【计算机网络】第五部分 传输层(23) UDP、TCP和SCTP
文章目录
UDP的讨论可在下列请求评论中找到:
769
TCP的讨论可在下列请求评论中找到:
675, 700, 721, 761, 793, 879, 896, 1078, 1106, 1110, 1144, 1145, 1146,
1263, 1323, 1337, 1379, 1644, 1693, 1901, 1905, 2001, 2018, 2488, 2580
SCTP的讨论可在下列请求评论中找到:
2960, 3257, 3284, 3285, 3286, 3309, 3436, 3554, 3708, 3758
这里开始给出传输层 transport layer 存在的基本理由,即进程到进程传递的必要性。主要讨论这类传递产生的问题,并讨论解决这些问题的方法。
在因特网模型中,传输层有三种协议:UDP、TCP和SCTP。首先讨论UDP协议,它是这三种中比较简单的一种协议。我们看到了如何使用这个非常简单的传输层协议,它缺少其他两个协议的一些特性。
然后讨论TCP协议,它是一种复杂的传输层协议。我们将了解到之前介绍的概念如何应用于TCP,并将有关TCP中拥塞控制和服务质量的讨论放在第24章,因为这两个问题同样适用于数据链路层和网络层。
最后讨论新的传输层协议SCTP ,它是为像多媒体这样的多接口与多流应用 multihomed, multistream applications 而设计的。
23.1 进程到进程的传递
数据链路层负责「链路上的两个相邻节点之间」的帧传递,这称为节点到节点的传递。网络层负责两台主机之间的数据报传递,这称为主机到主机的传递。然而,因特网中的通信并不是定义为两个节点或两个主机之间的数据交换。实际的通信是发生在两个进程(应用程序)之间的,我们需要进程到进程的传递 process-to-process delivery 。
但是,在任何时刻,在源主机上可能运行着多个进程,并且在目的主机上也运行着多个进程。为了完成传递过程,我们需要一种机制,将源主机上运行的某个进程的数据,发送到目的主机上运行的对应进程上。
传输层负责进程到进程的传递,即进程之间的分组传递以及部分消息传递。后面将会看到两个进程以客户/服务器的方式通信。图23.1 表示了三种传送类型以及它们的应用范围。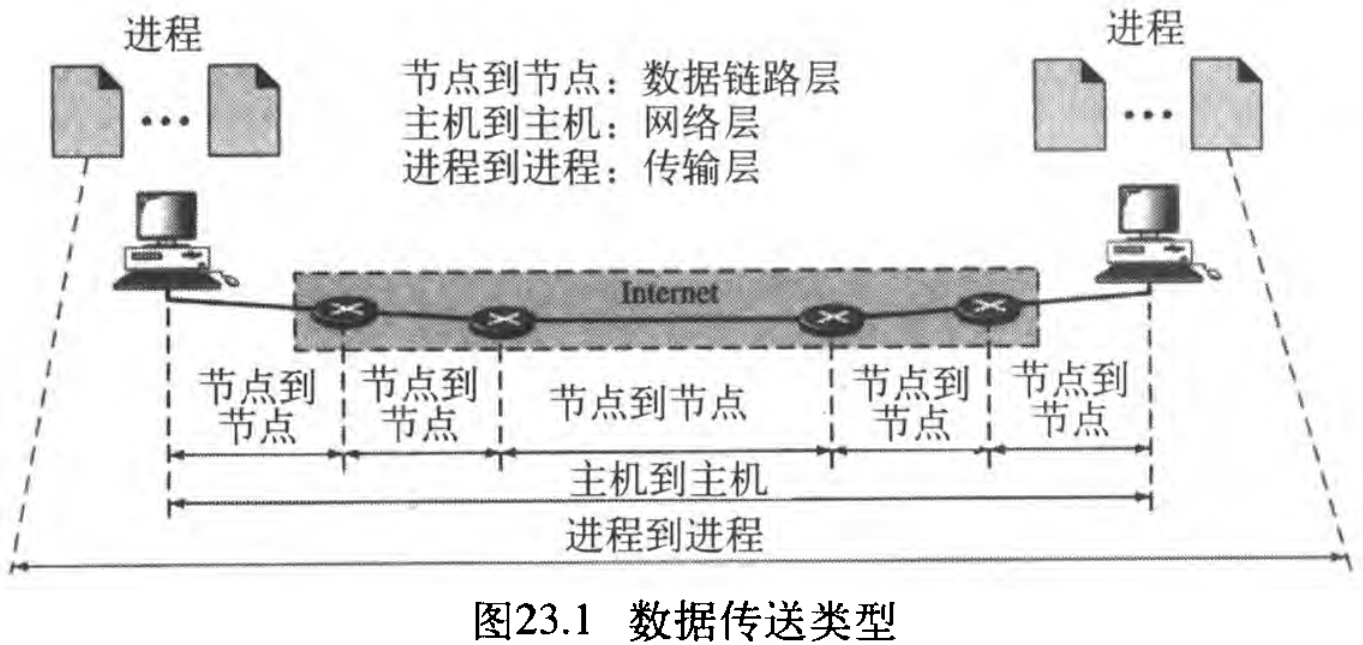
23.1.1 客户/服务器模式
虽然有多种方法可以实现进程到进程的通信,但最常用的一个方法是通过客户/服务器模式 client-server paradigm 。本地主机上的进程称为客户 client ,它通常需要「来自远程主机上的进程」提供的服务,这个远程主机称为服务器 server 。
这两个进程(客户和服务器)有相同的名字。例如,如果要从远程机器上获得日期和时间,我们需要在本地主机上运行 Daytime 客户进程,和在远程机器上运行 Daytime 服务器进程。
目前的操作系统支持多用户和多程序运行的环境。一个远程计算机在同 一时间可以运行多个服务器程序,就像许多本地计算机可在同一时间运行一个或多个客户应用程序一样。因此,对通信来说,我们必须确定义:
- 本地主机
- 本地进程
- 远程主机
- 远程进程
1. 寻址
每当需要传送信息到多个目的地之中的某一特定目的地时,就需要一个地址。在数据链路层,如果连接不是点到点的,则需要一个MAC地址,从多个节点中选择一个节点。数据链路层的帧需要一个目的端MAC地址用于传送数据,以及一个源地址用于下一节点的回答。
在网络层,需要一个IP地址来选择数百万主机之中的一个主机。网络层中的数据报需要目的IP地址用于传送数据,需要源IP地址用于接收目的主机的回答。
在传输层,需要一个称为端口号 port number 的传输层地址,利用这一地址从目的主机上运行的多个进程中选择相应的进程。目的端口号用于传送,而源端口号用于接收回答。
在因特网模型中,端口号是在 0 ∼ 65535 0\sim 65535 0∼65535 之间的 16 16 16 位整数。
- 客户程序用端口号定义它自己,这个端口号是由「运行在客户主机上的传输层软件」随机选择的,这是临时端口号
ephemeral port number。 - 服务器进程也必须用一个端口号定义它自己,但这个端口号不能随机选择。如果服务器站点的计算机运行一个服务器进程,并随机分配一个数字作为端口号,那么在客户站点的进程想访问该服务器、并使用其服务时,将不知道此端口号。当然,一个解决方法是发送一个特殊分组、并请求一个特定服务器的端口号,但是这需要更多的开销。
因特网决定给服务器使用全局端口号:它们称为熟知端口号well-known port number。但这条规则也有例外,例如,有一些客户端也被分配了熟知端口号there are clients that are assigned well-known port numbers。每一个客户进程都知道相应服务器进程的熟知端口号。例如,前面所讨论的Daytime客户进程可以使用临时(暂时)端口号 52000 52000 52000 来表示自己,但服务器Daytime进程就必须使用熟知(永久的)端口号 13 13 13 。图23.2表示了这一概念。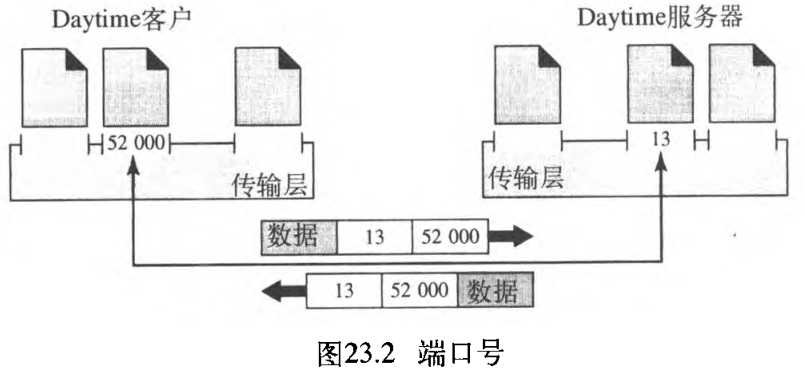
现在必须搞清楚,在选择数据的最终目的端时,IP地址和端口号起着不同的作用——目的IP地址在世界范围的不同主机中确定一个主机。但主机被选定后,端口号定义了在该特定主机上的多个进程中的一个进程(见图23.3)。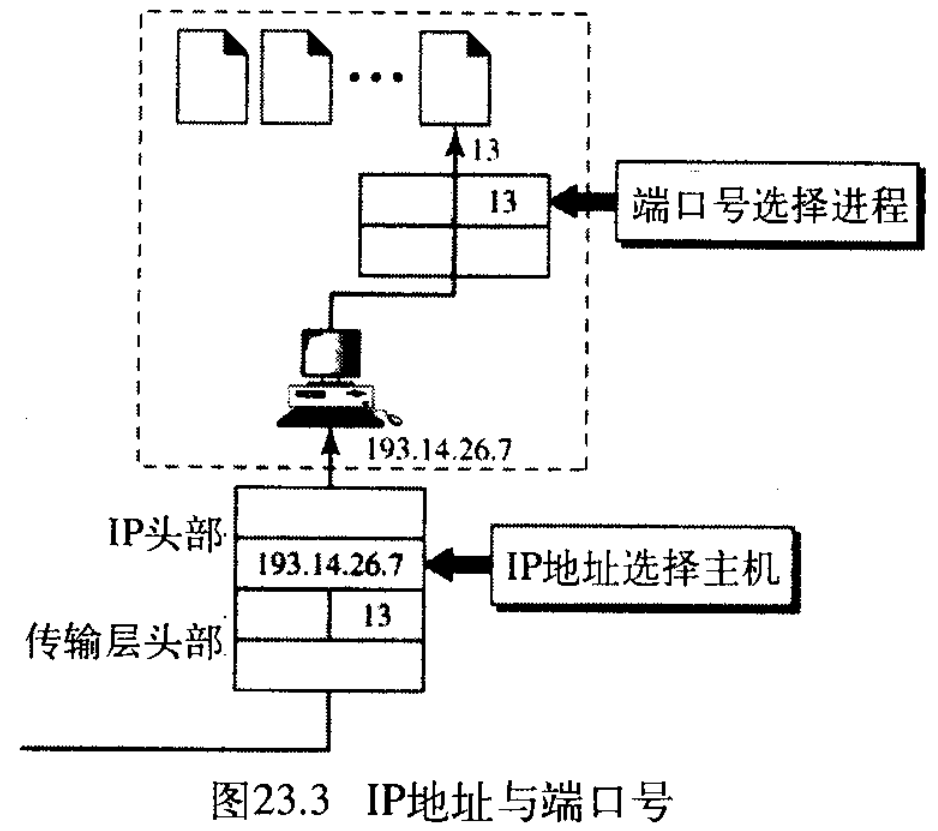
2. IANA范围
因特网号码分配管理局 Internet Assigned Number Authority, IANA 已经把端口编号划分为三种范围:熟知的、注册的和动态的(私有的) ,如图23.4所示:
- 熟知端口
well-known ports。端口号的范围是 0 ∼ 1023 0\sim 1023 0∼1023 ,由IANA分配和控制。这些是熟知端口。 - 注册端口
registered ports。端口号的范围是 1024 ∼ 49151 1024\sim 49151 1024∼49151 ,IANA不分配或也不控制。它们可在IANA注册以防重复。 - 动态端口
dynamic ports。端口号的范围是 49152 ∼ 65535 49152\sim 65535 49152∼65535 。这一范围内的端口号既不受控制也不需要注册,可以由任何进程使用。它们是临时端口。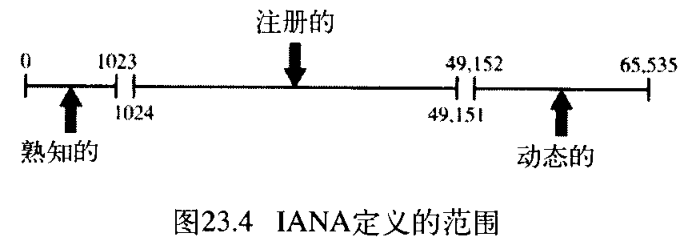
3. 套接字地址
进程到进程的传递需要有两个标识符,IP地址和端口号,它们各用在一端以建立一条连接。一个IP地址和一个端口号结合起来称为套接字地址 socket address 。客户套接字地址唯一定义了客户机进程,而服务器套接字地址唯一地定义了服务器进程(见图23.5所示)。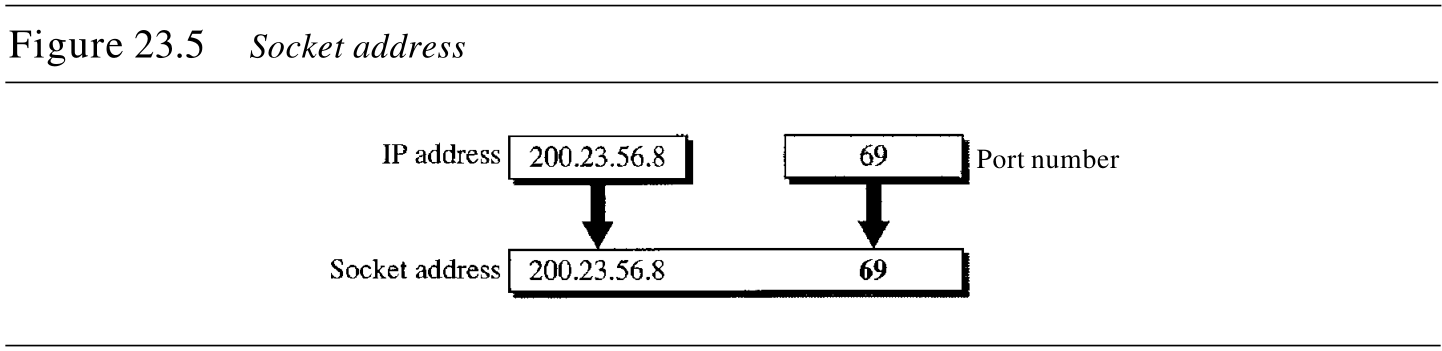
传输层协议需要一对套接字地址:客户套接字地址和服务器套接字地址。这四条信息是IP头部和传输层协议头部的组成部分。IP头部包含IP地址,而UDP或TCP头部包含端口号。
23.1.2 复用与分离
寻址机制允许通过传输层进行复用和分离 The addressing mechanism allows multiplexing and demultiplexing by the transport layer ,如图23.6所示。
1. 复用
在发送方站点,可能有多个进程要发送分组。但是,在任何时候只有一个传输层协议。这是一种多对一的关系,因而需要复用——传输层协议接收来自不同进程的报文,这些进程由「分配给它们的端口号」进行区分。添加了头部以后,传输层把分组发送给网络层。
2. 分离
在接收方站点,也只有一个传输层协议,但是有多个进程可能要接收分组。这是一对多的关系,因而需要分用——传输层接收来自网络层的数据报。经过纠错和去除头部以后,传输层根据端口号,将每个报文传递到适当的进程。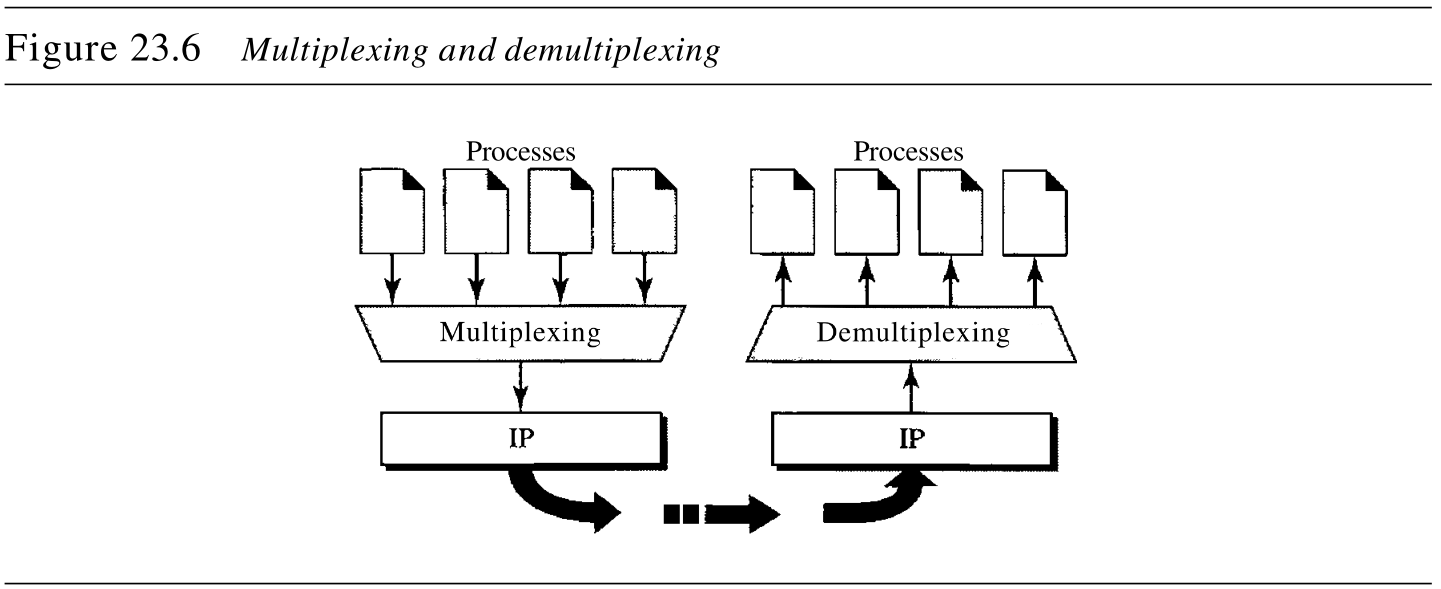
23.1.3 无连接服务与面向连接的服务
传输层协议可以是无连接的或面向连接的服务。
1. 无连接服务
在无连接服务 connectionless service 中,分组从一方发送给另一方,不需要建立连接和释放连接。分组没有编号。它们可能被延迟、丢失或无序到达,也没有确认过程。下面会看到,在因特网模型中,其中的一个传输层协议UDP就是无连接的。
2. 面向连接的服务
在面向连接的服务 connection-oriented service 中,首先在发送方和接收方之间建立一个连接,然后传送数据,最后释放连接。下面将看到,TCP和SCTP都是一种面向连接的协议。
23.1.4 可靠服务与不可靠服务
传输层服务可以是可靠的或不可靠的:
- 如果应用层程序需要可靠性,我们使用可靠的传输层协议,通过在传输层实现流量控制和差错控制来获得这种可靠性。这意味着一种较慢和更复杂的服务。
- 另一方面,如果应用程序不需要可靠性,因为它使用自己的流量和差错控制机制、或者它需要快速服务、或者服务的本质特性不要求流量和差错控制(如实时应用),那么就可以使用不可靠服务。
在因特网中,有三种不同的传输层协议,前面已提到过。UDP是无连接的和不可靠的,而TCP和SCTP则是面向连接的和可靠的。这三种协议都能与应用层程序的需要相对应。
一个疑问是:如果数据链路层是可靠的,并且已经有了流量控制和差错控制,那么还需要在传输层进行流量控制和差错控制吗?回答是需要的。因为在数据链路层的可靠性存在于两个节点之间,而我们需要端到端的可靠性,并且因为因特网的网络层是不可靠的(尽力传递),所以必须在传输层实现可靠性。要知道,数据链路层的差错控制并不能保证传输层的差错控制,让我们看一下图23.7。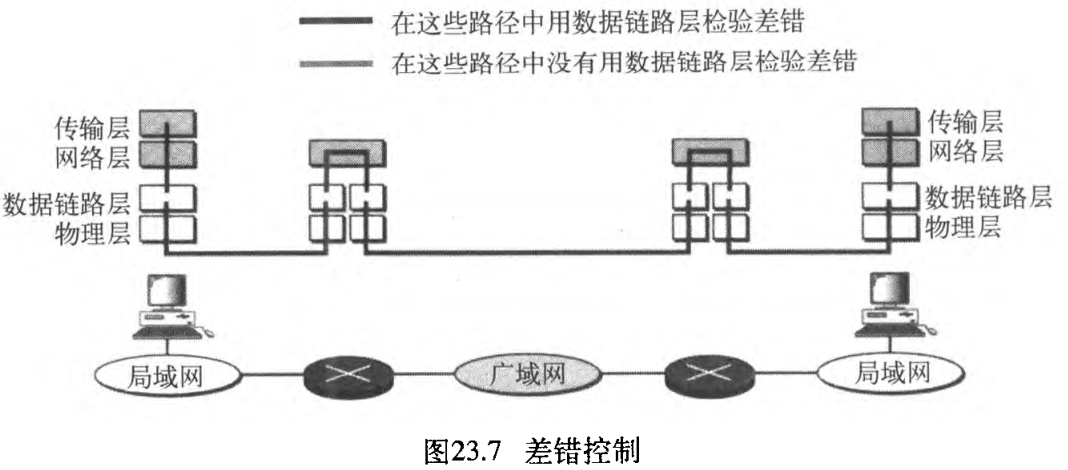
