pyspark——泰坦尼克生存预测
文章目录1、使用pyspark对数据集标签分布情况进行分析;Survived分布Pclass分布SibSp分布Parch分布Fare分布Embarked分布Cabin分布2、使用pyspark对数据特征分布进行分析,并清洗数据中的缺失值、错误值和异常值;PassengerIDPclassNameSexSibSpParchFareAge(数据补全)TicketCabinEmbarked3、使用pys
·
文章目录
1、使用pyspark对数据集标签分布情况进行分析;
- 总共有如下几种标签

- 排除一一对应的PassengerID,Ticket票号剩余的一一对齐分布进行分析
Survived分布
- 是否幸存,1表示幸存,0表示死亡
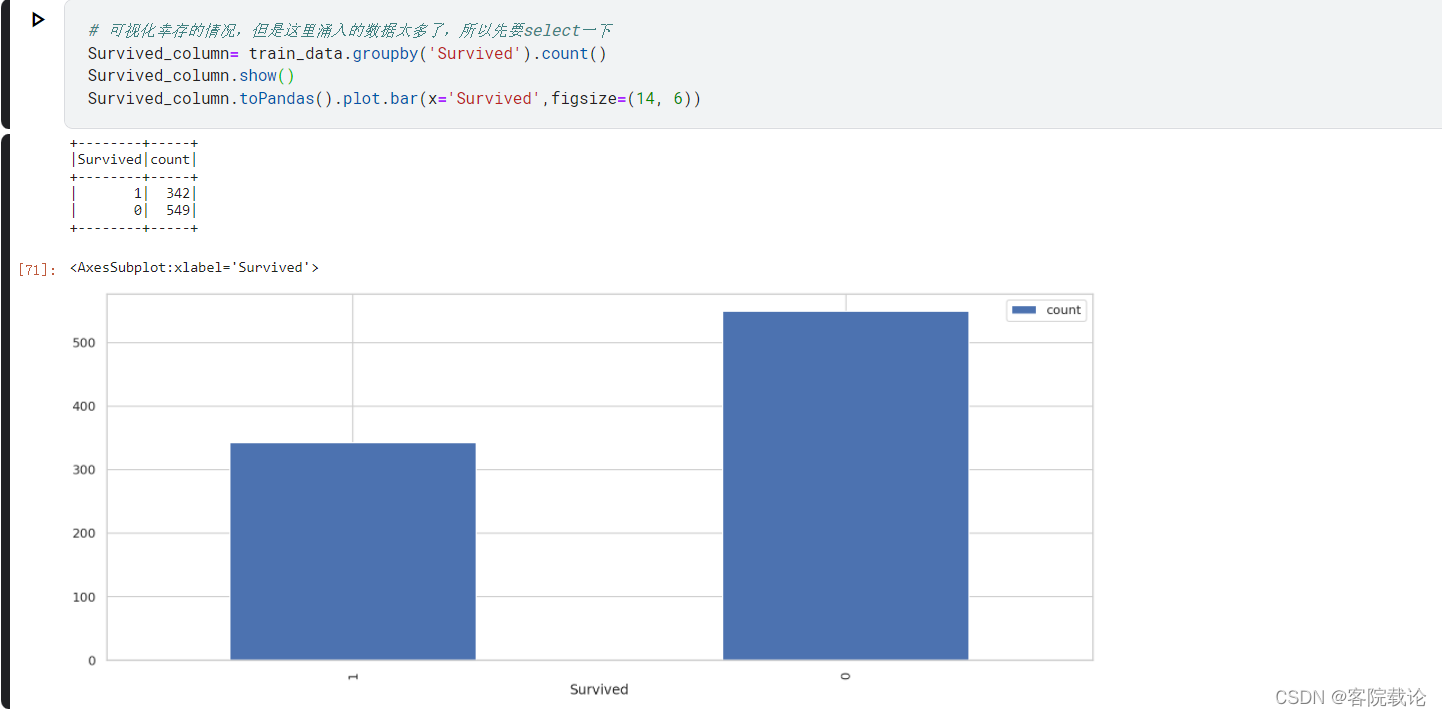
- 大部分都死了,少部分人活下来了
Pclass分布
- 船舱等级,1最好,2次之,3最后
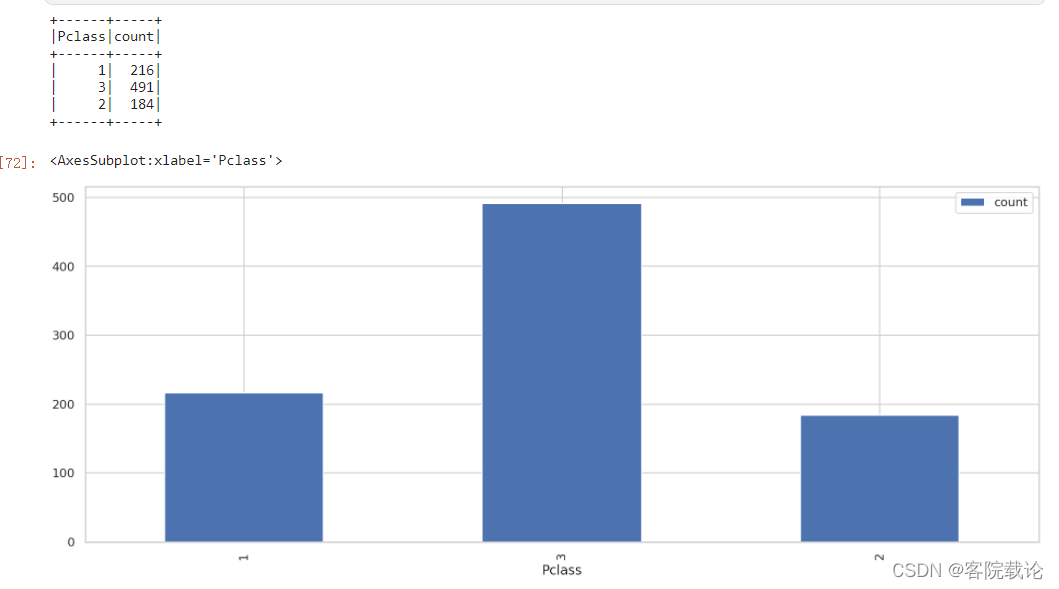
- 大部分都是二等舱的人
SibSp分布
- 该名乘客上船后,与其一起同行上船的兄弟姐妹的个数
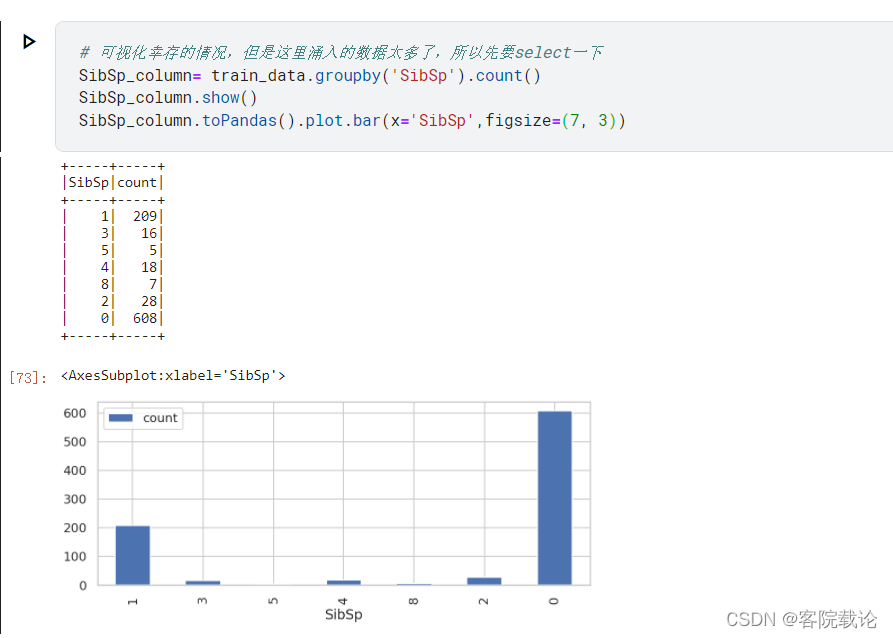
- 一般都是单身去的
Parch分布
- 该名乘客上船后,与其一起同行上船的家里的老人与孩子的个数
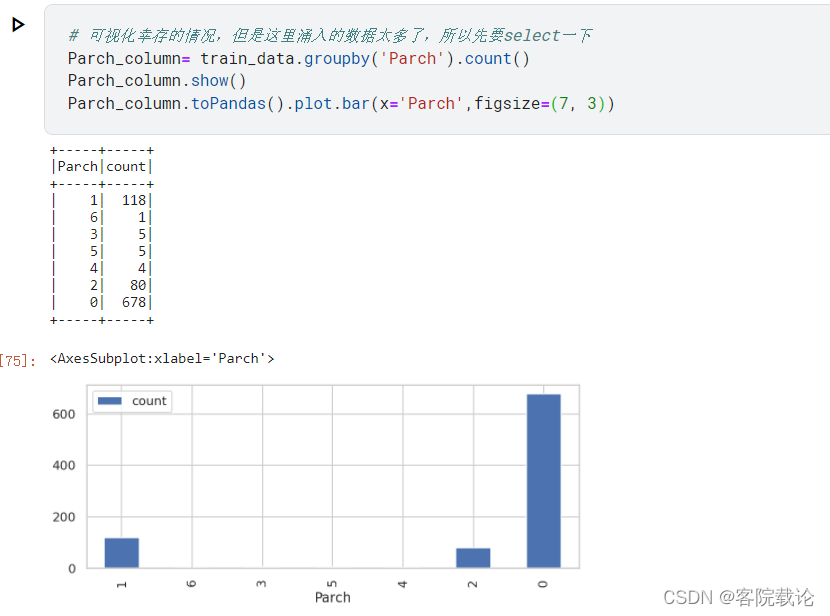
