6. 数据仓库环境准备
6. 数据仓库环境准备
1. 数据仓库环境准备
1.1 数据仓库运行环境
1.1.1 Hive环境搭建
https://blog.csdn.net/qq_44226094/article/details/123218860
Hive引擎:
- 默认MR
- Tez
- Spark
Hive on Spark:Hive 既作为存储元数据又负责 SQL 的解析优化,语法是 HQL 语法,执行引擎变成了 Spark ,Spark 负责采用 RDD 执行
Spark on Hive : Hive 只作为存储元数据,Spark 负责 SQL 解析优化,语法是 Spark SQL 语法,Spark 负责采用 RDD 执行
1.1.1.1 Hive on Spark 安装
https://blog.csdn.net/qq_44226094/article/details/123531414
1.1.1.2 Hive on Spark 测试
启动 hive 客户端
hive
创建一张测试表
create table student(id int, name string);

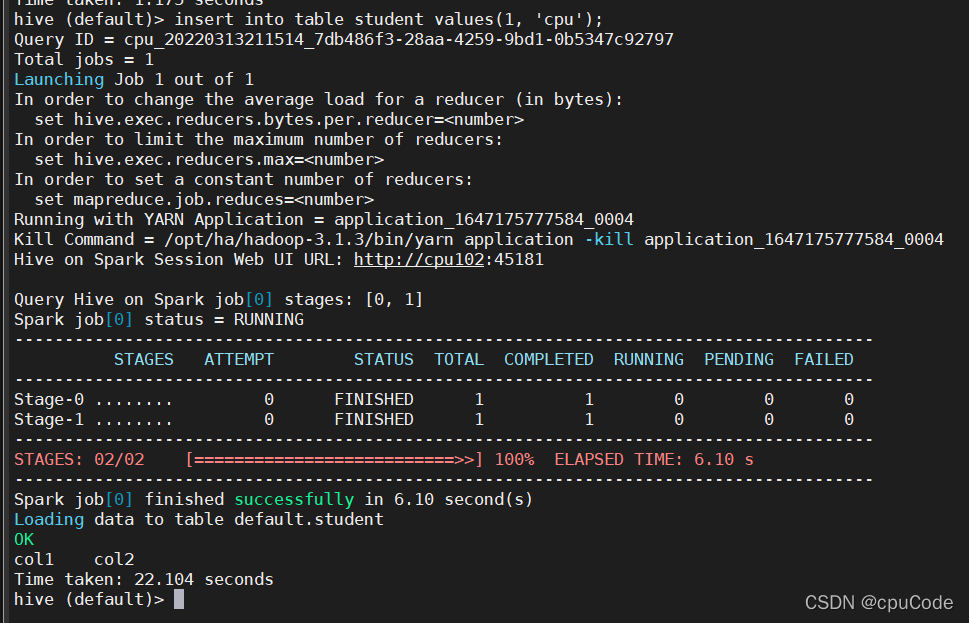
通过 insert 测试效果
ClassNotFoundException: org.apache.spark.AccumulatorParam 解决方案 :
https://blog.csdn.net/qq_44226094/article/details/123467092
insert into table student values(1, 'cpu');
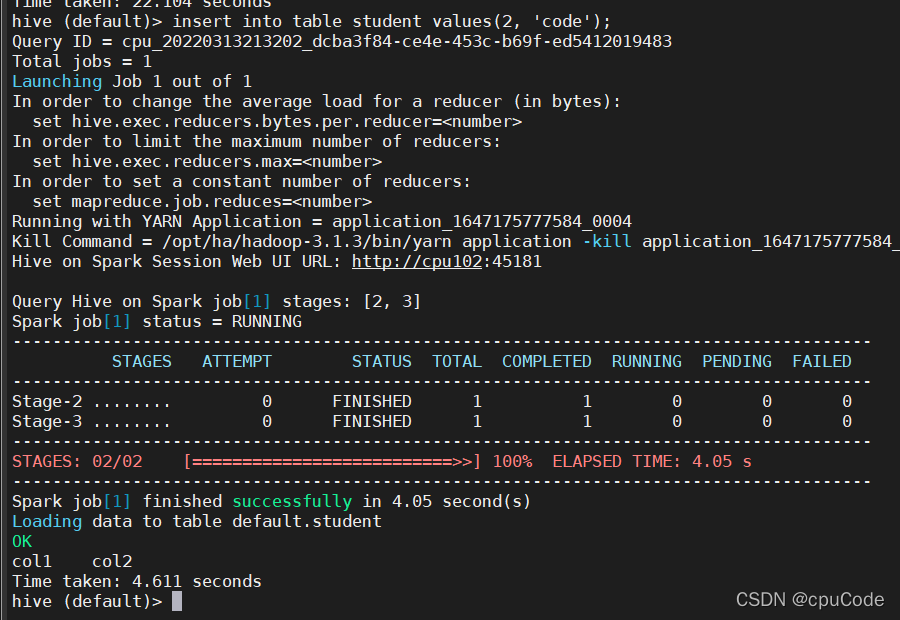
insert into table student values(2, 'code');
