数据可视化 理论知识(1) 数据可视化基础
数据类型
根据数据分析的要求,不同的应用应采用不同的数据分类方法。根据数据模型,我们可以将数据分为浮点数、整数、字符等;根据概念模型,可以定义数据为其对应的实际意义或者对象。在科学计算中,通常根据测量标度将数据分为四类:类别型数据、有序型数据、区间型数据和比值型数据。
- 类别型数据:用于区分物体。例如,根据性别可以将人分为男性或者女性;商品可按用途、原材料、生产方法、化学成分、使用状态等进行不同的分类。这些类别可以用来区分一组对象。
- 有序型数据:用来表示对象间的顺序关系,如成绩排名、身高排序等。
- 区间型数据:用于得到对象间的定量比较。相对于有序型数据,区间型数据提供了详细的定量信息。例如,身高 160cm 与身高 170cm 相差 10cm,而 170cm 与 180cm 也相差10cm,它们俩的差值是相等的。由此可见,区间型数据基于任意的起始点,只能衡量对象间的相对差别。
- 比值型数据:用于比较数值间的比例关系,可以精确地定义比例。比如,2 班的学生数量是 1 班的 2 倍(2∶1)。
不同的数据类型对应着不同的集合操作和统计操作:
通常并不区分区间型数据和比值型数据,所以可以将数据类型精简为三种:类别型数据、有序型数据和数值型数据(包括区间型数据和比值型数据)。
数据预处理
数据预处理的目的是提升数据质量,使得后续的数据处理、分析、可视化过程更加容易、有效。数据质量体现在以下六个方面:
- 有效性:数据与实际情况对应时,是否违背约束条件。
- 准确性:数据能否准确地反映现实。
- 完整性:采集的数据集是否包含了数据源中的所有数据点,且每个样本的属性都是完整的。
- 一致性:整个数据集中的数据的衡量标准要一致。
- 时效性:数据适合当下时间区间内的分析任务。
- 可信性:数据源中的数据是使用者可依赖的
数据预处理步骤有如下:
- 数据清理:指修正数据中的错误、识别脏数据、更正不一致数据的过程。其中涉及的技术有不一致性检测技术、脏数据识别技术、数据过滤技术、数据修正技术、数据噪声的识别与平滑技术等。
- 数据集成:指把来自不同数据源的同类数据进行合并,减少数据冲突,降低数据冗余程度等。
- 数据归约:指在保证数据挖掘结果准确性的前提下,最大限度地精简数据量,得到简化的数据集。数据归约技术包括维归约技术、数值归约技术、数据抽样技术等。数据归约技术可以用于得到数据集的归约表示,它虽然小,但会保持原数据的完整性。因此,在归约后的数据集上进行挖掘也会产生相同(或几乎相同)的分析结果。
- 数据变换:指对数据进行规范化处理。数据转换处理技术包括基于规则或元数据的转换技术、基于模型和学习的转换技术等
数据组织与管理、存储知识