Fare分布
- 船票价格
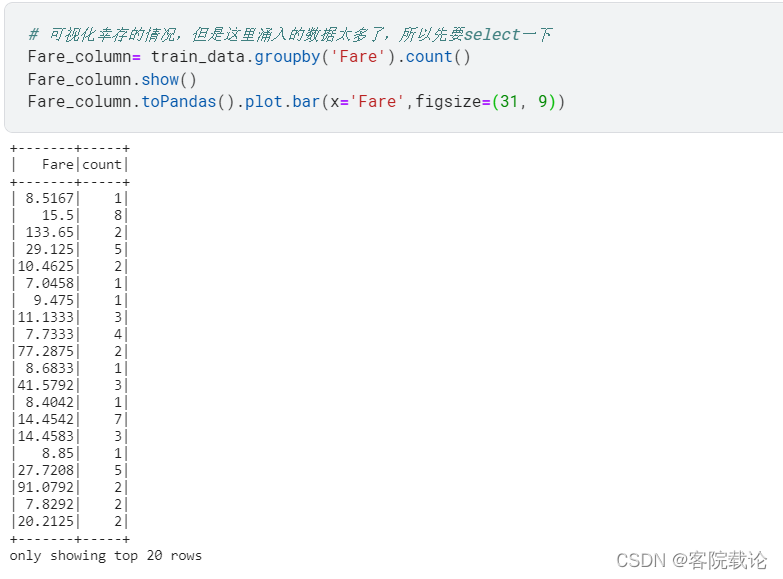
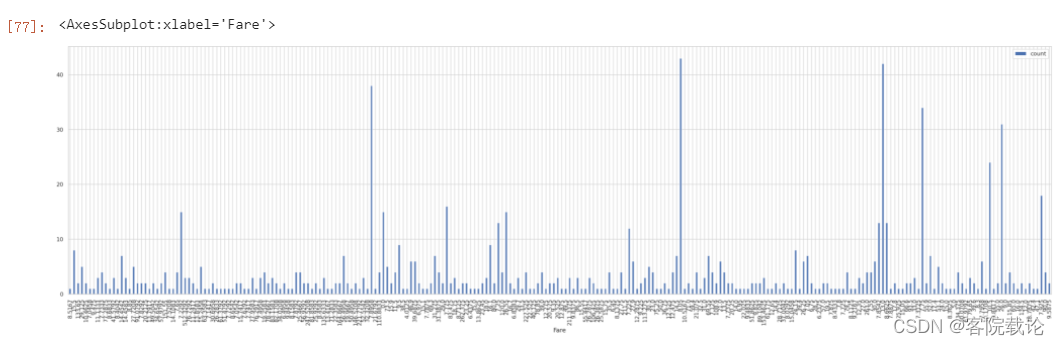
- 船票分布不是正态分布,而且分布的太开了,当然也有可能我的数据不是按照一定的顺序进行排序的。处理之后在画图,下图是按照价格升序排列之后的情况
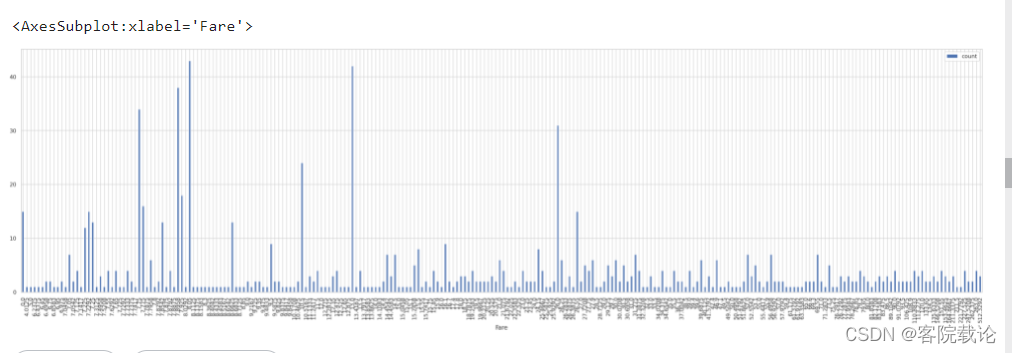
- 大部分人买的都是中低价
- 当然,船票的高低也就显示了一个人身份的高低
Embarked分布
- 该名乘客登船的码头,有三个:S、C、Q三个码头
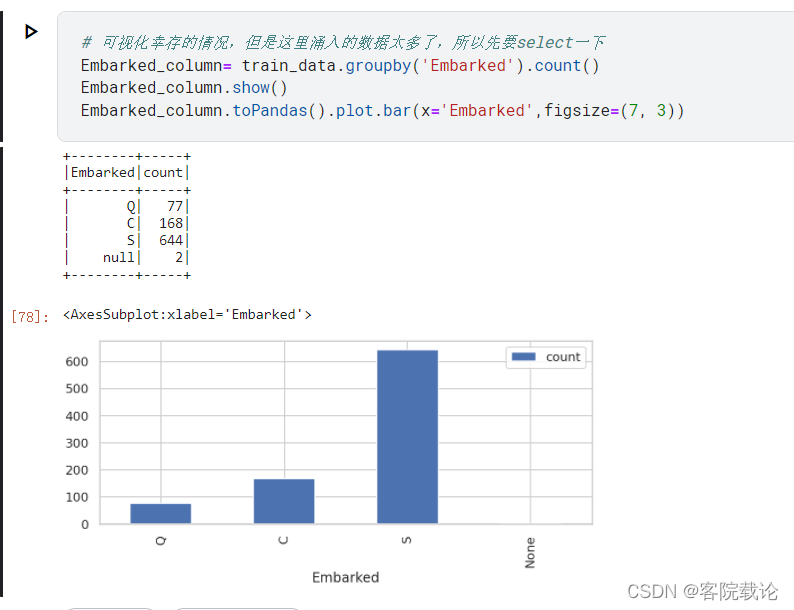
- 大部分人都是S口岸登陆的,当然登陆先后,做的位置可能会有不同,影响了逃生的顺序
Cabin分布
-
该名乘客所在船舱的编号
-
大部分人都是在一个船舱,都是none,说明这个数据是不具有参考性的,应该丢弃
2、使用pyspark对数据特征分布进行分析,并清洗数据中的缺失值、错误值和异常值;
- 统计各个列为空的具体情况如下,有177名乘客是没有年龄信息的,687个乘客是没有所在船舱编号的,2名乘客所登陆的码头不是很清晰,下面开始逐个分析各个列单独对于存活率的影响。
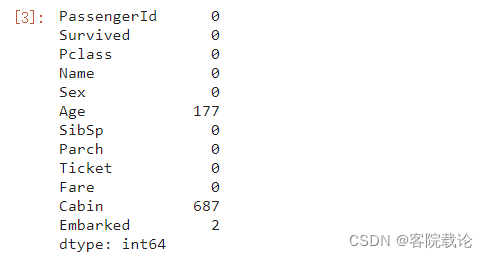
- 需要处理的字段为:
- 年龄Age
- 船舱Cabin
- Embarked登陆港口
PassengerID
- 记录乘客的Id编号。经过了解后:
- 并没有查到其构成具有特别的实际意义(如身份证的构成每一位都是有实际意义的);
- 仅作为唯一标识来定位到某一乘客身上(唯一值同总数据量一样);
- 因此认为不具有分析的价值,过后也会将它进行删除处理。并没有对其进行分析
Pclass
- 描述用户所属的等级,总共分为三等,用1、2、3来描述,其中:
- 1 - 1st class,高等用户;
- 2 - 2nd class,中等用户;
- 3 - 3rd class,低等用户;
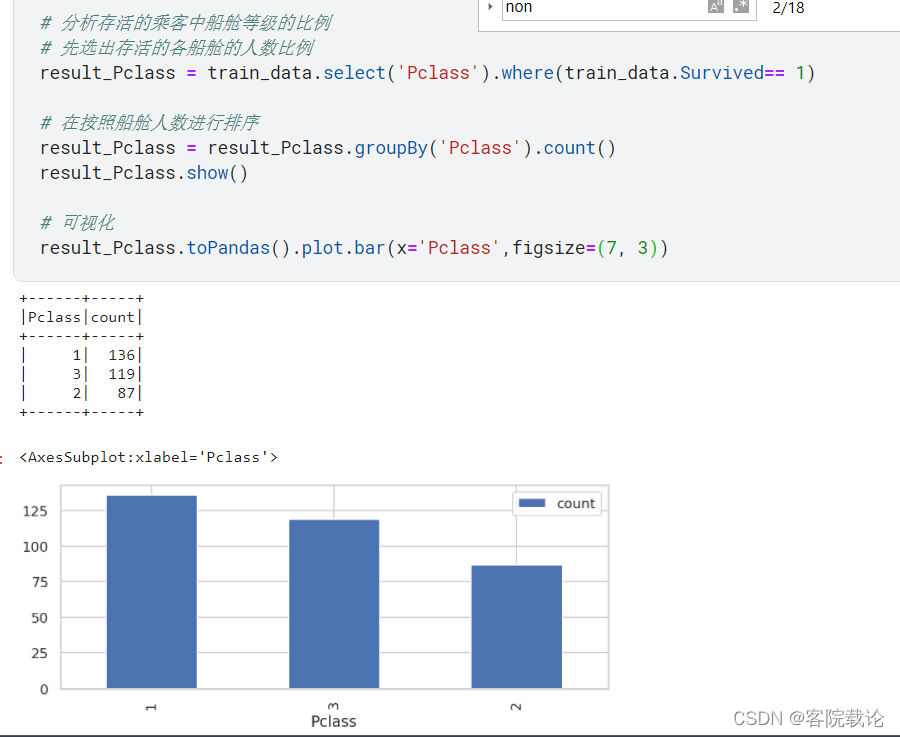
- 根据分析可得,高等用户的存活率更高,低等用户的存活率更低,前虽然不能啥都干成,但是能够提高存活率是真的
Name
- 描述乘客的全名。例如上例中的 Rugg, Miss. Emily 中:
- Rugg :first name,即名;
- Miss. :title,即称谓;
- Emily :last name,即姓
- 在登记乘客姓名时全都是用这种方法进行记录的;
Sex
描述乘客的性别,其中:
* male - 男性;
* female - 女性;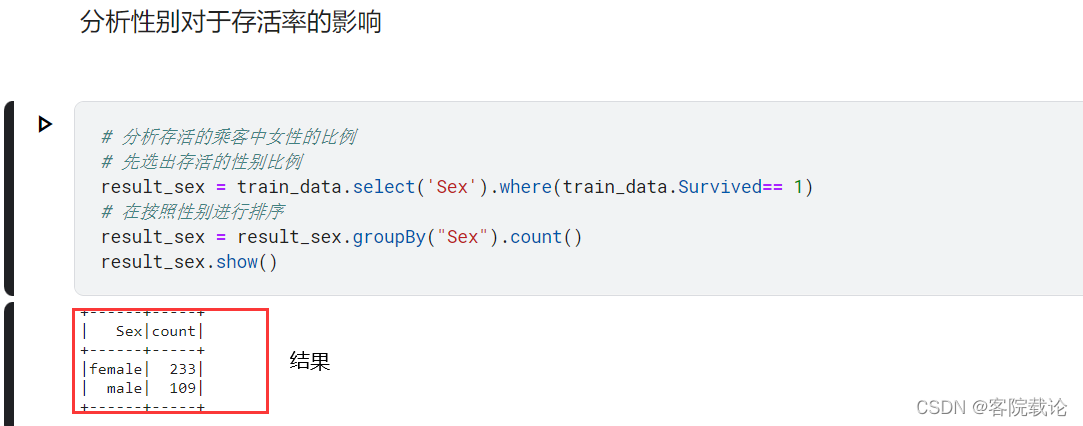
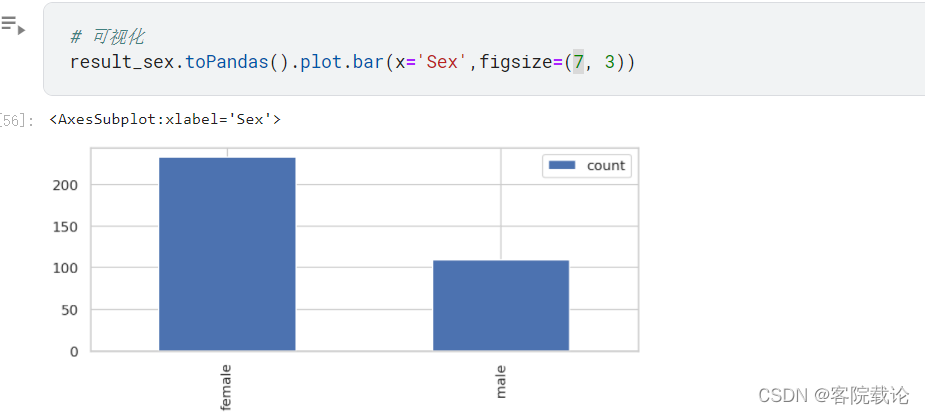