1.1.2 Yarn环境配置
增加 ApplicationMaster 资源比例
容量调度器对每个资源队列中同时运行的 Application Master 占用的资源进行了限制,该限制通过 yarn.scheduler.capacity.maximum-am-resource-percent 参数实现,其默认值是 0.1
该参数表示每个资源队列上Application Master 最多可使用的资源为该队列总资源的 10% ,目的 : 防止大部分资源都被 Application Master 占用,而导致 Map/Reduce Task 无法执行
生产环境该参数可使用默认值
当集群垃圾时,集群资源总数很少,如果只分配 10% 的资源给 Application Master,则可能出现,同一时刻只能运行一个 Job 的情况,因为一个Application Master 使用的资源就可能已经达到 10% 的上限了。所以可将该值适当调大
在 cpu101 的 /opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml文件中修改参数值
vim capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property>
分发 capacity-scheduler.xml 配置文件
xsync capacity-scheduler.xml
关闭正在运行的任务,重新启动 yarn 集群
stop-yarn.sh
start-yarn.sh
1.2 数据仓库开发环境
数仓开发工具 DataGrip。需要用到 JDBC 协议连接到 Hive,所以启动 HiveServer2
1.2.1 启动 HiveServer2
hiveserver2
1.2.2 配置 DataGrip 连接
