【spark实训】-- Scala实现单词计数
spark--Scala实现单词计数
目录
1.4 启动spark历史服务器history-server
一、训练要点
(1) RDD创建方法。
(2) flatMap操作方法。
二、需求说明
数据文件words.txt如图所示,文件中包含了多行句子,现在要求对文档中的单词计数,并把单词计数超过3的结果存储到HDFS上。

三、实现思路及步骤
(1)通过textFile的方法读取数据。
(2)通过flatMap将字符串切分成单词。
(3)通过map将单词转化为(单词,1 )的形式。
(4)通过reduceByKey将同一一个单词的所有值相加。
(5)通过filter将单词计数大于3的结果过滤出来。
(6)通过saveAsTextFile将结果写人到HDFS。
四、关键实现代码
hdfs dfs -put words.txt /user/root/
val worddata=sc.textFile("hdfs://node1:8020/user/root/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y)
val worddata=sc.textFile("hdfs://node1:8020/user/root/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y)
val worddata_3=worddata.filter(x=>x._2>3).map(x=>x._1)
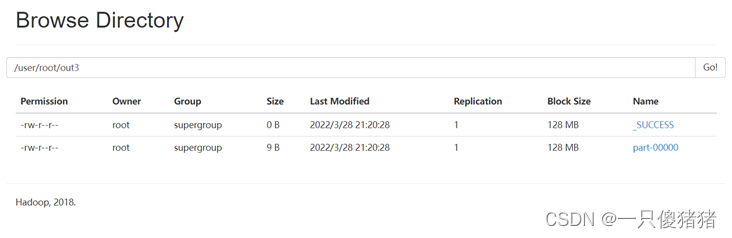
worddata_3.repartition(1).saveAsTextFile("/user/root/out3")
hdfs dfs -text /user/root/out3/par*五、具体实现单词统计步骤(含图片解析)
1、启动各种服务环境
1.1 启动hdfs集群