下面将看到,TCP中的流量和差错控制是通过滑动窗口协议实现的,就像在【计算机网络】第三部分 数据链路层(11) 数据链路控制中已经讨论过的那样。但是,窗口是面向字符而不是面向帧的。
23.1.5 三种协议
原始的TCP/IP协议族在传输层只规定了两个协议:UDP和TCP。在讨论TCP以前,首先关注这两个协议中较简单的UDP。然后在本章中也讨论新设计的传输层协议SCTP。图23.8表示了这些协议在TCP/IP协议族中的位置。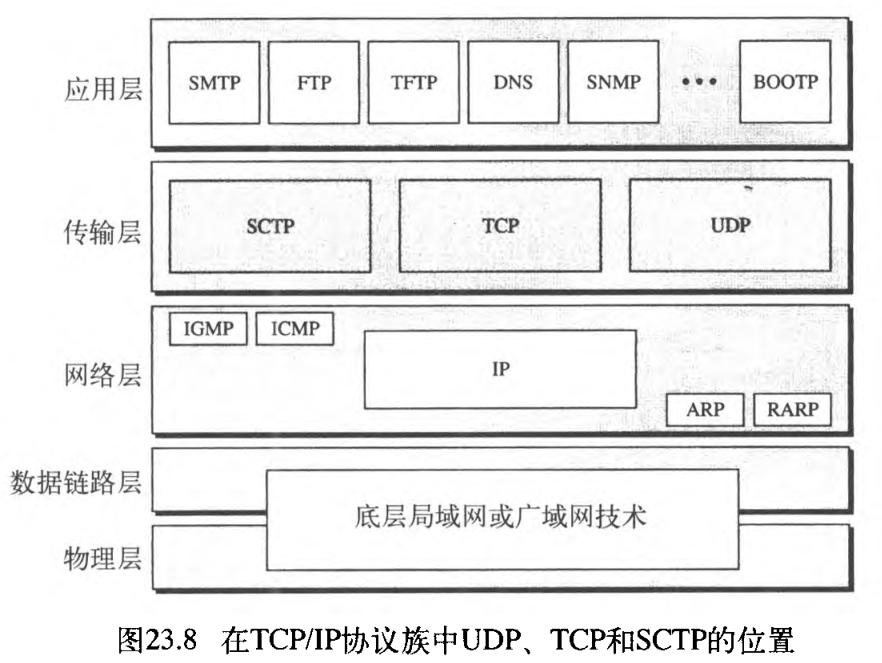
23.2 用户数据报协议(UDP)
用户数据报协议 User Datagram Protocol, UDP 称为无连接不可靠传输层协议 connectionless, unreliable transport protocol 。它除了提供进程到进程通信、而不是主机到主机通信外,就没有给IP服务增加任何东西。此外,它还完成非常有限的差错检验。
如果UDP功能如此差,那么为什么进程还要使用它?它有缺点但也有优点——UDP是一个非常简单的协议,开销最小。如果一个进程想发送很短的报文,而且不在意可靠性,就可以使用UDP。使用UDP发送一个很短的报文,在发送方和接收方之间的交互,要比使用TCP或SCTP时少得多。
23.2.1 熟知端口号
表23.1列出了UDP使用的一些熟知端口号。有些端口号是UDP和TCP都可使用的。稍后讨论TCP肘,将讨论它们。
| 端口 | 协议 | 说明 |
|---|---|---|
| 13 13 13 | Daytime |
Returns the date and the time |
| 17 17 17 | Quote |
Returns a quote of the day |
| 19 19 19 | Chargen |
Returns a string of characters |
| 53 53 53 | Nameserver |
Domain Name Service |
| 67 67 67 | BOOTPs |
Server port to download bootstrap information |
| 68 68 68 | BOOTPc |
Client port to download bootstrap information |
| 69 69 69 | TFTP |
Trivial File Transfer Protocol |
| 111 111 111 | RPC |
Remote Procedure Call |
| 123 123 123 | NTP |
Network Time Protocol |
| 161 161 161 | SNMP |
Simple Network Management Protocol |
| 162 162 162 | SNMP |
Simple Network Management Protocol (trap) |
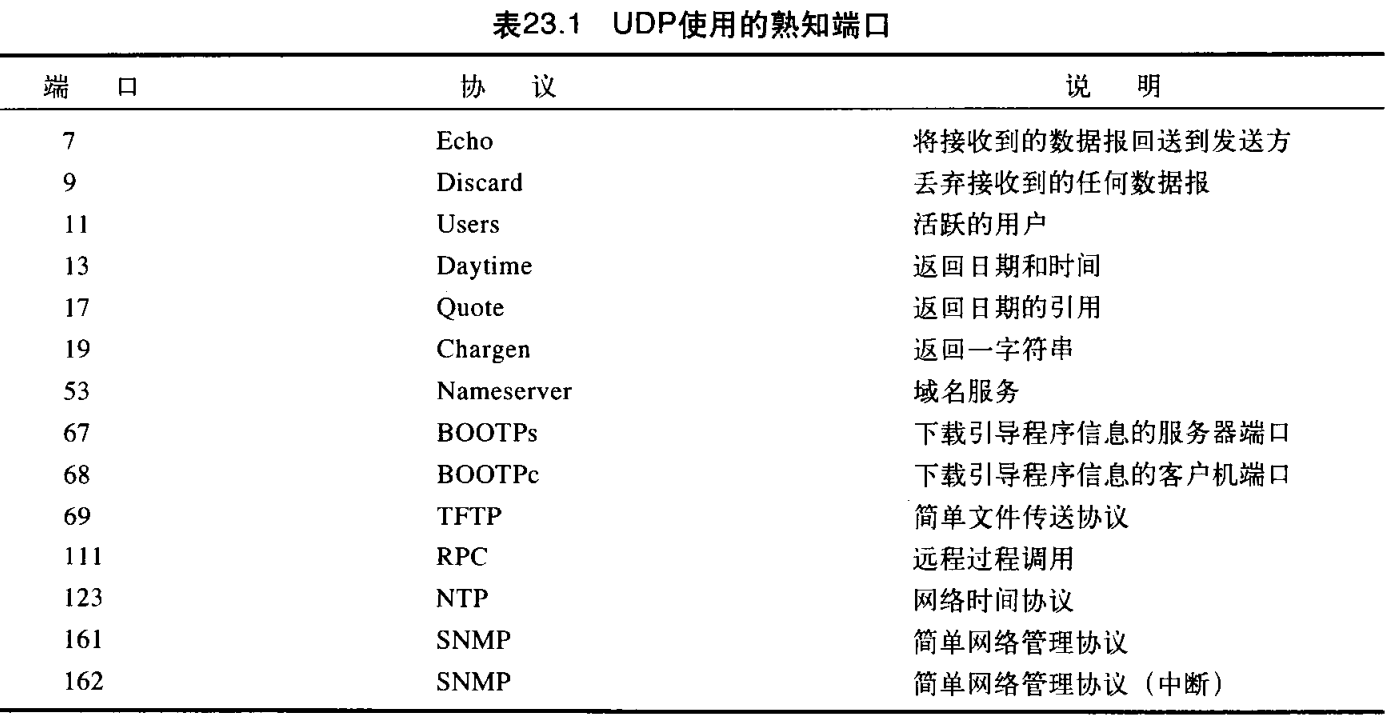
【例23.1】在UNIX中,熟知端口号存储在 /ect/services 文件中,这个文件的每行给出服务器名和熟知端口号。我们可用 grep 命令提取该行所对应的应用。下面表示了FTP的端口。注意:FTP可使用 UDP或TCP的端口 21 21 21 。SNMP使用两个端口号( 161 161 161 和 162 162 162),在第28章中看到每一个用于不同目的。
$ grep ftp /etc/services
ftp 21/tcp
ftp 21/udp
$ grep snmp /etc/services
snmp 161/tcp #Simple Nel Mgml Proto
snmp 161/udp #Simple Nel Mgmt Proto
snmptrap 162/udp #Traps for SNMP
23.2.2 用户数据报
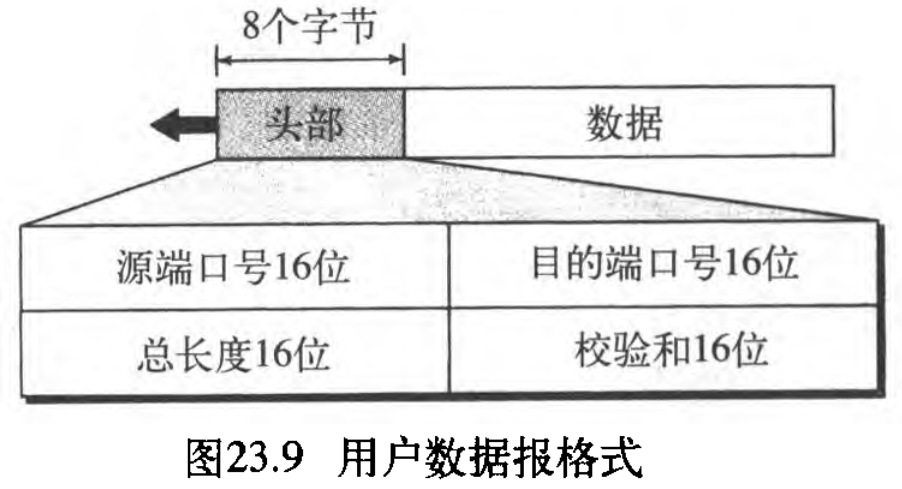
UDP分组称为用户数据报 user datagram ,有 8 8 8 字节的固定头部(TCP固定头部是 20 20 20 字节!)。图23.9说明了用户数据报的格式(很简单! )。用户数据报共有下列字段:
- 源端口号。这是在源主机上运行的进程使用的端口号。它有 16 16 16 位长,这就表示端口号可以从 0 0 0 到 65535 65535 65535 。如果源主机是客户端(当客户进程发送请求时),那么大多数情况下这个端口号就是暂时端口号,它由该进程请求,由源主机上运行的UDP软件进行选择。如果源主机是服务器(当服务器进程发送响应时),那么在大多数情况下这个端口号是熟知端口号。
- 目的端口号。这是在目的主机上运行的进程使用的端口号。它有 16 16 16 位长。如果目的主机是服务器(当客户进程发送请求时),那么在大多数情况下这个端口号是熟知端口号。如果目的主机是客户端(当服务器进程发送响应时),那么大多数情况下这个端口号是暂时端口号。在这种情况下,服务器将它接收到的请求分组中的暂时端口号复制下来。
- 长度。这是一个 16 16 16 位字段,它定义了用户数据报的总长度(头部加上数据)。 16 16 16 位可定义的总长度是从 0 0 0 到 65535 65 535 65535 字节。但是,总长度必须比这个小。因为UDP数据报存放在总长度为 65535 65535 65535 字节的IP数据报中。
UDP用户数据报的长度字段实际上是没有必要的:用户数据报封装成IP数据报,在IP数据报中有一个字段定义总长度,IP数据报还有一个字段定义头部长度。所以,如果将上述第一个字段的值减去第二个字段的值,就能求得「封装在IP数据报中的UDP数据报」的长度。
但是,UDP协议设计者认为,目标UDP根据UDP用户数据报中提供的信息计算数据长度,比要求IP软件提供这一信息更有效。应该当记得,当IP软件把UDP用户数据报提交给UDP层时,它已经除去了IP头部。 - 校验和。这个字段用来校验整个用户数据报(头部加数据)出现的差错。校验和将在下一节讨论。
23.2.3 校验和
在【计算机网络】第三部分 数据链路层(10) 检错与纠错中,已讨论过校验和的概念与计算方法,还讨论过如何计算IP和ICMP分组的校验和。现在,讨论如何计算UDP的校验和(注意进位回滚)。
UDP校验和的计算与IP和ICMP校验和的计算不同。这里校验包括三个部分:伪头部、UDP头部和从应用层来的数据。伪头部 pseudoheader 是IP分组的头部的一部分,用户数据报封装在IP分组中,其中有些字段要填入 0 0 0 The pseudoheader is the part of the header of the IP packet in which the user datagram is to be encapsulated with some fields filled with 0s(见图23.10)。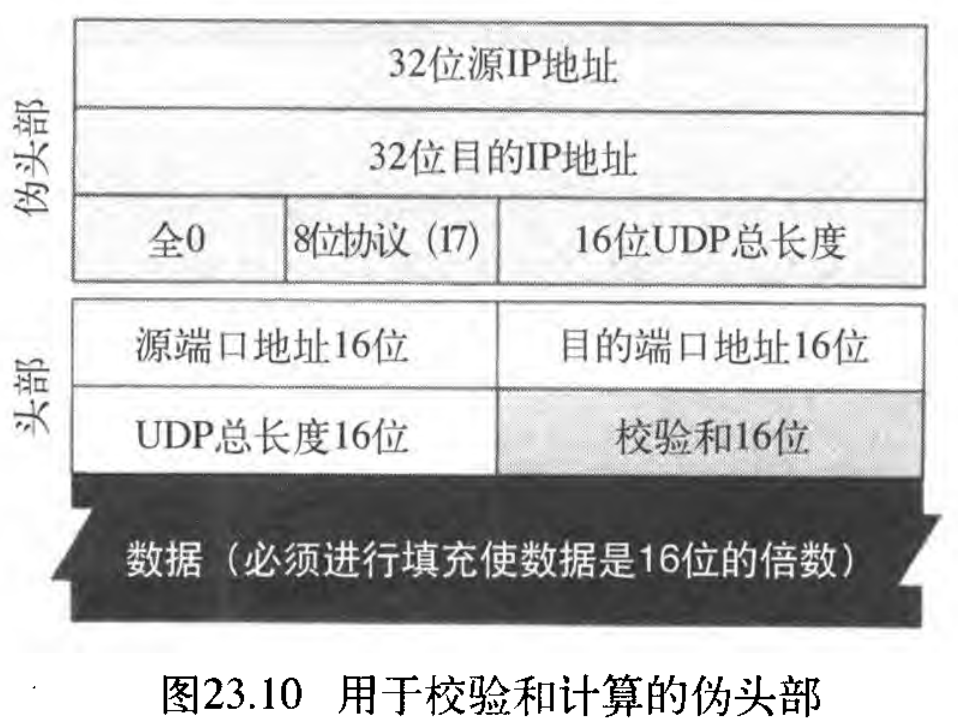
如果校验和不包括伪头部,用户数据报也可能是安全的和正确地到达。但是,如果IP头部受到损坏,那么它可能被提交到错误的主机。
(在伪头部中)增加协议字段,可确保这个分组是属于UDP,而不是属于其他传输层协议。在后面将会看到,如果一个进程既可用UDP又可用TCP ,则端口号可以是相同的。UDP的协议字段一直是 17 17 17 ,如果在传输过程中这个值改变了,在接收端计算校验和时就可检测出来,UDP就可丢弃这个分组。这样就不会传递给错误的协议。
注意伪头部字段和「IP头部最后 12 12 12 字节」的相似性。
【例23.2】图23.11给出了只有 7 7 7 个字节数据的、很小的用户数据报的校验和计算。因为数据的字节数是奇数,因此为了计算校验和就要加上填充。当用户数据报要传递给IP时,就将伪头部和填充丢弃。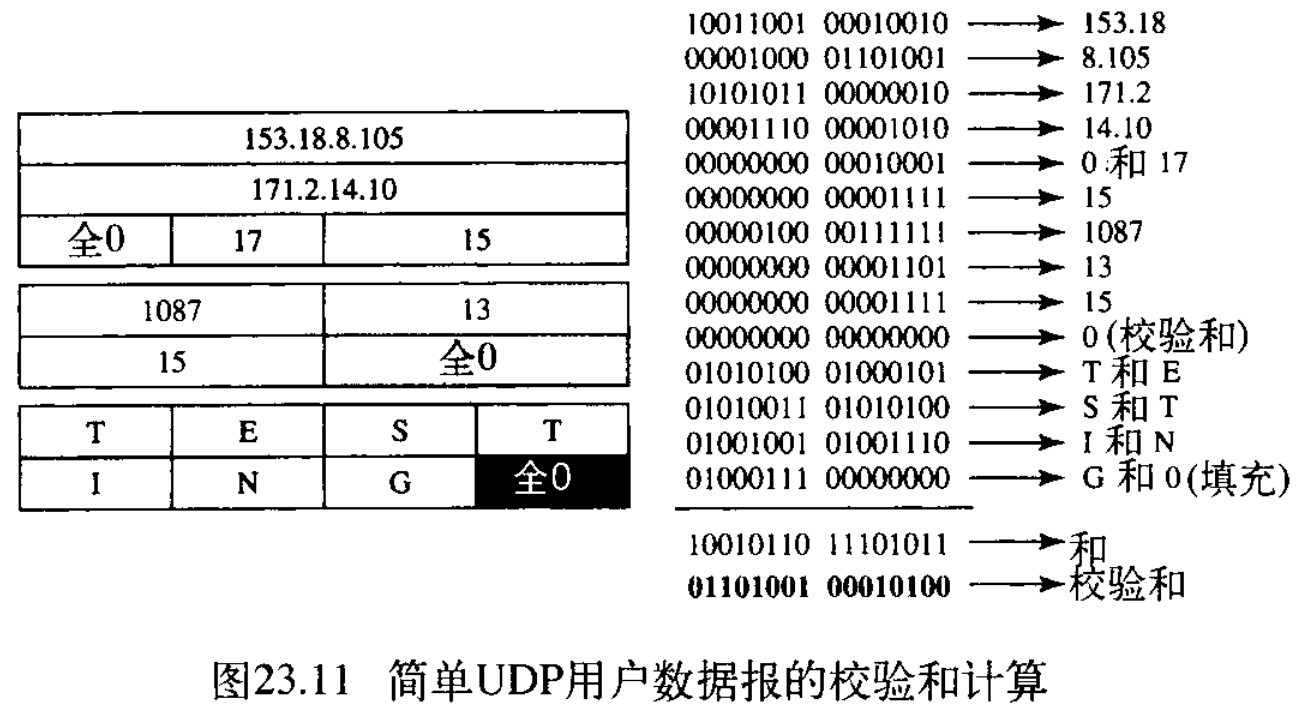
可选的校验和
校验和的计算、以及在用户数据报中包括的校验和都是可选的。如果不进行校验和的计算,则这个字段就填入全 1 1 1 。注意:计算得到的校验和永远不会是全 1 1 1 ,因为这就是说和是全 0 0 0 ,这是不可能的——由于它要求字段的值为全 0 0 0 ,这是不可能的。
23.2.4 UDP的操作
UDP使用了传输层共同的一些概念。简要讨论这些概念,然后在下一节介绍TCP协议时展开讨论。
1. 无连接服务
如前所述,UDP提供无连接服务。这表示UDP发送出去的每一个用户数据报都是一个独立的数据报。不同的用户数据报之间没有关系,即使它们都来自相同的源进程、并发送到相同的目的程序。用户数据报不进行编号。此外,也没有像TCP协议那样的连接建立和连接终止,这就表示,每一个用户数据报可以沿着不同的路径传递。
无连接的一个结果就是,使用UDP的进程不能向UDP发送数据流,也不能期望UDP将这个数据流分割成许多不同的、相关联的用户数据报。相反,每一个请求必须足够小,使其能够装入到用户数据报中,只有那些发送短报文的进程才应当使用UDP。
2. 流量控制和差错控制
UDP是一个简单的、不可靠的传输协议,它没有流量控制,因而也没有窗口机制。如果到来的报文太多肘,接收方可能会溢出。除校验和外,UDP也没有差错控制机制,这就表示发送方不知道报文是否丢失、还是重复传递。当接收方使用校验和检测出差错时,就悄悄地将此用户数据报丢弃。
缺少流量控制 flow control 和差错控制 error control ,就表示使用 UDP的进程必须要提供这些机制。
3. 封装和拆封
要将报文从一个进程发送到另一个进程时,UDP协议就要在IP数据报中封装和拆封报文。
4. 排队
我们已经提到过端口,但没讨论端口的实际实现。在UDP中,队列是与端口联系在一起的(见图23.12所示)。注意:即使当一个进程想与多个进程通信肘,它也只得到一个端口号,最后往往也只有一个出队列和一个入队列 queue 。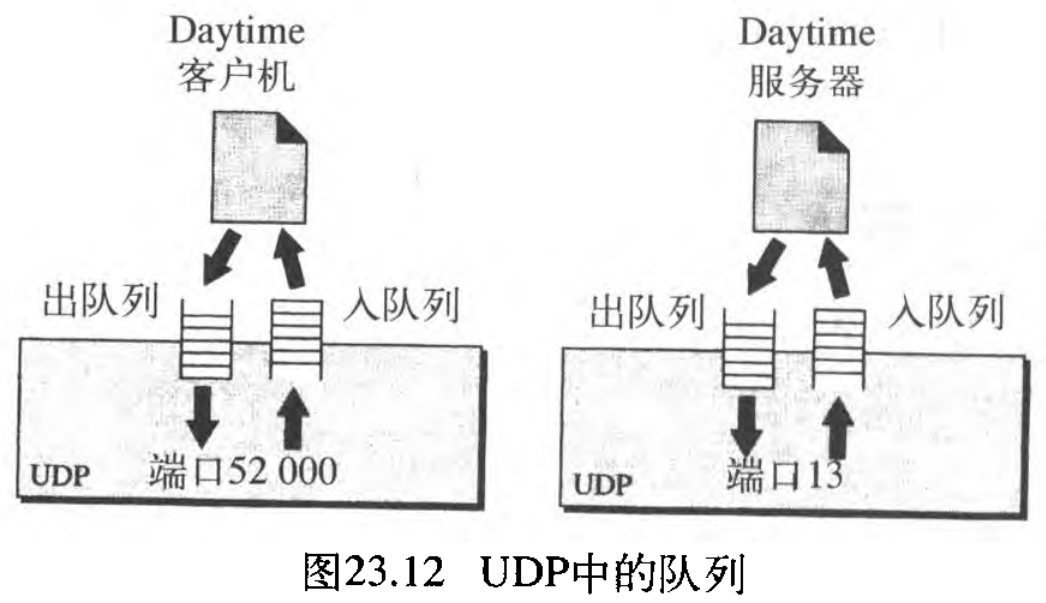