- 根据图片,可得,女性的存活率是远远高于男性的
SibSp
SibSp:描述了泰坦尼克号上与乘客同行的兄弟姐妹(Siblings)和配偶(Spouse)数目;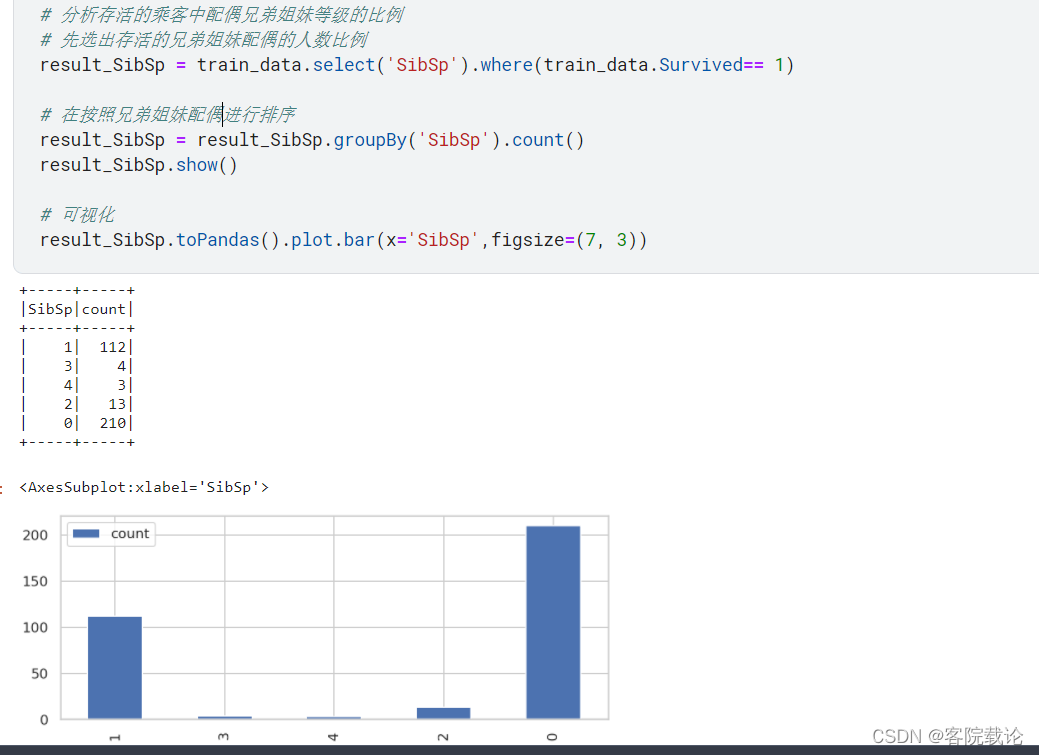
- 总结:随单身汉存活的数量比重较多,但是他的基数也多,对比原来的图像,我们很容易就发现,一个人去的死的最多,同时这也反映出阶级差距,也只有富人会拖家带口的坐一会邮轮。
Parch
Parch:描述了泰坦尼克号上与乘客同行的家长(Parents)和孩子(Children)数目;
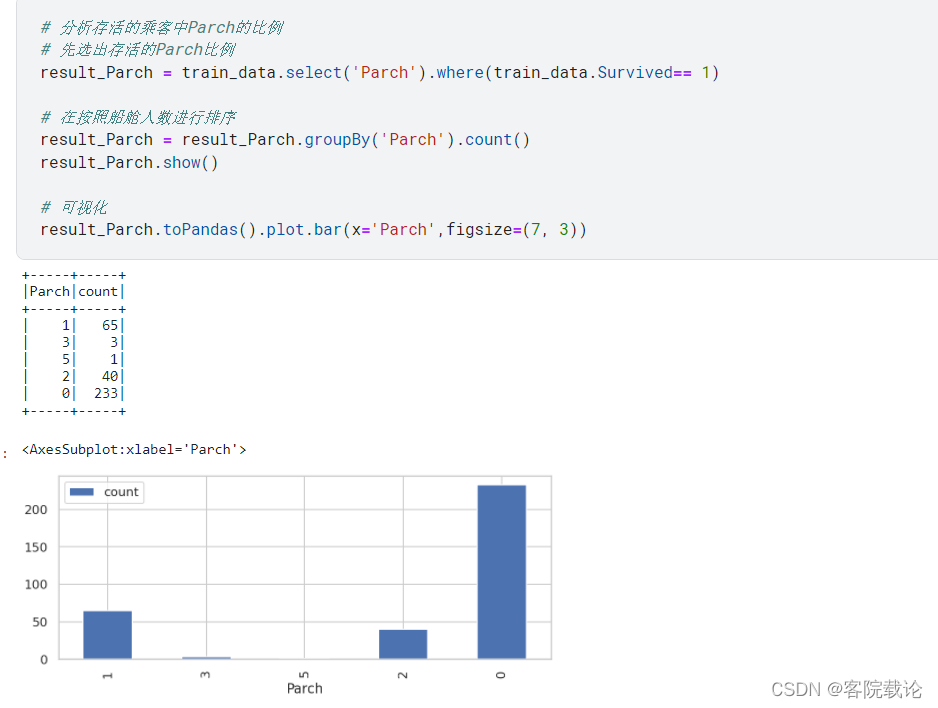
- 有后代的一般都是把升得机会让给了后代,自己选择死亡。比起登船的数据,有儿女的死亡的几率更大。
Fare
描述乘客上传所花费的费用;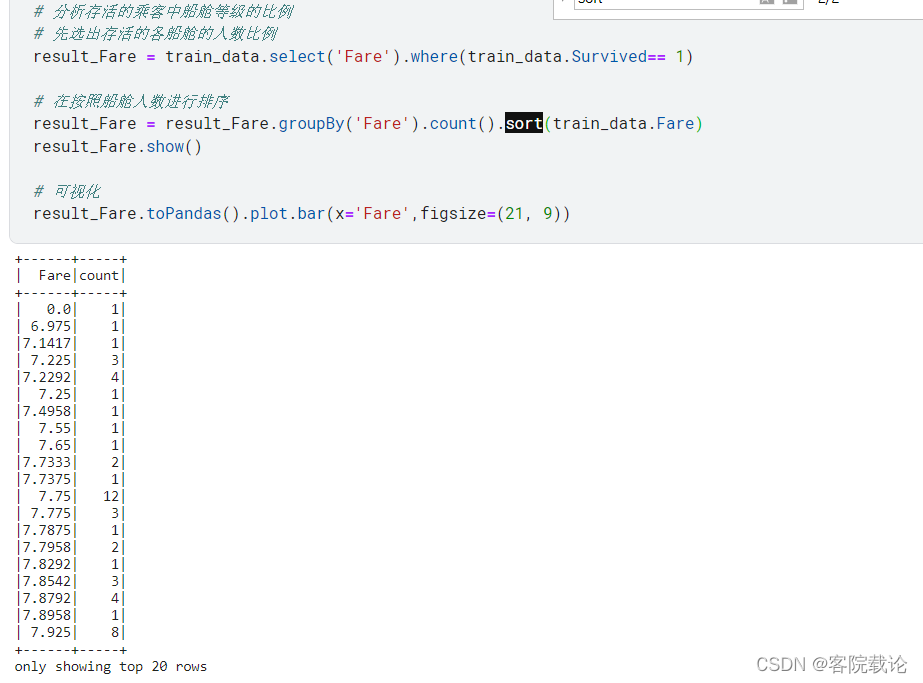
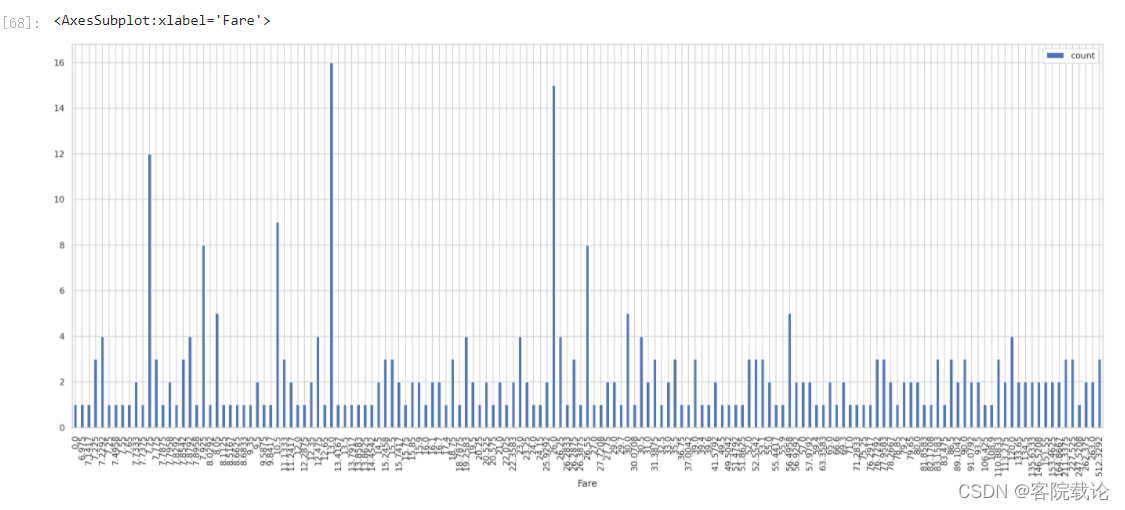
- 结论:和原来的数量比较之后,低价船票的死亡人数较多,高价船票的死亡人数较少
Age(数据补全)
描述乘客的年龄,其中有部分缺失值,需要用一些手段将她们补全,具体的方法方在下面数据清洗中;
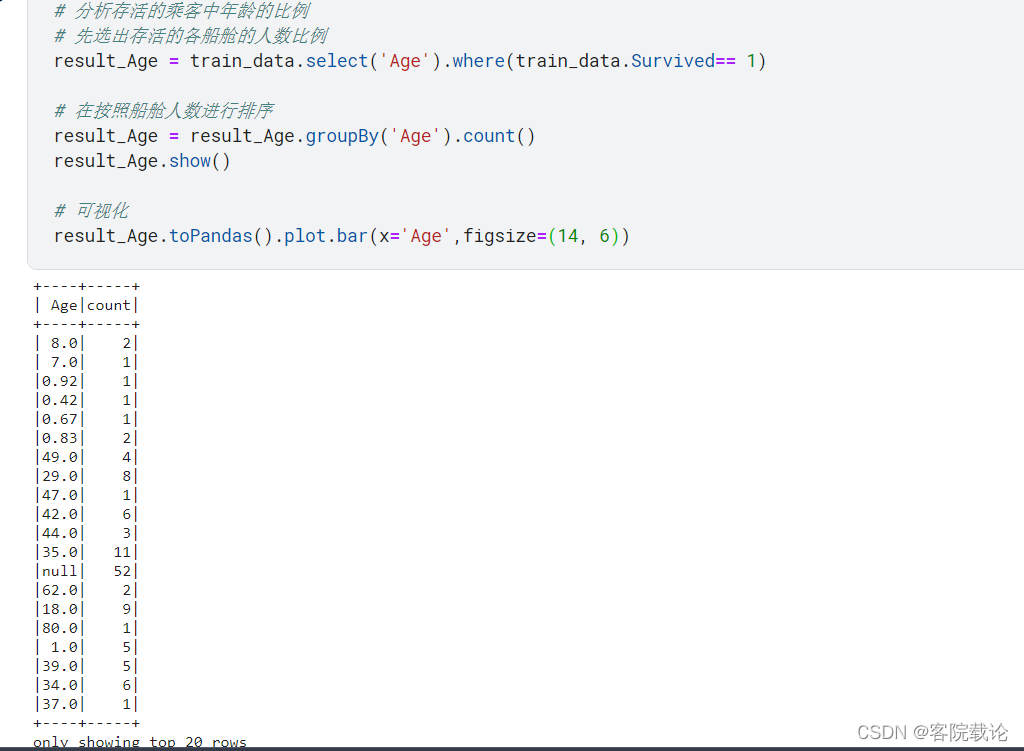
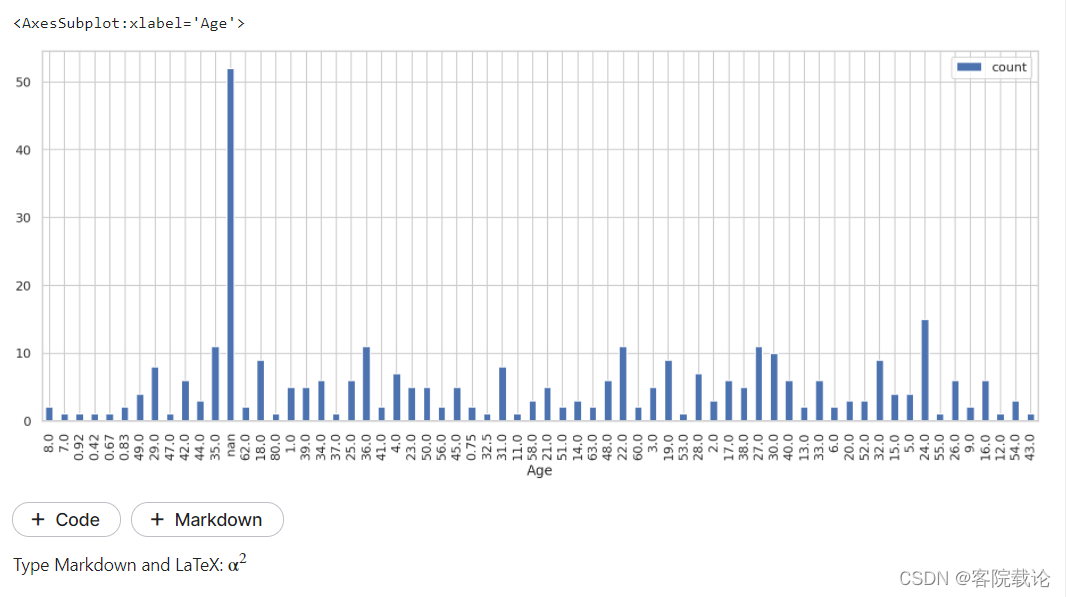