在node1操作
[root@node1 ~]# start-dfs.sh
1.2 启动yarn集群
在node1操作
[root@node1 ~]# start-yarn.sh
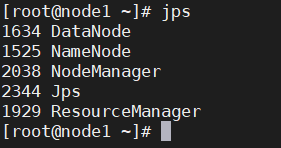
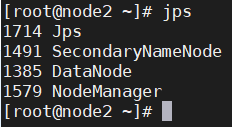
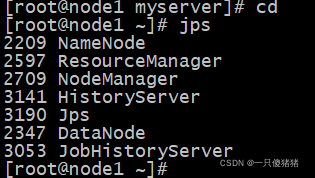
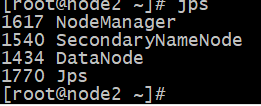
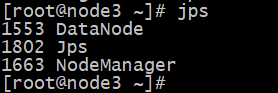
此时node1、node2和node3上的hdfs和yarn角色为
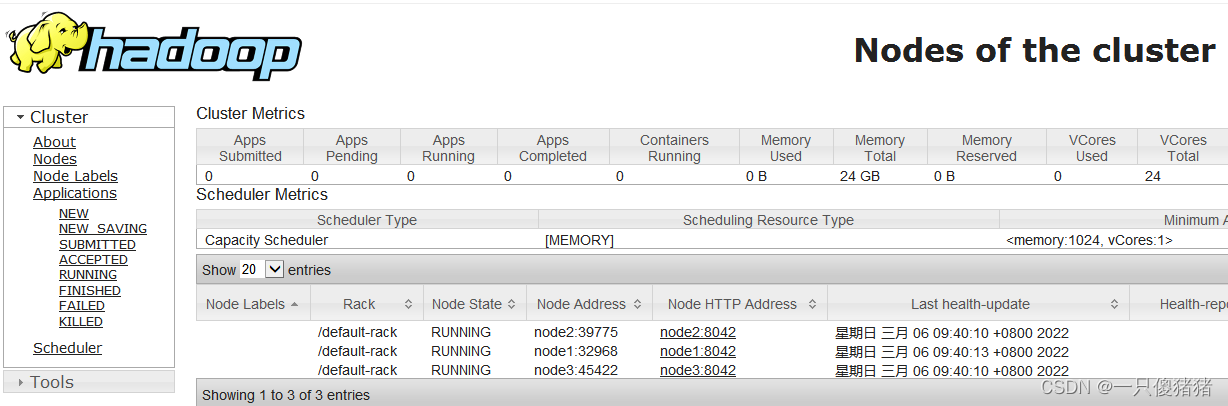
yarn集群监控界面
hdfs集群监控界面
http://node1:50070/dfshealth.html#tab-overview
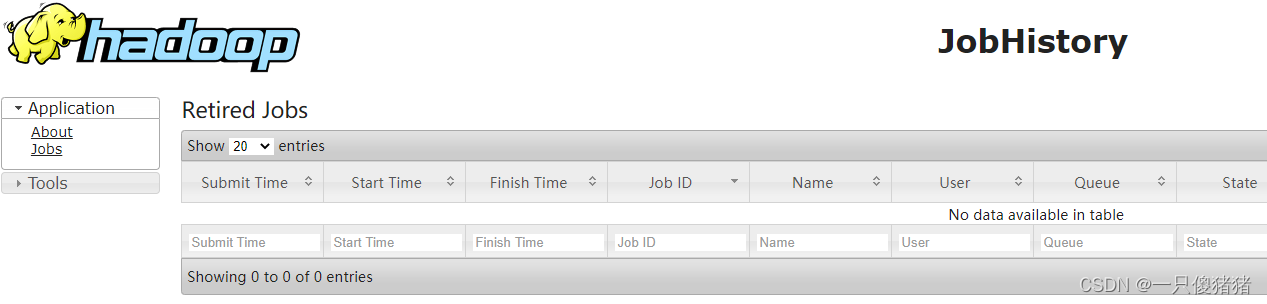
1.3 启动mr-jobhistory
[root@node1 myserver]# mr-jobhistory-daemon.sh start historyserver

mr-jobhistory监控界面
http://node1:19888/jobhistory
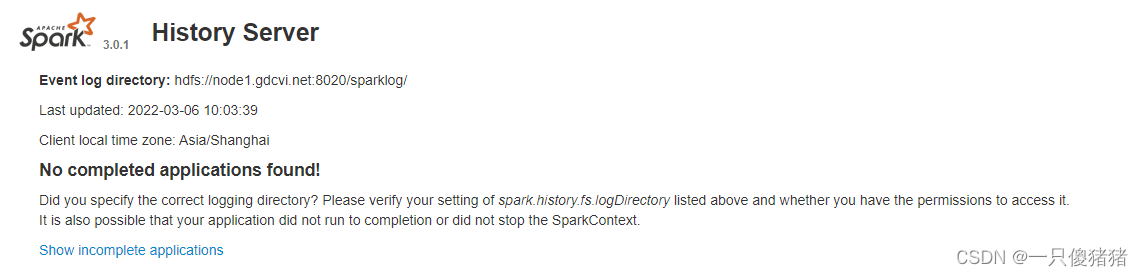
1.4 启动spark历史服务器history-server
[root@node1 myserver]# /myserver/spark301/sbin/start-history-server.sh

history-server监控界面
http://node1:18080/
服务全部开启后, 此时node1、node2和node3上的角色为 :
2、上传文件到虚拟机
