 for i in range(len(list1) - 1): # 内层循环:控制的是每一轮比较的次数,兼顾参与比较的下标 for j in range(len(list1) - 1 - i): # 相邻两个元素比较大小 # 如果下标小的元素 < 下标大的元素,则交换位置 if list1[j] < list1[j + 1]: list1[j],list1[j + 1] = list1[j + 1],list1[j] print(list1)
13.选择排序
排序思路:固定一个下标,然后拿这个下标对应的值依次和后面的元素进行比较,最值出现在头角标位置上
# 选择排序 # 以升序为例 list1 = [45,6,8,9,2,56,68,98,100,56,4,19] # 外层循环:控制比较的轮数 for i in range(len(list1) - 1): # 内层循环:控制的是每一轮比较的次数,兼顾参与比较的下标 for j in range(i + 1,len(list1)): # 相邻两个元素比较大小 # 如果下标小的元素 > 下标大的元素,则交换位置 if list1[i] > list1[j]: list1[i],list1[j] = list1[j],list1[i] print(list1) # 以降序为例 list1 = [45,6,8,9,2,56,68,98,100,56,4,19] # 外层循环:控制比较的轮数 for i in range(len(list1) - 1): # 内层循环:控制的是每一轮比较的次数,兼顾参与比较的下标 for j in range(i + 1,len(list1)): # 相邻两个元素比较大小 # 如果下标小的元素 < 下标大的元素,则交换位置 if list1[i] < list1[j]: list1[i],list1[j] = list1[j],list1[i] print(list1)
14.顺序查找
# 顺序查找:将待查找元素和列表中的每个元素进行依次的比对,如果相等,则表示查找成功 # 1. list1 = [34,6,7,7,8,7,45,76,8] key = 7 for i in range(len(list1)): if list1[i] == key: print(f"待查找元素{key},在列表中的索引为:{i}") print("*" *30) # 2.index() list1 = [34,6,7,7,8,7,45,76,8] key = 10 for i in range(len(list1)): if list1[i] == key: print(f"待查找元素{key},在列表中的索引为:{i}") break else: print(f"待查找元素{key}在列表中不存在")
15.二分法查找
查找思路:升序的前提下,将待查找的元素与中间下标对应的元素比较,如果大于中间下标对应的元素,则去右半部分查找
注意:前提是列表是有序(升序或者降序)的,通过折半来缩小查找范围,提高查找效率
# 以升序为例 list1 = [34,6,7,8,9,40,26,7,73,48,737] list1.sort() key = 7 left = 0 right = len(list1) - 1 while left <= right: # 计算中间下标 middle = (left + right) // 2 # 比较 if key > list1[middle]: # 后半部分:重置left的值 left = middle + 1 elif key < list1[middle]: # 前半部分:重置right的值 right = middle - 1 else: print(f"待查找元素{key}在列表中的下标为{middle}") # 查找到元素,则提前结束循环 break else: print(f"待查找元素{key}在列表中不存在") # 以降序为例 list1 = [34,6,7,8,9,40,26,7,73,48,737] list1.sort(reverse=True) key = 7 left = 0 right = len(list1) - 1 while left <= right: # 计算中间下标 middle = (left + right) // 2 # 比较 if key > list1[middle]: # 前半部分:重置right的值 right = middle - 1 elif key < list1[middle]: # 后半部分:重置left的值 left = middle + 1 else: print(f"待查找元素{key}在列表中的下标为{middle}") # 查找到元素,则提前结束循环 break else: print(f"待查找元素{key}在列表中不存在")
16.元组操作
# a t1 = (34,5,6,6,2,7,[1,2,3]) print(id(t1[-1])) t1[-1][0] = 100 print(t1) # (34, 5, 6, 6, 2, 7, [100, 2, 3]) print(id(t1[-1])) # b. # l1 = [3,5,6,7,7,(4,6,7)] # l1[-1][0] = 100 # print(l1) # 报错 # c.遍历 for ele in tuple3: print(ele) for i in range(len(tuple3)): print(i,tuple3[i]) for i,ele in enumerate(tuple3): print(i,ele)
17.列表和字典的区别
# 列表和字典的区别 格式:列表:[] 字典:{} 存储的数据:列表中可以存储任意类型的数据, 字典中存储的是键值对,其中键只能是不可变的数据类型,值可以是任意的类型 是否可变:列表是可变的,字典是可变的 是否有序:字典是有序的,Python3.7之前是无序的,3.7之后是有序的 是否可以存储重复数据:列表中可以存储重复数据,字典中的键是唯一的,值可以重复 使用的场景不同:列表常用与可以存储同类型的数据,字典常用于可以存储同一个对象的不同信息 或者 需要精确定位到某个数据
18.定义字典
使用不同的方式定义字典,至少两种
# 方式一 ****** info_dict = {"name":"张三","age":18,"hobby":"吹牛逼"} print(info_dict) # 方式二 ****** dict1 = {} dict1['aaa'] = 10 dict1['bbb'] = 20 print(dict1) # 方式三: # dict(key1=value1,key2=value2.....) dict2 = dict(x=10,y=20,z=30) print(dict2) # {'x': 10, 'y': 20, 'z': 30} # 问题:采用dict(key1=value1,key2=value2.....)方式,字典的key只能是字符串 # d1 = {10:1,20:2} # d2 = dict(10=1,20=2) # 方式四 # dict([(key1,value1),(key2,value2).....]) dict3 = dict([('a',11),('b',22),('c',33)]) print(dict3) dict3 = dict([(10,11),('b',22),('c',33)]) print(dict3) # 方式五: ******* # 映射 # dict(zip([key1,key2....],[value1,value2...])) dict4 = dict(zip(['name','age','score'],['jack',17,100])) print(dict4) dict4 = dict(zip(('name','age','score'),['jack',17,100])) print(dict4) dict4 = dict(zip(('name','age','score'),('jack',17,100))) print(dict4) dict4 = dict(zip(['name','age','score','height'],['jack',17,100])) print(dict4) dict4 = dict(zip(['name','age','score'],['jack',17,100,456,67,8])) print(dict4) # 注意:不管通过哪种方式定义字典,字典的key都不能是列表,字典,集合等可变的数据类型
19.简述列表,元组,字典,集合和字符串的区别
列表的本质:list,是一种有序的,可变的,可以存储重复元素的,可以存储不同类型的集合 元组的本质:tuple,是一种有序的,不可变的,可以存储重复元素的,可以存储不同类型的集合 字典的本质:dict,是一种有序的【Python3.7之后】,可变的,key不可以重复, 但是value可以重复,key只能是不可变的数据类型,vlue可以是任意的类型的集合 集合的本质:set,是一种无序的,可变的,不可以存储重复元素的,可以存储不同类型的集合 字符串的本质:str,是一种有序的,不可变的,可以存储重复字符的集合
20.编码、解码
编码:将字符串类型转换为字节类型,bytes()或encode() 解码:将字节类型转换为字符串类型,str()或decode() 字符串:'' "" 字节:b'' b"" 编码格式: utf-8 gbk # 1.编码 str1 = "3454hajgaj发哈哈%¥#@" # a.bytes() r1 = bytes(str1,encoding="utf-8") print(r1) print(type(r1)) # b.字符串.encode() r2 = str1.encode(encoding="gbk") print(r2) print(type(r2)) # 2.解码 # 注意:编解码采用的格式必须保持一致 # a.str() r3 = str(r1,encoding="utf-8") print(r3) print(type(r3)) # b.字节.decode() r4 = r2.decode(encoding="gbk") print(r4) print(type(r4)) # 扩展 # f = open(r"file1.txt","w",encoding="gbk") # f.write("你好hello") # f.close()
21.值传递和引用的区别
值传递:传参的时候,传递的是不可变的数据类型,如:int/float/bool/str/tuple等,当形参发生修改,实参没有影响 引用传递:传参的时候,传递的是可变的数据类型,如:list/dict.set等,当形参发生元素的修改,则实参会随着修改
22.什么是匿名函数,优缺点是什么
是一个lambda表达式,本质上还是一个函数,可以设置必需参数,默认参数,关键字参数和不定长参数 只不过表达式的执行结果就是函数的返回值 优点: 简化代码 减少内存空间的使用 缺点: 只能实现简单的逻辑,逻辑一旦复杂,如果使用,代码的可读性会降低,后期的维护性降低,则不建议使用
23.局部变量和全局变量
# a n = 9 def check(): n = 1 print(n) # 1 check() print(n) # 9 # b. # n = 9 # def check(): # n += 1 # n = n + 1 # check() # print(n) # UnboundLocalError: local variable 'n' referenced before assignment
24.简述global和nonlocal关键字的作用,并举例说明
24.1global
# 1. n = 9 def check(): n = 5 n += 1 # n = n + 1 print(n) # 6 check() print(n) # 9 # 2. # UnboundLocalError: local variable 'n' referenced before assignment n = 9 def check(): # global n,声明n变量来自于全局变量,则在函数中出现的n将不再是重新定义的新变量 global n n += 1 # n = n + 1 print(n) # 10 check() print(n) # 10
24.1nonlocal
# 说明:nonlocal一般应用在闭包中,跟局部作用域有关 # 1. x = 1 def outter(): x = 2 def inner(): x = 3 # 定义了一个新的变量 print("inner",x) inner() print("outter",x) outter() print('global',x) """ inner 3 outter 2 global 1 """ # 2. x = 1 def outter(): x = 2 def inner(): # nonlocal x,声明x不是局部变量,而是来自于函数作用域的变量 nonlocal x x = 3 # 表示重新赋值 print("inner",x) inner() print("outter",x) outter() print('global',x) """ inner 3 outter 3 global 1 """
25.简述可迭代对象和迭代器之间的区别和联系
区别: 可迭代对象:Iterable,可以直接作用于for循环的对象【可以使用for循环遍历其中元素的对象】, 如:list,tuple,dict,set,str,range(),生成器等 迭代器:Iterator,可以直接作用于for循环,或者可以通过next()获取下一个元素的对象, 如:生成器 联系: 迭代器一定是可迭代对象,可迭代对象不一定是迭代器 但是,可以通过系统功能iter()将不是迭代器的可迭代对象转换为迭代器
26.分别解释什么是列表推导式,字典推导式,集合推导式,生成器,可迭代对象,迭代器
迭代器和生成器都是容器对象。它们之间的关系是,生成器是一种特殊的迭代器。(生成器一定是迭代器,但迭代器不一定是生成器)。所以,我们从迭代器入手。迭代器: python中只要实现了迭代协议的容器,都是迭代器。python的迭代协议,基于两个方法: - next() 返回迭代容器中的下一个 - __iter__() 返回迭代器本身 生成器: 生成器是一种特殊的迭代器,所以也是有迭代器的特征的。next()和iter()方法。不同的是next()返回的是yield指令返回的值,iter()方法,返回的是一个生成器对象。
27.说明sort()和sorted()之间的区别和联系
相同点: a.二者都是用来排序的 b.默认的情况下,二者都是升序,如果要降序,都是设置reverse=True c.如果要自定义排序规则,二者都是设置key,key的值都得是一个函数 不同点: a.调用方式不同:列表.sort() , sorted(列表) b.sort是在原列表内部排序的,sorted是生成了一个新的列表
28.书写一个装饰器,可以统计任意一个函数的执行时间
def wrapper(func): def get_time(): # 开始时间戳 start = time.time() func() # 结束时间 end = time.time() return round(end - start,5) return get_time @wrapper def test(): for i in range(100000): pass print(test())
29.书写一个装饰器,可以统计任意一个函数的执行时间
import time def wrapper(func): def get_time(*args,**kwargs): # 开始时间戳 start = time.time() func(*args,**kwargs) # 结束时间 end = time.time() return round(end - start,5) return get_time @wrapper
30.@xxx被称为无参装饰器,@xxxx(value)有参的装饰器
def outter(a): def inner(b): pass return inner @outter(value) def func(): pass 工作原理: a.自动调用装饰器的内外部函数 b.将装饰器的参数value传参给外部函数的参数a,将被修饰的函数传参给内部函数的参数b c.原函数的函数名指向内部函数的返回值
31.自定义模块的优点
- 提高代码的可维护性 - 提高了代码的复用度,当一个模块书写完毕,可以被多个地方引用 - 引用其他的模块 - 避免函数名和变量名的命名冲突
32.面向过程和面向对象的区别
面向过程 在生活案例中: 一种看待问题的思维方式,在思考问题的时候,着眼于问题是怎样一步一步解决的,然后亲力亲为的去解决问题 在程序中: 代码从上而下顺序执行 各模块之间的关系尽可能简单,在功能上相对独立 每一模块内部均是由顺序、选择和循环三种基本结构组成 其模块化实现的具体方法是使用子程序 程序流程在写程序时就已决定 面向对象 在生活案例中: 也是一种看待问题的思维方式,着眼于找到一个具有特殊功能的具体个体,然后委托这个个体去做某件事情,我们把这个个体就叫做对象,一切皆对象 是一种更符合人类思考习惯的思想【懒人思想】,可以将复杂的事情简单化,将程序员从执行者转换成了指挥者 在程序中: 把数据及对数据的操作方法放在一起,作为一个相互依存的整体——对象 1》对同类对象抽象出其共性,形成类 2》类中的大多数数据,只能用本类的方法进行处理 3》类通过一个简单的外部接口与外界发生关系,对象与对象之间通过消息进行通信 4》程序流程由用户在使用中决定 5》使用面向对象进行开发,先要去找具有所需功能的对象,如果该对象不存在,那么创建一个具有该功能的对象 注意:面向对象只是一种思想,并不是一门编程语言,也不会绑定编程语言 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个一次调用就可以了 面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事物在整个解决问题的步骤中的行为
33.面向过程和面向对象的优缺点
面向过程: 优点:性能比面向对象高,开销比较大,比较消耗资源,比如单片机、嵌入式开发等一般采用面向过程开发,因为性能是最重要的因素 缺点:没有面向对象易维护,易复用,易扩展 面向对象: 优点:易维护,易复用,易扩展,由于面向对象有封装,继承,多态的特性,可以设计出低耦合的系统,使得系统更加灵活,更加易于维护 缺点:性能比面向过程低 Python是一门面向的语言,面向对象语言的特点:封装,继承和多态 狗吃屎:面向对象 吃狗屎:面向过程
34.简述实例属性【对象属性】和类属性之间的区别
