数据挖掘计算题-2
三、给定如表2所示的数据样本集,使用朴素贝叶斯算法对最后一个未知样本进行分类,请写出计算过程(保留小数点后三位)(共15分)计算过程:首先根据表画图有根据样例11的条件有(小数点保留后三位,忘了。。。反正过程就这样)计算过程:用样本ID7作为标点,对其他样本ID的属性进行距离运算:综上ID1、2、6为ID7的最近3个邻居∵1为no,2为yes,6为yes∴根据KNN算法,ID7为yes。五、给定如
三、给定如表2所示的数据样本集,使用朴素贝叶斯算法对最后一个未知样本进行分类,请写出计算过程(保留小数点后三位)(共15分)
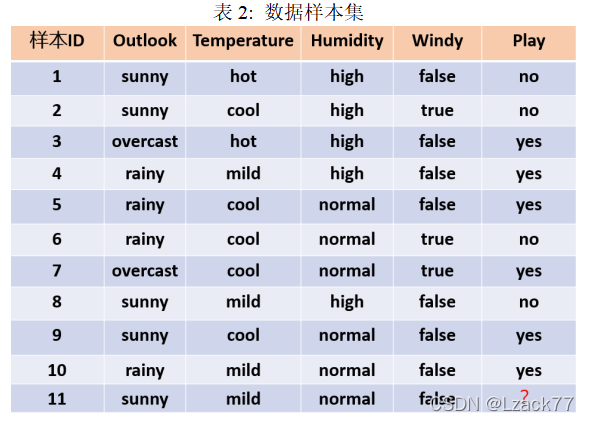
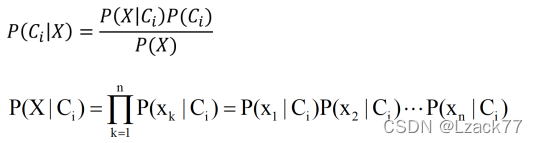
计算过程:
首先根据表画图有

根据样例11的条件有

(小数点保留后三位,忘了。。。反正过程就这样)
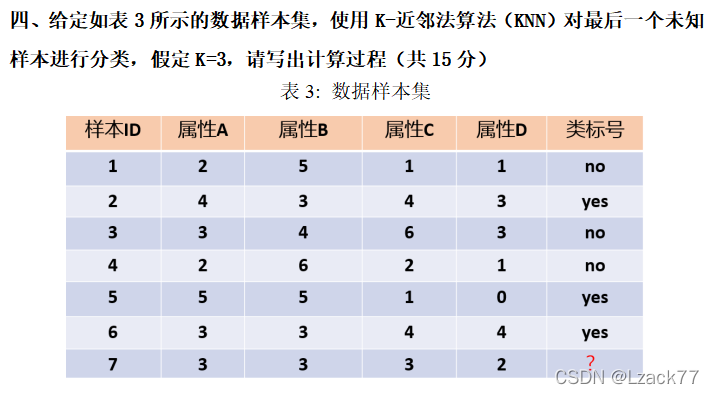
计算过程:
用样本ID7作为标点,对其他样本ID的属性进行距离运算:
综上ID1、2、6为ID7的最近3个邻居
∵1为no,2为yes,6为yes
∴根据KNN算法,ID7为yes。
五、给定如表4所示的数据样本集,使用K-means算法对样本进行聚类,设定类簇数目K=2,随机选择初始中心点对象为样本1和样本3,依据算法流程给出聚类过程(共15分)
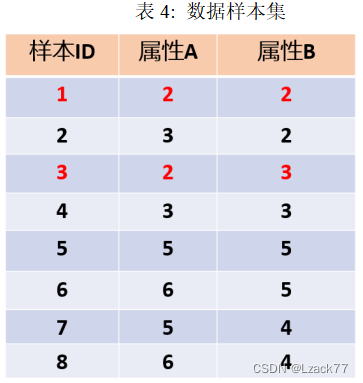
计算过程:
|
K |
D²(1.k) |
D²(3.k) |
|
2 |
1 |
2 |
|
4 |
2 |
1 |
|
5 |
18 |
13 |
|
6 |
25 |
20 |
|
7 |
13 |
10 |
|
8 |
20 |
17 |
分组1:{1,2}
分组2:{3,4,5,6,7,8}
分组1的数据中心(均值):(2.5,2) 设为C
分组2的数据中心(均值):(5,4) 设为D
以C(2.5,2)和D(5,4)作为新的数据点,同样的方法再次分组:
|
k |
D²(C.K) |
D²(D.K) |
|
1 |
√ |
|
|
2 |
√ |
|
|
3 |
√ |
|
|
4 |
√ |
|
|
5 |
√ |
|
|
6 |
√ |
|
|
7 |
√ |
|
|
8 |
√ |
分组1:(1,2,3,4)
分组2:(5,6,7,8)
重新选择数据中心(均值):C (2.5,2.5),D (5.5,4.5),再次进行分组
|
k |
D²(C.K) |
D²(D.K) |
|
1 |
√ |
|
|
2 |
√ |
|
|
3 |
√ |
|
|
4 |
√ |
|
|
5 |
√ |
|
|
6 |
√ |
|
|
7 |
√ |
|
|
8 |
√ |
∵分组结果不变
∴算法终止
最终分组结果为(第一组:1,2,3,4)(第二组:5,6,7,8)
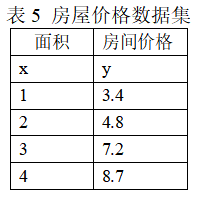
六、给定表5所示的某地房屋面积价格数据(20分)
(1)画出数据对应的散点图(2分);
(2)利用最小二乘法求出一元线性回归方程y=ax+b,并绘制在散点图上(9分);
(3)使用梯度下降法求解假定初始化(a, b)=(3.5, 3.5),学习率为0.02,写出下降3步的结果(9分)。
计算过程:
(1)
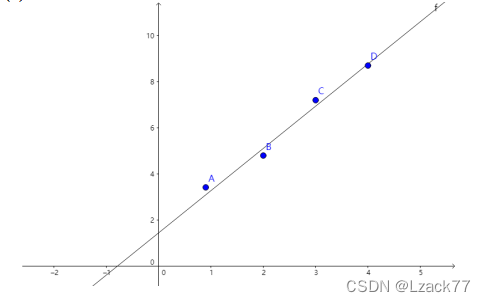
(2)