在客户机端,当进程启动时,它从操作系统请求一个端口号。一些实现会创建与每个进程关联的一个出队列和入队列 an incoming and an outgoing queue 。而有些实现只创建与每一个进程相关的入队列。在多数情况下,由客户打开的队列由暂时端口号来标识,只要进程在运行,这些队列就起作用。当进程终止时,队列就撤销。客户进程使用「在请求中指明的源端口号」,将报文发送到出队列。UDP逐个将报文取出,加上UDP头部递交给IP。出队列可能发生溢出。如果发生溢出,操作系统就要求客户进程在继续发送报文之前要等待。
当报文到达客户端时,UDP要检查一下,以确认对应于「该用户数据报中目的端口号字段」指明的端口号是否创建了入队列。如果有这样的入队列,UDP就将接收到的用户数据报,放在该队列的末尾;如果没有这样的队列,UDP就丢弃该用户数据报,并请求ICMP协议、向服务器发送端口不可达报文。所有发送给一个特定客户程序的入报文,不管是来自相同的服务器还是不同的服务器,都被放在同一个队列中。入队列可能会溢出,如果发生溢出,UDP就丢弃此用户数据报,并请求向服务器发送端口不可达报文。
在服务器端,创建队列的机制是不同的。用最简单形式,服务器在它开始运行时,就用它的熟知端口请求入队列和出队列。只要服务器运行,队列就一直是打开的。
当报文到达服务器进程时,UDP要检查一下,以确认对应于「该用户数据报中目的端口号字段」指明的端口号是否创建了入队列。如果有这样的队列,UDP就将接收到的用户数据报,放在该队列的末尾。如果没有这样的队列,UDP就丢弃该用户数据报,并请求ICMP协议向客户端发送一个端口不可达报文。一个特定服务器程序的所有入报文,不管是来自相同的客户还是不同的客户机,都放入同一队列。入队列可能溢出,如果发生溢出,UDP就丢弃这个用户数据报,并请求向客户发送端口不可达报文。
当服务器想要回答客户时,它就使用「在请求报文中指明的源端口号」,将报文发送到出队列。UDP逐个将报文取出,加上UDP的头部,递交给IP。出队列可能溢出,如果发生溢出,操作系统就要求服务器进程在继续发送报文之前要等待。
23.2.5 UDP的使用
下列是UDP协议的某些应用:
- UDP适用于这样的进程,它需要简单的请求-响应通信,而较少考虑流量控制和差错控制。对于需要传送成块数据的进程,如 FTP(见【计算机网络】第六部分 应用层(26) 远程登录、电子邮件与文件传输),则通常不使用它;
- UDP适用于具有内部流量控制和差错控制机制的进程。例如,简单文件传输协议
TFTP的进程,就包括流量控制和差错控制,它能够很容易地使用UDP; - 对多播来说,UDP是一个合适的传输协议。多播能力已被嵌入在UDP软件中,但没有嵌入在TCP软件中;
- UDP可用于管理进程,如SNMP(见第28章);
- UDP可用于某些路由选择更新协议,如路由选择信息协议
RIP(第22章)。
23.3 TCP
讨论的第二个传输层协议,称为传输控制协议 Transmission Control Protocol, TCP 。与UDP一样,TCP是一个进程到进程(程序到程序)的协议,所以它使用端口号。但与UDP不同的是,TCP是面向连接的协议。为发送数据,它在两个TCP之间建立一个虚拟连接。另外,TCP在传输层使用流量控制和差错控制机制。
简单地说,TCP被称为面向连接的、可靠的传输协议。它为IP服务增加了面向连接和可靠性的特性。
23.3.1 TCP服务
在详细讨论TCP之前,解释TCP向应用层进程提供的服务。
1. 进程到进程的通信
像UDP一样,TCP用端口号提供进程到进程的通信。表23.2列出了TCP使用的一些熟知端口号。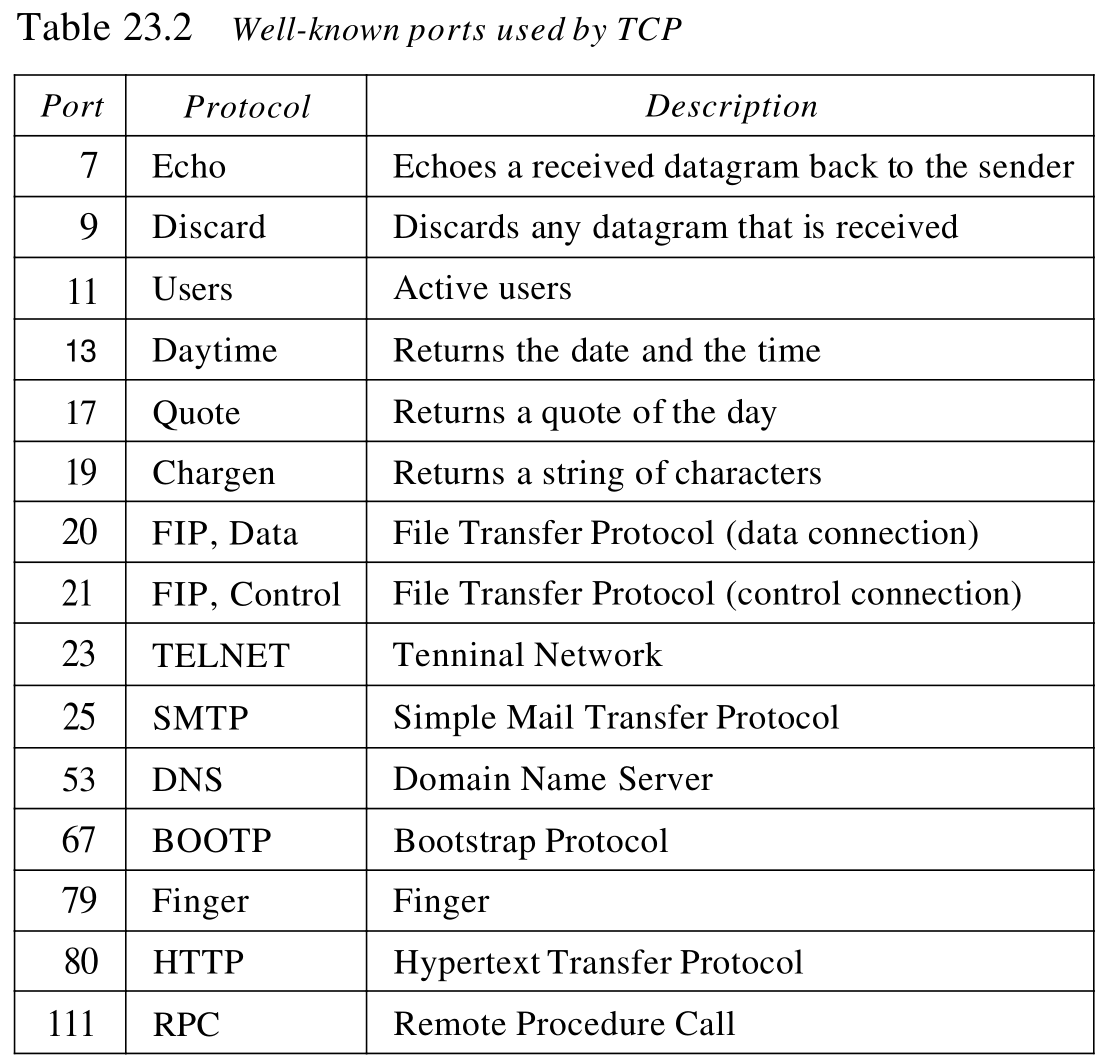
2. 流传递服务
与UDP不同,TCP是一个面向流的协议。在UDP中,进程(应用程序)发送一些具有预先规定界限 predefined boundaries 的报文给UDP进行传递。UDP将它自己的头部添加到这些报文中每一个报文上,并将它们传递到IP进行传输。来自进程的每一个报文被称为一个用户数据报,并最后变成一个IP数据报。IP和UDP都无法识别数据报之间的任何关系 Neither IP nor UDP recognizes any relationship between the datagrams 。
另一方面,TCP允许发送进程以字节流 a stream of bytes 形式传递数据,并且接收进程也以字节流形式接收数据。TCP建立一种环境,在这种环境中,两个进程好像由一根假想的"管道"连接,这个管道通过因特网传送这些进程的数据。这种假想的环境,如图23.13所示。发送进程产生(写入)字节流,而接收进程消费(读出)这些字节流。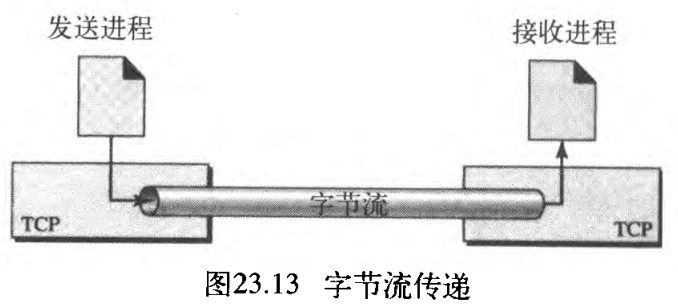
(1) 发送和接收缓冲区
因为发送和接收进程可能以不同的速度写入和读出数据,所以 TCP需要缓冲区来存储 TCP needs buffers for storage 。每一个方向都存在一个缓冲区:发送缓冲区和接收缓冲区(稍后会看到,这些缓冲区也用于TCP流量和差错控制机制)。实现缓冲的一种方法是,使用一字节存储单元的循环数组 use a circular array of 1-byte locations ,如图23.14所示。
为了简化,只画出了两个缓冲区,每个缓冲区 20 20 20 个字节。通常情况下,缓冲区是成百或上千个字节,这取决于实现方法。这里表示的缓冲区大小是相同的,实际上并非总是如此。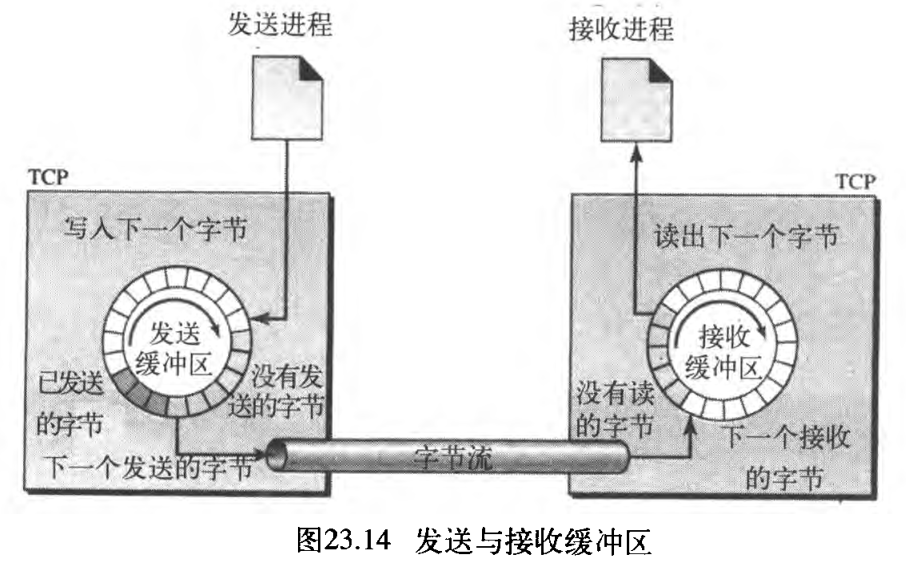
图23.14中表示了在一个方向上数据的移动。在发送端,缓冲区有三种类型的存储单元:白色的部分是空存储单元,可以由发送进程(生产者)填充。灰色的部分用于保存已经发送、但还没有得到确认的字节,TCP在缓冲区中保留这些字节,直到收到确认为止。有色部分是将由TCP发送的字节 The colored area contains bytes to be sent by the sending TCP 。但是,在后面将会看到,TCP可能只能发送灰色部分。这可能是由于接收进程缓慢、或者可能是网络中发生的拥塞。还要注意,灰色存储单元的字节被确认后,这些存储单元可以回收、并且对发送进程可用,这就是我们表示一个环形缓冲区的原因。
接收端的缓冲区操作比较简单。环形缓冲区分成两个区域(表示为白色和灰色)。白色区域包含空存储单元,可以由从网络上接收的字节进行填充。灰色区域表示接收到的字节,可以由接收进程读出。当某个字节被接收进程读出以后,这个存储单元可被回收,并加入到空存储单元池中。
(2) 段
尽管缓冲能够处理生产进程速度和消费进程速度之间的不相称问题,但在发送数据之前,还需要多个步骤。
IP层作为TCP服务的提供者,需要以分组的方式、而不是字节流的方式发送数据。在传输层,TCP将多个字节组合在一起成为一个分组,这个分组称为段 segment 。
TCP给每个段添加头部(为了控制的目的),并将该段传递给IP层。段被封装到IP数据报中,然后再进行传输。整个操作对接收进程是透明的。稍后,会看到这些段可能被无序接收、丢失、或者损坏和重发。所有这些均由TCP处理,接收进程不会觉察到任何操作。图23.15表示了在缓冲区中如何从字节生成段。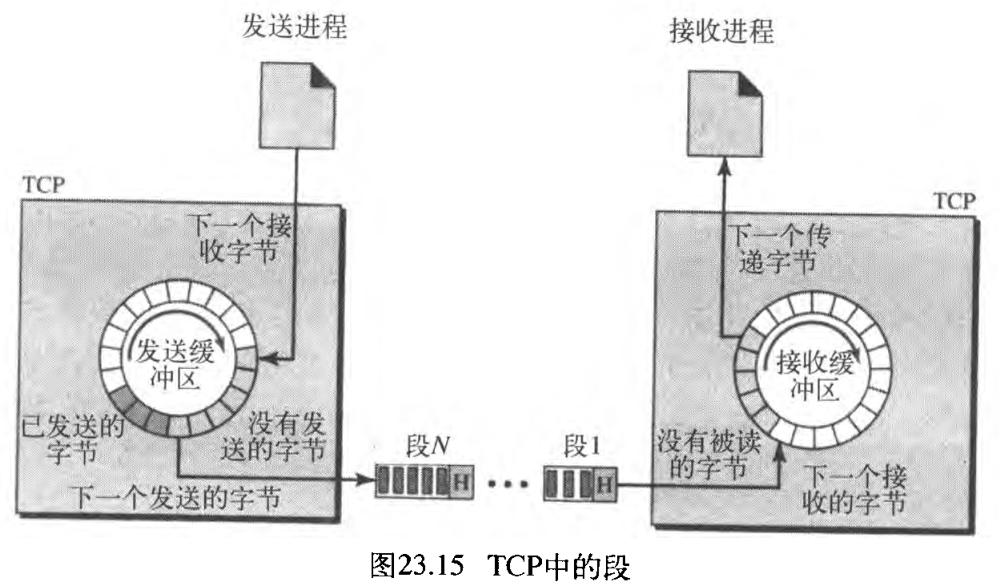
注意:段的大小不必相同。为了简单起见,在图23.15中只表示了一个包含 3 3 3 个字节的段和另一个包含 5 5 5 个字节的段。实际的段可能包含数百(或者数千)个字节。
3. 全双工通信
TCP提供全双工服务 full-duplex service ,即数据可以在同一时间双向流动。每一方TCP都有发送和接收缓冲区,它们能在双向发送和接收段。
4. 面向连接的服务
与UDP不同,TCP是一种面向连接的协议。站点 A A A 的一个进程要发送和接收来自站点 B B B 的另外一个进程的数据时,步骤如下:
- 在两个TCP之间建立一个连接;
- 在两个方向交换数据;
- 连接终止。
注意:这是一个虚连接,而不是一个物理连接。TCP段封装成IP数据报,并且可能被无序地发送、或丢失或被破坏,然后重发。每个段都可以通过不同的路径到达目的端。虽然不存在物理连接,但TCP会建立一种面向字节流的环境,在这种环境中,TCP能承担「按顺序传递这些字节到其他站点的任务」。这就好像建立了横跨多个岛屿的一座桥,以单一的连接从一个岛屿到另一个岛屿传送所有字节。
5. 可靠的服务
TCP是一种可靠的传输协议。它使用确认机制来检查数据是否安全和完整地到达。在后面进一步讨论差错控制的特点。
23.3.2 TCP特点
为了提供上一节中提到的服务,TCP有几个特性,本节将简要概述这些特性,并在后面进行详细讨论。
1. 序号系统
虽然TCP软件能够记录被其发送或接收的段,但是在段的头部没有段序号 segment number 字段。相反,有两个字段,称为序号 sequence number 和确认号 acknowledgment number 。这两个字段指的是字节序号,而不是段序号。
2. 字节序号
TCP给在一个连接中传输的所有数据字节编号 TCP numbers all data bytes that are transmitted in a connection 。在每个方向上序号都是独立的。当TCP接收来自进程的一些数据字节时,它会将其存储在发送缓冲区中、并给它们编号。
不必从 0 0 0 开始编号,TCP在 0 0 0 到 2 32 − 1 2^{32}-1 232−1 之间生成一个随机数,作为第一个字节的序号,例如,如果随机数是 1057 1057 1057 ,并且发送的全部字节个数是 6000 6000 6000 ,那么这些字节序号是 1057 ∼ 7056 1 057 \sim 7056 1057∼7056 。下面将会看到,字节序号用于流量和差错控制。序号字节被编号后,TCP对发送的每一个段分配一个序号,每个段序号是这个段中的第一个字节的序号。
【例23.3】假设一个TCP连接正在传送一个 5000 5 000 5000 字节的文件,第一个字节序号是 10001 10 001 10001 。如果数据被分成 5 5 5 个段,每一个数据段携带 1000 1000 1000 字节,试问每个段的序列号是什么?