a.定义的位置不同:类属性直接定义在类中,实例属性可以通过动态绑定 或者 定义在构造函数中 b.访问的方式不同:类属性可以通过对象或类名访问,而实例属性只能通过对象访问 c.优先级不同:在类属性和实例属性重名的情况下,使用对象访问,优先访问的是实例属性 d.在内存中出现的时机不同:类属性优先于实例属性出现在内存中,类属性随着类的加载而出现,实例属性随着对象的出现而出现 e.使用场景不同:类属性适用于多个对象共享的数据,实例属性适用于每个对象特有的数据
35.普通实例函数和__init__之间的区别和联系
不同点: a.函数名不同:实例函数的函数名需要自定义,但是,__init__是固定的,是系统的函数 b.调用不同:实例函数需要手动调用,__init__是在创建对象的过程中自动调用的 c.调用的次数不同:对于同一个对象而言,实例函数可以被调用无数次,__init__只会被调用一次 相同点: a.定义在类中,本质上都是实例函数,形参列表的第一个参数都是self b.默认参数,关键字参数,不定长参数都可以使用 c.也可以设置返回值
36.析构函数的调用时机
使用场景:一般用于程序的清理行为,如:关闭文件,关闭数据库等
37.阅读下面的代码,写出执行结果
class Person(): @property def show(self): return 10 p = Person() p.show() # 报错,被@property修饰的函数会被当做属性使用,则p.show的值为show函数的返回值 # 修改方式:p.show()--->r = p.show
38.解释下面不同形式的变量出现在类中的意义
a:普通属性,在类的外面可以直接访问 _a:在类的外面可以直接访问,但是不建议使用,容易和私有化属性混淆 __a:私有属性,只能在类的内部被直接访问,类的外面可以通过暴露给外界的函数访问 __a__:在类的外面可以直接访问,但是不建议使用,因为系统的属性和魔术方法都是这种形式的命名, 如:__slots__,__init__.__del__,__new__,__add__,__sub__,__mul__,__gt__,__lt__,__eq__,__ne__,__str__等
39.继承注意小题
class MyClass(object): x = 10 class SubClass1(MyClass): pass class SubClass2(MyClass): pass print(MyClass.x,SubClass1.x,SubClass2.x) # 10 10 10 SubClass1.x = 20 print(MyClass.x,SubClass1.x,SubClass2.x) # 10 20 10 MyClass.x = 30 print(MyClass.x,SubClass1.x,SubClass2.x) # 30 20 30
40.简述类中的实例函数,静态函数和类函数之间的区别
a.定义不同:被@classmethod修饰的函数表示类函数,被@staticmethod修饰的函数表示静态函数,实例函数没有装饰器 b.形参列表不同:实例函数的第一个参数是self,表示当前对象,类函数的第一个参数是cls,表示当前类,静态函数的参数没有要求 c.调用方式不同:类函数和静态函数都可以通过类名或者对象调用,但是,实例函数只能通过对象调用 d.使用场景不同:如果要封装一个工具类,则尽量使用类函数或静态函数,在实际项目开发中,常用实例函数
41.下面哪些打开文件的方式,可以自动创建一个新的文件
a.open('f1.txt','w',encoding='utf-8') b.open('f1.txt','wb',encoding='utf-8') c.open('f1.txt','w+',encoding='utf-8') d.open('f1.txt','a',encoding='utf-8') e.open('f1.txt','r',encoding='utf-8') #abcd
42.什么是单例设计模式?
程序运行过程中,确保某一个类只有一个实例【对象】,不管在哪个模块获取这个类的对象,获取到的都是同一个对象。该类有一个静态方法,向整个工程提供这个实例,例如:一个国家只有一个主席,不管他在哪 单例设计模式的核心:一个类有且仅有一个实例,并且这个实例需要应用于整个程序中,该类被称为单例类
50 执行with上下文的时候,底层的工作原理
with上下文的工作原理
"""
语法:
with 对象 as 变量名
处理事务
"""
class Person(object):
# 进入
def __enter__(self):
print("进入with上下文管理")
return self
# 退出
def __exit__(self, exc_type, exc_val, exc_tb):
print("退出with上下文管理")
with Person() as p1:
print("处理事务")
51 列出常见的异常并说明出现异常的原因,至少5个
# 【面试题】列出常见的异常并说明出现异常的原因,至少5个
# 1.NameError:使用了一个未定义的变量
# print(num) # NameError: name 'num' is not defined
# 2.ValueError:进行数据转换的时候,类型不匹配
# n = int(input("number:")) # ValueError: invalid literal for int() with base 10: 'gakgjak'
# 3.KeyError:当访问了不存在的key
# dict1 = {'a':10}
# print(dict1['b']) # KeyError: 'b'
# 4.AttributeError:当一个对象访问了不存在的属性或函数
class Person():
pass
p = Person()
# print(p.name) # AttributeError: 'Person' object has no attribute 'name'
# [24,456].appends(45) # AttributeError: 'list' object has no attribute 'appends'
# 5.IndexError:使用索引访问列表,字符串,元组的时候,索引越界
# 6.UnboundLocalError:当不同作用域的变量重名的情况下,访问了不属于当前作用域的变量
a = 10
def test():
global a
a += 1 # UnboundLocalError: local variable 'a' referenced before assignment
test()
print(a)
def outter():
a = 10
def inner():
nonlocal a
if a > 3: # UnboundLocalError: local variable 'a' referenced before assignment
a = 34
inner()
outter()
# 7.IndentationError
# if 1:
# num = 10 # IndentationError: unindent does not match any outer indentation level
# print(45)
# 8.FileNotFoundError:文件路径不存在
# open('file1.txt','r',encoding="utf-8") # FileNotFoundError: [Errno 2] No such file or directory: 'file1.txt'
# 9.ModuleNotFoundError:模块路径错误
# 10.TypeError:类型不匹配
# 11.KeyboardInterruptError
52 根据实际使用情况,给下面代码处理可能存在的异常
f = None
try:
f = open(r"file1.txt", 'r', encoding="utf-8")
f.read()
except FileNotFoundError as e:
print(e)
except LookupError as e:
print(e)
except ValueError as e:
print(e)
except UnicodeDecodeError as e:
print(e)
finally:
if f:
f.close()
# FileNotFoundError
# LookupError
# ValueError
# UnicodeDecodeError
53 自定义异常
# 1.自定义一个类,继承自Exception/BaseException
class MyException(Exception):
# 2.定义构造函数,调用父类的构造函数,并定义一个实例属性,表示异常的描述信息
def __init__(self,message):
super().__init__()
self.message = message
# 3.重写__str__,返回异常的描述信息字符串
def __str__(self):
return self.message
# 4.定义一个实例函数,用于处理出现的异常
def handle(self):
print("处理了异常~~~~")
try:
raise MyException("出现了错误")
except MyException as e:
print(e)
e.handle()
# 注意:如果要解决生活中的问题,则可以通过自定义异常处理
# 练习:
# 需求:自定义一个异常,表示上班迟到的异常,如果8点之前起床,上班不会迟到,如果8点之后起床的,上班会迟到
class LateException(Exception):
__slots__ = ("message",)
def __init__(self,message):
super().__init__()
self.message = message
def __str__(self):
return self.message
def handle(self):
print("延迟下班时间")
time = float(input("请输入起床的时间:"))
if time > 8:
# 出现异常
try:
raise LateException("闹铃响了没听见~~~~~~")
except LateException as e:
print("迟到的原因:",e)
e.handle()
else:
print("早早到达公司,开始搬砖~~~")
54 写出下面代码执行的结果
# 注意:不管什么情况下,finally永远都会执行,哪怕在函数中,try或except代码块中书写了return
# a.
# def test():
# try:
# list1 = [34, 5, 6]
# index = int(input("请输入列表的索引:")) # 1
# num = list1[index]
# print(f"获取的元素为:{num}")
# return
# except IndexError as e:
# print("IndexError", e)
# return
# except ValueError as e:
# print("ValueError:", e)
# finally:
# print("finally语句被执行了~~~~")
# test()
# b.
# def test():
# list1 = [34, 5, 6]
# index = int(input("请输入列表的索引:")) # 1
# num = list1[index]
# print(f"获取的元素为:{num}")
#
# try:
# test()
# except IndexError as e:
# print("IndexError", e)
# except ValueError as e:
# print("ValueError:", e)
# finally:
# print("finally语句被执行了~~~~")
55 match,search和findall之间的区别
r1 = re.match(r"\d+","abc2abc2")
print(r1)
r1 = re.search(r"\d+","abc2abc2")
print(r1)
r1 = re.findall(r"\d+","abc2abc2")
print(r1)
56 进程和线程之间的关系
a.一个程序启动之后,会启动一个进程
b.一个进程启动之后,可能会启动多个线程,但是至少需要有一个线程,否则这个进程是没有意义的
c.多个进程间不能共享资源,但多个线程之间资源共享的
d.系统创建进程需要为该进程重新分配系统资源,而创建线程则容易的多,因此使用多线程比使用多进程效率更高
57 如何自定义进程
from multiprocessing import Process
from time import sleep
# 【面试题】如何自定义进程
# 通过类的特点将进程进行封装,在使用的时候,只需要调用即可
# a.定义一个类,继承自Process
class MyProcess(Process):
# b.书写构造函数,调用父类的构造函数,并定义进程的名称
def __init__(self,name):
Process.__init__(self)
self.name = name
# c.定义进程处理任务的函数,命名为run,实际表示重写父类中的run函数
# 注意:如果要自定义进程的子类,则必须在子类中重写run函数
def run(self):
# 子进程需要处理的任务的逻辑代码
print("子进程启动")
sleep(1)
print("子进程结束~~~~~")
if __name__ == '__main__':
p = MyProcess("进程11")
p.start() # 调用start函数,自动调用run函数
58 定时线程
import threading
# 【面试题】
def run():
print("hello~~~~~")
if __name__ == '__main__':
print("主线程启动")
# Timer(seds,target)
t = threading.Timer(5,run)
t.start()
t.join()
print("主线程结束")
59 关于python序列化相关的模块
# 关于python序列化相关的模块
- joblib:
- dump(obj,filename)直接将python对象转换为字节数据存储到文件中(序列化),
- load(filename)将对象的字节数据从文件中加载(反序列化)
- pickle:针对任何对象
- dumps(obj)-->bytes
- dump(obj,filename) bytes写入到文件中
- loads("b")-->obj 从bytes反序列化为object对象
- load(filename) 从文件中加载bytes并反序列化为object对象
- json:json格式的字符串
- dumps(list|dict)-->str
- dump(list|dict,filename)
- loads(str)-->list|dict
- load(filename)-->list|dict
60 华为面试题
解密犯罪时间 | 时间限制:1秒 | 内存限制:262144K | 语言限制:不限
警察在侦破一个案件时,得到了线人给出的可能犯罪时间,形如 “HH:MM” 表示的时刻。
根据警察和线人的约定,为了隐蔽,该时间是修改过的,解密规则为:利用当前出现过的数字,构造下一个距离当前时间最近的时刻,则该时间为可能的犯罪时间。每个出现数字都可以被无限次使用。"
"输入描述: 形如HH:SS的字符串,表示原始输入
输出描述: 形如HH:SS的字符串,表示推理出来的犯罪时间
示例1 输入 18:52 输出 18:55 说明 利用数字1, 8, 5, 2构造出来的最近时刻是18:55,是3分钟之后。结果不是18:51因为这个时刻是18小时52分钟之后。 示例2 输入 23:59 输出 22:22 说明 利用数字2, 3, 5, 9构造出来的最近时刻是22:22。 答案一定是第二天的某一时刻,所以选择可构造的最小时刻为犯罪时间。 备注:
可以保证线人给定的字符串一定是合法的。例如,“01:35” 和 “11:08” 是合法的,“1:35” 和 “11:8” 是不合法的。最近的时刻有可能在第二天
def decrypt_crime_time(s):
nums_list = [int(i) for i in s if i != ":"]
H, M = [int(i) for i in s.split(":")]
nums_list = list({i * 10 + j for i in nums_list for j in nums_list if i <= 5})
nums_list.sort()
if H in nums_list and H != 23:
for i in nums_list:
if i <= M:
continue
return ":".join([str(H), str(i)])
else:
return ":".join([str(nums_list[0]), str(nums_list[0])])
s = "20:12"
print(decrypt_crime_time(s))
s = "23:59"
print(decrypt_crime_time(s))
61 关系型数据库有哪些对象
关系型数据库一般都支持约束、索引、视图、函数、存储过程、触发器、表、字典(动态视图)等对象。其中相对来说表是最重要的。
62 在数据库中一个表中可以创建多少个索引
创建索引的个数不受限制,但是一般会根据需要创建索引。
63索引分类和索引类型
【索引分类】:主键索引,唯一索引,普通索引,组合索引
【索引类型】:BTREE、HASH
64 事务的四个特性:(ACID)
事务具有四个特性:(ACID)
- ( Atomicity )原子性:事务中的操作要么全执行,要么全失败
- (Consistency) 一致性:事务操作的前后,数据保持一致
- (Isolation) 隔离性:事务之间互补影响,具有四个级别
- 读未提交(Read Uncommitted):可以读取未提交的记录。
- 读已提交(Read Committed):事务中只能看到已提交的修改。
- 可重复读(Repeatable Read):解决了不可重复读问题(MySQL 默认隔离级别)
- 序列化(Serializable):最高隔离级别。
- (Durability) 持久性:事务提交后数据将会保存,即使系统奔溃了也不会影响数据
65八进制转换为十进制
int(0o12) ----->10
66 哪些对象可以作为字典的key
可以hash的都可以作为key,
67 HTTP协议不同版本的区别
什么是HTTP协议?