- 由于年龄和称谓是密切相关的,所以根据年龄和姓名的一一对应性,所以根据姓名补全年龄:

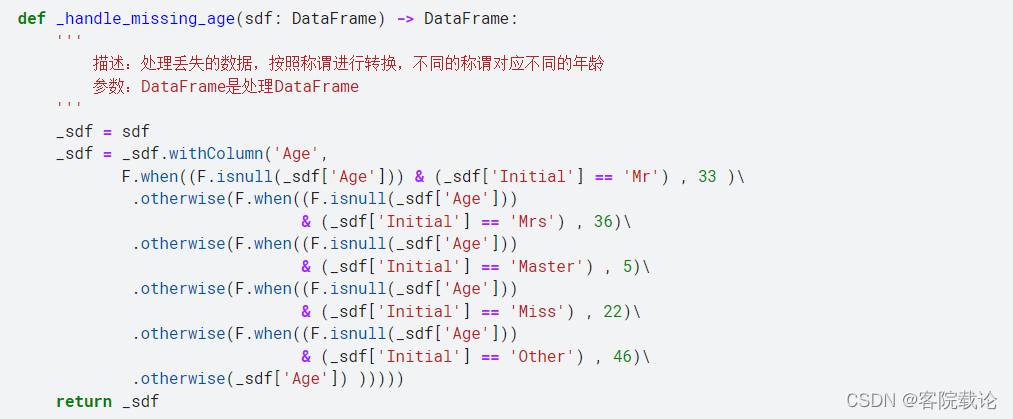
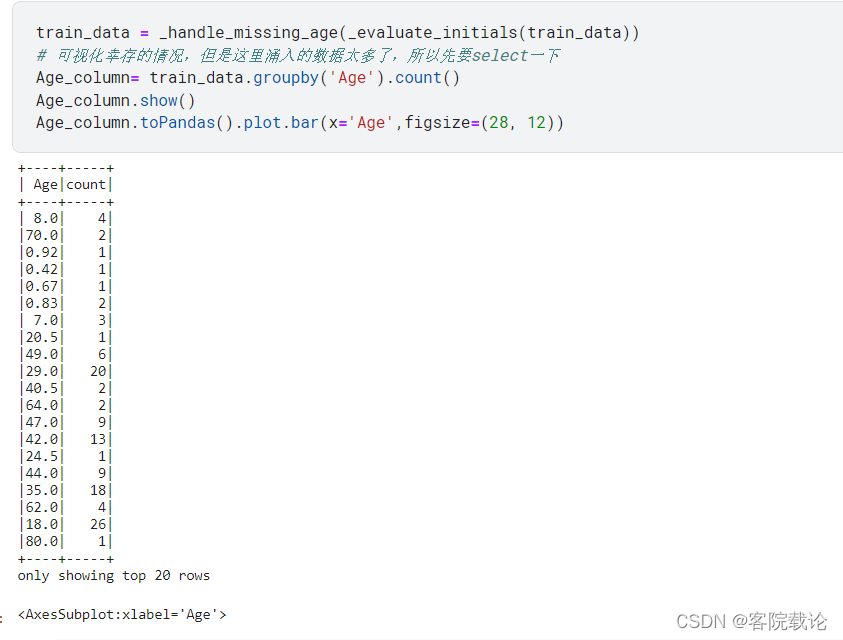
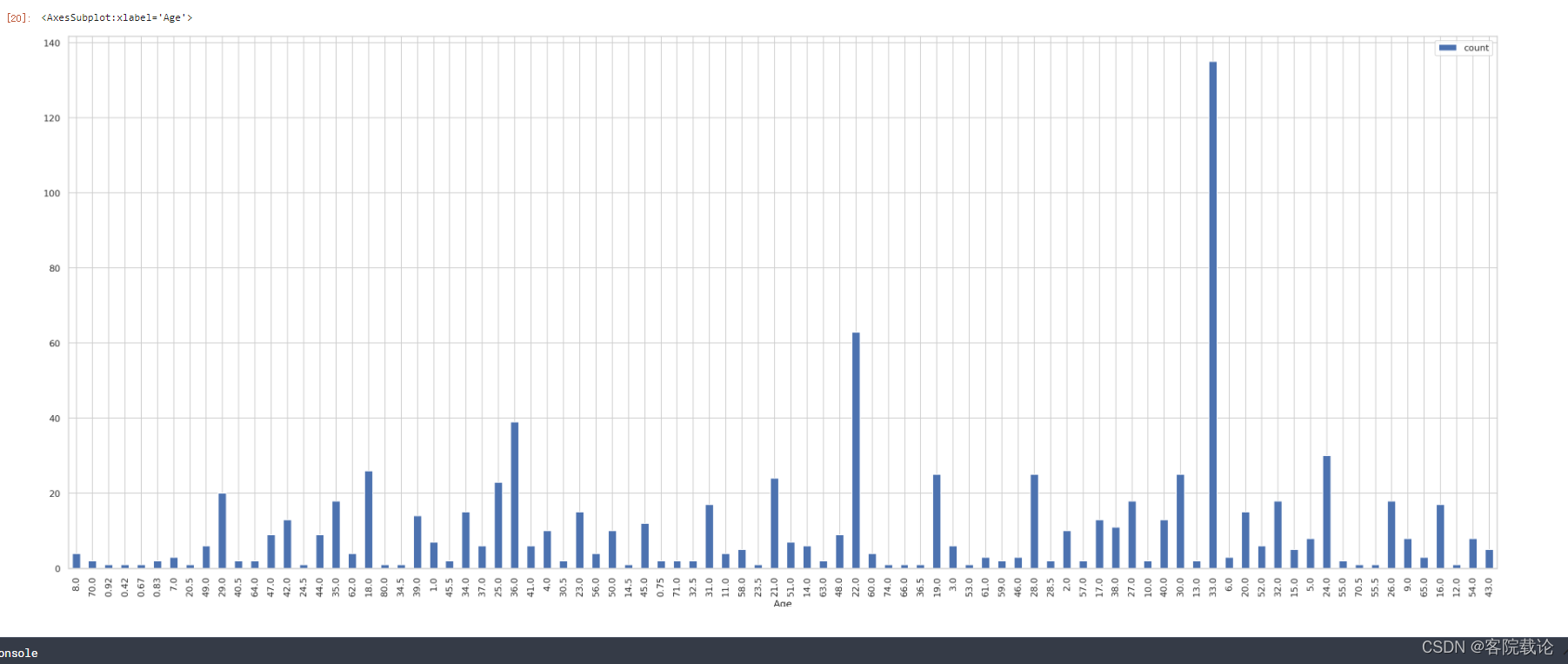
- 如上图,已经对Age中缺失的数据,根据称谓进行了补全
Ticket
- 描述乘客登船所使用的船票编号。虽然它没有编码上的规律,不存在缺失值,但是唯一值可以看到。故不作处理,同时将其删除,操作结果如下

Cabin
- 描述用户所住的船舱编号。由两部分组成,仓位号和房间编号,如C88中,C和88分别对应C仓位和88号房间。本字段缺失值较多
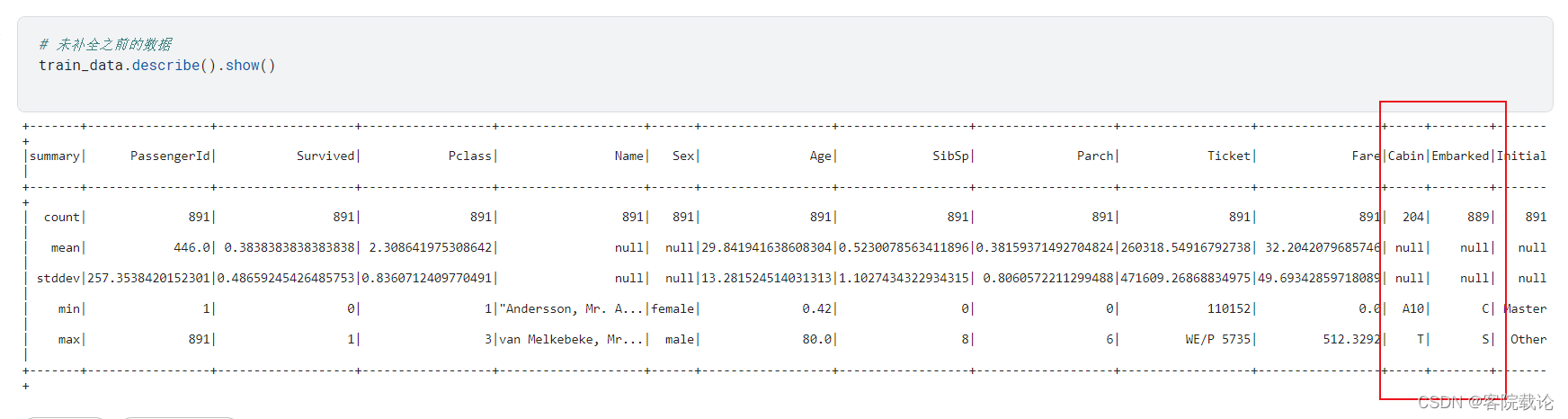
- 措施:针对Canbin数据,缺失太多了,已经对最终的生存旅没有任何影响,所以考虑将他删除,执行和结果如下

Embarked
- 描述乘客上船时的港口,包含三种类型:
- C:Cherbourg;
- Q:Queenstown;
- S:Southampton;
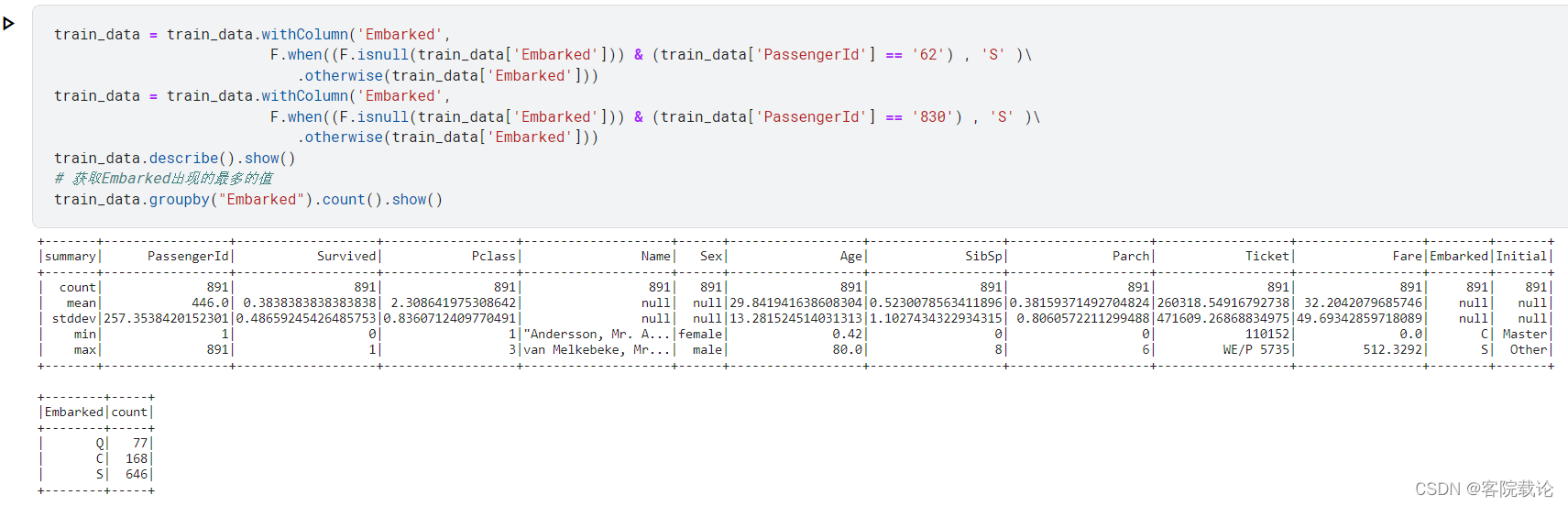
- 分析:Embarked登陆港口就缺失了少部分值,这里采用当前列的最多值也就是众数进行填充,执行的操作和结果如下。

- 获取embarked为空的用户信息如下.