解:每个段的序号如下所示:
- 段 1 → 1 → 1→ 序号: 10001 10001 10001(范围: 10001 ∼ 11000 10001\sim 11000 10001∼11000)
- 段 2 → 2→ 2→ 序号: 11001 11 001 11001(范围: 11001 ∼ 12000 11001\sim 12000 11001∼12000)
- 段 3 → 3 → 3→ 序号: 12001 12001 12001(范围: 12001 ∼ 13000 12001\sim 13000 12001∼13000)
- 段 4 → 4→ 4→ 序号: 13001 13 001 13001(范围: 13001 ∼ 14000 13 001\sim 14000 13001∼14000)
- 段 5 → 5 → 5→ 序号: 14001 14001 14001(范围: 14001 ∼ 16000 14001\sim 16000 14001∼16000)
当一个段携带数据和控制信息(捎带)时,它使用一个序号。如果一个段没有携带用户数据,那么它逻辑上不定义序号,虽然字段存在,但值是无效的。然而,有些段当仅携带控制信息时,也需要有一个序号用于接收方的确认。这些段用做连接建立、连接终止或连接废弃 connection establishment, termination, or abortion 。这些段中的每一个,好像携带一个字节那样使用一个序号,但都没有实际的数据,如果随机产生的序号是 x x x , 则第一个数据字节的编号是 x + 1 x+1 x+1 ,字节 x x x 被认为是一个伪字节 phony byte ,用于控制段打开一个连接 used for a control segment to open a connection ,我们不久将会见到。
3. 确认号
正如前面讨论的那样,TCP中的通信是全双工的;当建立一个连接时,双方同时都能发送和接收数据。每一方对字节编号,通常使用不同的起始字节号,每一方向的序号表明了该段所携带的第一个字节的序号 The sequence number in each direction shows the number of the first byte carried by the segment 。
每方也使用一个确认号来确认它已收到的字节。但是,确认号定义了「该方预期接收的下一个字节的序号」the number of the next byte that the party expects to receive 。另外,确认号是累积的 cumulative ,这意味:接收方记下它已安全而且正确地接收到的最后一个字节的序号,然后将它加 1 1 1 ,并通告这个结果作为确认号。在这里,术语"累积"指的是,如果一方使用 5643 5 643 5643 作为确认号,则表示它已经接收了所有从开始到序号为 5642 5 642 5642 的字节。但要注意,这并不是指接收方已经接收了 5642 5 642 5642 个字节,因为第一个字节的编号通常并不是从 0 0 0 开始的。
4. 流量控制
与UDP不同的是,TCP提供流量控制。数据的接收方控制发送方发送数据的数量,这样做是为了防止接收方数据溢出。序号系统允许使用面向字节的流量控制。
5. 差错控制
为了提供可靠的服务,TCP有一个差错控制机制。虽然差错控制以段作为差错检测(丢失或损坏段)的数据单元,稍后我们将会看到面向字节的差错控制。
6. 拥塞控制
与 UDP不同的是,TCP考虑网络中的拥塞。发送方发送的数据量不仅由接收方控制(流量控制),而且还要由网络中的拥塞程度决定。即发送窗口 = min ( r w n d , c w n d ) =\min (rwnd, cwnd) =min(rwnd,cwnd) 。
23.3.3 段格式
在更详细地讨论TCP之前,讨论TCP分组本身。在TCP中的分组称为段 segment 。 段的格式,如图23.16所示。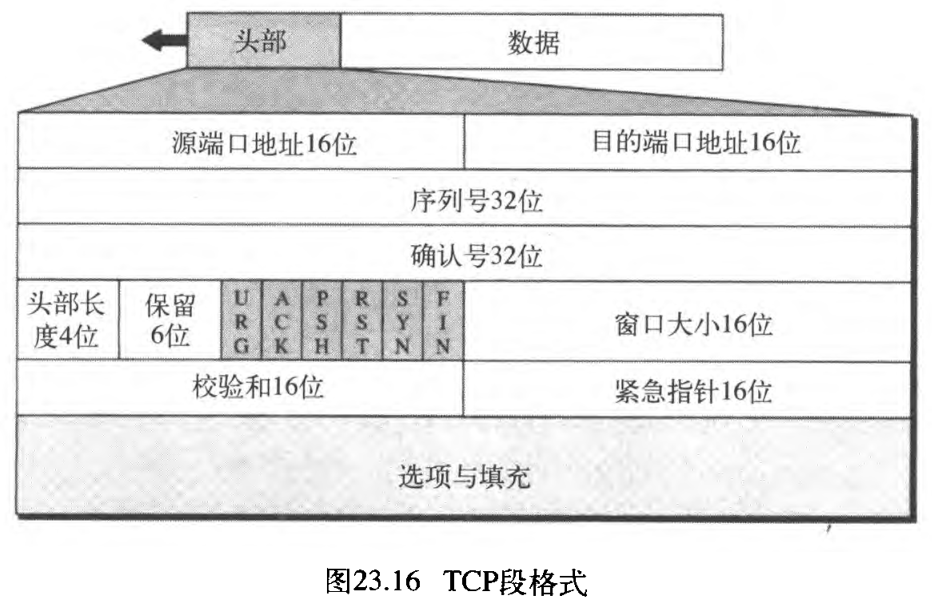
段包括 20 20 20 字节到 60 60 60 字节的头部,接着是来自应用程序的数据。如果没有选项,那么头部是 20 20 20 字节。如果有选项,最多是 60 60 60 字节(IPv4的头部结构长度为 20 20 20 字节,若含有可变长的选项部分,最多 60 60 60 字节)。在本节中,将讨论某些头部字段,以了解这些字段的意义和目的。
- 源端口地址。这是一个 16 16 16 位的字段,它定义了在主机中「发送该段的应用程序的端口号」。这与UDP头部的源端口地址的作用一样。
- 目的端口地址。这是一个 16 16 16 位的字段,它定义了在主机中「接收该段的应用程序的端口号」。这与UDP头部的目的端口地址的作用一样。
- 序列号。这个 32 32 32 位的字段定义了一个数,它分配给段中数据的第一个字节。如前所述,TCP是一种字节流传输协议。为了确保连通性,对要发送的每一个字节都进行编号。序列号告诉目的端,「在这个序列中的哪一个字节」是「该段的第一个字节」
which byte in this sequence comprises the first byte in the segment。在连接建立时,每一方都使用随机数生成器产生一个初始序列号initiaI sequence number, ISN,通常每一个方向的ISN都不同。 - 确认号。这个 32 32 32 位的字段定义了「段的接收方期望从对方接收的字节号」。如果段的接收方成功地接收了对方发来的字节号 x x x , 它就将确认号定义为 x + 1 x + 1 x+1 。确认和数据可捎带一起发送
be piggybacked together。 - 头部长度。这个 4 4 4 位的字段
HLEN,指明了TCP头部中共有多少个 4 4 4 字节长的字。头部的长度可以在 20 20 20 字节到 60 60 60 字节之间。因此,这个字段的值在 5 ( 5 × 4 = 20 ) 5\ (5 \times 4=20) 5 (5×4=20) 到 15 ( 15 × 4 = 60 ) 15\ (15 \times 4 = 60) 15 (15×4=60) 之间。 - 保留
Reserved。这个 6 6 6 位的字段保留为将来使用。 - 控制
Control。这个字段定义了 6 6 6 种不同的控制位或标记,如图23.17所示。在同一时间可设置一位或多位。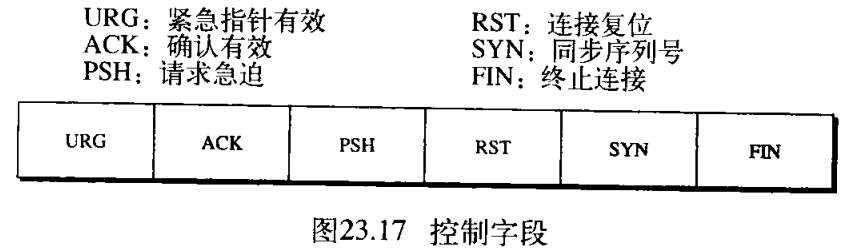
这些位用在TCP的流量控制、连接建立和终止、连接失败和数据传送方式等方面。表23.3显示了每位的说明。当讨论TCP的详细操作时,对它们做深入的讨论。
- 窗口大小
Window size。这个字段定义「对方必须维持的窗口的大小」(以字节为单位)。注意:这个字段的长度是 16 16 16 位,这意味着窗口的最大长度是 65535 65 535 65535 字节。这个值通常称为接收窗口receiving window, rwnd,它由接收方确定。此时,发送方必须服从接收端的支配。 - 校验和。这 16 16 16 位的字段包含了校验和。TCP校验和的计算过程,与前面描述的UDP所采用的计算过程相同。但是,在UDP数据报中校验和是可选的。然而,对TCP来说,将校验和包括进去是强制的,起同样作用的伪头部被加到段上。对TCP伪头部,协议字段的值是 6 6 6 。
- 紧急指示符
Urgent pointer。这个 16 16 16 位的字段只有当紧急标志置位时才有效。这个段包含了紧急数据,它定义了必须加到序列号上的一个数,以获取数据段中最后一个紧急字节的编号,稍后将会讨论它。 - 选项
Options。在TCP头部中可以有多达 40 40 40 字节的可选信息。这里不讨论这些选项,更多信息参见参考文献。
23.3.4 TCP连接
TCP是一种面向连接的协议。面向连接的传输协议会在源端和目的端之间,建立一条虚路径。然后,属于一个报文的所有段都沿着这条虚路径发送。整个报文使用单一的虚路径,有利于确认处理、以及对损坏或丢失帧的重发。
可能想知道TCP如何使用IP服务,一个无连接协议如何能面向连接?这就是TCP的连接是虚连接,而不是物理连接。TCP在一个较高层次上操作,TCP使用IP服务向接收方传递独立的段 individual segments ,但它控制连接本身。
- 如果一个段丢失或损坏了,则重新发送它。与TCP不同,IP不知道这个重新发送过程。
- 如果一个段失序到达,则TCP保存它、直到缺少的段到达。IP是不知道这个重新排序过程的。
在TCP中,面向连接的传输需要三个过程:连接建立、数据传输和连接终止。
1. 连接建立
TCP以全双工方式传输数据。当两个机器中的两个TCP建立连接后,它们就能够同时向对方发送段。这就表示,在传输数据之前,每一方都必须对通信进行初始化,并得到对方的认可 each party must initialize communication and get approval from the other party before any data are transferred 。
(1) 三次握手
在TCP中连接建立称为三次握手 three-way handshaking 。在例子中,称为客户的应用程序想要与另一个称为服务器的应用程序,使用TCP作为传输层协议建立连接。
该过程从服务器开始。服务器程序告诉它的TCP ,它已准备好接受一个连接。这就称为请求被动打开 passive open 。虽然TCP己准备好接受从世界上任何一个机器来的连接,但它自己并不能完成这个连接。
客户程序发出请求主动打开 active open 。想要与服务器进行连接的客户告诉它的TCP ,它需要连接到特定的服务器。TCP现在就开始如图23.18所示的三次握手过程。为了表示该过程,我们使用了两个时间序列,每端一个。
每个段头部的所有字段都有值,或许它的某些选项字也有。但是,我们每次仅表示「少数几个必须要知道的字段」,如果序列号、确认号、控制标记(仅是其中被置位的)和窗口大小等有值,我们就表示它们。这个阶段的三个步骤如下:
- 客户发送的第一个段是
SYN段。这个段仅有SYN标志被置位,它用于序列号同步(图画错了吧?)。它占用一个序列号。当数据传输开始时,序号加 1 1 1 。我们说SYN段不携带实际数据,但我们可以认为它是一个字节。 - 服务器发送第二个段,两个标志位
SYN和ACK置位的段,即SYN和ACK段。这个段有两个目的。它是另一方向通信的SYN段,并用ACK标志作为对第一个SYN段的确认。它占用一个序列号(来自服务器端的、对称的SYN段,也要占用序列号)。 - 客户发送第三个段。这个段仅仅是一个
ACK段,它使用ACK标志和确认序号字段来确认收到了第二个段。注意:这个段的序列号与SYN段中的序列号相同,ACK段没有占用任何序列号——ACK段,如果不携带数据,则它不占用序列号。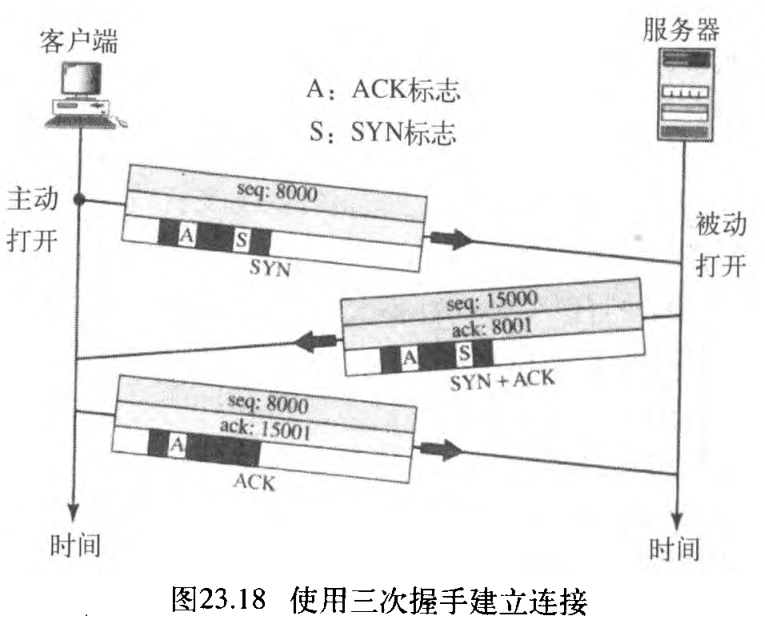
(2) 同时打开
当两个进程都发出一个主动打开时,可能会出现一种罕见的情况,称为同时打开 simultaneous open 。在这种情况下,两个TCP彼此发送 SYN + ACK 段,在它们之间建立一条单独的连接 one single connection is established between them 。
(3) SYN洪泛攻击
在TCP中的连接建立过程,易遭受到称为SYN洪泛攻击 SYN flooding attack 的严重安全问题:当一个恶意的攻击者将大量的 SYN 段发送到一个服务器,在数据报中通过伪装源IP地址,假装这些段来自不同的客户端时,就发生了这种情况。
假定客户机发出主动打开,服务器分配必要的资源,如生成通信表和设置计时器等。然后服务器送 SYN + ACK 段给这些假装客户,但这些段都丢失了。然而,在这段期间,许多资源被占用、但没有被使用。如果在短时间内,SYN 段的数量很大,服务器最终会耗尽它的资源而崩溃。
这种 SYN 洪泛攻击,属于一种称为拒绝服务攻击 denial-of-service attack 的安全攻击类型,此时一个攻击者通过大量的服务请求,独占系统,使得系统崩溃、拒绝对每个请求提供服务 the system collapses and denies service to every request 。
TCP的某些实现有减轻 SYN 攻击影响的策略。有些实现在特定时间周期内,对连接请求进行限制;另一些实现过滤掉来自「不需要的源地址」的数据报。一个新的策略是:使用 cookie 推迟资源分配,直到一个完整的连接建立。新的传输层协议STCP使用这种策略,在下一节讨论。
2. 数据传输
连接建立后,可进行双向数据传输 data transfer ,客户端与服务器双方都可发送数据和确认。稍后将学习确认的规则。目前,知道在同一段内携带确认时,在同一方向上也可以传输数据就行了,这就是数据捎带确认。
一个例子如图23.19所示,在连接建立后(图中没有表示出),客户端用两个段发送 2000 2000 2000 个字节的数据。然后,服务器用一个段发送 2000 2000 2000 个字节的数据。客户端发送另一个段。前面三个段携带数据与确认,但是最后一个段仅携带确认、且不占用序列号,这是因为已没有数据发送了。注意序列号与确认号的数值。
客户端发送的数据段有 PSH(急迫)标志,所以服务器TCP知道,当收到数据后立刻传递给服务器进程。稍后讨论这个标志的用法。另一方面,来自服务器的段没有设置急迫标志。大多数TCP实现都有选项,可设置或不设置此标志。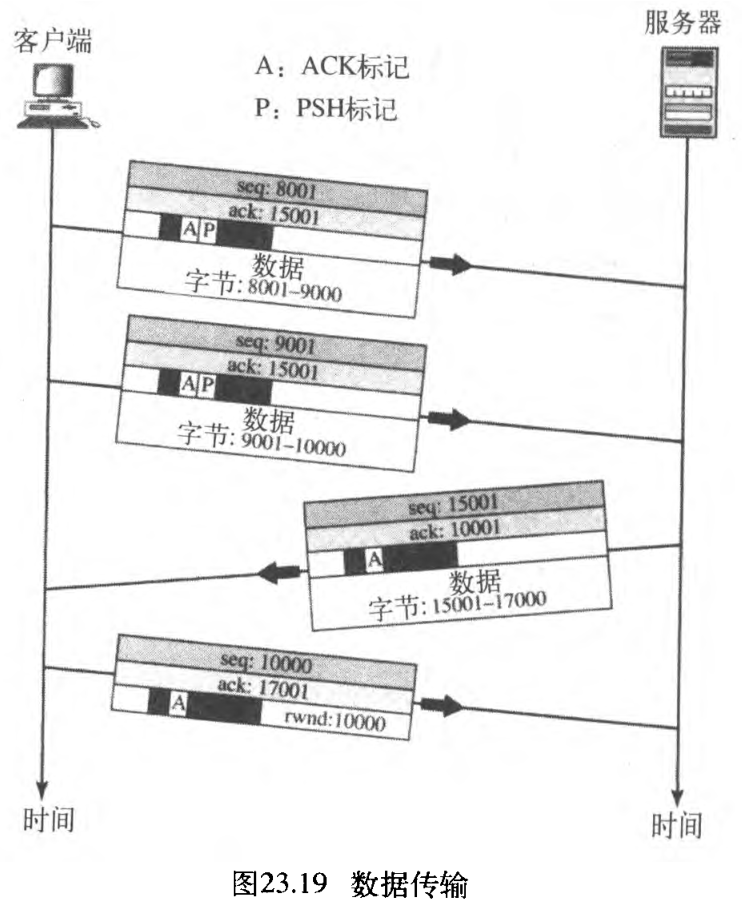
(1) 急迫数据 Pushing Data
我们知道,发送方的TCP使用缓冲区,存储来自发送方应用程序的数据流。发送方的TCP可以选择段的大小。接收方的TCP在数据到达时也将数据进行缓存,并当应用程序准备就绪时、或当接收端TCP认为方便时,将这些数据传递给应用程序。这种灵活性增加了TCP的效率。
但是,在有些情况下,应用程序并不需要这种灵活性。例如,应用程序与另一方应用程序进行交互式通信。一方的应用程序打算将其击键发送给对方应用程序,并希望接收到立即响应。数据的延迟传输和延迟传递,对这个应用程序来说是不可接受的。
TCP可以处理这种精况。在发送端的应用程序可请求急迫操作,这就表示:发送端的TCP不必等待窗口被填满,它创建一个段就立即将其发送;发送端的TCP还必须设置急迫位 PSH ,以告诉接收端的TCP——这个段所包括的数据,必须尽快地传递给接收应用程序,而不要等待更多数据的到来。
虽然急迫操作可由应用程序提出,但是现在的大多数实现却忽视了这些请求。TCP可以选择使用或不使用这个操作。
(2) 紧迫数据 Urgent Data
TCP是面向字节流的、面向连接的、可靠的协议。这就是说,从应用程序到TCP的数据被表示成一串字节流,数据的每一个字节在流中占有一位置。但是,在某些情况下,应用程序需要发送紧急字节 urgent bytes ,这表示:发送应用程序希望某一块数据由接收应用程序不按序读出。
作为一个例子,假定发送应用程序正在发送数据,以供接收应用程序处理。当处理结果返回时,发送应用程序出现了某些差错。它希望中止此过程,但它已发送了大量的数据。如果它发送出异常中止命令 Control + C ,这两个字符将被存放在接收端TCP缓冲区的末尾,当所有的数据被处理完毕时,这两个字符才被传递给接收应用程序。
解决这个问题的方法是,发送将 URG 位置 1 1 1 的段 a segment with the URG bit set :
- 发送应用程序告诉发送端的TCP这块数据是紧急的。发送端的TCP创建段,并将紧急数据放在段的开始,段的其余部分可以包括来自缓冲区的普通数据,头部中的紧急指针字段定义了紧急数据的结束和普通数据的开始
the end of the urgent data and the start of normal data。 - 当接收端的TCP接收到
URG位置 1 1 1 的段时,它就利用紧急指针的值,从段中提取出紧急数据,并不按序地将其传递给接收应用程序。
3. 连接终止
交换数据双方的任一方(客户或服务器)都可关闭连接,通常它是由客户端发起。当前大多数对连接终止的实现有两个方法:三次握手 three-way handshaking 和带有半关闭选项的四次握手 four-way handshaking with a half-close option 。
(1) 三次握手
当前对连接终止的多数实现是三次握手,如图23.20所示。
- 在正常情况下,从客户进程接收到一个关闭命令后,客户的TCP发送第一个段:
FIN段,即其中的FIN位置位。注意:FIN段可包含客户机要发送的最后数据块,或如图23.20所示的只是控制段。如果FIN段只是控制段、不携带数据,则该段仅占用一个序列号。 - 服务器TCP接收到
FIN段后,通知它的进程,并发送第二个段:FIN + ACK段,证实它接收到来自客户端的FIN段,同时宣布另一个方向的连接关闭。这个段还可以包含来自服务器最后数据块。如果FIN + ACK段没有携带数据,则该段仅占用一个序列号。 - 客户端的TCP发送最后一段:
ACK段,证实它接收到来自服务器的FIN段。这个段包含确认号,它是前面接收到来自服务器FIN段的序号加 1 1 1 。这个段不携带数据、也不占用序列号。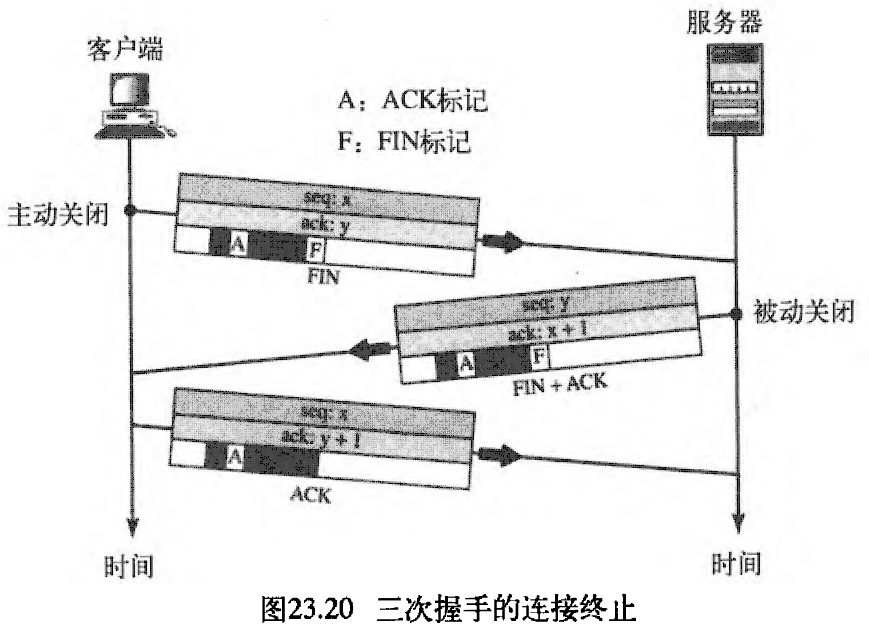
(2) 半关闭
在TCP中,一端可以停止发送数据后,还可以继续接收数据。这就是所谓的半关闭 half-close 。虽然任一端都可发出半关闭,但通常都是由客户端发起的。当服务器需要所有数据才能开始处理时,可能会发生半关闭。
例如,排序是一个很好的例子。当客户端发送数据给服务器进行排序时,服务器需要在开始排序之前接收到全部数据。这意味着,客户端发送完全部数据之后,它在出外/站方向的连接可以关闭,但在入内/站方向必须保持打开状态,才能接收已排序的数据。服务器在接收到数据后,还需要时间进行排序,它的对外方向必须保持打开。
图23.21表示了半关闭的例子。客户端发送 FIN 段半关闭连接,服务器通过发送 ACK 段确认半关闭。从客户端到服务器的数据传输结束,但是服务器还可以发送数据。当服务器已经发送完被处理的数据时,它发送一个 FIN 段,该 FIN 段由客户端的 ACK 来确认。
.