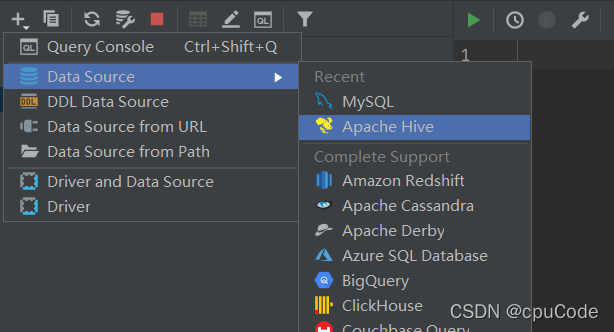
1.2.2.1 创建连接
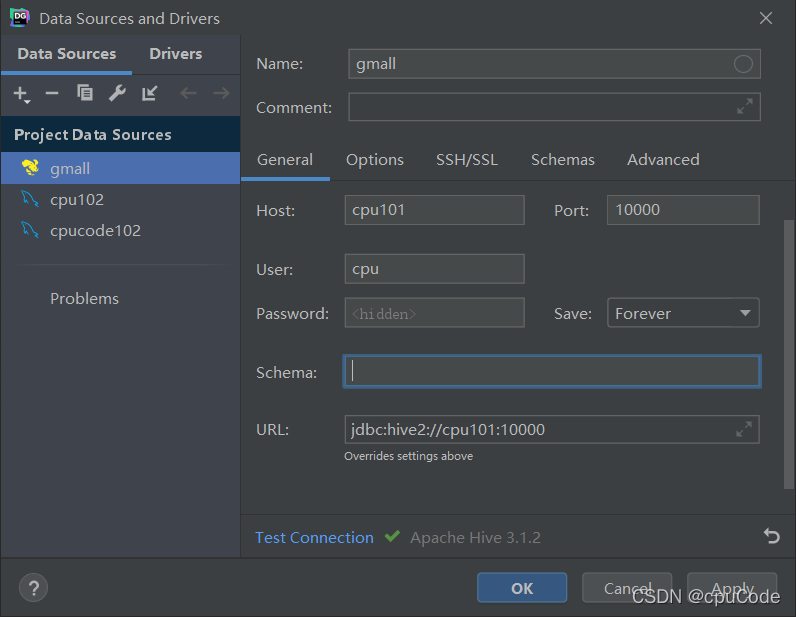
1.2.2.2 配置连接属性
所有属性配置,和 Hive 的 beeline 客户端配置一致即可
第一使用,配置过程会提示缺少 JDBC 驱动,下载即可
1.2.2.3 测试使用
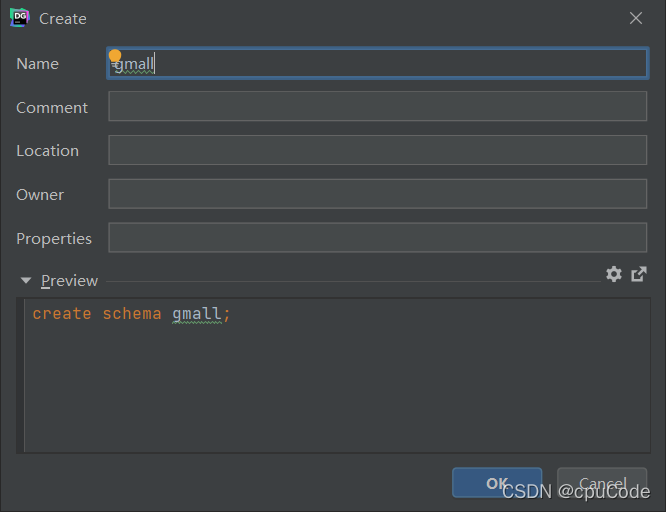
创建数据库gmall,并观察是否创建成功
创建数据库
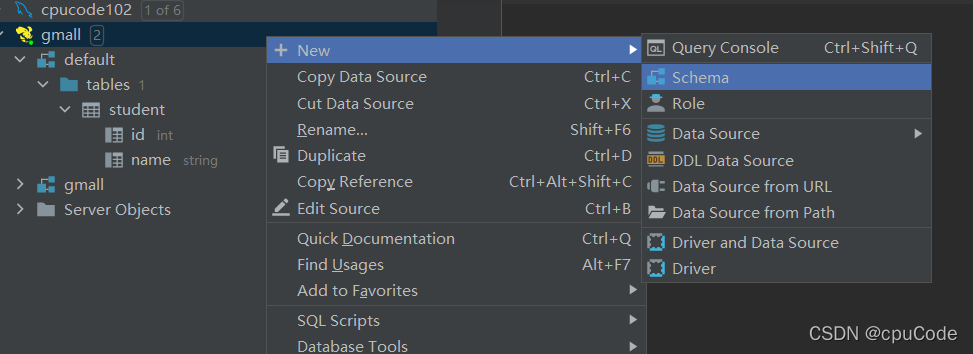
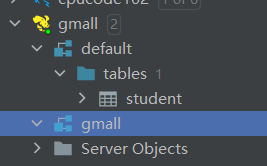
查看数据库
修改连接,指明连接数据库
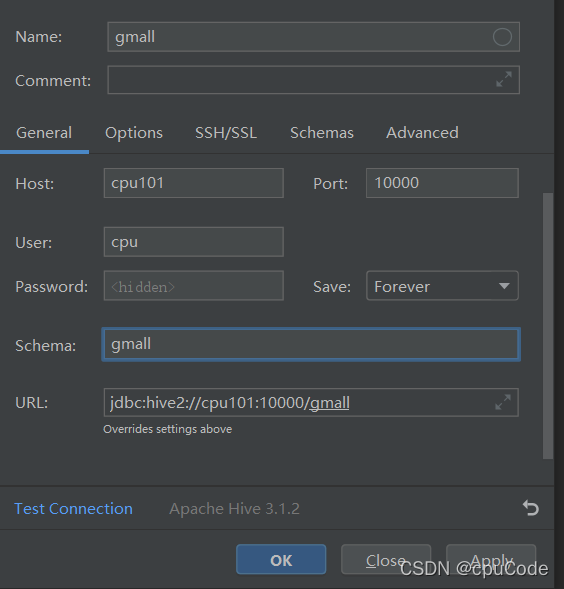
选择当前数据库为 gmall

1.3 模拟数据准备
企业在开始搭建数仓时,业务数据库存在历史数据,用户行为日志无历史数据
假定数仓上线的日期为 2020-06-14,为模拟真实场景,需准备以下数据
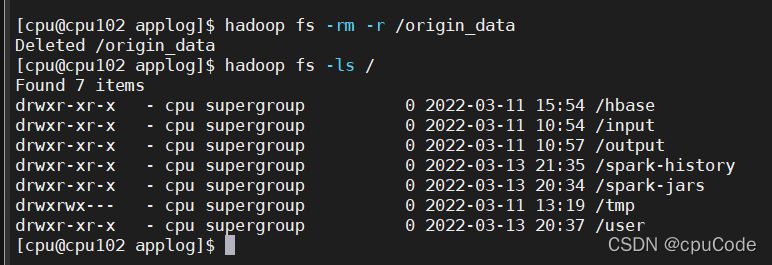
在执行以下操作之前,先将 HDFS 上 /origin_data 路径下之前的数据删除
hadoop fs -rm -r /origin_data
1.3.1 用户行为日志
用户行为日志,一般是没有历史数据的,故日志只需要准备 2020-06-14 一天的数据
具体操作如下:
启动日志采集通道
Zookeeper
zk.sh start
Kafak
kf.sh start
Flume
f1.sh start
f2.sh start
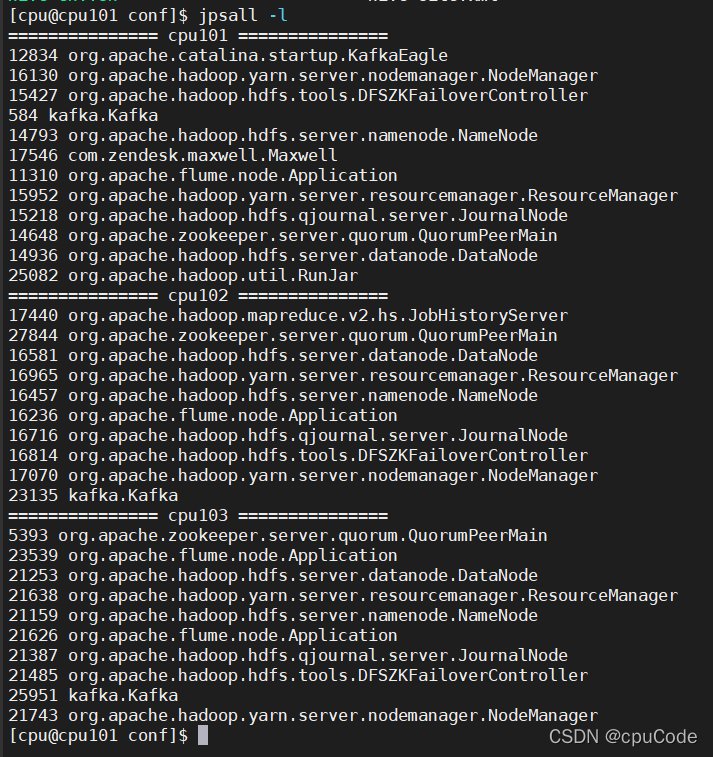
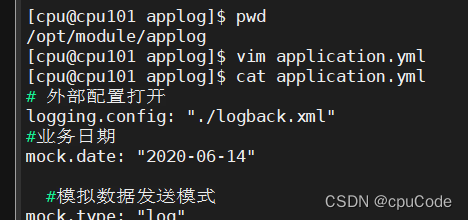