HTTP协议全称HyperText Transfer Protocol,中文名超文本传输协议。是互联网上应用最为广泛的一种网络协议。HTTP是基于TCP/IP协议的应用层协议,不涉及数据包的传输,主要是规定了客户端和服务器之间的通信格式。默认使用80端口。现在HTTP已经演化出了很多个版本。
HTTP/0.9
HTTP 0.9是最早发现的一个版本,在1991年发布,只接受GET一种请求方法,并且不支持请求头。只支持纯文本一种内容,服务器只能回应HTML格式的字符串,里边不能插入图片。HTTP 0.9具有典型的无状态性,每个事务独立进行处理,事务结束时就释放这个连接。由此可见,HTTP协议的无状态特点在其第一个版本0.9中已经成型。
GET /index.html
HTTP/1.0
1) HTTP 1.0是HTTP协议的第二个版本在1996年发布,如今仍然被广泛使用,尤其是在代理服务器中。
2) 1.0版本不仅仅支持GET命令还有POST和HEAD等请求方法。
3) HTTP的请求和回应格式也发生了变化,除了要传输的数据之外,每次通信都包含头信息,用来描述一些信息。
4) 不再局限于0.9版本的HTML格式,根据Content-Type可以支持多种数据格式,这使得互联网不仅仅可以用来传输文字,还可以传输图像、音频、视频等二进制文件。
5) 同时也开始支持cache,就是当客户端在规定时间内访问统一网站,直接访问cache即可。
6) 除了数据部分,每次通信都必须包括头信息(HTTP header)。
7) 其他的新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
8) 但是1.0版本的工作方式是每次TCP连接只能发送一个请求,当服务器响应后就会关闭这次连接,下一个请求需要再次建立TCP连接,就是不支持 keep-alive。 TCP连接的建立成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)。所以,HTTP 1.0版本的性能比较差。随着网页加载的外部资源越来越多,这个问题就愈发突出了。为了解决这个问题,有些浏览器在请求时,用了一个非标准的Connection字段。
HTTP/1.1
1) 最大变化,就是引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。不过,规范的做法是,客户端在最后一个请求时,发送Connection: close,明确要求服务器关闭TCP连接。
2) 加入了管道机制,在同一个TCP连接里,允许多个请求同时发送,增加了并发性,进一步改善了HTTP协议的效率。举例来说,客户端需要请求两个资源。以前的做法是,在同一个TCP连接里面,先发送A请求,然后等待服务器做出回应,收到后再发出B请求。管道机制则是允许浏览器同时发出A请求和B请求,但是服务器还是按照顺序,先回应A请求,完成后再回应B请求。
3) 一个TCP连接现在可以传送多个回应,势必就要有一种机制,区分数据包是属于哪一个回应的。这就是Content-length字段的作用,声明本次回应的数据长度。
4) 分块传输编码,使用Content-Length字段的前提条件是,服务器发送回应之前,必须知道回应的数据长度。对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)。因此,1.1版规定可以不使用Content-Length字段,而使用"分块传输编码"(chunked transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。
5) 新增了请求方式PUT、PATCH、OPTIONS、DELETE等。
6) 客户端请求的头信息新增了Host字段,用来指定服务器的域名。
7) HTTP/1.1支持文件断点续传,RANGE:bytes,HTTP/1.0每次传送文件都是从文件头开始,即0字节处开始。RANGE:bytes=XXXX表示要求服务器从文件XXXX字节处开始传送,断点续传。即返回码是206(Partial Content)
HTTP/2.0
1)二进制协议: HTTP/1.1 版的头信息肯定是文本(ASCII编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧"(frame):头信息帧和数据帧。
2)多工: HTTP/2 复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应,这样就避免了"队头堵塞"(HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级)。
举例来说,在一个TCP连接里面,服务器同时收到了A请求和B请求,于是先回应A请求,结果发现处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。
3)头信息压缩: HTTP 协议不带有状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如Cookie和User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。
HTTP/2 对这一点做了优化,引入了头信息压缩机制(header compression)。一方面,头信息使用gzip或compress压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
4)服务器推送: HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
意思是说,当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。
服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
总结
HTTP/0.9:功能捡漏,只支持GET方法,只能发送HTML格式字符串。
HTTP/1.0:支持多种数据格式,增加POST、HEAD等方法,增加头信息,每次只能发送一个请求(无持久连接)
HTTP/1.1:默认持久连接、请求管道化、增加缓存处理、增加Host字段、支持断点传输分块传输等。
HTTP/2.0:二进制分帧、多路复用、头部压缩、服务器推送
68 正则表达式的中文范围
u4e00-uf9fa5
69 关于put和patch的区别
patch:更新部分资源,非幂等,非安全
put:更新整个资源,具有幂等性,非安全
注意:
幂等性:多次请求的结果和请求一次的结果一样
安全性:请求不改变资源的状态
70 session 和 cookie的区别
- 作用范围不同,Cookie 保存在客户端(浏览器),Session 保存在服务器端。
- 存取方式的不同,Cookie 只能保存 ASCII,Session 可以存任意数据类型,一般情况下我们可以在 Session 中保持一些常用变量信息,比如说 UserId 等。
- 有效期不同,Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭或者 Session 超时都会失效。
- 隐私策略不同,Cookie 存储在客户端,比较容易遭到不法获取,早期有人将用户的登录名和密码存储在 Cookie 中导致信息被窃取;Session 存储在服务端,安全性相对 Cookie 要好一些。
- 存储大小不同, 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie
71 html 和 xml的区别
一、HTML
HTML(HyperTextMark-upLanguage)即超文本标记语言,是WWW的描述语言。
二、XML
XML即ExtentsibleMarkup Language(可扩展标记语言),是用来定义其它语言的一种元语言,其前身是SGML(标准通用标记语言)。它没有标签集(tagset),也没有语法规则(grammatical rule),但 是它有句法规则(syntax rule)。任何XML文档对任何类型的应用以及正确的解析都必须是良构的(well-formed),即每一个打开的标签都必须有匹配的结束标签,不得含有次序颠倒的标签,并且在语句构成上应符合技术规范的要求。XML文档可以是有效的(valid),但并非一定要求有效。所谓有效文档是指其符合其文档类型定义(DTD)的文档。如果一个文档符合一个模式(schema)的规定,那么这个文档是模式有效的(schema valid)。
三、HTML与XML的区别
通过以上对HTML及XML的了解,我们来看看他们之间到底存在着什么区别与联系
xml和html都是用于操作数据或数据结构,在结构上大致是相同的,但它们在本质上却存在着明显的区别。综合网上的各种资料总结如下。
(一)、语法要求不同:
1. 在html中不区分大小写,在xml中严格区分。
2. 在HTML中,有时不严格,如果上下文清楚地显示出段落或者列表键在何处结尾,那么你可以省略</p>或者</li>之类的结束标记。在XML中,是严格的树状结构,绝对不能省略掉结束标记。
3. 在XML中,拥有单个标记而没有匹配的结束标记的元素必须用一个/ 字符作为结尾。这样分析器就知道不用查找结束标记了。
4. 在XML中,属性值必须分装在引号中。在HTML中,引号是可用可不用的。
5. 在HTML中,可以拥有不带值的属性名。在XML中,所有的属性都必须带有相应的值。
6. 在XML文档中,空白部分不会被解析器自动删除;但是html是过滤掉空格的。
(二)、标记不同:
1、html使用固有的标记;而xml没有固有的标记。
2、Html标签是预定义的;XML标签是免费的、自定义的、可扩展的。
(三)、作用不同:
1. html是用来显示数据的;xml是用来描述数据、存放数据的,所以可以作为持久化的介质!Html将数据和显示结合在一起,在页面中把这数据显示出来;xml
则将数据和显示分开。 XML被设计用来描述数据,其焦点是数据的内容。HTML被设计用来显示数据,其焦点是数据的外观。
2. xml不是HTML的替代品,xml和html是两种不同用途的语言。 XML 不是要替换 HTML;实际上XML 可以视作对 HTML 的补充。XML 和HTML 的目标不同HTML 的设计目标是显示数据并集中于数据外观,而XML的设计目标是描述数据并集中于数据的内容。
3. 没有任何行为的XML。与HTML 相似,XML 不进行任何操作。(共同点)
4. 对于XML最好的形容可能是: XML是一种跨平台的,与软、硬件无关的,处理与传输信息的工具。
5. XML未来将会无所不在。XML将成为最普遍的数据处理和数据传输的工具。
72 数组和列表的区别
1. 列表list与数组array的定义:
列表是由一系列按特定顺序排列的元素组成,可以将任何东西加入列表中,其中的元素之间没有任何关系;
Python中的列表(list)用于顺序存储结构。它可以方便、高效的的添加删除元素,并且列表中的元素可以是多种类型。
数组也就是一个同一类型的数据的有限集合。
2. 列表list与数组array的相同点:
a. 都可以根据索引来取其中的元素;
3. 列表list与数组array的不同点:
a.列表list中的元素的数据类型可以不一样。数组array里的元素的数据类型必须一样;
b.列表list不可以进行数学四则运算,数组array可以进行数学四则运算;
c.相对于array,列表会使用更多的存储空间。
73 垃圾回收机制
垃圾回收机制,Python 采用 GC 作为自动内存管理机制,GC要做的有2件事,一是找到内存中无用的垃圾对象资源,二是清除找到的这些垃圾对象,释放内存给其他对象使用。
如何实现上述2点了,Python 采用了 引用计数 为主, 标志清除和分代回收 为辅测策略。
2.1 引用计数
查看源码,每一个对象,在源码里就是一个结构体表示,都会有一个计数字段.