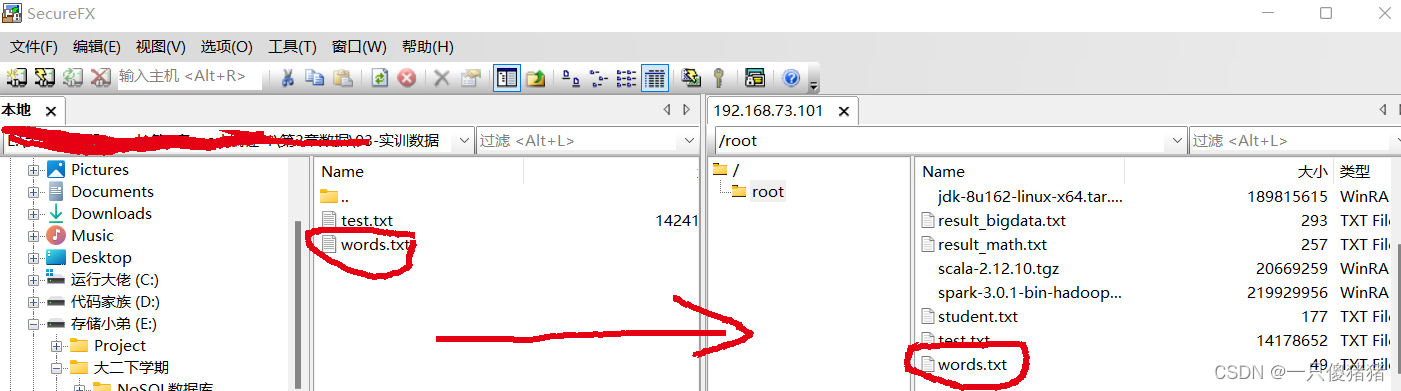
查看是否上传成功:

[root@nodel] hdfs dfs -put words.txt /user/root //上传到hdfs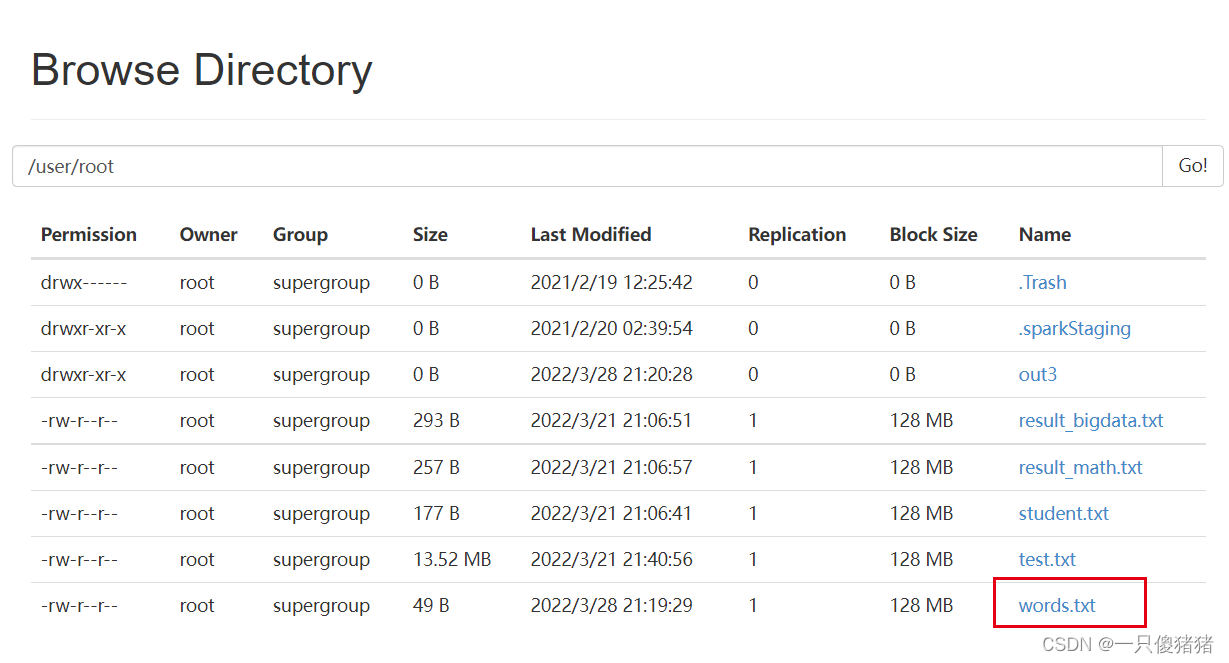
3、本地模式提交spark-submit
[root@node1 ~]# cd /myserver/spark301/sbin/
[root@node1 sbin]# /myserver/spark301/bin/spark-submit --master local[2] --class org.apache.spark.examples.SparkPi /myserver/spark301/examples/jars/spark-examples_2.12-3.0.1.jar 10 
4、spark本地模式启动spark-shell
[root@node1 opt]# ls
[root@node1 opt]# cd /myserver/spark301/bin/
[root@node1 bin]# /myserver/spark301/bin/spark-shell --master local[2]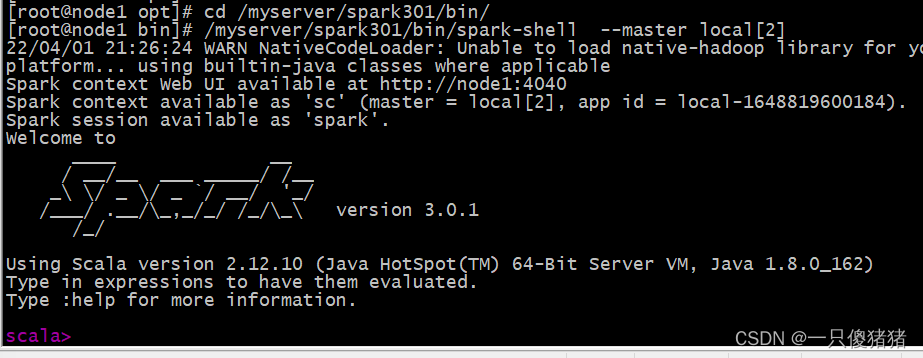
其中创建SparkContext实例对象:sc、SparkSession实例对象:spark和启动应用监控页面端口号:4040,详细说明如下:
Spark context Web UI available at http://node1.itcast.cn:4040
表示每个Spark 应用运行时WEB UI监控页面,端口号4040
Spark context available as 'sc' (master = local[2], app id = local-1646463160378).