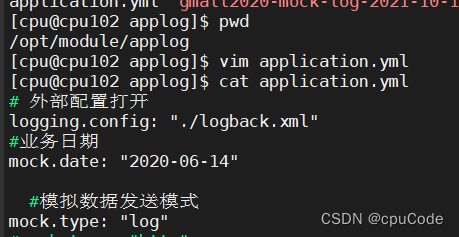
修改两个日志服务器(cpu101、cpu102)
/opt/module/applog/application.yml 配置文件
mock.date=2020-06-14
执行日志生成脚本
lg.sh
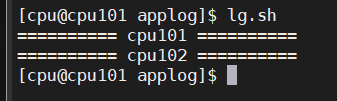
观察 HDFS 是否出现相应文件
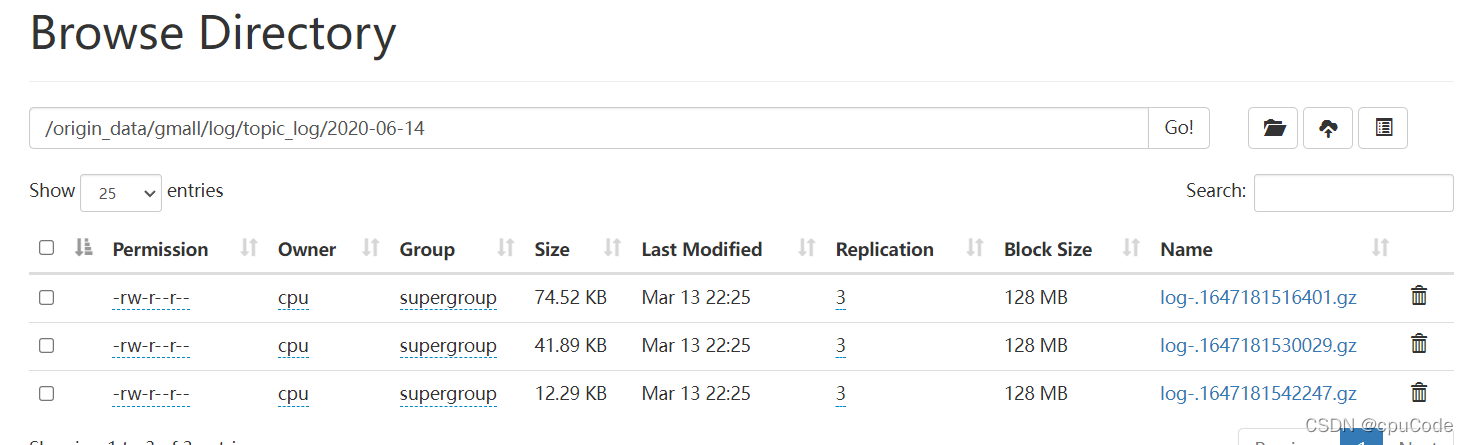
1.3.2 业务数据
业务数据一般存在历史数据,此处需准备 2020-06-10 至 2020-06-14 的数据
具体操作如下 :
关闭 Maxwell
mxw.sh stop
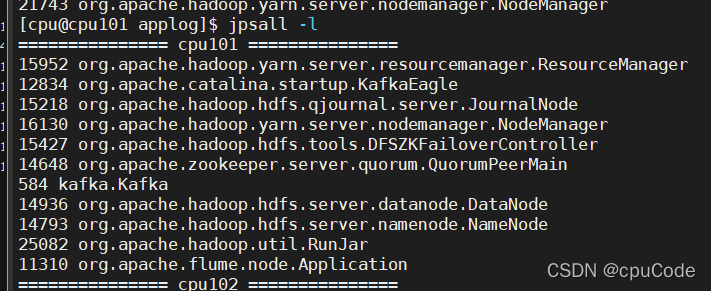
清空 gmall 数据 , 在重新 sql 写入
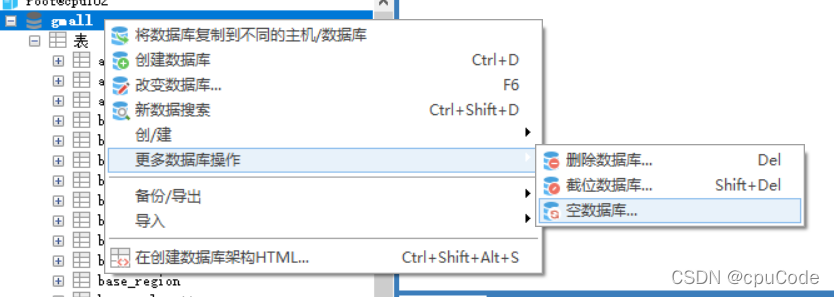
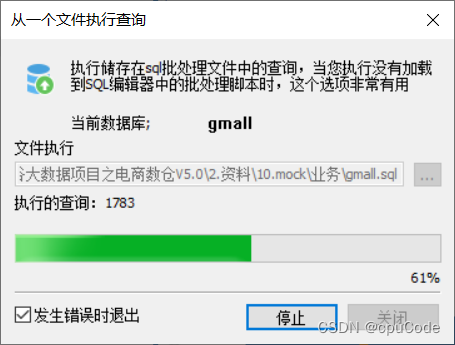
1.3.2.1 生成模拟数据
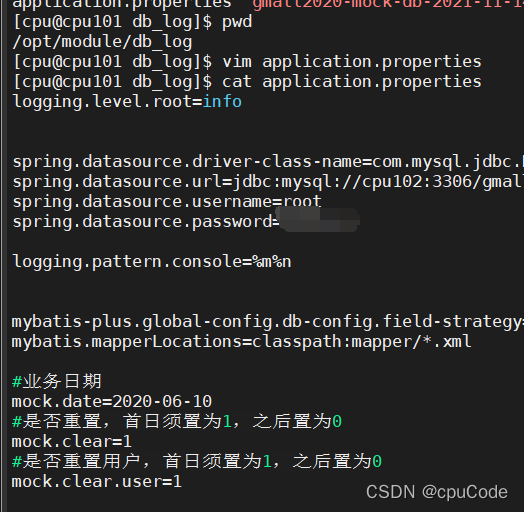
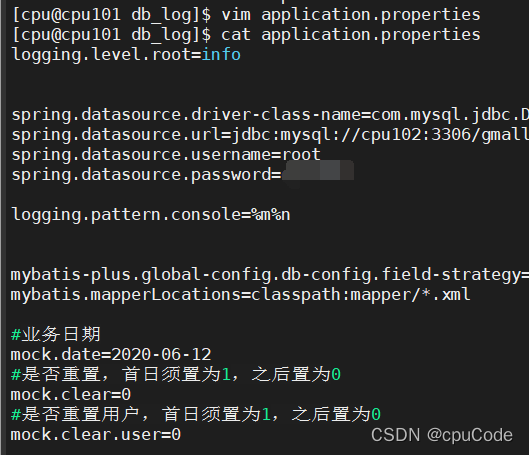
修改 cpu101 节点上的 /opt/module/db_log/application.properties 文件
#业务日期
mock.date=2020-06-10
#是否重置,首日须置为1,之后置为0
mock.clear=1
#是否重置用户,首日须置为1,之后置为0
mock.clear.user=1
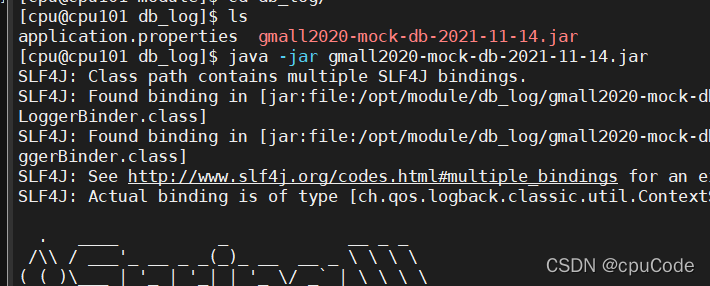