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少。
一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。
此算法的优点和缺点都是非常明显的:
优点:
简单
实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。
缺点:
需要额外的空间维护引用计数。
不能解决对象的循环引用。(主要缺点)
接下来说一下什么是循环引用:
A和B相互引用而且没有外部引用A与B中的任何一个。也就是对象之间互相应用,导致引用链形成一个环。
>>>>>>a = { } #对象A的引用计数为 1
>>>b = { } #对象B的引用计数为 1
>>>a['b'] = b #B的引用计数增1
>>>b['a'] = a #A的引用计数增1
>>>del a #A的引用减 1,最后A对象的引用为 1
>>>del b #B的引用减 1, 最后B对象的引用为 1
执行 del 后,A、B对象已经没有任何引用指向这两个对象,但是这两个对象各包含一个对方对象的引用,虽然最后两个对象都无法通过其它变量来引用这两个对象了,这对GC来说就是两个非活动对象或者说是垃圾对象。理论上是需要被回收的。
按上面的引用计数原理,要计数为0才会回收,但是他们的引用计数并没有减少到零。因此如果是使用引用计数法来管理这两对象的话,他们并不会被回收,它会一直驻留在内存中,就会造成了内存泄漏(内存空间在使用完毕后未释放)。
为了解决对象的循环引用问题,Python 引入了标记清除和分代回收两种GC机制。
2.2 标记清除
标记清除主要是解决循环引用问题。
标记清除算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。
它分为两个阶段:第一阶段是标记阶段,GC会把所有的 活动对象 打上标记,第二阶段是把那些没有标记的对象 非活动对象 进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为 Python 的辅助垃圾收集技术主要处理的是容器对象(container,上面讲迭代器有提到概念),比如list、dict、tuple等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。
Python 这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
2.3 分代回收
分代回收是一种以空间换时间的操作方式。
Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。
分代回收同样作为Python的辅助垃圾收集技术处理容器对象
74 乐观锁和悲观锁
悲观锁(Pessimistic Lock)
1️⃣理解
当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制【Pessimistic Concurrency Control,缩写“PCC”,又名“悲观锁”】。
悲观锁,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
之所以叫做悲观锁,是因为这是一种对数据的修改持有悲观态度的并发控制方式。总是假设最坏的情况,每次读取数据的时候都默认其他线程会更改数据,因此需要进行加锁操作,当其他线程想要访问数据时,都需要阻塞挂起。悲观锁的实现:
传统的关系型数据库使用这种锁机制,比如行锁、表锁、读锁、写锁等,都是在操作之前先上锁。
Java 里面的同步 synchronized 关键字的实现。
2️⃣悲观锁主要分为共享锁和排他锁:
共享锁【shared locks】又称为读锁,简称 S 锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
排他锁【exclusive locks】又称为写锁,简称 X 锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁。获取排他锁的事务可以对数据行读取和修改。
3️⃣说明
悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会。另外还会降低并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数据。
三、乐观锁(Optimistic Locking)
1️⃣理解
乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量。
乐观锁采取了更加宽松的加锁机制。也是为了避免数据库幻读、业务处理时间过长等原因引起数据处理错误的一种机制,但乐观锁不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。乐观锁的实现:
CAS 实现:Java 中java.util.concurrent.atomic包下面的原子变量使用了乐观锁的一种 CAS 实现方式。
版本号控制:一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会 +1。当线程 A 要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值与当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
2️⃣说明
乐观并发控制相信事务之间的数据竞争(data race)的概率是比较小的,因此尽可能直接做下去,直到提交的时候才去锁定,所以不会产生任何锁和死锁。
四、具体实现
1️⃣悲观锁实现方式
悲观锁的实现,往往依靠数据库提供的锁机制。在数据库中,悲观锁的流程如下:
在对记录进行修改前,先尝试为该记录加上排他锁(exclusive locks)。
如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。具体响应方式由开发者根据实际需要决定。
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
期间如果有其他对该记录做修改或加排他锁的操作,都会等待解锁或直接抛出异常。
以 MySql Innodb 引擎举例,说明 SQL 中悲观锁的应用
要使用悲观锁,必须关闭 MySQL 数据库的自动提交属性set autocommit=0。因为 MySQL 默认使用 autocommit 模式,也就是说,当执行一个更新操作后,MySQL 会立刻将结果进行提交。
以电商下单扣减库存的过程说明一下悲观锁的使用:
在对 id = 1 的记录修改前,先通过 for update 的方式进行加锁,然后再进行修改。这就是比较典型的悲观锁策略。
如果发生并发,同一时间只有一个线程可以开启事务并获得 id=1 的锁,其它的事务必须等本次事务提交之后才能执行。这样可以保证当前的数据不会被其它事务修改。
使用 select…for update 锁数据,需要注意锁的级别,MySQL InnoDB 默认行级锁。行级锁都是基于索引的,如果一条 SQL 语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
2️⃣乐观锁实现方式乐观锁不需要借助数据库的锁机制
主要就是两个步骤:冲突检测和数据更新。比较典型的就是 CAS (Compare and Swap)。
CAS 即比较并交换。是解决多线程并行情况下使用锁造成性能损耗的一种机制,CAS 操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值(V)与预期原值(A)相匹配,那么处理器会自动将该位置值更新为新值(B)。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。CAS 有效地说明了“我认为位置(V)应该包含值(A)。如果包含该值,则将新值(B)放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可”。Java 中,sun.misc.Unsafe 类提供了硬件级别的原子操作来实现这个 CAS。java.util.concurrent包下大量的类都使用了这个 Unsafe.java 类的 CAS 操作。
当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。比如前面的扣减库存问题,通过乐观锁可以实现如下:
乐观锁使用
在更新之前,先查询一下库存表中当前库存数(quantity),然后在做 update 的时候,以库存数作为一个修改条件。当提交更新的时候,判断数据库表对应记录的当前库存数与第一次取出来的库存数进行比对,如果数据库表当前库存数与第一次取出来的库存数相等,则予以更新,否则认为是过期数据。
75 html和xml的区别
- html是网页标签的标准或规范, 主要用于将标签的内容以不同的形式渲染到浏览器中.
- xml是一种数据格式,主要用于不同程序之间的数值交互。
<users>
<user id="10001">
<name>disen</name>
<loves>
<val>Music</val>
<val>Play</val>
</loves>
</user>
</users>
76 sys和os两个模块的区别
- sys是Python解析器内部的模块
- 添加代码的root目录 sys.path.insert(0, '')
- 查看python的版本,sys.version/platform
- 获取命令行参数 sys.argv
- 捕获全局的异常处理函数 sys.excepthook
- os是python程序针对操作系统的模块
- 文件与目录操作
- 环境变量的操作 os.environ
- 创建子进程(操作系统命令)os.system(), os.popen()
77 协程的三种方式
异步的
轮询方式 select, 主动去做的
回调方式 poll 被动的
增强式回调方式 epoll
78 pymysql的connect()方法的常用参数
-host
-port
-user
-passwd
-db
-charset
-cursor
-autocommit: False
79 写出pymsql的Cursor对象的方法与属性
-execute(sql, args)
args是tuple或list时,填充SQL语句中的%s占位符
args是dict时,填充SQL语句的%(name)s占位符
-fetchall()
-fetone()
-rowcount
-callproc(name, args) 调用存储过程(procedure)
-close
80 简述哪些对象可以使用with关键字
- stream文件流对象
- Condition 线程的条件变量对象
- Lock线程锁对象
- Connection数据库连接类cursor的对象
- 实现__enter__和__exit__两种方法的类对象
81 re正则的compile、match、search、findall的区别
- compile(pattern, flags) 创建正则对象,可以重复或多次使用。正则实例对象可以调用其他三个方法。
- match(pattern, string, flags=0) 匹配内容中正则部分,如果未匹配成功,返回None,匹配成功返回match对象。一般用于验证数据场景(手机号,身份证,邮箱)。
- search(pattern, string, pos=0, flags=0) 同match相似,返回第一次匹配正则是内容,未匹配成功返回None。匹配成功之后,可以通过match对象的group获取匹配的内容。
- findall(pattern, string, flags=0) 匹配所有的符合正则表达式的内容。
82 查看端口号的占用情况的命令
首先要检查是不是有net-tools工具
没有的话安装 yum -y install net-tools
netstat -ltpn | grep <端口号>
83 WSGI、uWSGI和uwsgi的区别
WSGI,全称Web Server Gateway Interface,是为Python语言定义的Web服务器和Web应用程序或框架之间的一种简单而通用的接口 。描述的是Web服务器如何与Web应用间进行通信。WSGI说白了就是一个网关,网关的作用就是在协议之间进行转换。
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。它要做的就是把HTTP协议转化成语言支持的网络协议。比如把HTTP协议转化成WSGI协议,让Python可以直接使用。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。
WSGI,是一种描述web服务器(如nginx,uWSGI等服务器)如何与web应用程序(如用Django、Flask框架写的程序)通信协议。
uwsgi协议是一个uWSGI服务器自有的协议,它用于定义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型描述,用于与nginx等代理服务器通信,它与WSGI相比是两样东西。
uWSGI是实现了uwsgi和WSGI两种协议的Web服务器。
84 Redis的五种数据类型
string hash list set zset(有序集合)
85 select、poll和epoll之间的区别
https://www.cnblogs.com/aspirant/p/9166944.html
86 文件上传的报文格式
87 埋点
获取某种资源的请求时,埋点对请求进行处理,用于进行数据分析
88 lock和Rlock的区别
lock和rlock都可以用来同步进程或者线程,它们之间的区别在于rlock是可重入的,也就是一个线程可以获取多次,只有在release相同次数时,rlock才会有locked状态转换为unlocked。
acquire和release的具体区别:
Lock.acquire([blocking]):
线程阻塞或者非阻塞的获取锁
1.当不带参数调用时,调用线程会阻塞,直到锁的状态是unlocked,然后把锁设置为locked,返回True
2.当设置blocking=False时,调用线程不会阻塞
3.如果有多个线程因为获取锁而阻塞的话,当锁的状态是unloacked的时候,只有一个线程能继续执行,具体哪个线程获取锁,继续执行要看具体的执行环境
RLock.acquire([blocking]):
线程阻塞或者非阻塞的获取锁
1.不带参数调用 如果线程已经获的了锁,那么锁的引用加1,返回True;如果线程没有获得锁,线程阻塞直到锁的状态是unlocked. 如果这个锁没有被任何线程拥有过,设置锁的引用计数为1,然后返回True。
2.设置blocking=False, 线程不阻塞
Lock.release():
释放锁
Rlock.release():
释放锁,每释放一个,锁的引用计数减1,直到锁的引用计数是0,锁的状态才设置为unlocked
89 RESTful的四个规范
- 每一种资源都有一个唯一的标识 URI(统一资源标识符)
- 每种资源都具有GET/POST/PUT/PATCH/DELETE等相关的动作(谓词)
- 每种资源的动作都是无状态的(短连接(请求头) Connection: close)
【扩展】长连接(请求头) Connection: keep-alive;
- 每一个动作交互的数据为json或xml
90 http的三次握手和https的三次握手
http的三次握手
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认。
第二次握手:服务器收到syn包,必须确认客户的syn(ack=j+1),同时自己也发送一个SYN包(syn=k),此时服务器进入SYN_RECV状态。
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
https的三次握手

91 flask的四大内置对象
- request from flask import request 线程本地变量
- session 针对MTV,处理有状态连接的数据,session和cookie组合使用
- config 当前项目的配置信息
- g(global) 局部的而函数内可以修改全局的变量
92 响应状态码含义
1xx: 表示临时响应并需要请求者继续执行操作的状态代码
100 继续
101 切换协议
2xx:表示成功处理了请求的状态的码
200 成功
201 已创建
202 已接受
203 非授权信息
204 无内容
205 重置内容
206 部分内容
3xx: 表示要完成请求,需要进一步操作,通常,这些状态代码用来重定向
300 多种选择
301 永久移动
302 临时移动
303 查看其他位置
304 未修改
305 使用代理
307 临时重定向
4xx: 这些状态码表示请求可能出错,妨碍了服务器的处理
400 错误请求
401 未授权
403 禁止
404 未找到
405 方法禁用
406 不接受
407 需要代理授权(与401)类似
408 请求超时
409 冲突
410 已删除
411 需要有效长度
412 未满足前提条件
413 请求实体过大
414 请求的url过长
415 不支持的媒体类型
416 请求范围不符合要求
417 未满足期望值
5xx: 这些状态码表示服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。
500 服务器内部错误
501 尚未实施
502 错误网关
503 服务不可用
504 网关超时
505 服务器不支持请求中所用的http协议版本
二、数据分析面试题
三、机器学习面试题
四、linux面试题
1.linux常用命令
1.ls命令 :查看当前路径下的文件及目录 -ls -l:以列表的形式常看文件及目录 -ls -li:以列表的形式并且显示编号 -ls -lS --block-size=K:按照文件大小来排序,大小单位为K(默认降序) -ls -ltr:以生成时间来排序:r代表反排,所以当前为升序 -ls -lA:查看当前目录下的所有文件(包含.开头的隐藏文件)但不显示.当前目录和..父级目录信息 -ls -la:显示.当前目录和..父级目录 2.cd命令 :跳转当前所在路径的命令 3.pwd命令 :查看当前路径的命令(绝对路径) 4.mkdir命令 :创建文件夹命令 5.rmdir命令 :删除文件夹命令 6.rm命令 :删除一个不为空的目录或者文件 -rm -rf 文件目录所在位置 -rm -rf *.txt 删除当前目录下所有的txt文件 7.touch :创建新的文件命令 8.echo :打印文本的命令 9.find :查找文件或目录(一般结合管道(|)和grep使用) 10.cp :复制文件的命令 11.mv :剪切文件的命令 12.cat :查看文件内容的命令 13.grep :过滤相关内容的命令