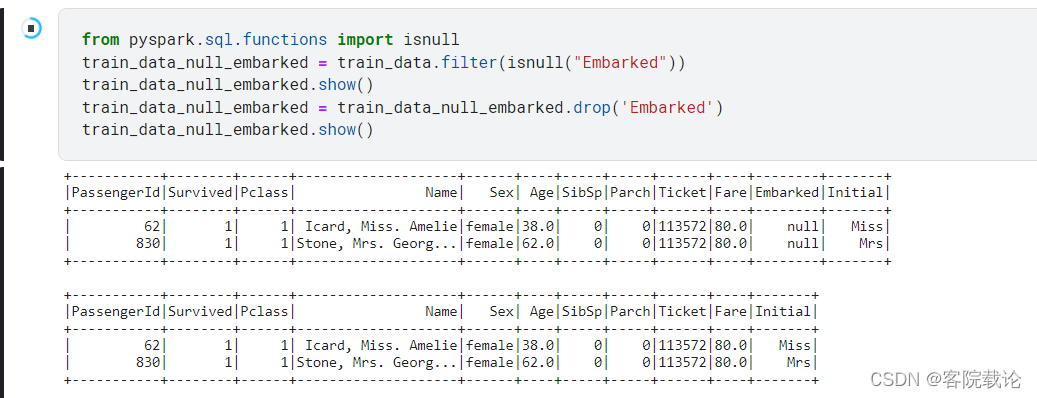
- 根据用户信息进行相关的修改,使用众数进行替换
增加新的特征,family_size
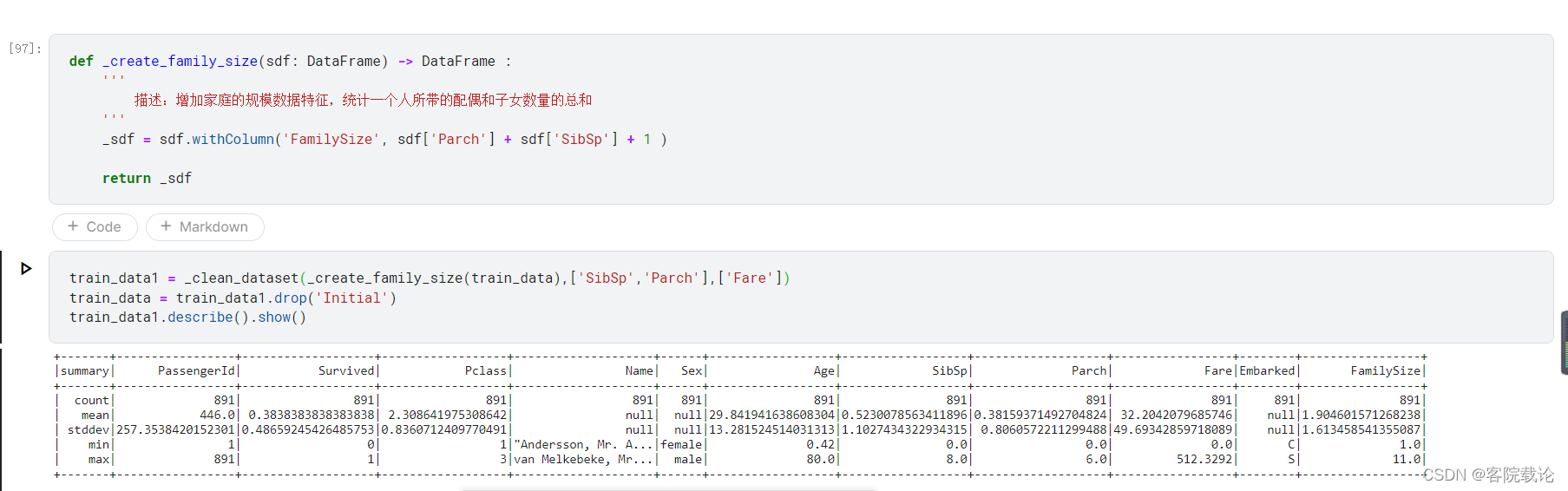
最终处理如下,所有数据都被补全了

3、使用pyspark提取文本数据的TF-IDF特征;
- TF-IDF:是文本挖掘中广泛使用的一种特征化的向量化方法,反映了一个词语在语料库中的对文档的重要性。词频TF(t,d)表示词语t在文档d中出现的次数;文档频率DF(t,D)是包含词语t的文档数量。如果我们只使用词语的频率来衡量重要性,很容易过分强调那些经常出现但很少包含文档信息的词语。如经常出现的 ‘的’‘了’‘我’ 等并不包含关于特定文档的特殊信息。IDF是一个词语提供多少信息的数值度量。
- 上述信息来自知乎
- 我们当前的数据集并不涉及文本信息,每一个信息都比较重要,不存在大量的重复信息,所以不用提取文本数据的TF-IDF特征
4、使用sklearn将数据集分割为训练集与测试集;
- 虽然当前题目已经给出了train.csv文件和test.csv文件,但是test文件中并没有给出对应生存结果,所以直接对train数据进行的分类和学习
将性别进行编码
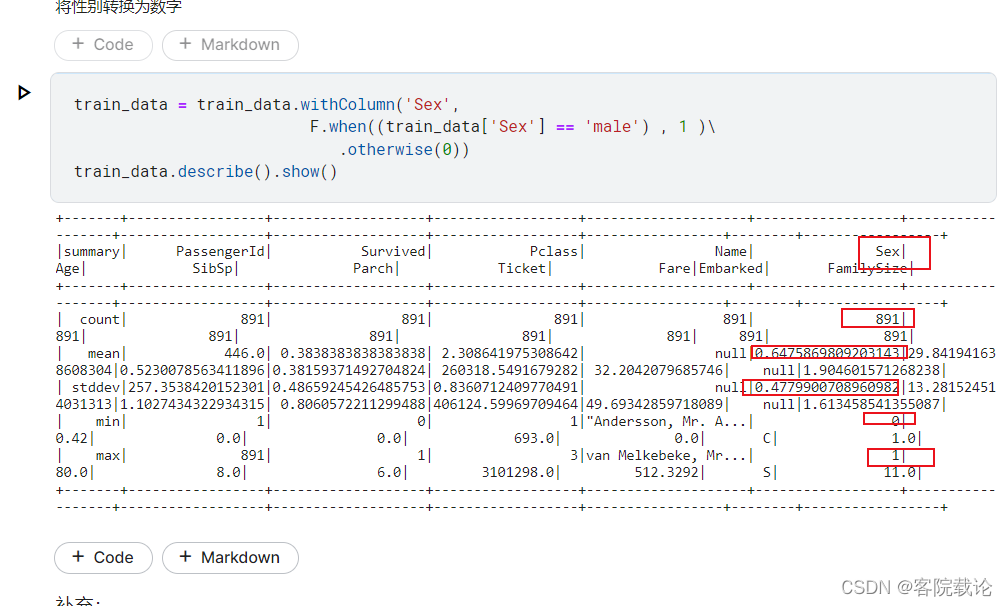
将Embarked进行编码
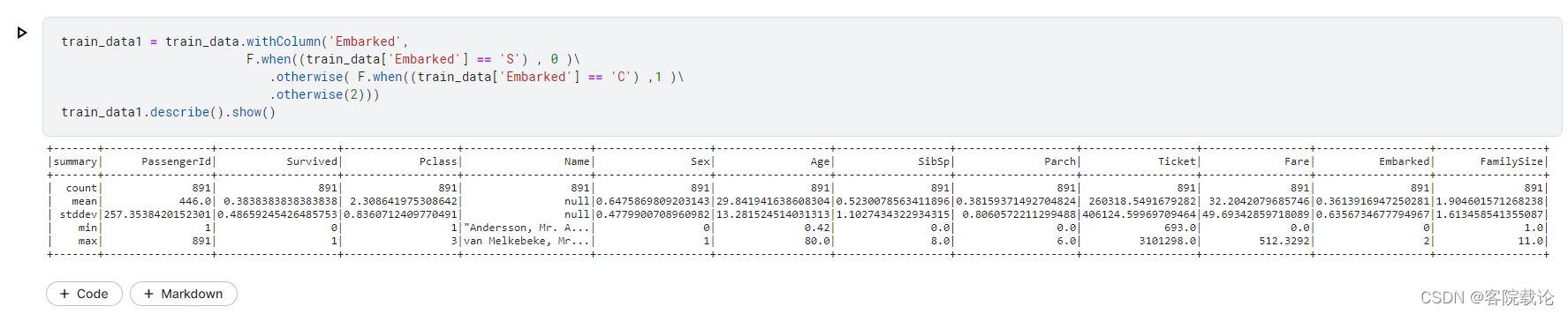
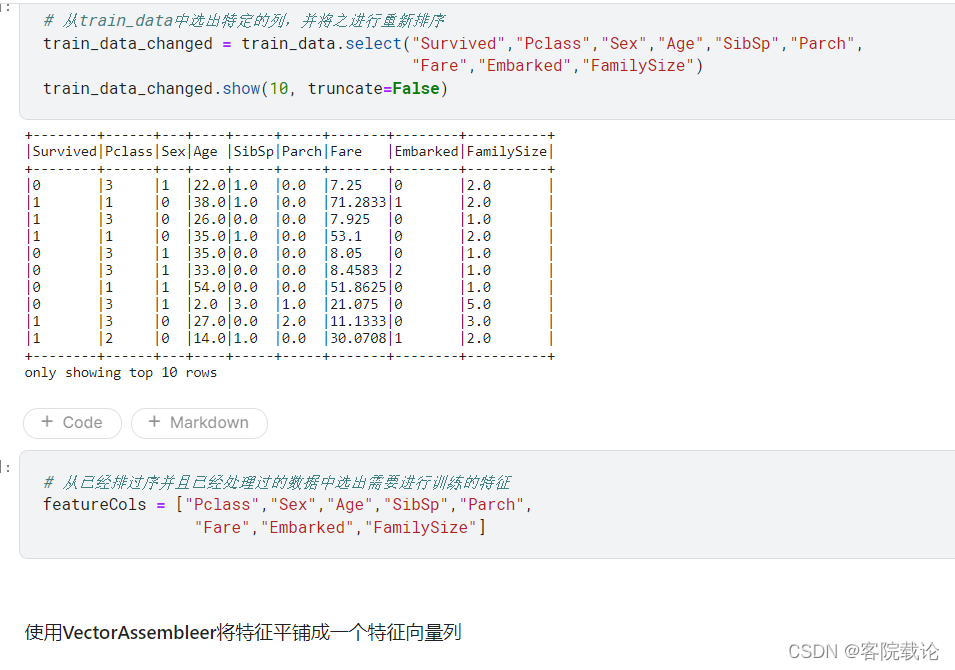
对特征进行排序并对其进行选择
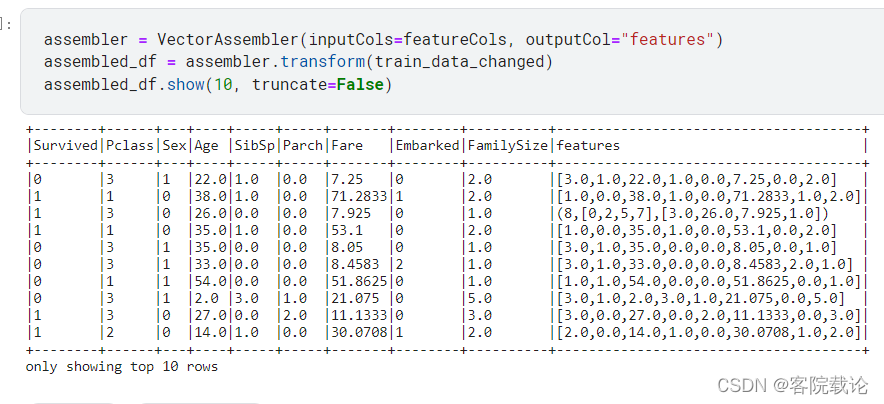
分割测试集和训练集
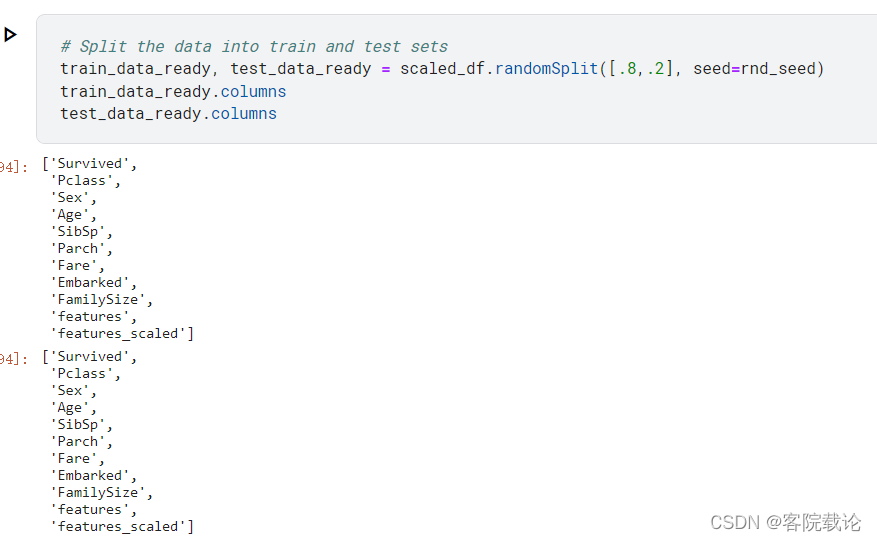