- 分布式文件系统:是指文件在物理上可能被分散存储在不同地点的节点上,各节点通过计算机网络进行通信和数据传输,但在逻辑上仍然是一个完整的文件。用户在使用分布式文件系统时,无须知道数据存储在哪个具体的节点上,只需像操作本地文件系统一样进行管理和存储数据即可。常用的分布式文件系统有HDFS(Hadoop 分布式文件系统)、GFS(Google 分布式文件系统)、KFS(Kosmos分布式文件系统)等,常用的分布式内存文件系统有 Tachyon 等。
- 文档存储: 文档存储支持对结构化数据的访问,一般以键值对的方式进行存储,文档存储模型支持嵌套结构,也支持数组和列值键。主流的文档数据库有
MongoDB、CouchDB、Terrastore、RavenDB 等。 - 键值存储:键值存储,即 Key-Value 存储,简称 KV 存储。它是 NoSQL
存储的一种方式。它的数据按照键值对的形式进行组织、索引和存储。键值存储能有效地减少读写磁盘的次数。键值存储实际是分布式表格系统的一种。主流的键值数据库产品有
Redis、ApacheCassandra、Google Bigtable。 - 图形数据库: 图形数据库是 NoSQL数据库的一种类型,是一种非关系型数据库,它应用图形理论存储实体之间的关系信息。主流的图形数据库有GooglePregel、Neo4j、Infinite Graph、DEX、InfoGrid、HyperGraphDB 等。
- 关系数据库: 关系模型是最传统的数据存储模型,数据按行存储在有架构界定的表中。表中的每个列都有名称和类型,表中的所有记录都要符合表的定义。用户可使用基于关系代数演算的结构化查询语言(Structured Query Language,SQL)提供相应的语法查找符合条件的记录。关系模型数据库通常提供事务处理机制,可以进行多条记录的自动化处理。在编程语言中,表可以被视为数组、记录列表或者结构。关系型数据库也进行了改进,支持如分布式集群、列式存储,支持
XML、JSON 等数据的存储。 - 内存数据库:内存数据库(Main Memory Database,MMDB)就是将数据放在内存中直接操作的数据库。相对于磁盘数据,内存数据的读写速度要高出几个数量级。MMDB
的最大特点是其数据常驻内存,即活动事务只与实时内存数据库的内存数据“打交道”,所处理的数据通常是“短暂”的,有一定的有效时间,过时则有新的数据产生。所以,实际应用中采用内存数据库来处理实时性强的业务逻辑。内存数据库产品有
Oracle TimesTen、eXtremeDB、Redis、Memcached等。 - 数据仓库: 数据仓库(Data Warehouse)是一种特殊的数据库,一般用于存储海量数据,并直接支持后续的分析和决策操作。数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。存放在数据仓库中的数据一般不会再修改。
数据分析与数据挖掘
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,目的是找出内在规律,提取隐藏在大量数据中的信息,从而帮助人们理解、判断、决策和行动。