连接半关闭后,数据可从服务器传送给客户端,而确认可从客户端传送给服务器。注意所用的序列号,第二个段 ACK 没有占用序列号,虽然客户端已接收了序列号 y − 1 y-1 y−1, 正在期望的是 y y y , 但服务器的序列号还是 y − 1 y - 1 y−1 。当连接最后关闭时,最后 ACK 段的序列号还是 x x x ,因为没有序列号在该方向的数据传输过程中被消耗。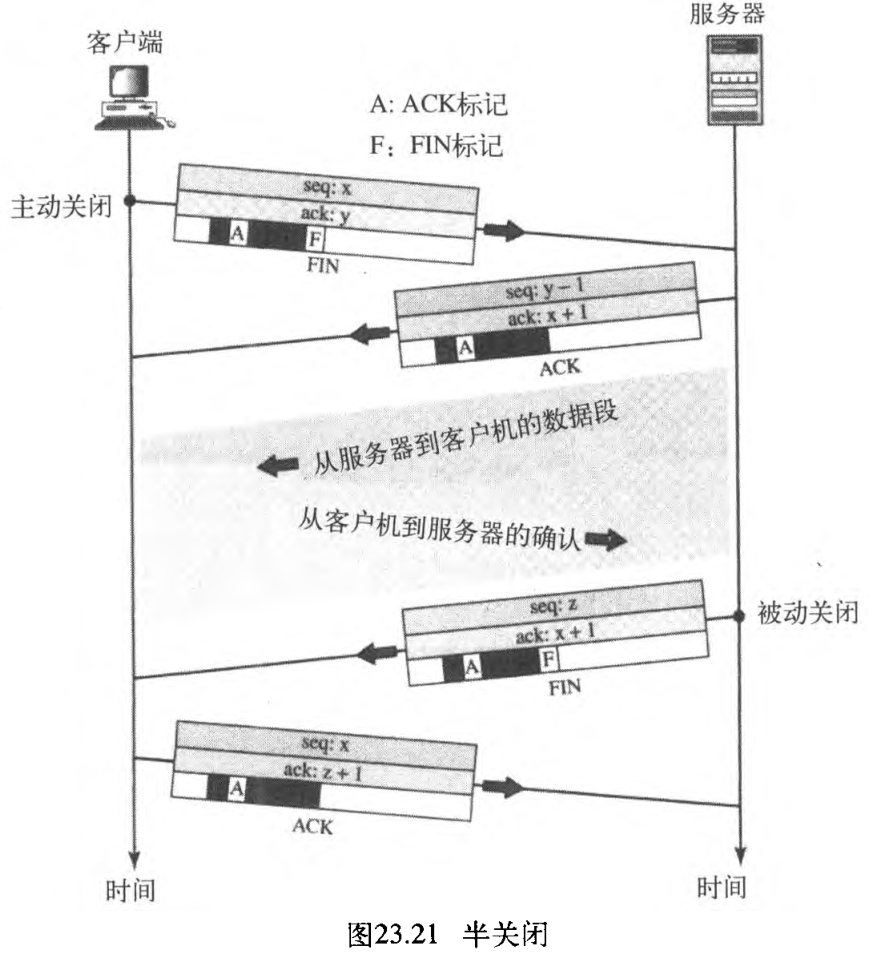
23.3.5 流量控制
如【计算机网络】第三部分 数据链路层(11) 数据链路控制讨论的那样,TCP使用滑动窗口处理流量控制。TCP使用滑动窗口协议,但其使用的滑动窗口协议界介于回退 N N N 帧与选择重发之间的滑动窗口 between the Go-Back-N and Selective Repeat sliding window ——由于它不使用 NAK ,看起来像回退 N N N 帧协议;由于接收方保存失序的段、直到丢失的段到达,它看起来又像选择重发。可是,这里的滑动窗口与数据链路所用的滑动窗口有两大点不同。
- 第一点,TCP的滑动窗口是面向字节的
byte-oriented,而数据链路层讨论的滑动窗口是面向帧的frame-oriented; - 第二点,TCP的滑动窗口是可变大小
variable size的,而数据链路层讨论的滑动窗口是固定大小fixed size的。
图23.22表示了TCP 中的滑动窗口,该窗口跨越缓冲区的一部分,其中存储着从进程接收到的字节,窗口内的字节都是在传输中的字节 the bytes that can be in transit ,可以发送它们、而不必考虑来自另一端的确认。这个设想的窗口有两个边沿:左边沿和右边沿。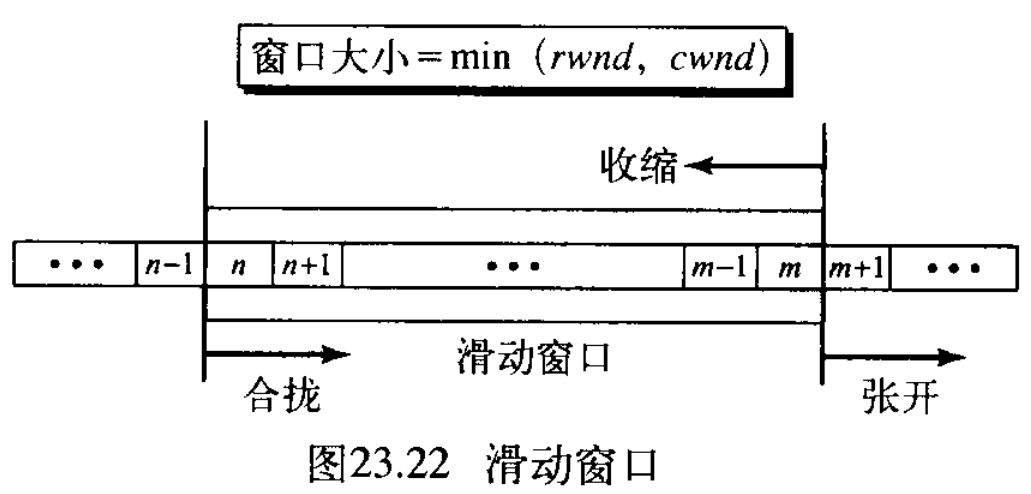
窗口是张开的、合拢的或收缩的 opened, closed, or shrunk 。正如将看到的,这三种活动是由接收方控制的(也取决于网络中的拥塞)而不是发送方。在这个问题上,发送方必须服从接收方的命令。
- 窗口张开是指右边沿向右移动,这允许缓冲区中有更多符合发送条件的新字节。
- 窗口合拢是指左边沿向右移动,即有些字节已被确认,发送方不必再为这些字节而担忧。
- 窗口收缩是指右边沿向左移动。因为这意味着取消某些字节的发送资格,因此强烈建议在实现中不使用它。如果发送方已经发送了这些字节,则会出现问题。注意:左边沿不能向左移动,因为这将宣告先前发送的某些确认无效
this would revoke some of the previously sent acknowledgments。
使用滑动窗口可使传输更加有效,同时也可以控制数据流,使得目的端不致因数据来得过多而瘫痪。一端的TCP窗口大小取决于两个值中较小的一个:接收方窗口 receiver window, rwnd 值和拥塞窗口 congestion window, cwnd 。接收方窗口值是在包含确认的段中由另一端宣布的值,它就是另一端在它的缓冲溢出和数据被丢弃之前、可以接收的字节个数。拥塞窗口值是网络为避免拥塞而确定的值,在后面讨论拥塞。
【例23.4】如果接收方主机 B B B 有一个 5000 5000 5000 个字节的缓冲区,已接收到但并未处理的 1000 1000 1000 个字节数据。试问主机 A A A 的接收方窗口 rwnd 的值是多少?
解:rwnd 的值 = 5000 − 1000 = 4000 =5000 - 1000=4000 =5000−1000=4000 ,主机 B B B 在它的缓冲溢出之前仅能接收 4000 4000 4000 个字节。主机 B B B 在下一段向主机 A A A 宣布。
【例23.5】如果 rwnd 的值是 3000 3000 3000 ,而 cwnd 值是 3500 3500 3500 ,试问主机 A A A 的窗口大小是多少?
解:窗口大小是 rwnd 和 cwnd 中较小的一个,它应是 3000 3000 3000 个字节。
【例23.6】图23.23表示了一个不切实际的滑动窗口,发送方已发送了 202 202 202 个字节。我们假定 cwnd 是 20 20 20(实际上,这个值是上千字节),接收方已发一个 rwnd 为 9 9 9(实际上,这个值也是上千字节)而确认号为 200 200 200 的 ACK 段。发送窗口的大小是 rwnd 和 cwnd 的最小值,即 9 9 9 个字节。字节号 200 200 200 到 202 202 202 都已发送、但未被确认 are sent, but not acknowledged 。字节号 203 203 203 到 208 208 208 可以发送、而不必考虑从另一端来的确认 can be sent without worrying about acknowledgment 。字节号 209 209 209 和它以上各字节不可能发送。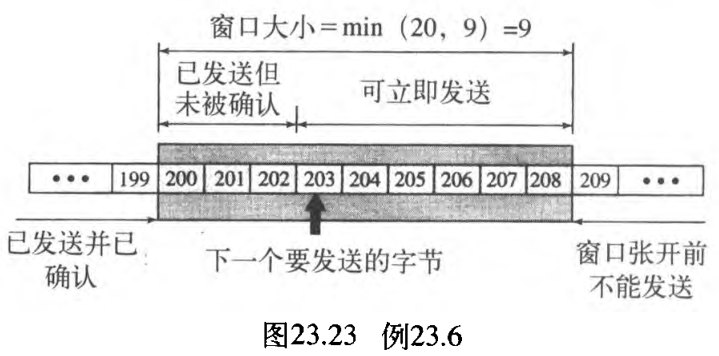
TCP滑动窗口的要点如下:
- 窗口大小是
rwnd和cwnd中的最小值; - 发送方不必发送一个全窗口大小的数据;
- 接收方可张开或合拢窗口,但不能收缩窗口;
- 只要不引起窗口收缩,目的方可以随时发送一个确认;
- 接收方可暂时关闭窗口,然而在窗口关闭后,发送方总是可以发送一个 1 1 1 字节的段。
23.3.6 差错控制
TCP是一个可靠的传输层协议。这意味着:向TCP发送数据流的应用程序,依靠TCP将整个数据流传递给另一端的应用程序,并且是按序的、无差错的、没有任何一部分丢失或重复的。
TCP使用差错控制提供可靠性。差错控制包括一些机制:检测受到损坏的段、丢失的段、失序的段和重复的段。差错控制还包括检测出差错后纠正差错的机制。TCP中的差错检测和纠正是通过三种简单工具来完成的:校验和、确认和超时。
1. 校验和
每个段都包括校验和字段,用来检查受到损坏的段。如果段被损坏,它将被目的端TCP丢弃,并认为是丢失了。
TCP在每段中强制使用一个 16 16 16 位的校验和。在【计算机网络】第五部分 传输层(24) 拥塞控制和服务质量中会看到,这 16 16 16 位的校验和对于新的传输层协议SCTP是不适合的。因为SCTP将整个头部格式重新配置,而TCP不可能改变它。
2. 确认
TCP使用确认方法来证实收到了数据段。不携带数据、但占用序列号的一些控制段也要确认,但 ACK 段(控制标记中 ACK 置位、但不携带数据的段)不占用序列号,是不要确认的。
3. 重传
差错控制机制的核心是段的重传:当一个段损坏、丢失或延迟时,就重传这个段。在当前实现中,有两种情况要重传段:重传计时器 retransmission timer 到时或当发送方收到三个重复的 ACK 时。注意:不占用序列号的段不宣传,尤其是 ACK 段不重传,对 ACK 段也不设置重传计时器。
(1) RTO后重传
TCP对所有重要的段(已发送、但还未被确认)的最新实现使用了一个重传超时 retransmission time-out, RTO 计时器。当计时器到时,重发一个最早的重要的段 the earliest outstanding segment ,即使没有接收到的 ACK 可能是由于段被延迟、ACK 被延迟或丢失确认等。注意:对仅携带确认的段没有设置超时计时器,这说明这样的段不需要重发。
在TCP中,RTO 的值是动态的,根据段的往返时间 round-trip time, RTT 进行更新—— RTT 是一个段到达目的端、并接收到一个确认所需要的时间,它使用了一种类似于第12章讨论的 back-off 往返策略。
(2) 三个重复 ACK 段之后的重发
如果 RTT 的值不是很大,先前关于段重传的规则就足够了 。但有时某一段丢失了,而接收端收到了许多失序的段,它们不可能都被存储(有限的存储器大小)。
为了缓解这种情况,当今的大多数实现遵循三次重复 ACK 规则 three-duplicate-ACKs rule ,立即重发缺少的段。这一特点称为快速重传 fast retransmission ,在稍后的例子和拥塞控制中将会看到。
(3) 失序的段
当一个段被延迟、丢失或丢弃时,后面一些段的到达就失序了。TCP最初的设计是丢弃所有失序的段,并重传那个缺少的段、以及其后的一些段。
当今大多数的实现不丢弃失序的那些段,暂时将它们存储,并标记它们为失序的段,直到缺少的那个段到达。但是注意:这些失序的段不传递给进程,TCP确保数据按序传递给进程。即数据可以失序到达、并被接收的TCP暂时存储,但TCP确保传递给进程的段是有序的。
4. 某些情况
在本节中,给出TCP操作时某些情况的例子。在这些情况中,用长方形表示段。如果段携带数据,就显示字节序列号的范围和确认字段的值。如果段仅是一个确认,仅用小方框中的确认号表示。
(1) 正常操作
第一种情况表示了两个系统之间的双向数据传输,如图23.24所示。客户TCP发送一个段,而服务器TCP发送三个段。图23.24表示了应用于每个确认的规则:有数据要发送,所以该段显示期望接收的下一个字节序号。
当客户端接收到来自服务器的第一个确认时,它没有更多的数据要发送,它仅发送一个 ACK 段。但是,该确认段需要延迟 500 ms 500\textrm{ms} 500ms ,以观察是否还有更多的段到达。当计时器到时,客户端触发一个确认,这样做是因为客户端不知道是否还有其他的段到来,它不再延迟这个确认。当下一个段到达时,启动另一个确认计时器。但是,在它到时之前,第三个段到达,第三个段的到达触发另一个确认。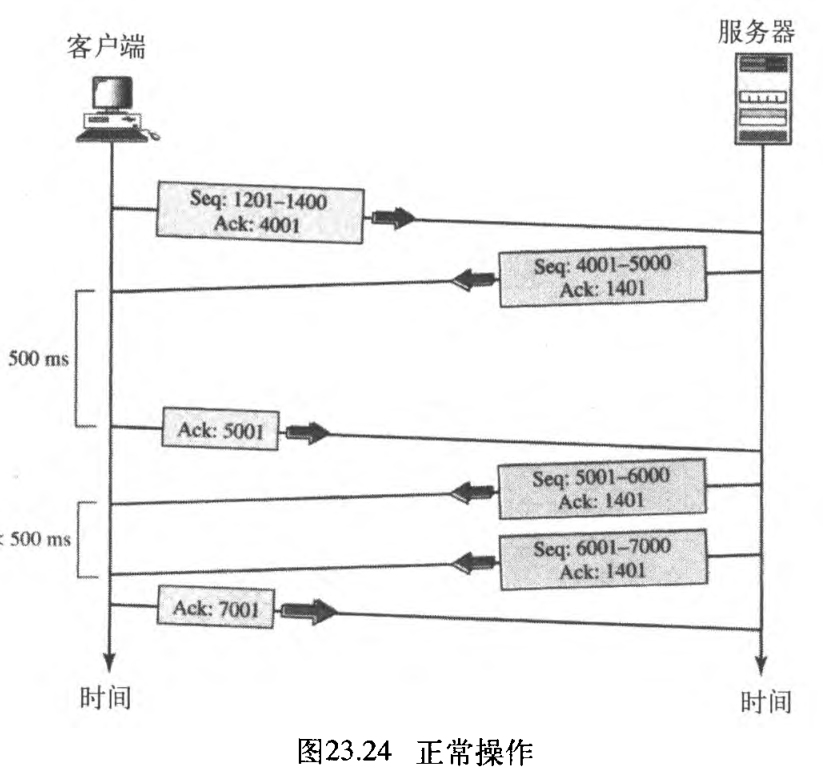
(2) 丢失的段(超时重传)
在这种情况下,我们说明了当一个段丢失或损坏时,将会发生什么。接收方对丢失的段和损坏的段用同样的方法处理:丢失的段是在网络中的某处被丢失的,损坏的段是被接收方本身丢弃的。图23.25表示了一种情况,在这种情况下,一个段可能由于拥塞,被网络中的某个路由器丢弃或丢失。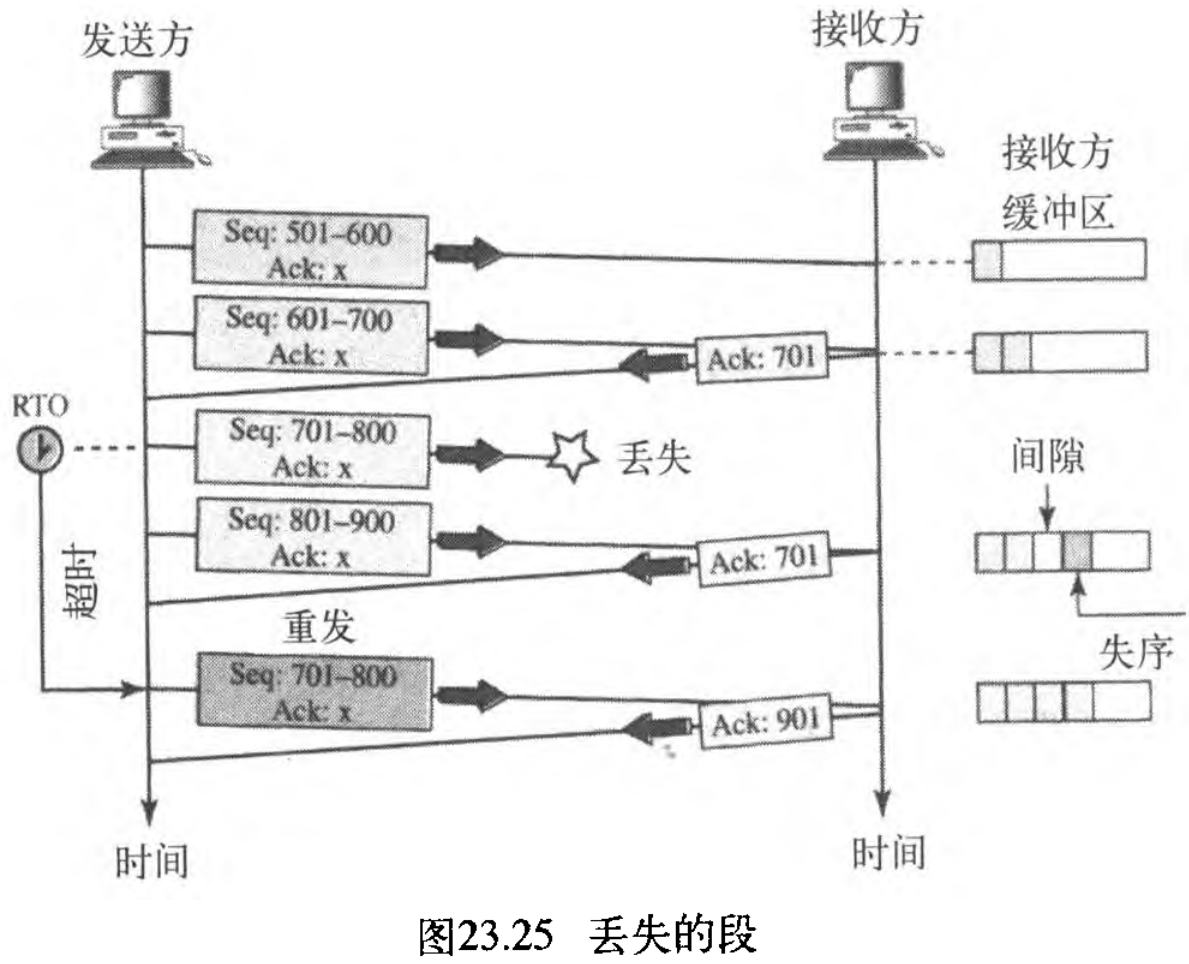
我们假定数据传输是单向的:一方发送,另一方接收。在这个特定情况下,发送方发送段 1 1 1 和段 2 ,这两个段立即被一个 ACK 确认。但是,段 3 3 3 被丢失了,接收方接收到段 4 4 4 ,发生了失序。接收方将数据存储在其缓冲器的段中,但留出一个间隙,以指明数据中存在不连续性。接收方立即给发送方发送一个确认,表示了它期望的下一个字节( 701 701 701)。注意:接收方存储从 801 801 801 到 900 900 900 的字节,但在这个间隙被填充之前、不将这些字节传递给应用程序。接收方TCP仅将有序的数据传递给进程。