2.文件权限操作
1.文件权限概念: 一个文件或目录的权限由三大部分组成的,分别是用户权限+用户组权限+其它组权限。每部分的权限又分为三小部分,分别是 r(读), w(写), x (执行),代表的数值分别是 r: 4, w:2, x: 1,如果权限值为0时,使用 -表示。 2.修改文件的权限:chmod命令 - 字符权限:chmod [ugoa] [r|w|x] - 数值权限:chmod 777 a.txt
3.服务操作
1.systemctl命令: - start 启动服务 - stop 终止服务 - restart 重启服务 - enable 启动服务(第一次启动) - disable 禁用服务 - status 查看服务状态 2.service命令:同systemctl雷同 3.netstat命令:监测到网络数据流的工具 - netstat -s: 查看网络的统计信息 - netstat - ltpn: 查看所有tcp协议的程序及端口号 4.ps命令:查看当前运行的进程 ----> ps -ef 5.kill命令:杀死某一个进程 ----> kill -9 进程号 6.内存使用情况 top命令:实时获取内存和进程的使用情况。 free命令:命令格式: free [-h|-k|-b|-m|-g|-t] 7.磁盘使用情况 df命令:查看当前所有挂装载磁盘上的存储情况 ----> df [-l|-a|-h] 8.定时任务 crontab命令:使用crontab命令查看、编辑、发布和删除定时任务。
4.yum安装命令
1.更新与配置资源 yum update -y 2.安装git - yum search git - yum install git -y - git --version 3.安装python3.7 - yum install wget -y - wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tar.xz - scp root@10.36.174.67:/opt/project1/python3.7.tar.xz /opt/ - tar -xvf python3.7.tar.xz
5.docker服务
1.docker基本概念 Docker是虚拟化的容器服务。是基于共享底层系统内核和硬件资源,构建的一个虚拟的系统。与VM虚拟机的不同之处,是共享宿主机的内存、存储等相关的资源。而VM是独立的内存、CPU和存储等资源。 2.docker组成部分 - Docker的客户端:为用户提供操作docker的工具,用户输入的命令发送给docker守护进程,则docker守护来管理docker镜像和容器。主要命令是docker【重点】 - Docker的守护进程(dockerd: docker daemon 服务):是一种后端进程(即没有界面),也是一种服务。在使用docker命令时,必须保证docker服务启动(systemctl start docker)。负责接收docker客户端发送的指令并解析和执行。 - Docker镜像:容器的创建是依赖于镜像的,可以将镜像看成为一个类,容器可以被看成为类的实例。镜像分本地镜像和远程镜像, 本地镜像是从远程镜像仓库中下载的,也可以是从某一个容器中生成的。 - Docker容器:由镜像生成的, 一个容器即是一个微型的linux系统,可以进入容器中进行相关的操作,但是linux的工具(如vim)不存在,如需要,则手动安装。容器中的数据可以由宿主机(容器所在的操作系统)进行同步或管理。最后,容器可以生成本地镜像。 3.docker的常用命令 docker images # 查看本地所有镜像 docker search <镜像名> # 搜索相关的镜像资源 docker pull <镜像名>[:版本号] # 从远程镜像仓库中下载到本地, 默认版本为latest docker run [-itd] [-v <宿主机的文件目录>:<容器的文件目录> ...] [-p <宿主机的端口>:<容器的端口> ...] --name <容器名> [--hostname hostname] [--ip ipv4地址] [--network network] [-e 环境变量=值 ...] <镜像名或ID>[:版本号] # 运行 docker ps [-a] # 查看docker中正在运行的容器(子进程), -a代表所有容器(启动、未启动) docker stop|start|restart <容器名或ID> docker logs [-n 最后的行数] <容器名或ID> # 查看容器的日志 docker cp <宿主机文件位置> <容器名或ID>:<容器文件位置> # 宿主机和容器之间相互复制文件 docker exec [-it] <容器名或ID> <容器内部的命令> # 执行容器内部的命令(完整的) docker rmi <镜像名或ID> # 删除镜像 docker rm <容器名或ID> # 删除容器 docker save -o xxx.tar <IMAGE> ... 将一个或多个镜像打包成一个tar压缩文件 docker load -i xxxx.tar 从一个tar压缩文件中加载一个或多个镜像 docker tag SOURSE_IMAGE[:TAG] TARGET_IMAGE[:TAG] 从源镜像重新标记新的镜像名 4.docker的网络操作 docker network [connect|create|ls|inspect|disconnect|prune|rm]
6.pymysql测试连接
1.pip安装pymysql pip install pymysql -i https://mirrors.aliyun.com/pypi/simple 2.编写connect_mysql.py文件 from pymysql import Connect conn = Connect(host='10.36.174.67', port=3306, user='root', passwd='root', db='mysql', charset='utf8') print('--connect OK--') with conn.cursor() as c: c.execute('select user,host from user') for row in c.fetchall(): print(row) 3.执行测试脚本 python connect_mysql.py
7.vi编辑器
1.vi编辑器基本概念 - Linux强大的文本编辑器,存在三种模式:选择(默认)模式、编辑模式、命令行模式 2.模式切换: - 从选择模式 切换 到编辑模式: 按 i键(当前光标位置插入编辑) - 从编辑模式 切换 到 选择模式: ESC键 - 从选择模式 切换 到 命令行模式: Shift + : 3.编辑模式: - 按 i插入, - 按 o当前行下插入新行 - 按O(shift + o) 当前行的上方插入一行 - 按I(shift+i) 移动光标到当前行的行首 - 按A(shift+a)移动光标到当前行的行尾 - 按u撤消之前的操作 - 按ctrl+r取消撤消操作 - 按x 删除当前光标所在的字符 - 按dd删除当前行(剪贴的效果,即可以dd之后按p来粘贴)。 - 按数字+dd 从当前光标所在的行开始,删除 n 行。 4dd表示当前行开始向下删除4开行。 - 按nyy 从当前光标开始复制n行 - 按p在当前光标所在行的下方开始粘贴(之前复制的内容) - 按gg进入首行首字符位置 - 按Shift+g进入最后一行首字符位置 - 按gg d G 清空文件内容 4.命令行模式: - /查询的内容 - set number 显示行号 - 行号 跳转到指定行号的行首 - w 写入,不退出 - q 退出,前提没有修改文件(正常退出) - q! 强制退出, 不保存 - %s/查找的内容/替换的内容/g 查找并替换全部
8.用户及组命令
useradd、usermod、userdel、passwd 、chown 命令1.创建系统用户: useradd或adduser 可以创建linux用户 常用的选项: -d, --home-dir HOME_DIR 指定home目录 -e, --expiredate EXPIRE_DATE 指定用户的过期时间 -g GID 指定主组的名称, 默认用户名即是主组名 -G GID 指定附加组的名称 -m 创建用户的家目录(Home) -p PASSWORD 指定口令 -r 表示创建系统用户,非系统用户不能ssh远程登录 2.删除用户: userdel -fr 用户名 -f 是强制删除,没有提示 -r 是删除用户的home目录和mail相关资源 3.修改用户口令 使用 passwd修改用户的新口令。
9.mysql创建用户和数据库
1.查看数据库 show databases; 2.打开数据库 use databases; 3.创建用户 create user 'disen'@'%' identified by 'disen'; 4.授权 grant all privileges on stu.* to 'disen'@'%'; 如果授权之后,无法使用数据库,可以刷新试试 flush privileges;
10.linux的目录结构
Linux操作系统中的文件目录结构: / 根目录,位于Linux文件系统目录结构的顶层,一般根目录下只存放目录,不要存放文件,/etc、/bin、/dev、/lib、/sbin应该和根目录放,类同Window的根路径是各个盘符(C:、D:) ~ 当前用户的home(家)目录 (非root用户是在/home/{用户名}, root用户的家目录是 /root) /bin : 提供用户使用的基本命令, 存放二进制命令,不允许关联到独立分区,OS启动会用到里面的程序。 /boot:用于存放引导文件,内核文件,引导加载器. /sbin:管理类的基本命令,不能关联到独立分区,OS启动时会用到的程序(重要的命令通常处于bin,不重要的则安装在sbin)。 /lib:存放系统在启动时依赖的基本共享库文件(.so)以及内核模块文件. 系统使用的函数库的目录 也存放了大量的脚本库文件 ,程序在执行过程中,需要调用时会用到 /lib64:存放64位系统上的辅助共享库文件. /etc: 系统配置文件存放的目录,该目录存放系统的大部分配置文件和子目录,不建议在此目录下存放可执行文件 。 /home:普通用户主目录,当新建账户时,都会分配在此,建议单独分区,并分配额外空间用于存储数据。 /root: 系统管理员root的宿主目录,系统第一个启动的分区为/,所以最好将/root和/放置在一个分区下。 /media:便携式移动设备挂载点目录. /mnt:临时文件系统挂载点. /dev: 设备(device)文件目录,存放linux系统下的设备文件,访问该目录下某个文件,相当于访问某个设备,存放连接到计算机上的设备(终端、磁盘驱动器、光驱及网卡等)的对应文件 (b 随机访问,c 线性访问) /opt:第三方应用程序的安装位置. /srv: 服务启动之后需要访问的数据目录,存放系统上运行的服务用到的数据,如www服务需要访问的网页数据存放在/srv/www内。 /tmp:存储临时文件, 任何人都可以访问,重要数据一定不要放在此目录下。 /usr: 应用程序存放目录,/usr/bin 存放保证系统拥有完整功能而提供的应用程序, /usr/share 存放共享数据,/usr/lib 存放不能直接运行的,却是许多程序运行所必需的一些函数库文件,_/usr/local 存放软件升级包,第三方应用程序的安装位置,/usr/share/doc _系统说明文件存放目录。 /var :放置系统中经常要发生变化的文件,如日志文件。/var/log 日志目录及文件./var/tmp:保存系统两次重启之间产生的临时数据. /proc: 用于输出内核与进程信息相关的虚拟文件系统,目录中的数据都在内存中,如系统核心,外部设备,网络状态,由于数据都存放于内存中,所以不占用磁盘空间 /sys : 用于输出当前系统上硬件设备相关的虚拟文件系统.
五、Linux shell编程总结
五、MySQL面试题
1.什么是数据库
1.数据库的基本概念: - 数据库(Database)是一种存储结构化数据的方式,一般存在两种类型的数据库: 关系型数据库、非关系型数据库。 - 关系型数据库: 存储二维关系表的仓库, 二维关系表是由列(特征)和行组成的。提供标准的SQL语句进行管理(创建、修改、删除)。关系型数据库一般都支持约束、索引、视图、函数、存储过程、触发器、表、字典(动态视图)等对象。【重点】 - 非关系型数据库: 不需要使用SQL,通过SDK(软件开发环境-模块或库, Software Development Kit)相关的方法进行操作,不支持二维关系结构,又称之为NoSQL数据库。包含redis、mongodb等。
2.有哪些关系型数据库
- 大厂的关系型数据库: DB2(IBM公司)、Oracle(甲骨文公司)、MySQL(原Sun公司,目前也是甲骨文公司)。 - 其它的关系型数据库:MariDB(个人, 同MySQL一个作者)、 posgreSQL(开源的数据库) - Hadoop家族的数据库: Hive(依赖MySQL, MapReduce), Hbase(实时) - 嵌入式设备中的数据库: sqlite3(没有特定的数据类型)、IotDB(分布式物联网存储的实时数据库)
3.三个数据范式
1.数据范式的基本概念: 限制表的设计, 让表的结构更合理、减少数据冗余。 2.第一范式: 确保每一个列保持原子性(列不可分隔)。 理解:表字段每一列一个属性,不可在差分成两个或者多个列。 3.第二范式: 确保每一列的数据都和主键相关,即表中存在主键约束。 理解:存在任意的一个表字段,都和表的主键存在部分依赖。 4.第三范式: 确保每一列都和主键直接相关,而不能间接相关。即存在主外键关系。 理解:存在一个表字段,和主键存在传递函数关系(即存在主外键关系)
4.DDL语句
1.DDL语句基本概念:(主要是对表、视图、...进行操作) DDL 数据库描述或定义语言(Data Definition Language),包含数据库、表、视图、函数、索引、存储过程、触发器等对象的创建、修改和删除等操作。
4.1创建和删除数据库
1.创建数据库:create database 数据库名 2.删除数据库:drop database 数据库名
4.2创建表
1.语法: create table [if not exists] <表名>(<字段名> <字段类型>[ (字段数据长度) ] [约束] [comment 注释文本], ...,[constraint 表级约束语句]) [engine=INNODB|MYISAM|MEMERY|CSV] [character set 字符集]; 2.注意 创建表的时候主要关注:字段名,字段类型,约束,和引擎 3.特别注意:constraint子句 constraint [约束名称] 约束类型 [index_type: {BTREE, HASH}] (字段名,...) [references 引用表的名称(引用的字段名) on <delete|update> <restrict|cascade|set null|no action|set default> ]
4.3修改表
修改表: 表名、表字段名、字段类型及字段的约束。 1.修改表名 alter table 表名 rename as|to 新表名 举例:alter table book rename as tb_book; 2.修改表字段 alter table 表名 change column 旧字段名 新字段名 类型 举例:alter table tb_book change column name book_name varchar(40); 3.修改字段类型 alter table 表名 modify 列名 类型(长度) 举例:alter table tb_book modify summary varchar(200); 4.删除字段主外键约束 - 删除外键约束: alter table 表名 drop foreign key 约束名称 举例:alter table tb_book drop foreign key book_author_fk; - 删除主键约束: alter table 表名 drop primary key 举例:alter table tb_author drop primary key; - 删除唯一约束: alter table <表名> drop {index|key} 唯一约束名或列名 举例:alter table tb_book drop index name; 5.删除字段 alter table 表名 drop 字段名 举例:alter table tb_book drop summary; 6.添加字段 alter table 表名 add 字段名 数据类型 约束 注释等 举例:alter table tb_book add column summary text not null; 7.添加字段约束 alter table <表名>add [constraint [约束名] ] | primary key [index_type: {using btree|hash}] (字段1, 字段2, ....) | unique [key | index ] [index_name] [index_type] (字段1, 字段2, ...) | foreign key (字段1, 字段2,...) references 引用表名(字段1,字段2, ...) [on delete|update restrict|cascade|set null|no action|set default] 举例:alter table tb_author modify author_id integer primary key auto_increment; -- alter table tb_author add primary key (author_id);
4.4删除表
drop table 表名
4.5查询表结构
方式一: DESC 方式二: show create table 表名
4.6查看所有的表
show tables;
4.7子查询创建表
create table 表名 select子句 举例: create table tb_bejin_author select * from tb_author where city='北京';