常用的数据分析有统计分析、探索性数据分析、验证性数据分析、在线分析与处理:
- 统计分析:是指对数据进行统计描述和统计推断的过程。统计描述指应用统计特征(均值、标准差和相关系数等)、统计表和统计图等方法,对数据的数量特征及其分布规律进行测定和描述(如集中趋势、离散程度和相关程度等)。统计推断是指用概率方法判断数据之间的关系及用样本统计特征来推测总体特征的方法。统计推断已成为统计学的核心内容,是数据分析的重要方法。
- 探索性数据分析(Exploratory Data Analysis,EDA):是对调查、观测所得到的一些初步的杂乱无章的数据,在尽量少的先验假定下进行处理,通过作图、制表等形式和方程拟合、计算某些特征量等手段,探索数据的结构和规律的一种数据分析方法。它强调从数据中寻找出之前没有发现过的特征和信息。
- 验证性数据分析:是指在已经有事先假设的关系模型等情况下,通过数据分析来验证已提出的假设。
- 在线分析与处理(Online Analysis Processing,OLAP):是一种交互式探索大规模多维数据集的方法。OLAP 将数据实体的多项重要属性定义为多个维度,让用户比较不同维度上的数据。OLAP 的基本功能有切片和切块(Slice and
Dice)、钻取(Drill)和旋转(Pivoting)。
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中的信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现搜索隐藏于大量数据中的信息。
常见的数据挖掘分析方法有分类与预测、聚类分析、关联分析和异常分析等。
- 分类与预测 :
分类算法是从数据中选出已经分好类的训练集,在此训练集上运用数据挖掘分类技术,构造一个分类模型,然后再根据此分类模型对数据集中未分类的数据进行分类。其中,类的个数是确定的,预先定义好的。分类器的构造方法多种多样,如决策树、贝叶斯方法、神经网络和遗传算法等。 - 聚类分析 :
聚类指将数据集聚集成几个簇(聚类),使得同一个聚类中的数据集之间的相似程度高,而不同聚类中的数据集之间的相似程度低,利用分布规律从数据集中发现有用的规律。聚类不依赖于预先定义好的类,不需要训练集。因此,聚类通常作为其他算法(如特征和分类)的预处理步骤。聚类方法有很多,常见的有五类:划分方法、层次方法、基于密度方法、基于网格方法和基于模型方法。 - 关联分析:
关联分析就是发现存在于大量数据集中的关联性或相关性,从而描述了一个事物中某些属性同时出现的规律和模式。关联分析中的最重要的内容是关联规则的挖掘研究,关联规则描述在一个数据集中的一个数据与其他数据之间的相互依存性和关联性。关联规则可从事务、关系数据中的集合对象发现频繁模式、关联规则、相关性或因果结构。关联分析的一个典型例子是购物篮分析。该过程通过发现顾客放入购物篮中的不同商品之间的联系,分析顾客的购买习惯。 - 异常分析:
在海量数据中,有少量数据与通常数据的行为特征不一样,在数据的某些属性方面有很大的差异。它们是数据集中的异常子集,或称离群点。通常,它们被认为是噪声,常规的数据处理试图将它们的影响最小化,或者删除这些数据。然而,这些异常数据可能是重要信息,包含潜在的知识。
数据挖掘的步骤如下:
- 确定业务对象: 清晰地定义业务问题,认清数据挖掘的目的。数据的挖掘结果是不可预测的,但要探索的方向应是有预见的,不应该带有盲目性。
- 数据准备 :
数据的准备包括数据的选择(选择适用于数据挖掘应用的数据)、数据的预处理(研究数据的质量,并确定将要进行的挖掘操作的类型)和数据的转换(将数据转换成一个针对挖掘算法建立的分析模型)。 - 数据挖掘: 对所得到的经过预处理的数据进行挖掘。除了选择合适的挖掘算法外,其余一切工作都能自动地完成。
- 结果分析: 解释并评估结果。其使用的分析方法一般应根据数据挖掘操作而定,通常会用到可视化技术。
- 知识的同化: 将分析所得到的知识集成到业务信息系统的组织结构中去。
数据可视化的基本框架
数据可视化的流程以数据流向为主线,其核心流程主要包括数据采集、数据处理和变换、可视化映射和用户感知四大步骤。
- 数据采集。可视化的对象是数据,而采集的数据涉及数据格式、维度、分辨率和精确度等重要特性,这些都决定了可视化的效果。因此,在可视化设计过程中,一定要事先了解数据的来源、采集方法和数据属性,这样才能准确地反映要解决的问题。
- 数据处理和变换。这是数据可视化的前期准备工作。原始数据中含有噪声和误差,还会有一些信息被隐藏。可视化之前需要将原始数据转换成用户可以理解的模式和特征并显示出来。包括去噪、数据清洗、提取特征等流程。
- 可视化映射。可视化映射过程是整个流程的核心,其主要目的是让用户通过可视化结果去理解数据信息以及数据背后隐含的规律。该步骤将数据的数值、空间坐标、不同位置数据间的联系等映射为可视化视觉通道的不同元素,如标记、位置、形状、大小和颜色等。因此,可视化映射是与数据、感知、人机交互等方面相互依托,共同实现的。
- 用户感知。可视化映射后的结果只有通过用户感知才能转换成知识和灵感。用户从数据的可视化结果中进行信息融合、提炼、总结知识和获得灵感。数据可视化可让用户从数据中探索新的信息,也可证实自己的想法是否与数据所展示的信息相符合,用户还可以利用可视化结果向他人展示数据所包含的信息。用户可以与可视化模块进行交互。
数据可视化的设计标准,设计数据可视化时,我们应遵守以下可视化设计标准:
- 表达力强。能真实全面地反映数据的内容。
- 有效性强。一个有效的可视化设计应在短时间内把数据信息以用户容易理解的方式显示出来。
- 能简洁地传达信息。这样能在有限的画面里呈现更多的数据,而且不容易让用户产生误解。