我们已表示了最早的重要段的计时器 the earliest outstanding segment ,因为接收方永远不会给丢失或失序段发送确认(段 4 4 4 得到的确认号仍是 701 701 701 ),因此这个定时器肯定会超时。当该计时器到时时,发送方TCP重发段 3 3 3 ,该段此时到达并被正确确认。注意:按照相应的规则,第二个确认和第三个确认的值是不同的,第三个确认一次性确认了重发的段 3 3 3 和此前到达的段 4 4 4 。
(3) 快速重传
在这个情况中,我们要表示快速重传的思想。除了 RTO 具有较大的值外,该情况与第二种情况相同(见图23.26)。当接收方接收到第四个、第五个和第六个段时,它触发一个确认。发送方接收到 4 4 4 个具有相同值的确认( 3 3 3 个是重复的)。虽然段 3 3 3 的计时器还没有到时,但快速传输要求立即重发段 3 3 3 ,该段是所有这些确认所期望的。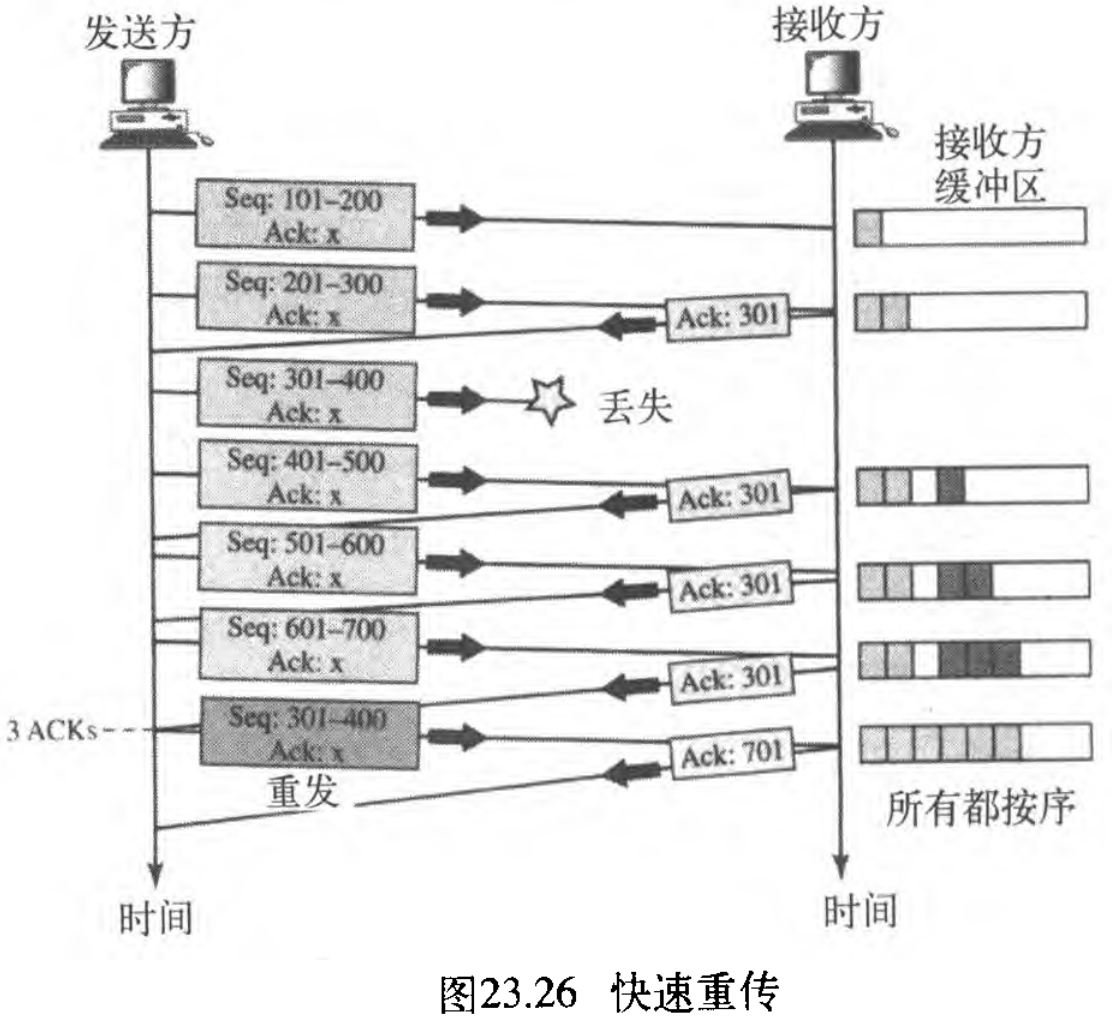 注意:虽然有 4 4 4 个段都没被确认,但只有一个段被重新传输。当发送方接收到这个重发的
注意:虽然有 4 4 4 个段都没被确认,但只有一个段被重新传输。当发送方接收到这个重发的 ACK 时,因为确认是累计的,因此它知道这 4 4 4 个段是安全的和可靠的。
23.3.7 拥塞控制
在【计算机网络】第五部分 传输层(24) 拥塞控制和服务质量讨论TCP的拥塞控制。
23.4 SCTP
流控制传输协议 SCTP 是一种新的可靠的、面向报文的传输层控制协议。然而,SCTP主要是为最近引入的因特网应用而设计的。这些新的应用,如 IUA(IP上的ISDN)、M2UA 和M3UA(电话信令)、H.248(媒体网关控制)、H.323(IP电话)和 SIP(IP电话)等,都需要提供比TCP更复杂的服务。
SCTP提供了更高的性能和可靠性。我们简要比较UDP 、TCP和 STCP的性能。
- UDP是一个面向报文
message-oriented的协议,进程将报文传递给UDP,将它封装在一个用户数据报中,通过网络发送。UDP保留报文边界,每个报文与其他报文无关。正如在后面将看到的,当我们处理一些应用,如IP电话和实时数据传输时,这个特性是想要的。但是,UDP是不可靠的,发送方不知道报文的命运,报文可能会丢失、重复或失序;UDP也还缺乏其他特性,如缺少友好的传输层协议所需要的拥塞控制和流量控制。 - TCP是一个面向字节
byte-oriented的协议。它从进程中接收一个报文或多个报文,以一个字节流的方式存储它们,并以段的方式发送它们,没有保存报文的边界。但是,TCP是一个可靠的协议,重复段会被删除、丢失的段会重发,并且字节按序传递到端进程。TCP还有拥塞控制和流量控制机制。 - SCTP兼有UDP和TCP的特性。SCTP是一个可靠的面向报文的协议,它保存报文的边界,同时它检测丢失的数据、重复的数据和失序的数据。它还有拥塞控制和流量控制机制。稍后会看到,SCTP还有UDP和TCP中没有的一些新特性。
23.4.1 SCTP服务
在讨论SCTP操作之前,先说明SCTP向应用层进程提供的服务。
1. 进程到进程通信(多流服务)
SCTP使用TCP空间中的熟知端口号,表23.4列出了SCTP使用的一些额外的端口。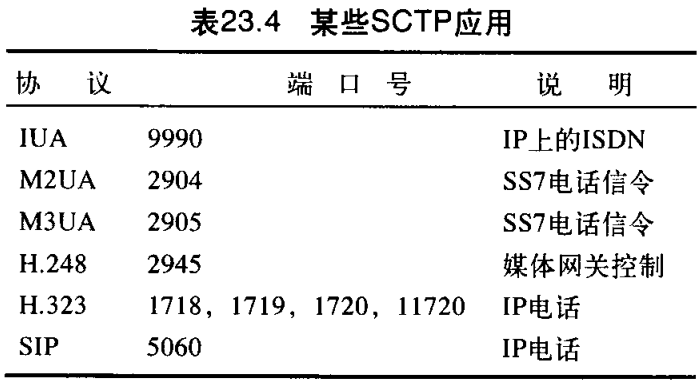
在前一节讨论过TCP是一种面向流的协议,TCP客户端与 TCP服务器的每一次连接,都包含了一个单一的流。这个方法存在的问题是,在流中任何一点的丢失,会阻塞其余数据的传递。当传输文本时,这还可以接受;但当传输实时数据(音频或视频)时,这就不能接受了。
SCTP在每一次连接中提供多流服务 multistream service ,用SCTP专门名词称为关联 association ,SCTP的一次关联能包含多个流。如果多流中某一个被阻塞,其余的流仍然可传递它们的数据。这种思想类似于高速公路上的多车道,每一个车道可用于不同类型的交通量。例如,一条车道用于正常的交通,另一条车道用于合伙车。如果正常的交通受到阻塞,合伙车辆依旧可达目的地。图23.27表示了多流传递的思想。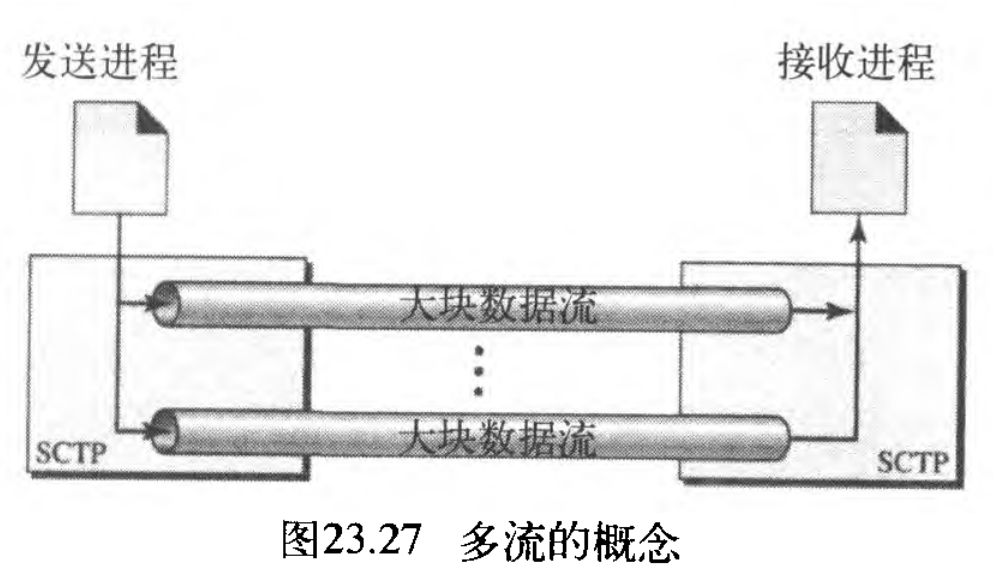
2. 多接口
一个TCP连接包括了一个源IP地址和一个目的IP地址。这就是说,即使发送方或接收方是一个多接口主机 multihomed host(即连接到具有多个IP地址的多个物理地址上),在连接期间,每端的这些IP地址中仅有一个是可用的 only one of these IP addresses per end can be utilized 。
另一方面,SCTP关联支持多接口服务 multihoming service ,发送和接收主机可以在每一端为关联定义多个IP地址。在这个容错方法 fault-tolerant approach 中,当一条通路发生故障时,可以用另一个接口不中断地传递数据。当发送和接收实时有效载荷时,如因特网上的电话,这个特性是很有用的。图23.28表示了多接口的思想。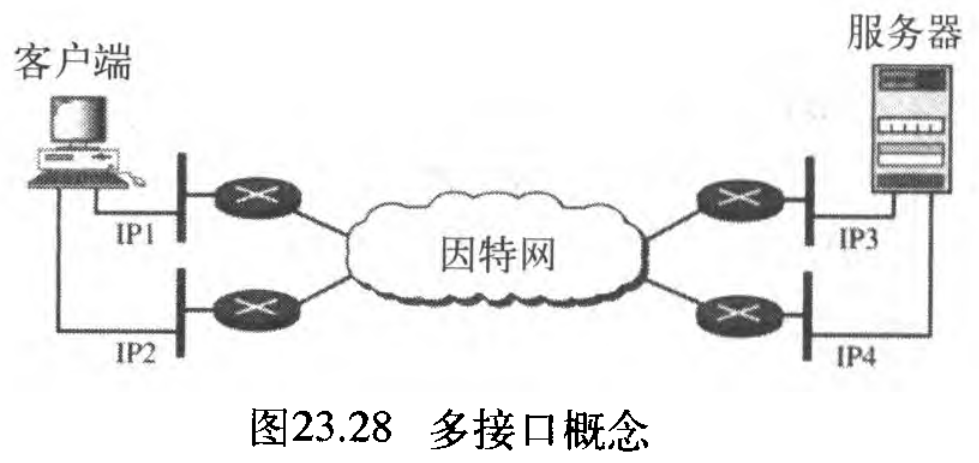
在图23.28中,客户端用两个IP地址分别连接两个局域网络,服务器也用两个IP地址分别连接两个网络。客户端和服务器可用四个不同的IP地址对做出一个关联。但是应注意,在目前SCTP的实现中,仅有一对IP地址可用于正常的通信;当选用的主路径有故障时,可使用替换路径。换言之,目前SCTP不允许不同路径共用。
3. 全双工通信
像TCP一样,SCTP提供全双工服务。在全双工服务中,数据可同时在两个方向流动。每一个SCTP都有一个发送和接收缓存区,在两个方向都可以发送分组。
4. 面向连接服务
像TCP一样,SCTP是面向连接的协议。但是,在SCTP中连接被称为关联。站点 A A A 的进程要向站点 B B B 的另一个进程发送或接收数据时,其步骤如下:
- 两个SCTP彼此建立关联:
- 双方向交换数据$
- 终止关联。
5. 可靠的服务
像TCP一样,SCTP是可靠的传输协议。它利用确认机制检测数据是否安全和可靠地到达。在差错控制这一节进一步讨论这个特性。
23.4.2 SCTP特性
首先讨论SCTP的一般特性,然后将这些特性与TCP特性相比较。
1. 传输序列号
TCP的数据单元是字节,在TCP中用序列号对字节编号,以控制数据传输。另一方面,SCTP的数据单元是数据大块 DATA chunk 。由于分段原因,数据大块与来自进程的报文可能有、也可能没有一一对应的关系(以后讨论)。在SCTP中,用数据大块的编号控制数据传输,SCTP使用传输序列号 transmission sequence number, TSN 对数据大块进行编号。
换言之,SCTP中的 TSN 所起的作用类似于TCP中的序列号。TSN 是 32 32 32 位长,初始值可取 0 0 0 到 2 32 − 1 2^{32} -1 232−1 之间的随机数。每个数据大块的头部必须有相应的 TSN。
2. 流标识符
在TCP中,每一次连接仅有一个流。而在SCTP中,每次关联可以有多个流。因此,每个流需要用流标识符 SI 进行标识。注意,每个数据大块的头部必须有 SI ,这样当它到达目的端时,它可正确地放入它的流中。SI 是从 0 0 0 开始的 16 16 16 位数字。
3. 流序列号
当一个数据大块到达目的SCTP时,它被传递到适当的流中,并按原序排列。这就是说,除了 SI 之外,为了区别属于同一个流中的不同数据大块,SCTP还用流序列号 stream sequence number, SSN 对每个流中的每个数据大块进行定义。
4. 分组
在TCP中,段携带数据和控制信息,数据作为一组字节被携带,而控制信息是用它头部的 6 6 6 个控制标记来定义。而SCTP的设计完全不同:数据作为数据大块被携带,控制信息作为控制大块被携带,多个控制大块与数据大块可合并成一个分组 packet 。SCTP中一个分组起的作用与TCP中的段相同 A packet in SCTP plays the same role as a segment in TCP 。
图23.29比较了TCP的段与 SCTP的分组。扼要列出SCTP的分组和TCP的段不同: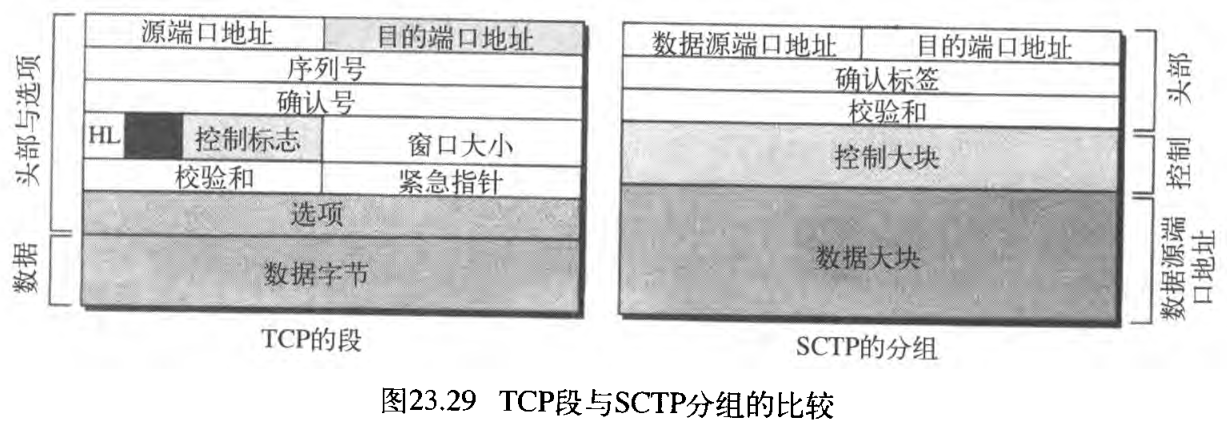
- TCP中的控制信息在头部,而SCTP中的控制信息是在控制大块中,有几种类型的控制大块,每个类型用于不同的目的;
- 一个TCP段中的数据作为一个实体处理,而一个SCTP分组可以携带多个数据大块,每个可能属于不同的流。
- 选项可以是TCP段的一部分,而SCTP分组不存在选项,SCTP中的选项是通过定义新的大块类型来处理的
Options in SCTP are handled by defining new chunk types。 - TCP头部的强制性部分是 20 20 20 个字节,而SCTP头部仅是 12 12 12 个字节。SCTP头部较短是由于下列因素:
- SCTP序列号
TSN属于每个数据大块,因此它位于数据大块的头部; - 确认号和窗口大小都是每个控制大块的一部分;
- SCTP头部的长度是固定的 12 12 12 个字节) ,因此不需要头长度字段(TCP段中用
HLEN表示),不存在用选项生成头部的长度; - 在SCTP中没有紧急指针。
- SCTP序列号
- TCP中的校验和是 16 16 16 位,而SCTP中的校验和是 32 32 32 位。
- SCTP中确认标签
verification tag是关联标识符association identifier,而在TCP中是没有的。TCP中的IP地址和端口地址一起定义了一个连接,而在SCTP中,用不同的IP地址实现多接口,定义每个关联都需要唯一的确认标签。 - TCP段的头部有一个序列号,它定义数据部分中的第一个字节编号,而SCTP分组可包含多个数据大块,用
TSN, SI, SSN定义每个数据大块。 - TCP中有些段携带控制信息(如
SYN和FIN),它要占用一个序列号,在SCTP中,控制大块不使用TSN, SI, SSN。这三个标识符仅属于数据大块,而不是属于整个大块。
在SCTP中,控制信息和数据信息在分开的大块中携带。在SCTP中,有数据大块、流和分组:一个关联可发送多个分组,一个分组可包含多个大块,而各个大块可属于不同的流。
为了使这些术语定义得更清晰,让我们假定进程 A A A 用 3 3 3 个流发送 11 11 11 个报文给进程 B B B 。前面的 4 4 4 个报文用第一个流,其次的 3 3 3 个报文用第二个流,最后的 4 4 4 个报文用第三个流。虽然一个长的报文可能被多个数据大块携带,但是我们还是假定每个报文装载在一个数据大块中。因此,我们在 3 3 3 个流中有 11 11 11 个数据大块。