5.DML语句
1.DML语言的基本概念:(主要是对表中的数据进行增删改的操作) DML(Data Manipulation Language) 数据操纵语言,主要负责数据(行或记录)的插入、更新和删除操作。
5.1增加数据
1.单行插入:insert into <表名> [(字段1, 字段2, ...)] values (字段值1, 字段值2, ...) 举例:insert into tb_author values(1, 'disen', '西安', '17791692095'); 2.多行插入:insert into <表名> [((字段1, 字段2, ...))] values (字段值1, 字段值2, ...), (字段值1, 字段值2, ...),(字段值1, 字段值2, ...),...(字段值1, 字段值2, ...); 举例:insert into tb_author(city, name, phone) values ('北京', '老邓', '18918810018'), ('北京', '老刘', '17866541239'), ('杭州', '老马', '18766541908'); 3.子查询方式插入:insert into <表名> [(字段1, ...)] select子句; 举例:insert into tb_bejin_author select * from tb_author where city='北京';
5.2更新数据
update <表名> set 字段1=字段值1 [,字段2=字段值2, ...] [where 子句] 举例:update tb_author set city='上海' where city='西安' and name='disen';
5.3删除数据
delete from <表名> [where 子句] 举例:delete from tb_book where act_price <= 15;
6.DQL语句
1.DQL语句的基本概念:(主要是对表中的数据进行查看操作) DQL(Data Query Language)数据查询语言,主要负责数据的查询,包含单表查询、多表查询、子查询、分组查询、条件查询、模糊查询、分页查询、窗口函数统计等。
6.1select from where语句
1.select select后面主要跟的是表字段,筛选想要的字段 2.from from后面主要跟的是表名,表示从哪个表里面去查看 3.where where后面主要跟的是条件,表示满足这样条件的表数据有哪些 4.group by、having,order by、limit、offset、rows等 这些主要是更在where后面用于细致的过滤条件
6.2内连接、外链接、自然连接语句
1.内连接 join on:将两个主外键关系的表进行连接,返回的是符合匹配后的数据 join后面跟的是要被连接的表 on后面跟的是条件:两个表主外键相等 2.外链接 - 左外连接:left join on 不同之处在于,连接后的表除了保存了匹配后的数据,还保存了左边表中没有匹配的数据 - 右外连接:right join on 不同之处在于,连接之后的表除了保存了匹配之后的数据,还保存了右边表中没有匹配的数据 3.自然连接 join:和内连接的原理一致,只不过他不在需要on后面的主外键相当的条件了,默认会匹配他们的主外键关系,也是我们在设计模型中常用的连接方式
6.3分组语句
group by 分组子句,可以按列中相同的数据进行分组,分组之后的数据可以聚合计算,聚合计算函数包含最小min()、最大max()、求和sum()、统计数量count和平均avg()。
6.4排序语句
order by 子句可以按列的值进行升序ASC、降序DESC进行排序 【注意】order by 可以对多个列进行排序,先左后右。如果左边的值相同的情况下,按右边的列值进行排序。
6.5分页语句
mysql 中分页使用limit 关键字, limit子句在select查询语句的最后位置。limit 起始行号(从0开始), 记录个数(行数,一般使用10, 20, 50, 100)
6.6union语句
- union 语句实现两个select子查询的数据联合。默认是去重的。 - union all 保留所有子查询的结果,不去重。 举例: select a.book_id, a.book_name, b.name as author_name,b.author_id from tb_book a natural left join tb_author b union select a.book_id, a.book_name, b.name as author_name,b.author_id from tb_book a natural right join tb_author b;
6.7windows语句
1.windows语句基本概念: - mysql 从8.0开始支持窗口语句查询,即分区统计和现在数据进行连接显示(输出 )。一般配合 聚合函数+ over(), over()函数中可以指定分区(分组)的字段,即指定partition by子句。当然也可以使用其它的窗口函数,如rank实现排名。 2.常用语句: - 聚合函数+over() - 费聚合函数+over() - row_number() - rank()排名 【注意】在over()函数中指定partition by子句。当然也可以使用其它的窗口函数,如rank实现排名。
7.DTL语句
1.DTL语句的基本概念: DTL主要是对事务进行操作的语句。
7.1开启事务
begin;
7.2回滚事务
callback;
7.3提交事务
commit;
8.常用函数
8.1时间函数
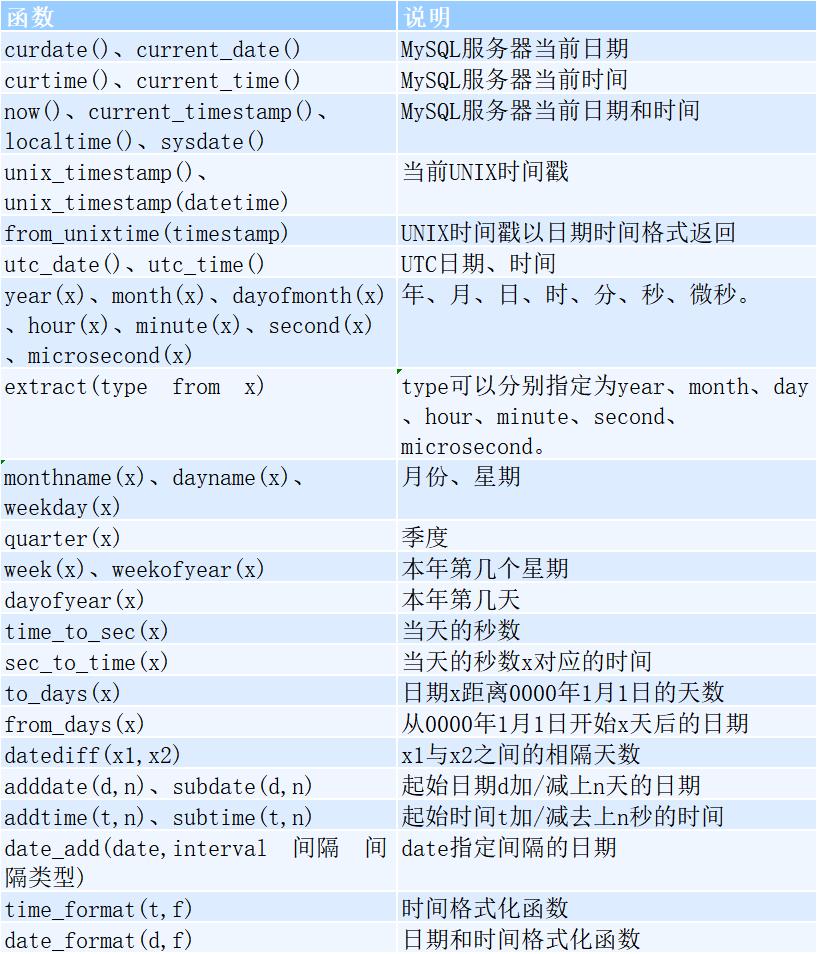
8.2字符函数

8.3数值函数
1.常用的数值函数: - abs(n): 绝对值 - round(n): 四舍五入 - ceil(n): 上行取整 - floor(n): 下行取整 - sin(n) - cos(n) - tan(n) - atan(n) - asin(n) - acos(n): - sqrt(n): 开平方根 - power(n, m): n的m次方/幂
8.4聚合函数
1.常用的聚合函数: - min() - max() - sum() - avg() - count()
8.5加密函数
1.常用的加密函数 - 不可逆的有: sha1(s): sha1 签名信息, 40位。 sha2(s, 0|224|256|384|512): 比sha1更强大的数据加密算法 md5(s): md5签名信息,32位。 可逆的有: aes_encrypt(str, key): 使用key密钥对str进行AES加密(对称加密-可逆的) aes_decrypt(encrypt_str, key): 使用key密钥进encrypt_str密文解密。
9.索引
mysql索引是一种数据结构(btree, hash),在DQL语句的where条件中使用索引字段,则先从索引中查询,达到加速查询效果。 【重点】一张表中的索引个数,原则上没有限制,但索引不能过量创建,否则会影响DML语句的性能。 视图是一种高级子查询,即将查询语句存储,以便之后使用。视图同表一样,存在创建、修改和查询。
9.1创建索引
方式一: create [ unique|fulltext|spatial ] index <索引名> [ using <index_type> ] on <表名>(<字段名> [ (length)] [ ASC | DESC ]) 举例:create index pay_time_index using btree on tb_table(order_pay_time,DESC); 方式二: 在创建表的时候创建索引 举例: drop table if exists tb_cate; create table if not exists tb_cate( id integer primary key auto_increment, name varchar(20), ord int, constraint unique index name_uniq using btree (name) ); 方式三: 在修改表的时候创建索引 举例: alter table tb_cate add fulltext index cate_name_index (name);
9.2查看索引
查看索引我们常用的方法是通过索引视图来查看
9.3删除索引
alter table 表名 drop index 索引名 【注意】删除普通索引都好删除,在删除外键索引时,先要解除外键约束,才能删除。同理,删除主键索引时,先要解除主键约束,才能删除。
10.视图
视图用于缓存复杂的sql语句, 查询的用法同表。 视图本质上是一张虚拟的表。
10.1创建视图
create view as select子句 举例: create or replace view account_top10 as select * from account where money >= 1000000;
10.2删除视图
drop view [if exists] <视图名>;
11.函数
11.1创建函数
create [definer=user[@host] ] function <函数名> ( [IN |OUT|INOUT] <参数名> <参数类型>, ...) returns <函数返回数据的类型> [comment 注释] [deterministic] <函数的功能>; 举例: create function pct_format(val float) returns varchar(10) deterministic return concat(round(val * 100), '%');
11.2使用函数
select c.cid,c.name, max(score) max_score, min(score) min_score, round(avg(score),2) avg_score, pct_format(sum(s1)/count(1)) as '及格率', pct_format(sum(s2)/count(1)) as '中等率', pct_format(sum(s3)/count(1)) as '优良率', pct_format(sum(s4)/count(1)) as '优秀率' from ( select cid, score, if(score >= 60, 1, 0) as s1, if(score >=70 and score <80,1, 0) as s2, if(score >=80 and score <90, 1, 0 ) as s3, if(score >=90,1, 0) as s4 from SC ) A natural join Course c group by c.cid,c.name;
11.3删除函数
drop function [if exists] <函数名>;
12.存储过程
1.存储过程概念: 存储过程可以实现比较复杂业务逻辑的SQL语句,SQL语句可以是DML或DQL语句。
12.1创建存储过程
CREATE [DEFINER = user] procedure <存储过程名> ([proc_parameter[,...]]) [characteristic ...] begin <存储过程体> end; 举例: delimiter && create procedure stu_total_level (sid varchar(50), out sum_score float, out level varchar(10)) begin select sum(score) , case when sum(score)>=240 then '优' when sum(score)>=200 then '良' when sum(score)>=180 then '及格' else '不及格' end into sum_score, level from SC group by sid; end && delimiter ; 【注意】delimiter是SQL语句的结束符
12.2调用存储过程
使用call调用存储过程,如果存储过程需要变量输出,则直接使用@变量名声明 举例: -mysql> call stu_total_level('01', @score, @level); -mysql> select @score, @level;
12.3删除存储过程
drop procedure if exists <存储过程名>;
13.触发器
1.触发器基本概念 trigger存储器是基于行级事件,监测发生或改变的数据。 如,删除用户信息时,在删除之前可以将数据存储到日志文件中(备份)。
13.1创建触发器
CREATE trigger 触发器名称 trigger_time trigger_event ON tbl_name FOR EACH ROW [trigger_order] trigger_body{ begin; 操作 end; } trigger_time: { BEFORE | AFTER } trigger_event: { INSERT | UPDATE | DELETE } trigger_order: { FOLLOWS | PRECEDES } other_trigger_name
13.2删除触发器
drop trigger 触发器名称
14.数据库用户
1.数据库用户概念: 数据库的管理用户信息存储在mysql.user表中。 一般用户信息包含user用户名、host主机、authentication_string 口令等。
14.1创建用户
create user <user>@<host> identified [with mysql_native_password] by <口令> [password expire [default | never | interval N day] ] [account lock|unlock] 举例: create user 'disen'@'%' identified with mysql_native_password by 'disen';
14.2修改用户
alter user [if exists] <user>@<host> identified [with mysql_native_password] by <口令> [password expire [default | never | interval N day] ] [account lock|unlock] - 锁定用户: alter user 'disen'@'%' account lock; - 修改并解锁用户: alter user 'disen'@'%' identified with mysql_native_password by 'disen123' account unlock;
14.3删除用户
drop user [if exists] <user>@<host> 举例:drop user 'disen'@'%';
15.权限
mysql中存在非常多的权限,以便于为不同的管理员提供不同的权限操作
15.1管理员权限
1.常见权限等级命令 - ALL 具有所有权限 - CREATE TABLESPACE 创建表空间 - CREATE USER 创建用户 - FILE 输出文件和加载文件 - PROCESS 访问线程信息的权限 - RELOAD 重载权限,如具有flush相关的功能(flush-privileges、flush-status) - REPLICATION CLIENT 客户端备份权限 - REPLICATION SLAVE 主从备份权限 - SHOW DATABASES 显示数据库信息的权限 - SHOW VIEW 显示视图的权限 - SHUTDOWN 关闭或重启服务的权限,针对mysqladmin shutdown|restart命令。 - SUPER 具有超级用户权限,如设置全局变量等 - TRIGGER 具有触发器相关权限 - UPDATE 具有更新表记录的权限 - SELECT 具有查询表的权限 - INSERT 具有插入表权限 - INDEX 具有索引相关的管理权限 - DELETE 具有删除表记录的权限 - CREATE View 具有创建视图的权限 - CREATE 具有创建数据库和表的权限 - DROP 具有删除对象的权限 ALTER 具有修改对象的权限
15.2授权
grant <权限> on <数据库>[.<对象>] to <用户名>@<主机> 举例:grant select,update on studb.Student to 'disen'@'%'; grant select,update on studb.Teacher to disen;
15.3查看权限
show grants; show grants for <user>@<host> ; show grants current_user();
15.4撤销权限
REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level FROM user_or_role [, user_or_role] ... 举例: revoke drop on studb.A from disen;
16.SQL优化
-1.通过show status命令了解各种SQL的执行频率 -2.定位执行效率较低的SQL语句 -3.通过EXPLAIN分析较低SQL的执行计划 -4.通过show profile分析SQL -5.通过trace分析优化器如何选择执行计划 -6.确定问题并采取相应的优化措施
六、Python与MySQL的交互【连接桥梁】
1.pymysql的curl操作
2.封装DB类
3.基于type元类设计ORM
4.sqlalchemy的应用
七、FASTAPI面试题
八、html+css+javascript面试题
九、Django面试题
十、VUE面试题
十一、爬虫面试题
十二、Redis面试题
1.Redis和MySQL的区别
1.mysql是关系型数据库,而redis是NOSQL,非关系型数据库。mysql将数据持久化到硬盘,读取数据慢,而redis数据先存储在缓存中,读取速度快,但是保存时间有限,最后按需要可以选择持久化到硬盘。 2.mysql作为持久化数据库,每次访问都要在硬盘上进行I/O操作。频繁访问数据库会在反复连接数据库上花费大量时间。redis则会在缓存区存储大量频繁访问的数据,当浏览器访问数据的时候,先访问缓存,如果访问不到再进入数据库.