y = 1.83x+1.45
图像如上
PS:也可以直接套公式
![]()
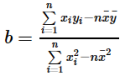
(3)
先来看两个例子:(转载https://blog.csdn.net/weixin 42278173)
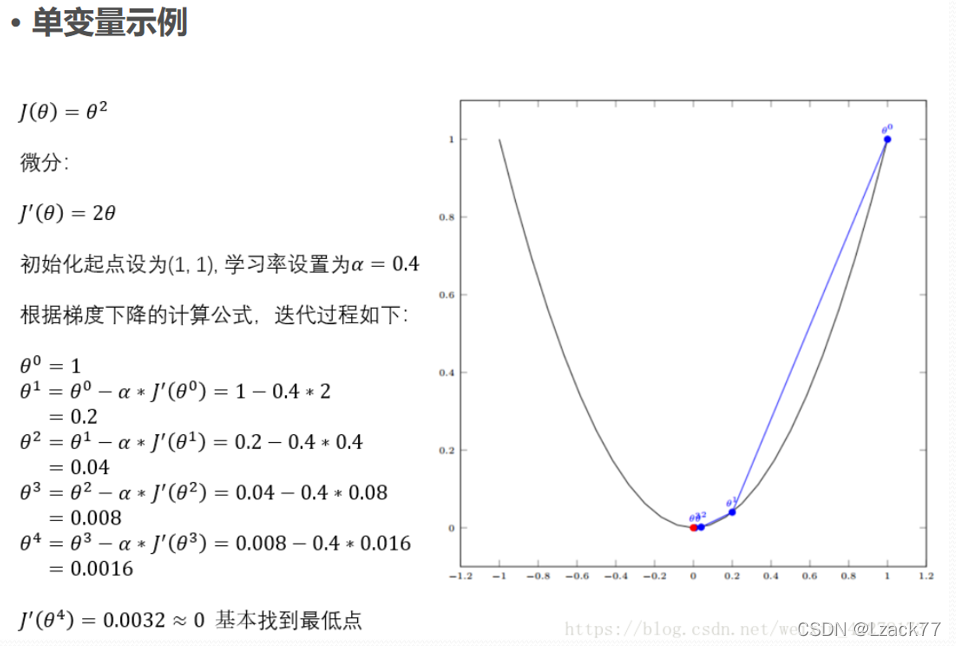
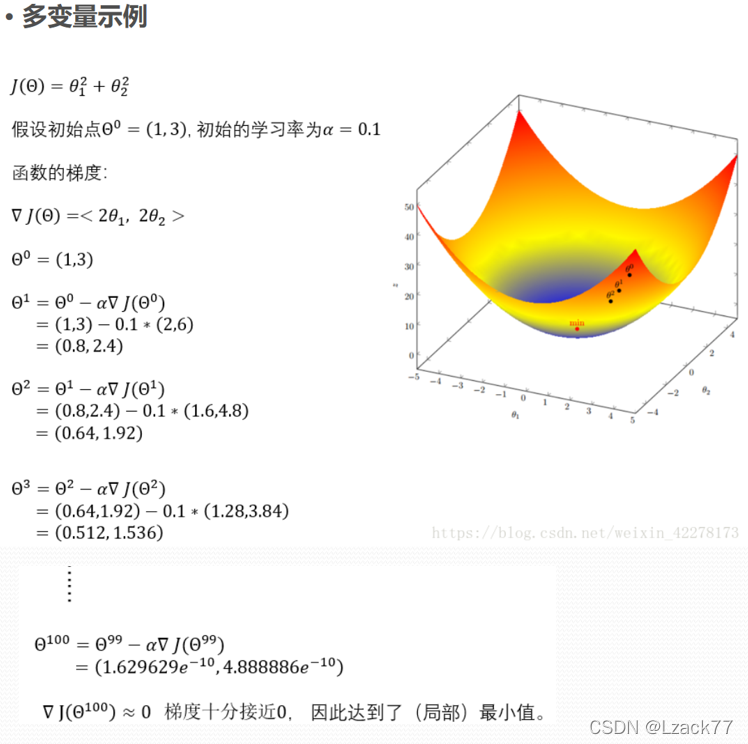
a1 = 0.676、b1 = 2.504
a2 = 1.6392、b2 = 2.797
a3 = 1.3294、b3 = 2.658
下降三步结果为(1.329,2.658)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)