sparkSql排好序了,但写入库中发现无序,解决方法
场景描述:当我们使用sparkSql排好序了,但存入数据库中发现是乱序的,而且确定代码没有问题。原因:是因为我们使用了多核模式,而多核模式意味着多线程同时操作,所以即使你排好序了也没用解决方法:直接改成单核模式——local有些场景数据量大而且需要排序,我使用单核那效率也太低了吧!我既想用 local[*] 也想数据按我的规则排好,那么就可以在保存的时候使用repartition(1)完美解决此问
·
场景描述:当我们使用sparkSql排好序了,但存入数据库中发现是乱序的,而且确定代码没有问题。
原因:是因为我们使用了多核模式,而多核模式意味着多线程同时操作,所以即使你排好序了也没用
![]()
解决方法:直接改成单核模式——local
有些场景数据量大而且需要排序,我使用单核那效率也太低了吧!
我既想用 local[*] 也想数据按我的规则排好,那么就可以在保存的时候使用repartition(1)
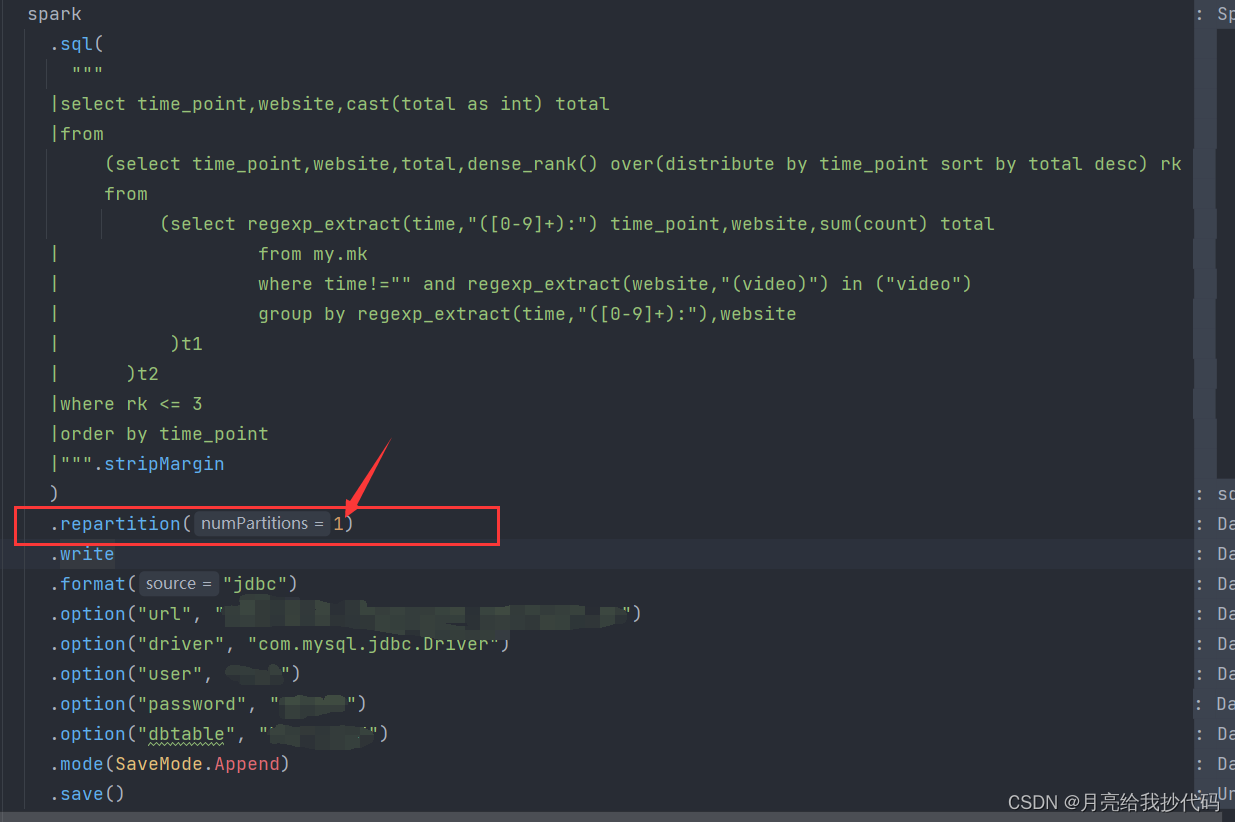
完美解决此问题~

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)