执行模拟生成业务数据的命令,生成第一天 2020-06-10 的历史数据。
java -jar gmall2020-mock-db-2021-11-14.jar
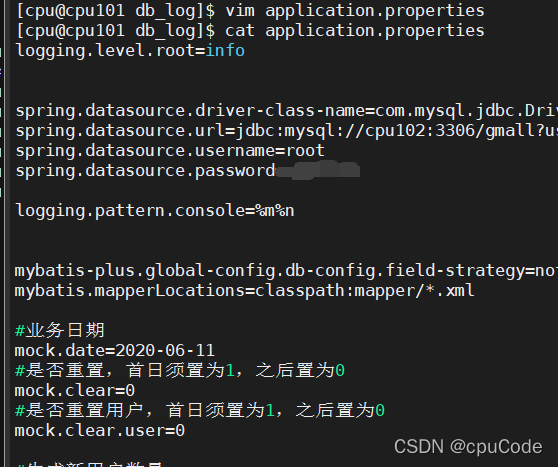
修改 /opt/module/db_log/application.properties 文件
#业务日期
mock.date=2020-06-11
#是否重置,首日须置为1,之后置为0
mock.clear=0
#是否重置用户,首日须置为1,之后置为0
mock.clear.user=0
执行模拟生成业务数据的命令,生成第二天 2020-06-11 的历史数据
java -jar gmall2020-mock-db-2021-11-14.jar
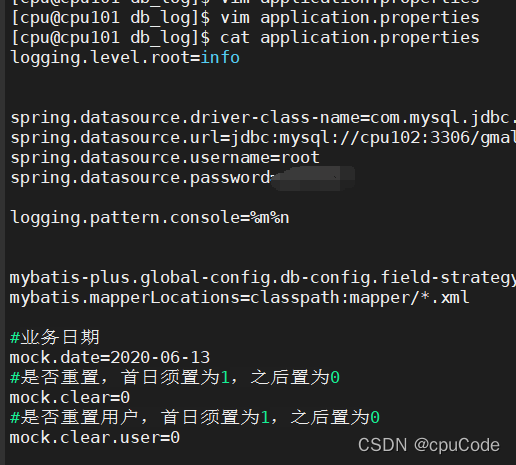
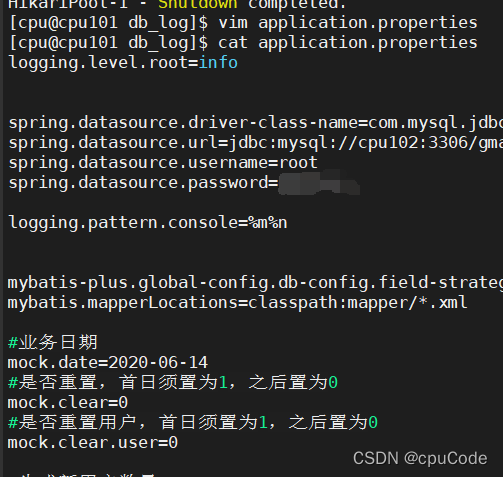
之后只修改 /opt/module/db_log/application.properties 文件中的 mock.date 参数,依次改为 2020-06-12 ,2020-06-13 ,2020-06-14 ,并分别生成对应日期的数据
1.3.2.2 全量表同步
执行全量表同步脚本
mysql_to_hdfs_full.sh all 2020-06-14
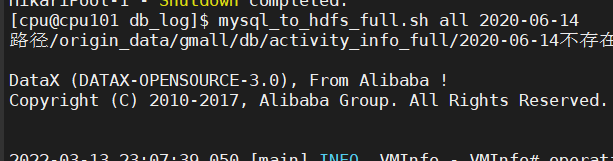
观察HDFS上是否出现全量表数据
1.3.2.3 增量表首日全量同步
清除 Maxwell 断点记录
由于 Maxwell; 支持断点续传,而重新生成业务数据的过程,会产生大量的 binlog 操作日志,这些日志并不需要。所以清除 Maxwell 的断点记录,从 binlog 最新的位置开始采集
关闭Maxwell
mxw.sh stop