- 易用。用户交互的方式应该简单、明了,用户操作起来更方便。
- 美观。视觉上的美感可以让用户更易于理解可视化要表达的内容,提高工作效率。
数据可视化的设计框架:
框架中的每个层次都存在着不同的设计难题,第一层需要准确定义问题和目标,第二层需要正确处理数据,第三层需要提供良好的可视化效果,第四层需要解决可视化系统的运行效率问题。各层之间是嵌套关系,外层的输出是内层的输入。
- 第一层描述现实生活中用户遇到的实际问题。在第一层中,可视化设计人员会用大量的时间与用户接触,采用有目标的采访或软件工程领域的需求分析方法来了解用户需求。
- 第二层是抽象层,它将第一层确定的任务和数据转换为信息可视化术语
- 第三层是编码层,设计视觉编码和交互方法,是可视化研究的核心内容。视觉编码和交互这两个层面通常相互依赖。
- 第四层则需要具体实现与前三个层次匹配的数据可视化展示和交互算法,相当于一个细节描述过程。
数据可视化的主要目的是准确地为用户展示和传达出数据所包含(隐藏)的信息。
数据可视化的基本图表
原始数据绘图用于可视化原始数据信息的直观呈现。其典型方法有数据轨迹、柱状图、条形图、折线图、直方图、饼图、等值线图、走势图、散点图、气泡图、维恩图、热力图和雷达图等。实际选择图表时应先从总体上观察数据,然后细化到具体的分类和其他的特性。
-
数据轨迹 : 数据轨迹是一种标准的单变量数据呈现方法:x 轴显示自变量,y
轴显示因变量。数据轨迹可直观地呈现数据分布、离群值、均值的偏移等。(也叫做K线图)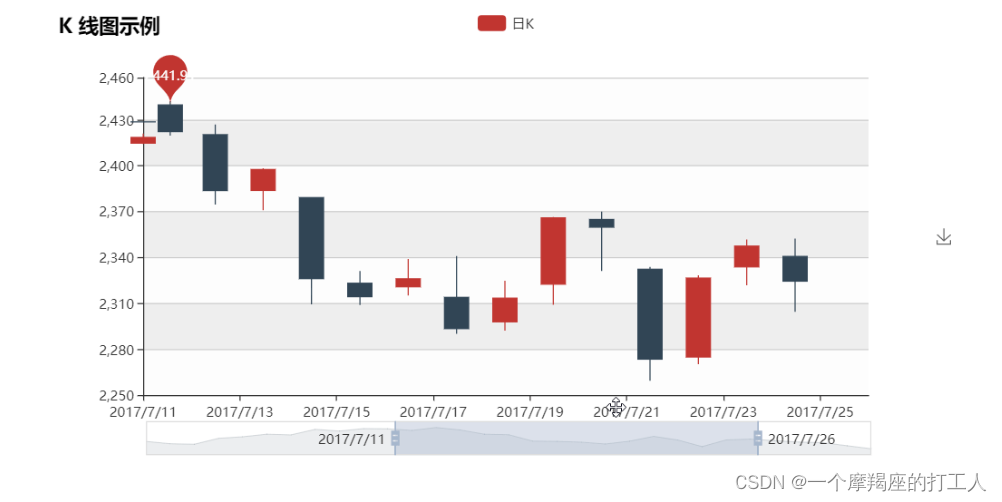
-
柱状图 :
柱状图采用长方形的形状和颜色编码数据的属性。柱状图的每根直柱内部也可以用像素图方式编码,称为堆叠柱状图。柱状图适用于二维数据集,但只有一个维度需要比较,柱状图利用柱子的高度反应数据的差异。柱状图的局限在于只适用于中小规模的数据集。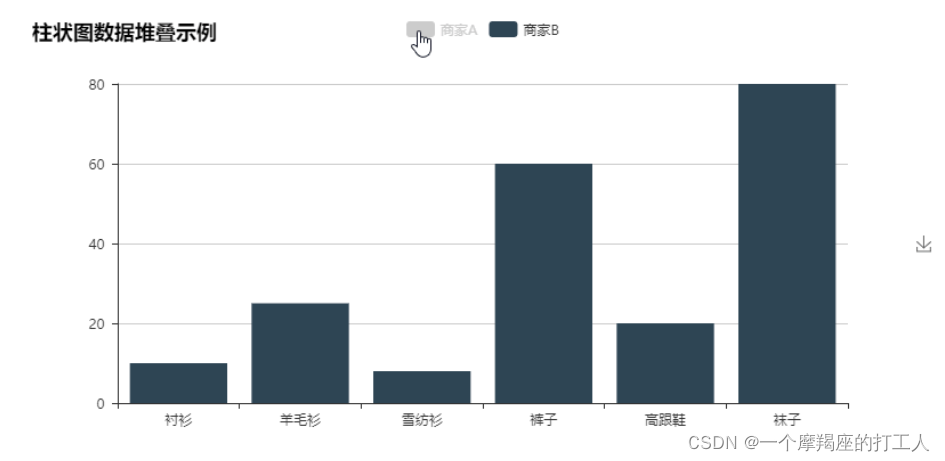
-
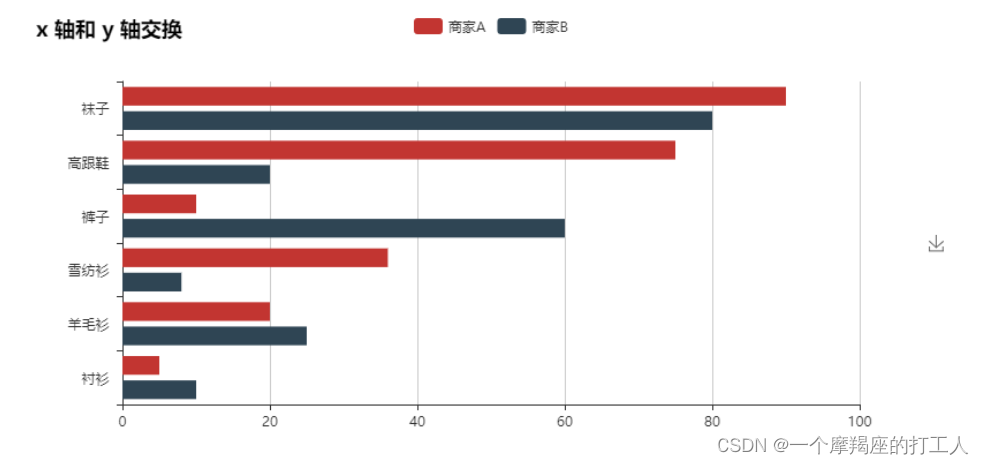
条形图 : 条形图是柱形图向右旋转了 90°的呈现方式,如图 2-24 所示。当条目数较多时,如大于12条时,移动端上的柱状图会显得拥挤不堪,这时更适合用条形图。条形图的条目数一般要求不超过 30 条,否则易带来视觉和记忆上的负担。
-
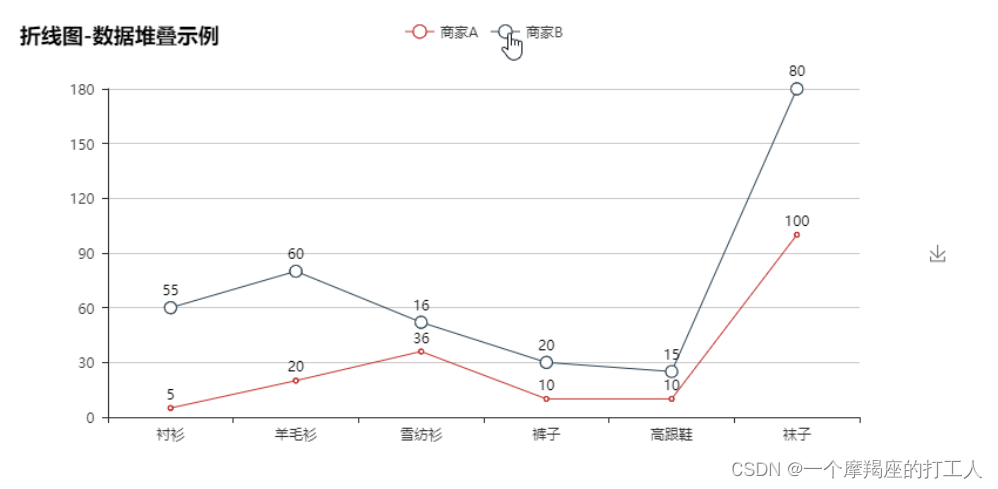
折线图 : 拆线图可用于二维大数据集,适用于趋势比单个数据点更重要的场合。折线图还适用于多个二维数据集的比较。
-
直方图 : 直方图是对数据集中某个数据属性的频率统计。对于单变量数据,其取值范围映射到横轴,并分割为多个子区间。直方图可以呈现数据的分布、离群值和数据分布的状态。直方图的各个部分之和等于单位整体,而柱状图的各个部分之和则没有限制,这是两者的主要区别。