2.Redis的五大数据类型
1.字符串类型 String 添加操作:set 2.哈希对象 hash 添加操作: hset 3.列表对象 list 添加操作: lpush 4.集合对象 set 添加操作:sadd 5.有序集合对象 sorted set 添加操作: zadd
3.Redis如何解决key冲突?
拉链法。这个问题可以考虑到另一个问题,HashMap是如何解决key冲突的,同样也是采用拉链地址法。如果被问到解决key值冲突还有什么方法?一般来说解决key值冲突的方法有俩种,一种是开放地址法,另一种就是拉链法。
4.Redis的存储机制和持久化方案?
背景:首先要明白什么是持久化?上面第一个问题已经阐述过了,简单来说,类似于MySQL这种直接将数据存到硬盘的方式就是持久化。但是Redis又不能照搬照抄SQL的存储方法,最大的原因也是讲过的——NoSQL,也就意味着没有类似于B+树的操作。方法一: RDB持久化策略。也是redis的默认方法。先将数据存储到内存,当数据累计到某种设定的阈值后会触发一次DUMP 操作,将变化的数据存进RDB文件。一旦 Redis 异常退出,就会丢失最后一次快照以后更改的所有数据 方式二: 开启AOF持久化策略 先将数据存储到内存。开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入硬盘中的 AOF 文件.AOF文件不存储数据,储存的是执行的命令。 AOF最关键的配置就是关于调用fsync追加日志文件的频率,有两种预设频率,always每次记录进来都添加,everysecond 每秒添加一次。(fsync函数的作用就是将数据从内存写入硬盘)。 由于AOF和RDB存储的文件内容并不相同,RDB存储的是真实的,存进去的数据,AOF存储的是大量操作数据的指令,这种指令一旦增多,就会必然使得AOF文件扩大,所以会引发一种新的机制:Rewrite。所谓Rewrite就是将日志文件中的所有数据都重新写到另外一个新的日志文件中,但是不同的是,对于老日志文件中对于Key的多次操作,只保留最终的值的那次操作记录到日志文件中,从而缩小日志文件的大小。
5.redis过期策略
如何设置redis的过期时间?最简单的就是使用 expire key second,当然还有各种其他方式,比如 pexpire key milliseconds等等,redis查看过期时间的语法也很简单,ttl key就可以看到还剩多长时间。redis内置的策略叫做惰性删除,也叫“被动删除”。 原理:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。这个方法是可取的,但是必然存在另外一个问题,使用的时候判断是否过期再删除,万一我不使用呢?若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露
6.Redis的集群策略?
redis的集群有多个,但是性能最强大的是官方的redis-cluster。1.使用去中心化化思想, 使用hash slot方式 将16348个hash slot 覆盖到所有节点上 对于存储的每个key值 使用CRC16(KEY)&16348=slot 得到他对应的hash slot 并在访问key时就去找他的hash slot在哪一个节点上 然后由当前访问节点从实际被分配了这个hash slot的节点去取数据。 2.投票容错。通过投票容错机制判断节点是否还在工作中。Redis集群中每个节点都会按时向其他节点发送”心跳包”。当有一个节点不响应时,则判断该节点故障。要求是超过半数的投票不响应。 3.为了解决节点master失效fail的问题,可以使用主从复制策略。
7.Redis是单线程的吗?
redis是单线程的! redis 核心就是 如果我的数据全都在内存里,我单线程的去操作 就是效率最高的,为什么呢,因为多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU 绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处理这个事。在内存的情况下,这个方案就是最佳方案。什么时候用多线程的方案呢? 答案是:下层的存储等慢速的情况。比如磁盘
8.redis的常用命令
8.1key相关的命令
- keys * 查看所有的key - select n 选择某一个数据库,n可以是0~15, 默认的数据库是0号库, 默认是16个数据库 - del key [key ...] 删除key - expire key seconds 设置key的过期时间 - flushdb 清空当前的库的key - flushall 清空所有库的key - exit 退出redis交互环境
8.2string相关命令
- set name disen [EX seconds] 添加name的值为disen ,可指定过期时间(秒) - get name 获取name的value值
8.3 list类型的命令
- hset key field value 赋值 举例:hset user username ljj - hget key field 取值 举例:hget user username - hget key 获取所有字段值 举例:hget user - hdel key field 删除字段 举例:hdel user username - hincrby key field increment 增加数字 举例:hincrby user age 2 - hexists key field 判断字段是否存在 举例:hexists user username
8.4 hash类型的命令
- lpush key value [value…] 向列表左边添加元素 举例:lpush list:1 1 2 3 - rpush key value [value…] 向列表右边添加元素 举例:rpush list:1 4 5 6 - lrange key start stop 查看start到stop之间的元素 举例:lrange list:1 0 2 - lpop key rpop key 移除列表左边的元素并返回 举例: lpop list:1 - llen key 获取列表中所有元素 举例:llen list:1 - lrem key count value 删除列表指定元素 举例:lrem list:1 0 4 - lindex key index 获取指定索引元素值 举例:lindex list:1 2 - lset key index value 设置指定索引的元素值 举例:lset list:1 2 2 - ltrim key start stop 只保留start,stop中间的元素值 举例:ltrim list:1 0 2 - linsert key before | after pivot value 向列表中插入元素 - rpoplpush source destination 将元素从一个列表移动到另一个列表中去
8.5 set类型的命令
- sadd key member [member…] 增加元素 - srem key member [member…] 删除元素 - smembers key 获取集合中所有元素 - sismember key member 判断元素是否在集合中 - sdiff key [key…] 集合的差集运算 - sinter key [key…] 集合的交集运算 - sunion key [key…] 集合的并集运算 - scard key 获取集合中元素的个数 - spop key 从集合中弹出一个元素(随机弹出)
8.6 zset类型的命令
1.zset基本概念: SortedSet 又叫 zset,SortedSet 是有序集合,可排序的,但是唯一。 SortedSet 和 Set 的不同之处,会给 Set 中元素添加一个分数,然后通过这个分数进行排序。- zadd key score member [score member…] 增加元素 - zscore key member 获取元素分数 - zrem key member [member…] 删除元素 - zrange key start stop [withscores] 获得排名在某个范围的元素列表 - zrevrange key start stop [withscores] 按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素 - zrank key member 从小到大获取元素排名 - zrevrank key member 从大到小获取元素排名 - zrangebyscore key min max [withscores][limit offset count] 获取指定分数范围的元素 - zincrby key increment member 增加某个元素的分数,返回结果值 - zcard key 获得集合中元素的数量 - zcount key min max 获得指定分数范围内元素的个数 - zremrangebyrank key start stop 按照排名范围删除元素
十三、Git操作面试题
1.git常用命令有哪些?
git branch 查看本地所有分支 git status 查看当前状态 git commit 提交 git branch -a 查看所有的分支 git branch -r 查看远程所有分支 git commit -am "init" 提交并且加注释 git remote add origin git@192.168.1.119:ndshow git push origin master 将文件给推到服务器上 git remote show origin 显示远程库origin里的资源 git push origin master:develop git push origin master:hb-dev 将本地库与服务器上的库进行关联 git checkout --track origin/dev 切换到远程dev分支 git branch -D master develop 删除本地库develop git checkout -b dev 建立一个新的本地分支dev git merge origin/dev 将分支dev与当前分支进行合并 git checkout dev 切换到本地dev分支 git remote show 查看远程库 git add . git rm 文件名(包括路径) 从git中删除指定文件 git clone git://github.com/schacon/grit.git 从服务器上将代码给拉下来 git config --list 看所有用户 git ls-files 看已经被提交的 git rm [file name] 删除一个文件 git commit -a 提交当前repos的所有的改变 git add [file name] 添加一个文件到git index git commit -v 当你用-v参数的时候可以看commit的差异 git commit -m "This is the message describing the commit" 添加commit信息 git commit -a -a是代表add,把所有的change加到git index里然后再commit git commit -a -v 一般提交命令 git log 看你commit的日志 git diff 查看尚未暂存的更新 git rm a.a 移除文件(从暂存区和工作区中删除) git rm --cached a.a 移除文件(只从暂存区中删除) git commit -m "remove" 移除文件(从Git中删除) git rm -f a.a 强行移除修改后文件(从暂存区和工作区中删除) git diff --cached 或 $ git diff --staged 查看尚未提交的更新 git stash push 将文件给push到一个临时空间中 git stash pop 将文件从临时空间pop下来 --------------------------------------------------------- git remote add origin git@github.com:username/Hello-World.git git push origin master 将本地项目给提交到服务器中 ----------------------------------------------------------- git pull 本地与服务器端同步 ----------------------------------------------------------------- git push (远程仓库名) (分支名) 将本地分支推送到服务器上去。 git push origin serverfix:awesomebranch ------------------------------------------------------------------ git fetch 相当于是从远程获取最新版本到本地,不会自动merge git commit -a -m "log_message" (-a是提交所有改动,-m是加入log信息) 本地修改同步至服务器端 : git branch branch_0.1 master 从主分支master创建branch_0.1分支 git branch -m branch_0.1 branch_1.0 将branch_0.1重命名为branch_1.0 git checkout branch_1.0/master 切换到branch_1.0/master分支 du -hs git branch 删除远程branch git push origin :branch_remote_name git branch -r -d branch_remote_name ----------------------------------------------------------- 初始化版本库,并提交到远程服务器端 mkdir WebApp cd WebApp git init 本地初始化 touch README git add README 添加文件 git commit -m 'first commit' git remote add origin git@github.com:daixu/WebApp.git 增加一个远程服务器端
2.提交是发生冲突,你能解释冲突是如何产生的吗?你是如何解决的?
我们在开发过程中,都有自己的分支,基本不会发生提交冲突。但如果是诸如公共类的公共方法,我和别人同时修改同一个文件,他提交后我再提交就会报冲突的错误。 发生冲突,在IDE里面一般都是对比本地文件和远程分支的文件,然后把远程分支上文件的内容手工修改到本地文件,然后再提交冲突的文件使其保证与远程分支的文件一致,这样才会消除冲突,然后再提交自己修改的部分。特别要注意下,修改本地冲突文件使其与远程仓库的文件保持一致后,需要提交后才能消除冲突,否则无法继续提交。必要时可与同事交流,消除冲突。 发生冲突,也可以使用命令。 - 通过git stash命令,把工作区的修改提交到栈区,目的是保存工作区的修改; - 通过git pull命令,拉取远程分支上的代码并合并到本地分支,目的是消除冲突; - 通过git stash pop命令,把保存在栈区的修改部分合并到最新的工作空间中;
3.如果本次提交失误操作,如何撤销?