清空 Maxwell 数据库,相当于初始化 Maxwell
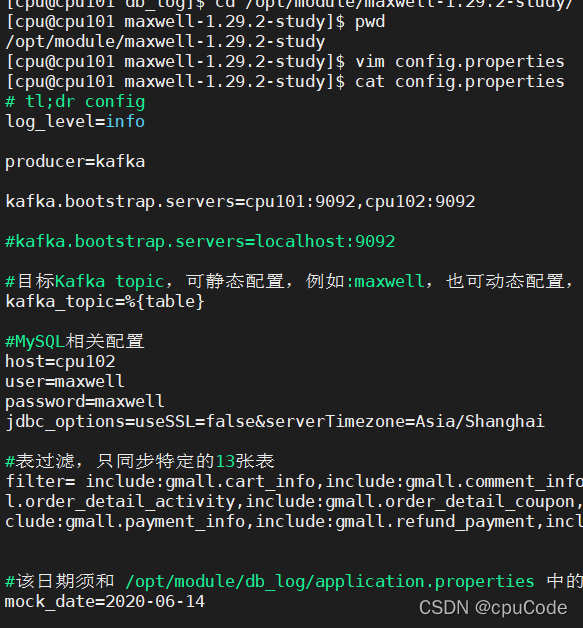
修改 Maxwell 配置文件中的 mock_date 参数
vim config.properties
mock_date=2020-06-14
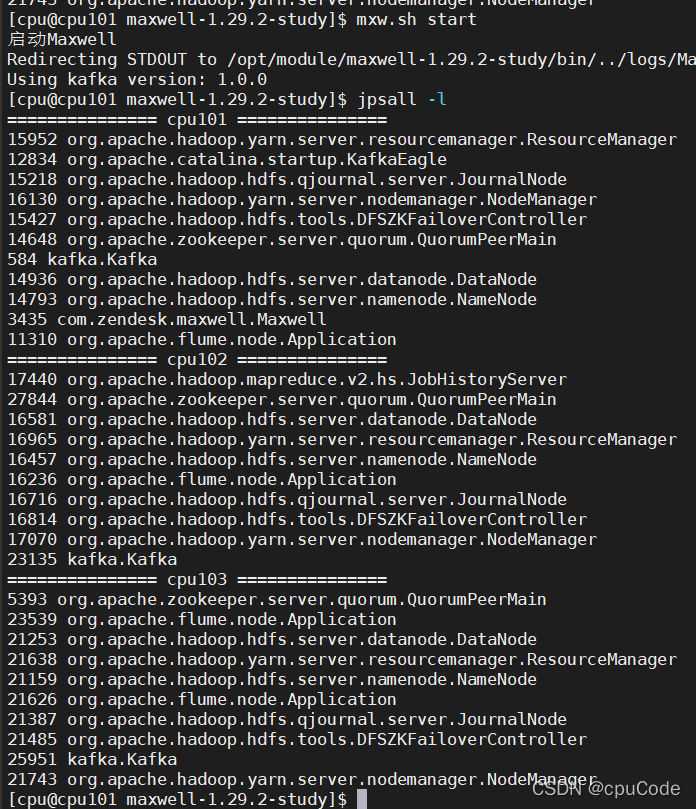
启动增量表数据通道,包括 Maxwell、Kafka、Flume
f3.sh start
kf.sh start
mxw.sh start
执行增量表首日全量同步脚本
mysql_to_kafka_inc_init.sh all
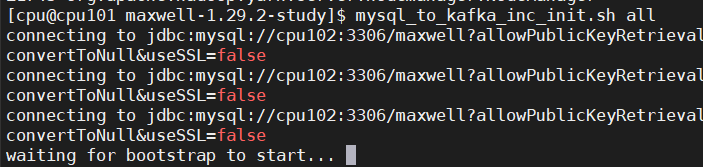
观察 HDFS 上是否出现全量表数据
1.3.3 数据自动生成同步
消息生成
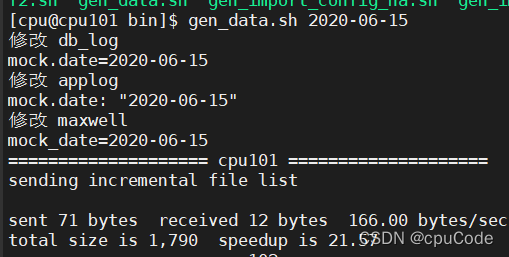
vim gen_data.sh
内容 :
#!/bin/bash
delete_data(){
host=node190
for i in $*; do
count_size=$(ssh $host "mysql -u root -pcpucode -e 'use gmall; select count(*) from $i;'")
size=$(echo $count_size | awk '{print $2}')
if [[ $size -ge 3000 ]]; then
ssh $host "mysql -u root -pcpucode -e 'use gmall; delete from $i limit 100;'"
fi
done
}
/home/hdfs/bin/lg.sh