表示SparkContext类实例对象名称为sc
在运行spark-shell命令行的时候,创建Spark 应用程序上下文实例对象SparkContext
主要用于读取要处理的数据和调度程序执行
Spark session available as 'spark'.
Spark2.x出现的,封装SparkContext类,新的Spark应用程序的入口
表示的是SparkSession实例对象,名称spark,读取数据和调度Job执行
5、执行以下代码实现 单词统计: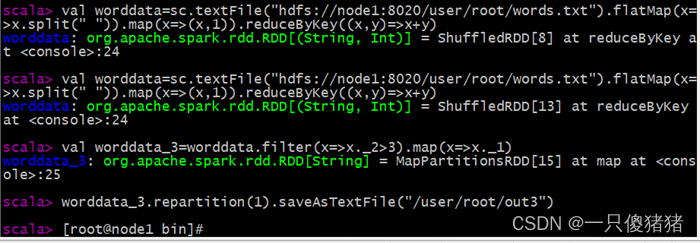
六、运行结果截图

七、总结
开启服务
在node1操作
[root@node1 ~]# start-dfs.sh
[root@node1 ~]# start-yarn.sh
[root@node1 myserver]# mr-jobhistory-daemon.sh start historyserver
[root@node1 myserver]# /myserver/spark301/sbin/start-history-server.sh
停止服务
在node1操作
[root@node1 ~]# stop-dfs.sh
[root@node1 ~]# stop-yarn.sh
[root@node1 myserver]# mr-jobhistory-daemon.sh stop historyserver
[root@node1 myserver]# /myserver/spark301/sbin/stop-history-server.sh
监控界面
http://node1:50070/dfshealth.html#tab-overview
http://node1:19888/jobhistory
http://node1:18080/


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)