-
饼图 : 饼图采用环状方式呈现各分量在整体中的比例。由于人眼对面积的大小不敏感,当饼图各个分量比例相差不大时,应用柱状图替代饼图。除饼图外,环形图(甜甜圈图)也可以表示占比,其差异是将饼图的中间区域挖空,在空心区域显示文本信息,比如标题。旭日图既可以表示占比情况,也可以表示层级构成关系。
-
等值线图 : 等值线图使用相等数值的数据点连线来表示数据的连续分布和变化规律。等值线图中的曲线是空间中具有相同数值(高度、深度等)的数据点在平面上的投影。
-
走势图 : 走势图是一种紧凑、简洁的数据趋势表达方式,它通常以折线图为基础,往往直接嵌入在文本或表格中。走势图使用高度密集的折线图表达方式来展示数据随某一变量(时间、空间)的变化趋势。
-
散点图 : 散点图是表示二维数据的标准方法。在散点图中,所有数据以点的形式出现在笛卡儿坐标系中,每个点所对应的横、纵坐标分别代表该数据在坐标轴上的属性值大小。散点图适用于三维数据集,但其中只有两维需要比较。为了识别第三维,可以为每个点加上文字标识,或者不同的颜色。
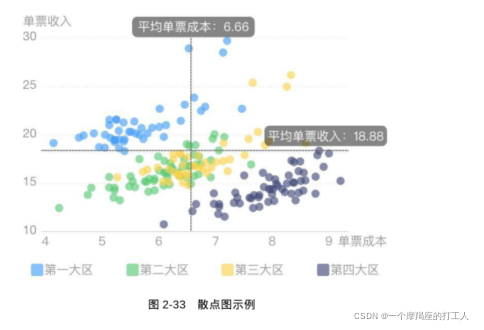
-
气泡图 : 气泡图是散点图的一种变形,通过每个点的面积大小来表示第三维。如果为气泡图加上不同颜色(或者文字标签),气泡图就可以用来表示四维数据。
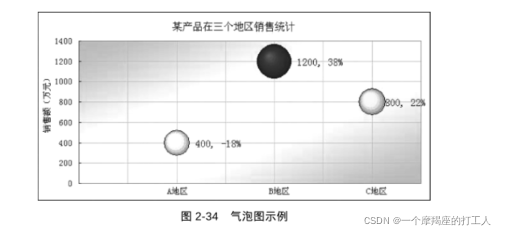
-
维恩图: 维恩图(Venn 图),它使用平面上的封闭图形来表示数据集合之间的关系。每个封闭图形代表一个数据集合,图形之间的交叠部分代表集合间的交集,图形外的部分代表不属于该集合的数据部分
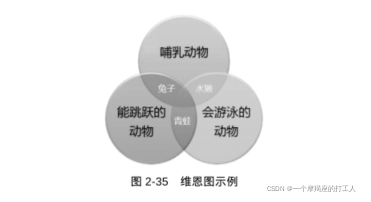
-
热力图 : 热力图使用颜色来表达位置相关的二维数值数据大小。这些数据常以矩阵或方格形式排列,或在地图上按一定位置关系排列,每个数据点可以使用颜色编码数值。
-
雷达图:雷达图又称蜘蛛网图(Spider Chart),适用于多维数据(四维以上),且每个维度必须可以排序。
-
箱形图 : 又称为盒须图,是用于显示一组数据分散情况的统计图,因形如箱子而得名。。它显示出一组数据的最大值、最小值、中位数及上下四分位数。
-
WordCloud(词云图):
词云
数据可视化工具
数据可视化工具大致分为入门级工具(Excel)、信息图表工具(D3、Visual.ly、Raphaël、Flot、Echarts、Tableau)、地图工具(Modest Maps、Leaflet、PolyMaps、Openlayers、Kartograph、Quanum GIS)和高级分析工具(Processing、NodeBox、R、Python、Weka 和 Gephi)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)