# 防止卡死 , 一直停留
ps -ef | grep 'gmall2020-mock-db-2021-11-14.jar' | grep -v grep | awk '{print $2}' | xargs kill
# 删除些数据 , 防止卡死
delete_data "cart_info" "comment_info" "coupon_use" "favor_info" "order_detail_activity" "order_detail_coupon" "order_detail" "order_info" " order_refund_info" "order_status_log" "payment_info" "refund_payment" "user_info"
# 生产业务数据
cd /opt/module/db_log
/app/hadoop/jdk1.8.0_271/bin/java -jar gmall2020-mock-db-2021-11-14.jar
修改数据
vim change_date.sh
内容 :
#!/bin/bash
# 根据情况修改配置文件位置
DB_LOG=/opt/module/db_log/application.properties
APPLOG=/opt/module/applog/application.yml
MAXWELL=/opt/module/maxwell-1.29.2-study/config.properties
# 时间选择
if [ -n "$1" ] ;then
do_date=`date -d '-721 day' +%F`
else
do_date=`date -d '-1 day' +%F`
fi
change_config(){
#修改数据
echo "修改 db_log"
sed -i "/mock.date=/ c mock.date=$do_date" $DB_LOG
# 查看数据修改后情况
grep 'mock.date=' $DB_LOG
echo "修改 applog"
sed -i "/mock.date: / c mock.date: \"$do_date\"" $APPLOG
grep 'mock.date:' $APPLOG
echo "修改 maxwell"
sed -i "/mock_date=/ c mock_date=$do_date" $MAXWELL
grep 'mock_date=' $MAXWELL
#分发数据
/home/hdfs/bin/xsync $DB_LOG
/home/hdfs/bin/xsync $APPLOG
/home/hdfs/bin/xsync $MAXWELL
}
# 停止maxwell
mxw.sh stop
change_config
# 启动maxwell
mxw.sh start
定时任务
crontab -l
- 在 crontab 文件都被保存在
/var/spool/cron/目录中 - 日志文件在
/var/log/cron - 执行日志文件 :
/var/spool/mail/hdfs
*/5 * * * * . /etc/profile; /home/hdfs/bin/gen_data.sh date +\%F
0 0 * * * . /etc/profile; /home/hdfs/bin/mysql_to_hdfs_full.sh all 1
0 0 * * * . /etc/profile; /home/hdfs/bin/change_date.sh 1
该时间请按照递增的方向设置 , 如 : 设置了 2020-06-15 后, 就不要设置 2020-06-14 这些前面的天数

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)