5、使用pyspark中任意一个有监督学习算法在训练集上训练机器学习模型;
- 使用线性回归学习有监督的学习,不过我觉得这个应该使用分类相关的算法进行学习
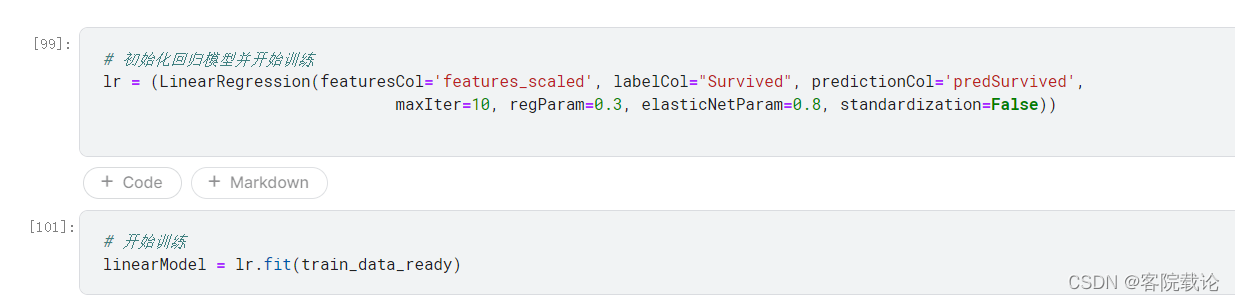
- 线性回归的系数和截距
6、使用训练好的机器学习模型预测测试集样本的分类或回归值;
- 分析:由于我使用的是回归解决的,所以是否存活就转变为概率问题,如果概率值低于0.5默认无法存货,如果概率值高于0.5,默认是存活的
- 注意:根据实际情况,由不同的变化,你可以选择0.5或者0.5以上的一个数字来决定
将概率转化为0和1的存活问题
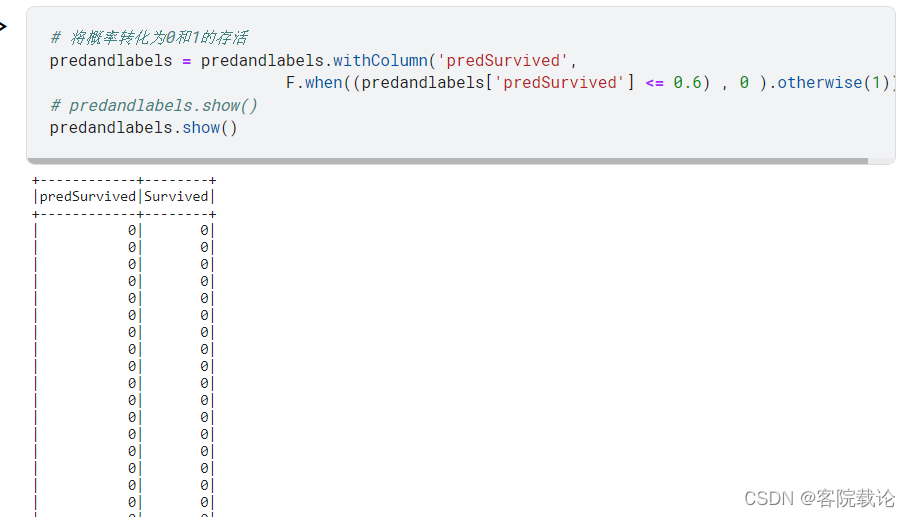
- 预测结果如下,展示一下同体的数据情况,发现概率为0.6的话,全部死亡了,所以调低概率
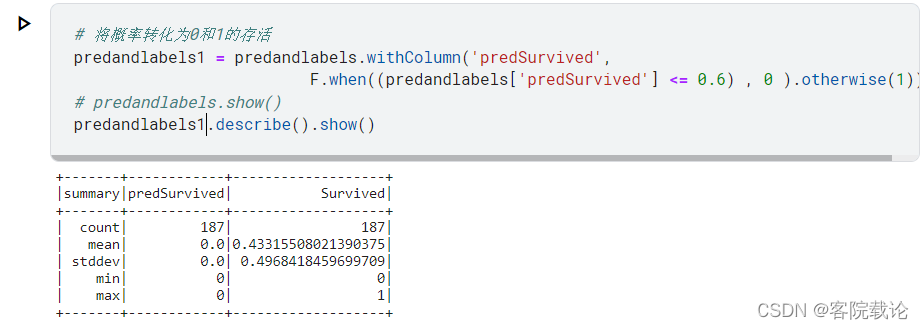
-
将概率跳到0.4,还是全死
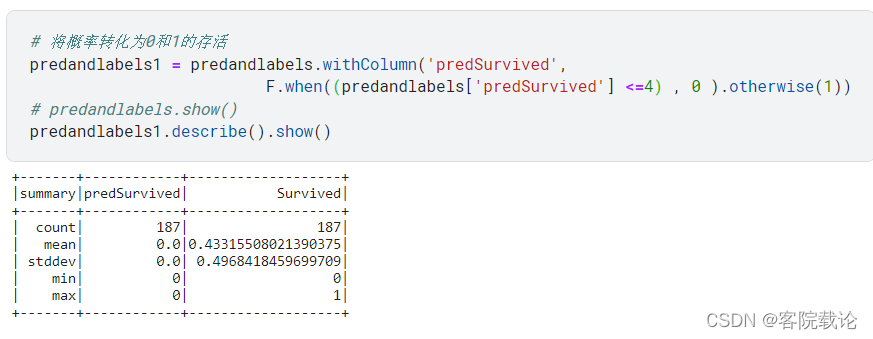
-
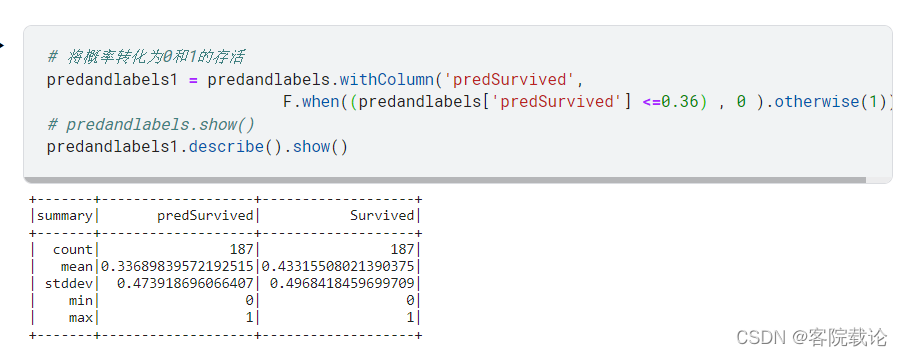
将概率跳到0.34发现存活率很高,并且也原来的数据很贴近
7、使用sklearn计算分类准确率(分类问题)或者R方(回归问题)。
计算R方(因为是使用回归问题做的分类问题)
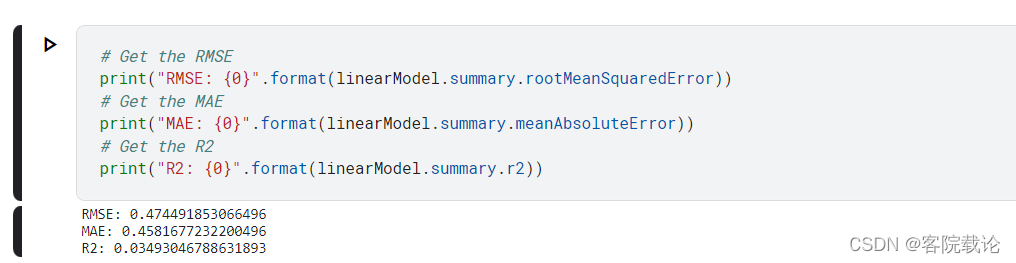
- 总结,在这里是将分类问题当作回归问题来做,很明显效果很差,R2越高,则显示结果越准确。MAE越低则结果越准确,在这里都是比较大的。现在开始计算准确率。不过这个也是有问题的,毕竟我是0和1的分类,但是这里使用概率进行计算的,不合理,所以还是得看准确率1.