如果想撤销提交到索引区的文件,可以通过git reset HEAD file;如果想撤销提交到本地仓库的文件,可以通过git reset –soft HEAD^n恢复当前分支的版本库至上一次提交的状态,索引区和工作空间不变更;可以通过git reset –mixed HEAD^n恢复当前分支的版本库和索引区至上一次提交的状态,工作区不变更;可以通过git reset –hard HEAD^n恢复当前分支的版本库、索引区和工作空间至上一次提交的状态。
4.如果我想修改提交的历史信息,应该用什么命令?
如果修改最近一次提交的历史记录,就可以用git commit –amend命令;vim编辑的方式; 如果修改之前提交的历史记录,就需要按照下面的步骤: 第一步:- git logs -3 首先查看前三次的提交历史记录; 第二步:- git rebase –i HEAD~3,会把前3次的提交记录按照倒叙列出来; - 这里把第一行的‘pick’修改为‘edit’,然后esc + :wq退出vim编辑器; 第三步:- git commit –amend 进入vim编辑器并修改提交信息。 第四步:- git rebase –continue 第五步:- 查看修改结果,修改成功
5.你使用过git stash命令吗?你一般什么情况下会使用它?
命令git stash是把工作区修改的内容存储在栈区。 以下几种情况会使用到它: - 解决冲突文件时,会先执行git stash,然后解决冲突; - 遇到紧急开发任务但目前任务不能提交时,会先执行git stash,然后进行紧急任务的开发,然后通过git stash pop取出栈区的内容继续开发; - 切换分支时,当前工作空间内容不能提交时,会先执行git stash再进行分支切换;
6.如何查看分支提交的历史记录?查看某个文件的历史记录呢?
- 查看分支的提交历史记录: - git log –number:表示查看当前分支前number个详细的提交历史记录; - git log –number –pretty=oneline:在上个命令的基础上进行简化,只显示sha-1码和提交信息; - git reflog –number: 表示查看所有分支前number个简化的提交历史记录; - git reflog –number –pretty=oneline:显示简化的信息历史信息; - 查看文件的历史记录: 如果要查看某文件的提交历史记录,直接在上面命令后面加上文件名即可。 注意:如果没有number则显示全部提交次数。
7.能不能说一下git fetch和git pull之间的区别?
简单来说:git fetch branch是把名为branch的远程分支拉取到本地;而git pull branch是在fetch的基础上,把branch分支与当前分支进行merge;因此pull = fetch + merge。
8.使用过git merge和git rebase吗?他们之间有什么区别?
简单的说,git merge和git rebase都是合并分支的命令。 git merge branch会把branch分支的差异内容pull到本地,然后与本地分支的内容一并形成一个committer对象提交到主分支上,合并后的分支与主分支一致; git rebase branch会把branch分支优先合并到主分支,然后把本地分支的commit放到主分支后面,合并后的分支就好像从合并后主分支又拉了一个分支一样,本地分支本身不会保留提交历史。
9.能说一下git系统中HEAD、工作树和索引之间的区别吗?
- HEAD 文件包含当前分支的引用(指针); - 工作树 是把当前分支检出到工作空间后形成的目录树,一般的开发工作都会基于工作树进行;索引index文件是对工作树进行代码修改后,通过add命令更新索引文件;GIT系统通过索引index文件生成tree对象;
10.之前项目中是使用的GitFlow工作流程吗?它有什么好处?
GitFlow可以用来管理分支。GitFlow工作流中常用的分支有下面几类:
10.1master分支
最为稳定功能比较完整的随时可发布的代码,即代码开发完成,经过测试,没有明显的bug,才能合并到 master 中。请注意永远不要在 master 分支上直接开发和提交代码,以确保 master 上的代码一直可用;
10.2develop分支
用作平时开发的主分支,并一直存在,永远是功能最新最全的分支,包含所有要发布 到下一个 release 的代码,主要用于合并其他分支,比如 feature 分支; 如果修改代码,新建 feature 分支修改完再合并到 develop 分支。所有的 feature、release 分支都是从 develop 分支上拉的。
10.3feature分支
这个分支主要是用来开发新的功能,一旦开发完成,通过测试没问题(这个测试,测试新功能没问题),我们合并回develop 分支进入下一个 release
10.4release分支
用于发布准备的专门分支。当开发进行到一定程度,或者说快到了既定的发布日,可以发布时,建立一个 release 分支并指定版本号(可以在 finish 的时候添加)。开发人员可以对 release 分支上的代码进行集中测试和修改bug。(这个测试,测试新功能与已有的功能是否有冲突,兼容性)全部完成经过测试没有问题后,将 release 分支上的代码合并到 master 分支和 develop 分支
10.5hotfix 分支
用于修复线上代码的bug。**从 master 分支上拉。**完成 hotfix 后,打上 tag 我们合并回 master 和 develop 分支。
10.6GitFlow主要工作流程
1.初始化项目为gitflow , 默认创建master分支 , 然后从master拉取第一个develop分支 2.从develop拉取feature分支进行编码开发(多个开发人员拉取多个feature同时进行并行开发 , 互不影响) 3.feature分支完成后 , 合并到develop(不推送 , feature功能完成还未提测 , 推送后会影响其他功能分支的开发);合并feature到develop , 可以选择删除当前feature , 也可以不删除。但当前feature就不可更改了,必须从release分支继续编码修改 4.从develop拉取release分支进行提测 , 提测过程中在release分支上修改BUG 5.release分支上线后 , 合并release分支到develop/master并推送;合并之后,可选删除当前release分支,若不删除,则当前release不可修改。线上有问题也必须从master拉取hotfix分支进行修改; 6.上线之后若发现线上BUG , 从master拉取hotfix进行BUG修改; 7.hotfix通过测试上线后,合并hotfix分支到develop/master并推送;合并之后,可选删除当前hotfix ,若不删除,则当前hotfix不可修改,若补丁未修复,需要从master拉取新的hotfix继续修改; 8.当进行一个feature时 , 若develop分支有变动 , 如其他开发人员完成功能并上线 , 则需要将完成的功能合并到自己分支上,即合并develop到当前feature分支; 9.当进行一个release分支时 , 若develop分支有变动 , 如其他开发人员完成功能并上线 , 则需要将完成的功能合并到自己分支上,即合并develop到当前release分支 (!!! 因为当前release分支通过测试后会发布到线上 , 如果不合并最新的develop分支 , 就会发生丢代码的情况); GitFlow的好处:为不同的分支分配一个明确的角色,并定义分支之间如何交互以及什么时间交互;可以帮助大型项目理清分支之间的关系,简化分支的复杂度。
11.使用过git cherry-pick,有什么作用?
命令git cherry-pick可以把branch A的commit复制到branch B上。 在branch B上进行命令操作: - 复制单个提交:git cherry-pick commitId - 复制多个提交:git cherry-pick commitId1…commitId3 注意:复制多个提交的命令不包含commitId1.
12.git跟其他版本控制器有啥区别?
GIT是分布式版本控制系统,其他类似于SVN是集中式版本控制系统。 分布式区别于集中式在于:每个节点的地位都是平等,拥有自己的版本库,在没有网络的情况下,对工作空间内代码的修改可以提交到本地仓库,此时的本地仓库相当于集中式的远程仓库,可以基于本地仓库进行提交、撤销等常规操作,从而方便日常开发。
13.如何把本地仓库的内容推向一个空的远程仓库?
- git remote add origin XXXX - git push -u origin master - git push origin master
14.常用命令补充
1.生成密钥:ssh-keygen 2.git init在当前目录下创建一个本地仓库 3.git push -u origin master
15.git分支操作,问什么要做git分支
十五、项目阐述
1.二手交易平台
2.自动化测试平台
简单的说,git merge和git rebase都是合并分支的命令。
git merge branch会把branch分支的差异内容pull到本地,然后与本地分支的内容一并形成一个committer对象提交到主分支上,合并后的分支与主分支一致;
git rebase branch会把branch分支优先合并到主分支,然后把本地分支的commit放到主分支后面,合并后的分支就好像从合并后主分支又拉了一个分支一样,本地分支本身不会保留提交历史。
9.能说一下git系统中HEAD、工作树和索引之间的区别吗?
- HEAD 文件包含当前分支的引用(指针); - 工作树 是把当前分支检出到工作空间后形成的目录树,一般的开发工作都会基于工作树进行;索引index文件是对工作树进行代码修改后,通过add命令更新索引文件;GIT系统通过索引index文件生成tree对象;
10.之前项目中是使用的GitFlow工作流程吗?它有什么好处?
GitFlow可以用来管理分支。GitFlow工作流中常用的分支有下面几类:
10.1master分支
最为稳定功能比较完整的随时可发布的代码,即代码开发完成,经过测试,没有明显的bug,才能合并到 master 中。请注意永远不要在 master 分支上直接开发和提交代码,以确保 master 上的代码一直可用;
10.2develop分支
用作平时开发的主分支,并一直存在,永远是功能最新最全的分支,包含所有要发布 到下一个 release 的代码,主要用于合并其他分支,比如 feature 分支; 如果修改代码,新建 feature 分支修改完再合并到 develop 分支。所有的 feature、release 分支都是从 develop 分支上拉的。
10.3feature分支
这个分支主要是用来开发新的功能,一旦开发完成,通过测试没问题(这个测试,测试新功能没问题),我们合并回develop 分支进入下一个 release
10.4release分支
用于发布准备的专门分支。当开发进行到一定程度,或者说快到了既定的发布日,可以发布时,建立一个 release 分支并指定版本号(可以在 finish 的时候添加)。开发人员可以对 release 分支上的代码进行集中测试和修改bug。(这个测试,测试新功能与已有的功能是否有冲突,兼容性)全部完成经过测试没有问题后,将 release 分支上的代码合并到 master 分支和 develop 分支
10.5hotfix 分支
用于修复线上代码的bug。**从 master 分支上拉。**完成 hotfix 后,打上 tag 我们合并回 master 和 develop 分支。
10.6GitFlow主要工作流程
1.初始化项目为gitflow , 默认创建master分支 , 然后从master拉取第一个develop分支 2.从develop拉取feature分支进行编码开发(多个开发人员拉取多个feature同时进行并行开发 , 互不影响) 3.feature分支完成后 , 合并到develop(不推送 , feature功能完成还未提测 , 推送后会影响其他功能分支的开发);合并feature到develop , 可以选择删除当前feature , 也可以不删除。但当前feature就不可更改了,必须从release分支继续编码修改 4.从develop拉取release分支进行提测 , 提测过程中在release分支上修改BUG 5.release分支上线后 , 合并release分支到develop/master并推送;合并之后,可选删除当前release分支,若不删除,则当前release不可修改。线上有问题也必须从master拉取hotfix分支进行修改; 6.上线之后若发现线上BUG , 从master拉取hotfix进行BUG修改; 7.hotfix通过测试上线后,合并hotfix分支到develop/master并推送;合并之后,可选删除当前hotfix ,若不删除,则当前hotfix不可修改,若补丁未修复,需要从master拉取新的hotfix继续修改; 8.当进行一个feature时 , 若develop分支有变动 , 如其他开发人员完成功能并上线 , 则需要将完成的功能合并到自己分支上,即合并develop到当前feature分支; 9.当进行一个release分支时 , 若develop分支有变动 , 如其他开发人员完成功能并上线 , 则需要将完成的功能合并到自己分支上,即合并develop到当前release分支 (!!! 因为当前release分支通过测试后会发布到线上 , 如果不合并最新的develop分支 , 就会发生丢代码的情况); GitFlow的好处:为不同的分支分配一个明确的角色,并定义分支之间如何交互以及什么时间交互;可以帮助大型项目理清分支之间的关系,简化分支的复杂度。
11.使用过git cherry-pick,有什么作用?
命令git cherry-pick可以把branch A的commit复制到branch B上。 在branch B上进行命令操作: - 复制单个提交:git cherry-pick commitId - 复制多个提交:git cherry-pick commitId1…commitId3 注意:复制多个提交的命令不包含commitId1.
12.git跟其他版本控制器有啥区别?
GIT是分布式版本控制系统,其他类似于SVN是集中式版本控制系统。 分布式区别于集中式在于:每个节点的地位都是平等,拥有自己的版本库,在没有网络的情况下,对工作空间内代码的修改可以提交到本地仓库,此时的本地仓库相当于集中式的远程仓库,可以基于本地仓库进行提交、撤销等常规操作,从而方便日常开发。
13.如何把本地仓库的内容推向一个空的远程仓库?
- git remote add origin XXXX - git push -u origin master - git push origin master
14.常用命令补充
1.生成密钥:ssh-keygen 2.git init在当前目录下创建一个本地仓库 3.git push -u origin master
15.git分支操作,问什么要做git分支
十五、项目阐述
1.二手交易平台
2.自动化测试平台
3.高校团委学生会管理系统

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)