应用进程传递 11 11 11 个报文给STCP ,这里对每个报文标上适合的流记号 。虽然进程可传递第一个流的一个报文,然后再传递第二个流的另一个报文。但是,我们假定首先传递属于第一个流的所有报文,然后再传递属于第二个流的所有报文,最后传递属于第三个流的所有报文。
我们还假定网络仅允许每个组有三个数据大块。这就是说,我们需要 4 4 4 个分组如图23.30所示。第一个分组和一部分第二个分组携带流 0 0 0 中的数据大块,第二个分组和第三个分组携带流 1 1 1 中的数据大块,第三个分组和第四个分组携带流 2 2 2 中的数据大块。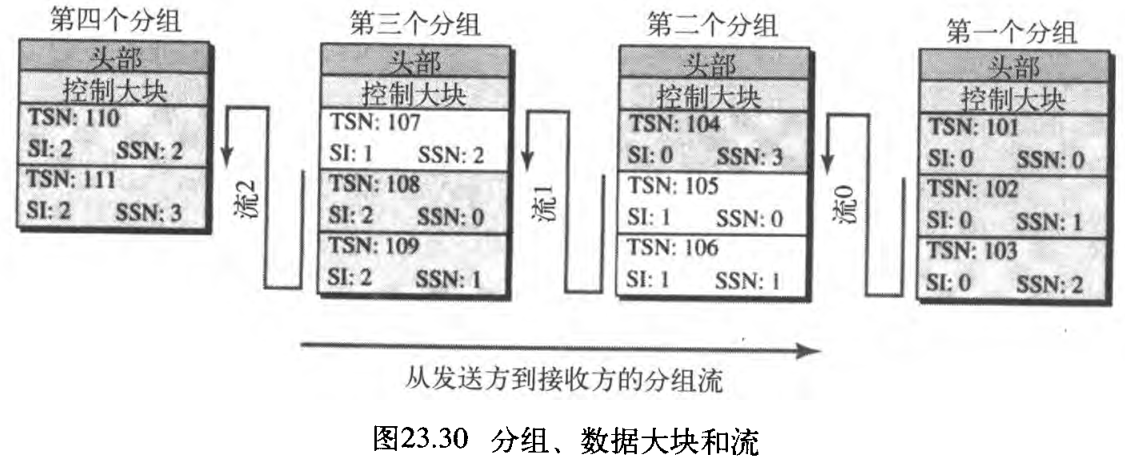
注意,每个数据大块需要三个标识符:TSN, SI, SSN 。TSN 是累计数,将会看到它也用于流量控制和差错控制。SI 定义这些块所属的流。SSN 定义了在特定流中数据大块的次序。在我们的例子中,对每个流,SSN 都从 0 0 0 开始编号计数。
5. 确认号
TCP确认号是面向字节的,它指的是序列号,而SCTP确认号是面向大块的,它指的是 TSN 。TCP与SCTP确认号的第二个不同是控制信息,在TCP中控制信息是段头部的一部分,为了确认只携带控制信息的段 segments that carry only control information ,TCP使用序列号和确认号(例如,SYN 段需要用 ACK 段确认)。
但在SCTP中,确认号仅用于对数据大块的确认。此外,控制大块携带控制信息,它不使用 TSN ,如果需要的话,这些控制大块用另一个适当类型的控制大块来确认(有些不需要确认)。例如,INIT 控制大块是由 INIT ACK 大块来确认,它不需要序列号或确认号。
6. 流量控制
像TCP一样,SCTP实现流量控制、以避免接收方崩溃,在后面讨论SCTP的流量控制。
7. 差错控制
像TCP一样,SCTP实现差错控制、以提供可靠性。TSN 号和确认号用于差错控制,在后面讨论差错控制。
8. 拥塞控制
像TCP一样,SCTP实现拥塞控制、以决定多少个数据大块可置于网络中。在【计算机网络】第五部分 传输层(24) 拥塞控制和服务质量讨论拥塞控制。
23.4.3 分组格式
在这一节说明分组格式和大块的各种类型。在本节中所列出的大多数信息,在后面变得更加清楚。
SCTP分组有一个强制性的通用头部和一组称为大块的块的集合 a set of blocks called chunks 。大块有两种类型:数据大块 data chunks 和控制大块 control chunks 。控制大块控制和维护关联,而数据大块携带用户数据。在一个分组中,控制大块在数据大块之前。图23.31表示了SCTP分组的一般格式。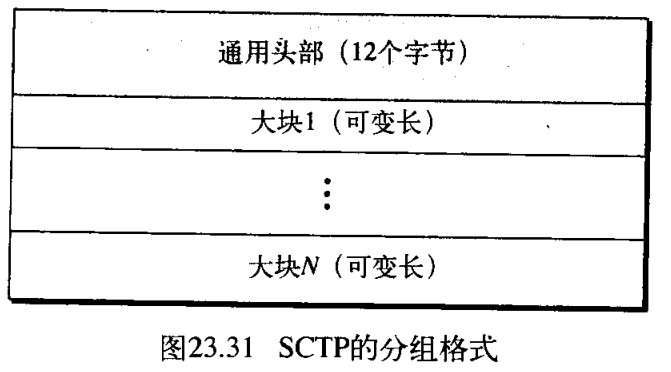
1. 通用头部
通用头部 general header 定义分组所属的每个关联的端点 the endpoints of each association to which the packet belongs ,保证了分组属于一个特定的关联,并保护分组内容包括本身头部的完整性。通用头部格式如图23.32所示。
通用头部有 4 4 4 个字段:
- 源端口地址。这是一个 16 16 16 位字段,它定义进程发送分组的端口号。
- 目的端口地址。这是一个 16 16 16 位字段,它定义进程接收分组的端口号;
- 确认标签。这是一个数,它将一个分组与一个关联相匹配。它防止将以前关联的一个分组误认为是这个关联中的一个分组。它作为关联的一个标识符,在关联期间,它在每个分组中都是相同的。在关联中,每个方向有各自的确认标签
There is a separate verification used for each direction in the association。 - 校验和。这是一个 32 32 32 位字段,它包含CRC-32校验和。注意校验和的长度从 16 16 16 位(UDP、TCP和IP)增加到 32 32 32 位,并允许用CRC-32校验和。
2. 大块
大块携带控制信息或用户数据,每块的详细格式超出了范围。所有大块的前三个字段是相同的,信息字段取决于大块类型。最重要的是,SCTP要求信息部分是 4 4 4 字节的倍数,如果不是,在信息部分的末尾增加填充字节( 8 8 8 个 0 0 0) 。一些大块和它们的说明见表23.5: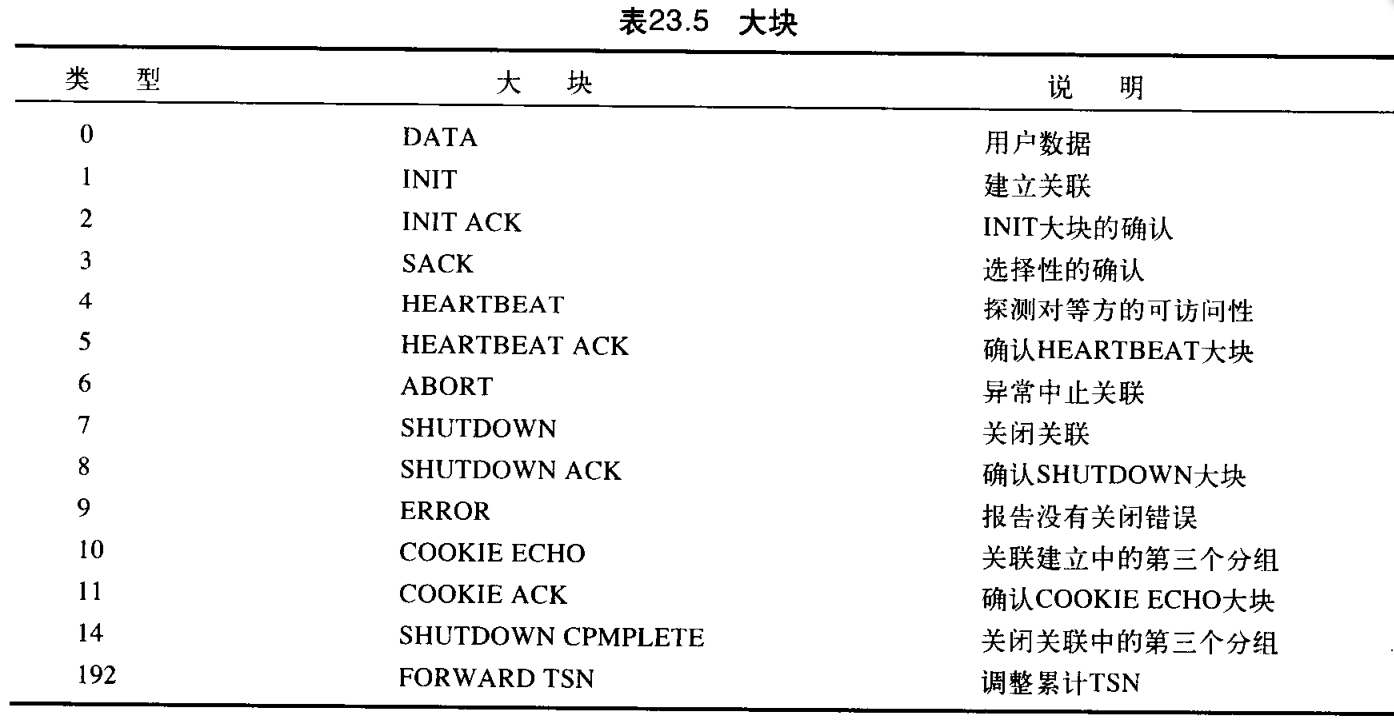
23.4.4 SCTP关联
像TCP一样,SCTP是一个面向连接的协议。但是,为了强调其多接口性,SCTP中的连接被称为关联。
1. 关联建立
SCTP中的关联建立 association establishment 要求四次握手 four-way handshake 。在这个过程中,一个进程(通常是客户)想要与另一个进程(通常是服务器)建立关联,使用SCTP作为传输层协议。
与TCP相似,SCTP服务器需要准备接收一个关联(被动打开),而由客户发起建立关联(主动打开),SCTP关联建立,如图23.33所示。在正常情形下,步骤如下:
- 客户端发送第一个分组,它是一个
INIT大块INIT chunk; - 服务器发送第二个分组,它是一个
INIT ACK大块INIT ACK chunk,携带INIT或INIT ACK大块的分组中不允许有其他大块; - 客户端发送第三个分组,它包含一个
COOKIE ECHO大块COOKIE ECHO chunk,这是一个很简单的大块,它毫无改变地回应由服务器发送的cookie。SCTP允许在这个分组中包含数据大块; - 服务器发送第四个分组,它包含对接收到的
COOKIE ECHO大块进行确认的COOKIE ACK大块COOKIE ACK chunk。SCTP允许在这个分组中包含数据大块。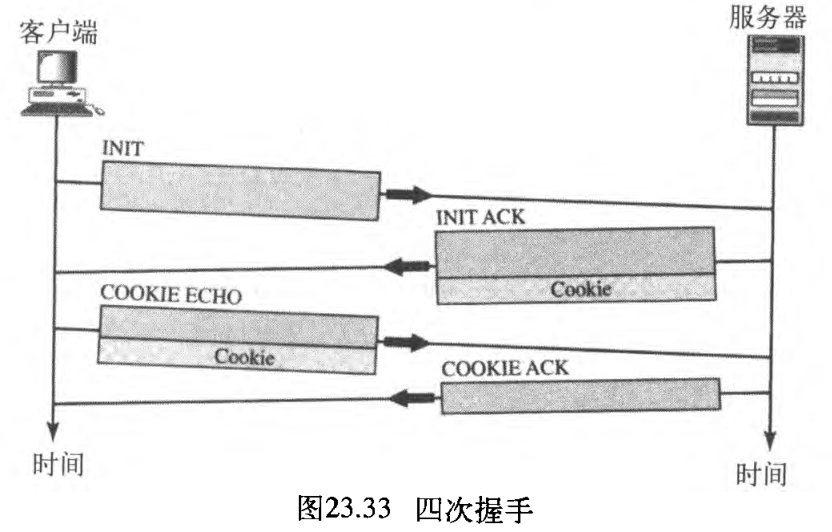
Cookie
在前几节中,讨论过SYN洪泛攻击。利用TCP,一个恶意的攻击者可以向一个TCP服务器,发送大量的、具有不同假IP地址的伪造的 SYN 段。每次服务器接收到一个 SYN 段时,它设置状态表 sets up a state table 并分配其他资源,同时等待下一段到达。然而,一段时间后,服务器可能会因为资源耗尽而崩溃。
SCTP设计者使用一种策略防止这种类型的攻击。当发送方IP地址被确认时,这个策略是推迟资源分配、直到接收到第三个分组。第一个分组中接收到的信息必须以某种方式保存到第三个分组到达。但是,如果服务器保存该信息,那就需要资源(存储器)的分配,这是一个困境。
解决办法是包装该信息,并把它送回到客户,这称为生成一个 cookie ,这个 cookie 与第二个分组一起发送给接收第一个分组的地址。有两种可能的情形:
- 如果第一个分组的发送方是一个攻击者,那么服务器永远不会接收到第三个分组,
cookie丢失了,但没有分配资源。服务器的唯一的工作是"baking" cookie。 - 如果第一个分组的发送方是需要建立连接的一位诚实的客户,那么它接收到带有
cookie的第二个分组。它毫无改变地用该cookie发送一个分组(在序列中是第三个分组)。服务器接收到第三个分组,而且知道它来自一位诚实的客户,因为发送方发送的cookie已经在那里。现在服务器可以分配资源了。
如果没有实体可以"吃掉"由服务器"生成"的 cookie ,那么上述策略就可以起作用。为了保证这一点,服务器用它自己的密钥产生该信息的一个摘要(见【计算机网络】第七部分 网络安全(30) 密码学)。信息和摘要一起生成一个 cookie ,它在第二个分组中被发送给客户。当 cookie 在第三个分组中返回时,服务器计算信息的摘要。如果该摘要与发送的摘要相匹配,那么该 cookie 就没有被其他的实体修改。
2. 数据传输
关联的目的是为了在两端之间传输数据。关联建立后,就可以进行双方向的数据传输,客户端与服务器都可发送数据。像TCP一样,SCTP支持捎带。
然而,TCP与SCTP在数据传输方面存在着很大的不同,TCP从进程接收报文,这些报文作为字节流、在其间没有可识别的边界。为了它的对等方的使用,进程可插入一些边界,但TCP将那些标记作为文本的一部分对待。换言之,TCP把每个报文附加 append 到它的缓存中,一个段可能携带两个不同报文的一部分 A segment can carry parts of two different messages. 。TCP使用的唯一的排序系统是字节编号。
另一方面,SCTP识别并维护边界,来自进程的每个报文作为一个单元处理,并插入到一个 DATA 大块中,除非这个报文被分段(后面讨论)。在这种情况下,SCTP与UDP一样具有一个很大的优势:数据大块相互关联。
通过把 DATA 大块的头部加到报文上,从进程接收到的一个报文成为一个 DATA 大块;如果要分段,则成为几个 DATA 大块。一个报文或一个报文的分段形成的每个 DATA 大块,都有一个 TSN 。我们要记住,只有 DATA 大块使用 TNS ,也只有 DATA 大块使用 SACK 大块进行确认。
图23.34表示了一个简单数据传输的情形,客户端发送 4 4 4 个 DATA 大块,从服务器接收两个 DATA 大块。稍后,讨论SCTP中的流量和差错控制,此时假定在这种情形下一切都顺利。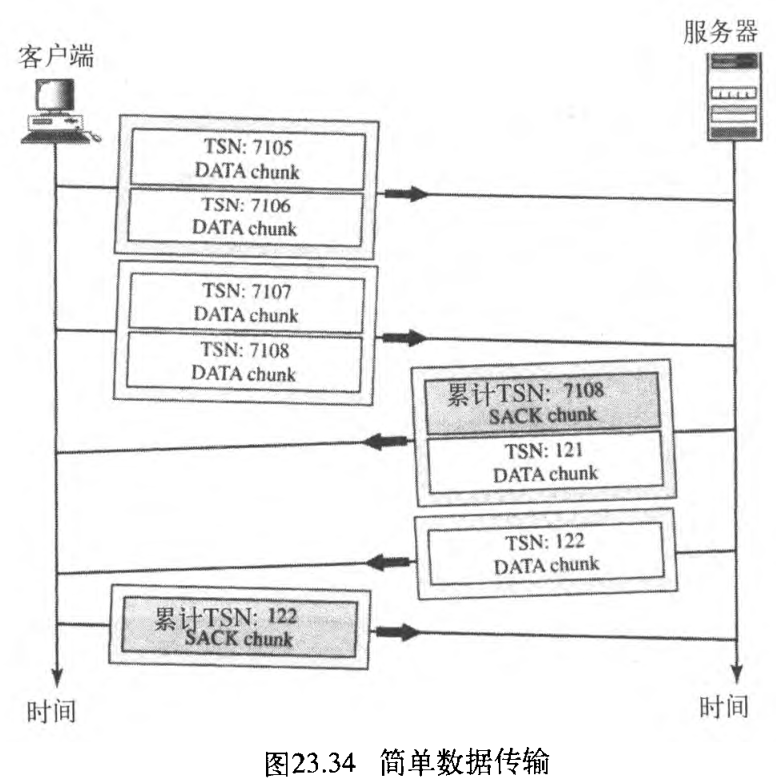
- 客户端发送第一个分组,它携带
TSN分别为 7105 7 105 7105 和 7106 7 106 7106 的两个DATA大块。 - 客户端发送第二个分组,它携带
TSN分别为 7107 7107 7107 和 7108 7 108 7108 的两个DATA大块。 - 第三个分组来自服务器,它包括了对收到来自客户端的
DATA大块进行确认所需要的SACK大块。与TCP相反,SCTP只有按顺序收到的最后一个TSN进行确认,而不是下一个所期望的。第三个分组还包括了TSN为 121 121 121 的来自服务器的第一个DATA大块。 - 不久,服务器发送另一个携带
TSN为 122 122 122 的、最后一个DATA大块的分组,但由于接收来自客户端的最后的DATA大块已被确认,所以在这个分组中不包括SACK大块。 - 最后,客户端发送一个分组,该分组包含了一个
SACK大块,该SACK大块是对接收到的、来自服务器最后两个DATA大块的确认。
在SCTP中的确认定义了累计 TSN ,最后数据大块的 TSN是按序接收的。
(1) 多接口数据传输
我们讨论SCTP多接口的性能,它与UDP和TCP不同的特性。多接口允许双方为了通信定义多个IP地址,但这些地址中只有一个地址能被定义为主地址 primary address ,其余的地址都是可选地址。