计算分类准确率
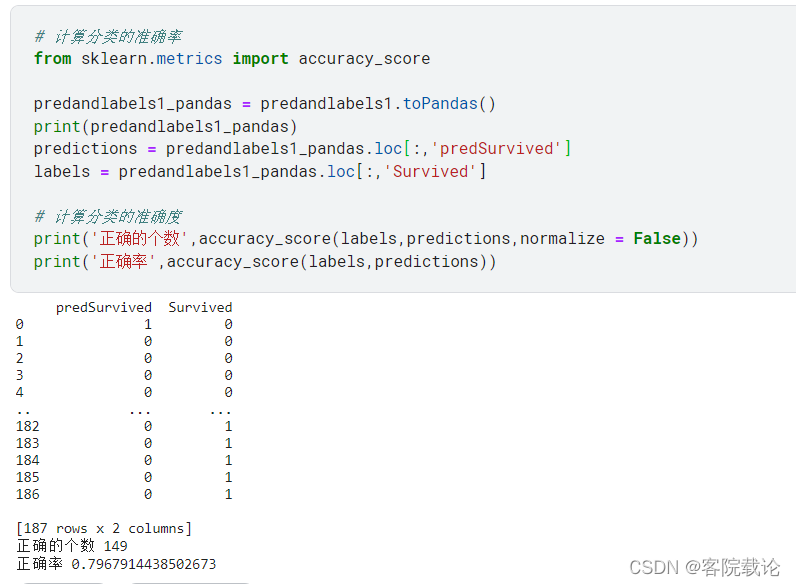
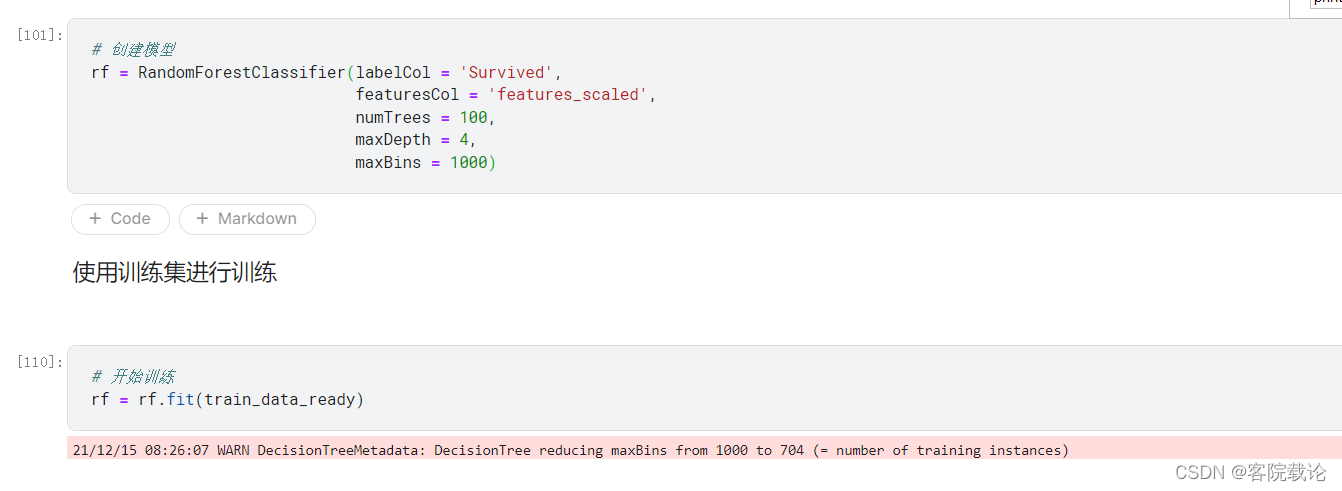
尝试使用单纯的分类问题解决分类分类问题(使用随机森林分类算法)
创建模型
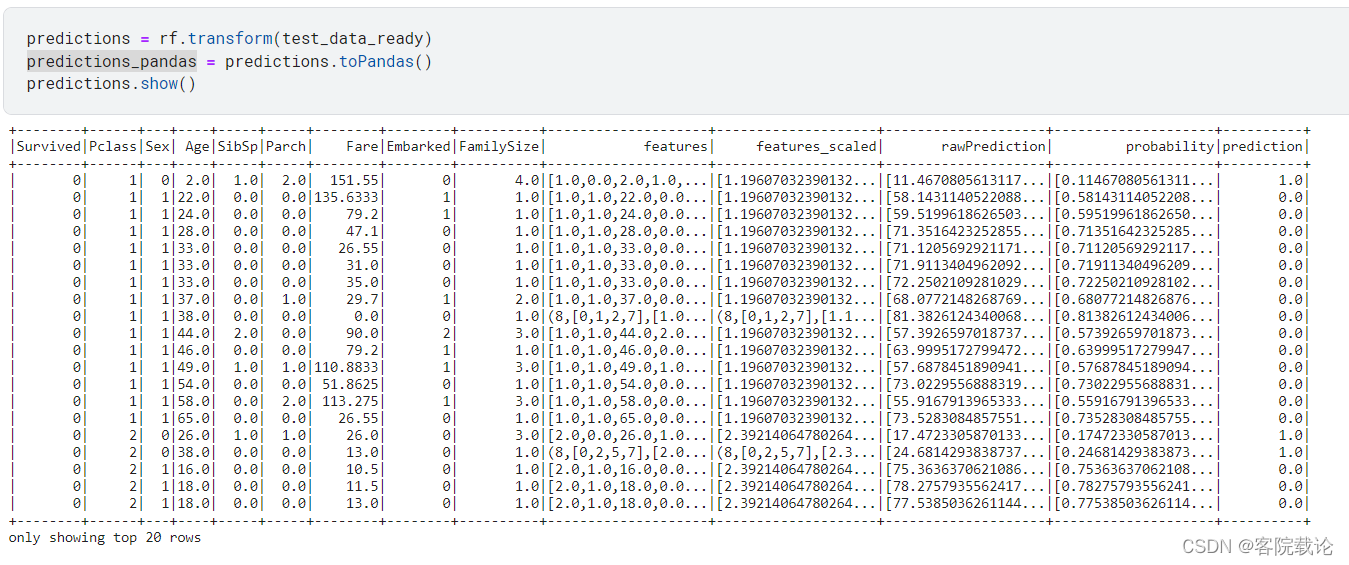
预测结果展示
计算准确率
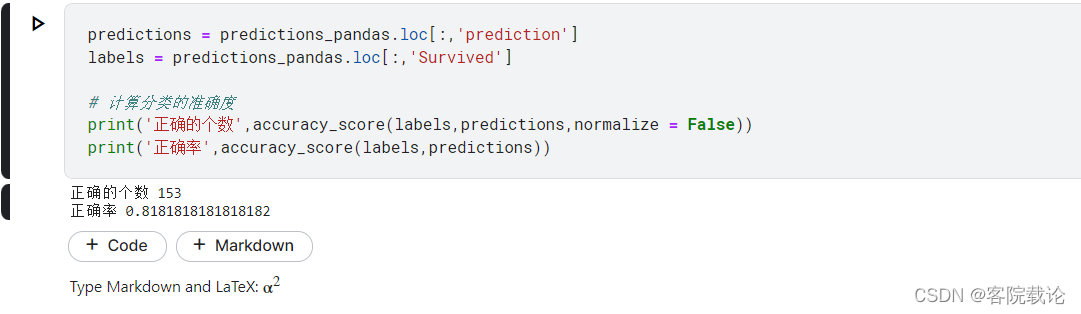
分析与总结
- 在处理好数据之后,使用了两种模型进行训练,一种是以回归的思路去解决的,根据最后生成的值进行判定,准确率有79%。另外一种使用的是分类问题的思路去解决得,准确度有81%。虽然差不多,但是如果当作回归问题去解决,还要人工手动的去识别最佳的概率判定界限。
- 第一次接触机器学习,发现大部分的时间都用在了数据分析和处理上,不过确实见识到了数据分析和处理的妙处。但是数据处理和分析还是需要很多的先验知识,比如说我就不知道英语里称谓和年龄之间的关系,这还是上网搜的。还是觉得深度学习比较香,不需要那么多的先验知识。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)