在关联建立期间,主地址被定义。有趣的是,一端的主地址由另一端决定。换言之,源端定义目的端的主地址。
(2) 多流传递
SCTP的一个重要特性是数据传输和数据传递 data transfer and data delivery 是不同的:SCTP使用 TSN 号处理数据传输,在源端与目的端之间移动数据大块。数据大块的传递是用 SI 和 SSN 来控制。
SCTP支持多流,这就是说发送进程可定义不同的流,一个报文可属于这些流中某一个。每个流被赋于一个流标识符 Sl ,它唯一地定义这个流。
(3) 分段
在数据传输中的另一个问题是分段 fragmentation 。虽然SCTP也用IP中分段 fragmentation 这个术语,但IP中的分段与SCTP中的分段属于不同的级别:前者是在网络层,而后者是在传输层。
如果一个报文(封装在IP数据报中)的长度不超过路径的 MTU ,当这个报文创建一个 DATA 大块时,SCTP保存进程到进程的报文的边界。携带一个报文的IP数据报的长度,等于报文的长度(以字节为单位)加上 4 4 4 个开销:数据大块的头部、必需的 SACK 大块、SCTP通用头部和IP头部。如果总长度超过 MTU ,则报文需要分段。
3. 关联终止
像TCP一样,在SCTP中交换数据的双方(客户端与服务器)的任一方都可关闭连接。但与TCP不同的是,SCTP不允许有半关闭的情形:如果某一端关闭了关联,另一端必须停止发送新的数据。如果在终止请求的队列中还有数据,那么将这些数据送,并关闭关联。
关联终止 association termination 使用三个分组 SHUTDOWN, SHUTDOWN ACK, SHUTDOWN COMPLETE ,如图23.35所示。注意:虽然在图中终止是由客户端发起的,但也可由服务器发起。关联终止可以有多种情况,在本章末提到的参考文献中有讨论。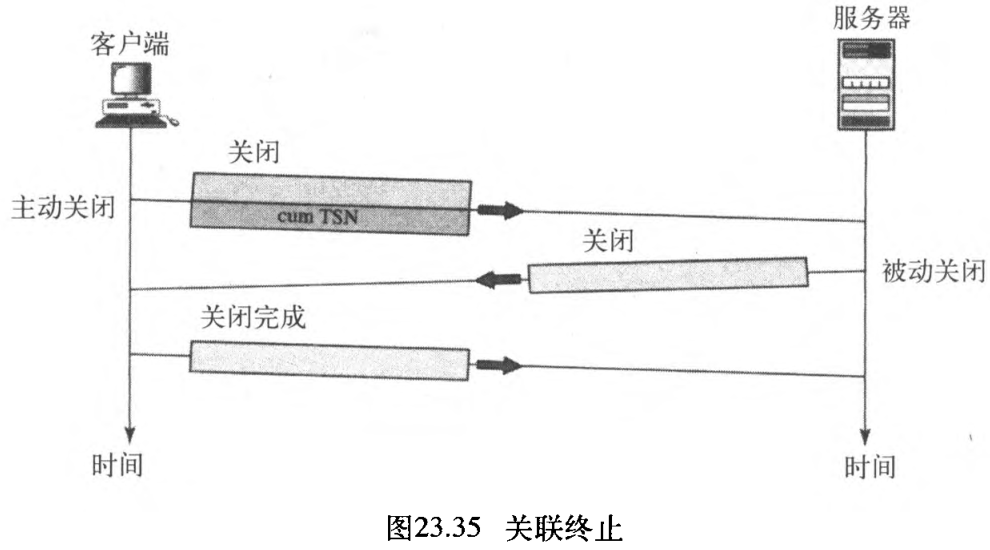
23.4.5 流量控制
SCTP的流量控制与TCP的流量控制相类似。在TCP中,我们只需要处理一个数据单元——字节。在SCTP ,我们需要处理两个数据单元的数据:字节和大块 the byte and the chunk 。rwnd 和 cwnd 的值用字节表示,TSN 的值和确认用大块表示。
为了说明这个概念,我们做某些不实际的假定,假设网络永远不会拥塞和永远没有差错。换言之,我们假定 cwnd 是无穷大,分组不丢失、不延迟、不失序到达。还假定数据传输是单向的。在后面几节改进这些不实际的假定。
关于流量控制,现在SCTP的实现依旧是使用一个面向字节的窗口。然而,为了使概念变成更加容易了解,用大块表示缓冲区。
1. 接收方站点
接收方有一个缓冲区(队列)和三个变量。该队列保存接收到、但还未被进程读出的大块。第一个变量保存最后收到的 TSN 值,即 cumTSN 。第二个变量保存缓冲区大小,即 winSize 。第三个变量保存最后的累计确认值,即 lastACK 。图23.36表示接收方站点的队列和变量。
- 当站点接收到一个数据大块时,将它存储在缓冲区(队列)的末端,并从
winSize减去该数据大块的大小。这一大块的TSN号存储在cumTSN变量中; - 当进程读出一个大块时,该块从队接收列中移去,并在
winSize中加上移去大块的大小(循环使用);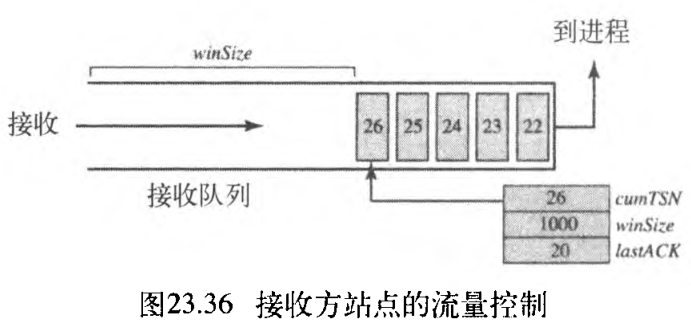
- 当接收方决定发送一个
SACK时,它检验lastACK的值。如果它小于cumTSN, 接收方就发送一个「累计TSN号等于cumTSN」的SACK,同时该SACK也包含wizeSize的值作为该窗口的大小。
2. 发送方站点
发送方有一个缓冲区(队列)和三个变量:curTSN, rwnd, inTransit 。如图23.37所示。我们假定每个大块的长度为 100 1 00 100 个字节。
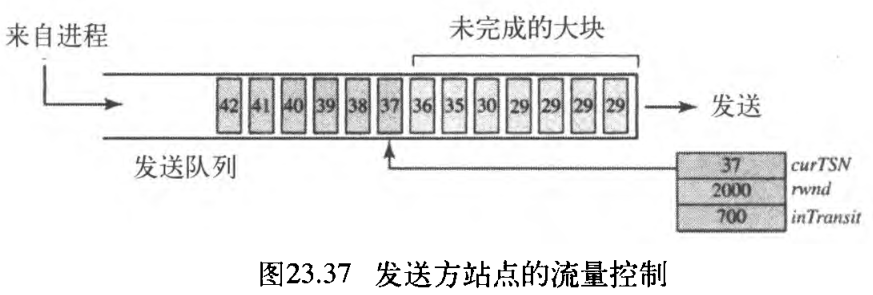
缓冲区保存由进程产生的大块,这些大块或者已被发送或者准备发送。第一个变量 curTSN 指的是下一个要发送的大块,队列中所有小于这个值的大块都已被发送、但还没有被确认,它们是未完成的。第二个变量 rwnd 保存接收方通告窗口的最新值(以字节为单位)。第三个变量 inTrasit 保存正在传输中(即字节已发送、但还未被确认)的字节个数。下面是发送方所用的过程。
- 如果
curTSN指向的大块的数据大小<= rwnd - inTransit时,该大块可以发送。发送后,curTSN值增 1 1 1 并指向下一个要发送的大块。inTransit的值加上己被发送大块的数据大小。 - 当接收到一个
SACK,队列中具有TSN值小于或等于SACK中的TSN值的那些大块从队列中移去并丢弃。发送方不再关心它们。inTrasit值减去被丢弃块总的大小。用SACK中通告窗口的值更新rwnd的值。
3. 一个实例
给出如图23.38所示的一个简单实例。开始时,发送方站点的 rwnd 和接收方站点的 winSize 都是 2000 2000 2000(在关联建立期间通告)。发送方队列初始有 4 4 4 个报文,它发送一个数据大块,并在 inTransit 变量中加上字节数 1000 1 000 1000 。之后,发送方检查rwnd 与 inTrasit 的差,它是 1000 1000 1000 ,所以发送方可发送另一个数据大块。现在两个变量的差为 0 0 0 ,不能再发送数据大块。
过一会儿,确认数据大块 1 1 1 和 2 2 2 的 SACK 到达。这两个大块从队列中移去,此时 inTransit 的值是 0 0 0 。但是,SACK 通告了接收窗口的值是 0 0 0 ,这使得发送方将 rwnd 值更新为 0。现在发送方被阻塞,它不能发送任何数据大块(有一个例外稍后说明)。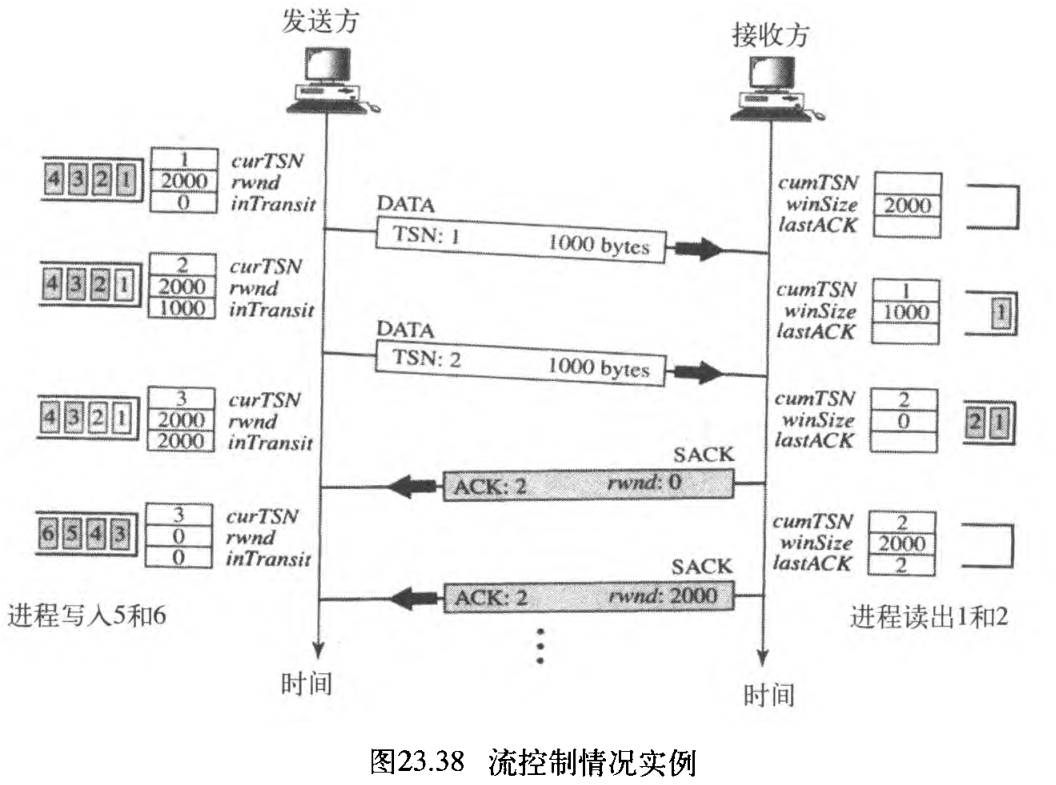
在接收方,开始时队列是空的。当第一个数据大块接收到后,队列中有一个报文,并且 cumTSN 值为 10 10 10 ,winSize 的值减小到 1000 1000 1000 ,这是因为第一个报文占用 1000 1000 1000 个字节。接收到第二个报文后,窗口大小的值为 0 0 0 而 cumTSN 为 2 2 2 。此时,我们将看到接收方需要发送累计 TSN 为 2 2 2 的 SACK 。第一个 SACK 发送后,进程读出这两个报文,这就是说现在队列有空间,接收方用 SACK 通告这种情况,允许发送方发送更多的数据大块。余下的事件在图中没有表示。
23.4.6 差错控制
像TCP一样,SCTP是一个可靠的传输层协议。它使用一个 SACK 大块,向发送方报告接收方缓冲区的状态。在接收方站点与发送方站点,每个实现都使用不同的实体和计时器集合。用一个最简单的设计,介绍这个概念。
1. 接收方站点
在我们的设计中,接收方将所有到达的大块存储在队列中,包括失序大块。但是,它给任何丢失的大块保留空间。它丢弃那些重复的报文,但追踪它们并向发送方报告。图23.39表示了一个接收方站点的典型设计、和在一个特定时间接收队列的状态。
发送的最后确认是对数据大块 20 20 20 ,有效窗口大小是 1000 1000 1000 个字节。大块 21 21 21 到 23 23 23 已按序收到,第一个失序的块包含大块 26 26 26 到 28 28 28 ,第二个失序块包含大块 31 31 31 到 34 34 34 。一个变量保存 cumTSN 的值。一组变量保存失序的那些块的首块 TSN 和末块 TSN 。一组变量保存接收到的那些重复的大块。注意:在队列中,不需要对重复的大块进行排序,它们被丢弃。图23.39中也显示了,将要发送给发送方的、用以报告接收方状态的 SACK 大块。那些失序大块的 TSN 号是相对于(偏移量 )累计TSN的。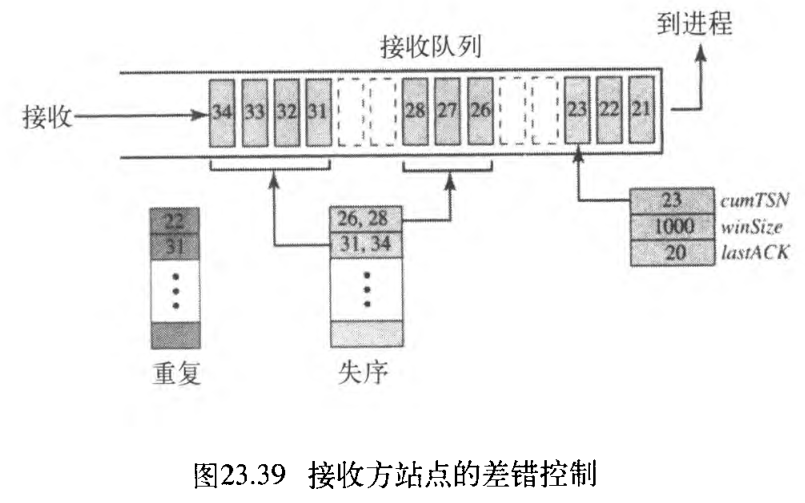
2. 发送方站点
在发送方站点,我们的设计要求两个缓冲区(队列):一个发送队列和一个重传队列。也使用前一节描述的三个变量 rwnd, inTrasit, curTSN 。图23.40表示了一个典型的设计。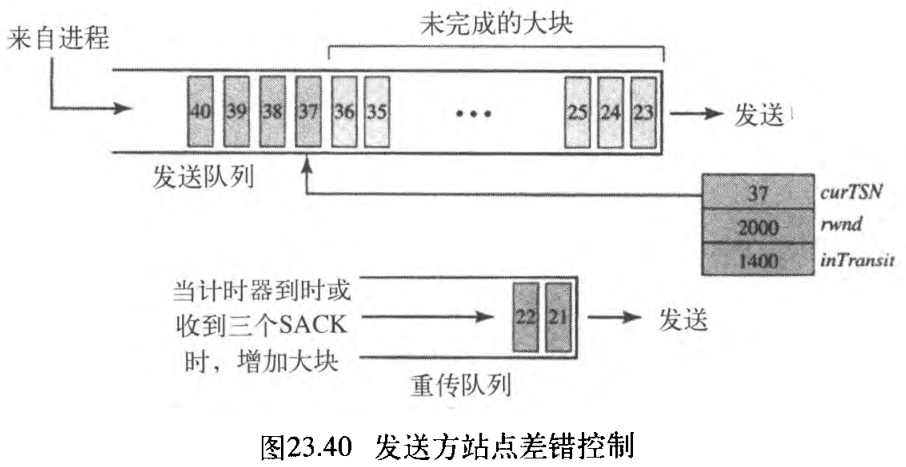
发送队列保存大块 23 23 23 到 40 40 40 。其中大块 23 23 23 到 36 36 36 已发送,但还未被确认,它们是未完成的大块。curTSN 指向下一个要发送的大块 37 37 37 。假定每个大块是 100 100 100 个字节,这就是说数据中的 1400 1 400 1400 个字节(大块 23 23 23 到 36 36 36)是正在传输中的。
这时发送方有一个重传队列,当发送一个分组时,那个分组(那个分组中的所有大块)的重传计时器开始启动。有些实现对整个关联使用一个计时器,但我们为了简单起见,继续按惯例对每个分组使用一个计时器。当一个分组的重传计时器到时时,或声称一个分组丢失的 4 4 4 个重复的 SACK(在第12章中讨论过快速重传)到达时,那个分组中的所有大块都移到重传队列中被重新发送。在重传队列中的大块具有优先权。换言之,下一次发送方发送的大块将来自重传队列的大块 21 21 21 。
3. 发送数据大块
每当在发送队列中存在TSN的值 >= curTSN 的数据大块时,或者在重传队列中有数据大块时, 一个端就可以发送一个数据分组。重传队列中的大块具有优先发送权。但是,一个分组所包含的数据大块的大小,或多个数据大块总的大小必须小于或等于 rwnd - inTransit ,在前几节已讨论过,帧的总的大小必须小于或等于 MTU 。
4. 重发
像TCP一样,为了控制丢失的或丢弃的大块,SCTP采用两种策略:使用重发计时器和接收到同一丢失大块的 4 4 4 个 SACK 。
5. 生成SACK大块
差错控制中的另一个问题是生成 SACK 大块。生成 SCTP SACK 大块的规则,与TCP中「使用 ACK 标记进行确认 acknowledgment with the TCP ACK flag 」所用的规则相似。
23.4.7 拥塞控制
像TCP一样,SCTP是一个传输层协议,其分组会遭受到网络拥塞。SCTP设计者也使用相同的策略,将在【计算机网络】第五部分 传输层(24) 拥塞控制和服务质量中讨论TCP拥塞控制。SCTP具有慢速启动(指数增加)、拥塞避免(加性增加)和拥塞检测(乘性减少)等阶段。像TCP一样,SCTP也使用快速重传和快速恢复、以及慢速恢复。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)