动手学强化学习第九章(策略梯度算法)
·
文章转载自《动手学强化学习》https://hrl.boyuai.com/chapter/intro
1.理论
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V0oZoou2-1651247139124)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220429233235352.png)]](https://i-blog.csdnimg.cn/blog_migrate/59d90cea11facc93cf6a349efbf83e48.png)
本节介绍的是REINFORCE算法,其在估计每个状态动作对的奖励时不使用整个回合的奖励,而是该时刻开始之后的累计奖励作为权值。
∇ θ J ( θ ) = E π θ [ ∑ t = 0 T ( ∑ t ′ = t T γ t ′ − t r t ′ ) ∇ θ log π θ ( a t ∣ s t ) ] \nabla_{\theta} J(\theta)=\mathbb{E}_{\pi_{\theta}}\left[\sum_{t=0}^{T}\left(\sum_{t^{\prime}=t}^{T} \gamma^{t^{\prime}-t} r_{t^{\prime}}\right) \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right)\right] ∇θJ(θ)=Eπθ[t=0∑T(t′=t∑Tγt′−trt′)∇θlogπθ(at∣st)]
算法流程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PeV6ImuT-1651247139127)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220429233548923.png)]](https://i-blog.csdnimg.cn/blog_migrate/021fcc1957a0feb31f53bca0cc49f4b1.png)
在下面的代码实现中,先实现一个episode然后从后往前计算回报,损失函数是负的回报乘于log的该状态下采取该动作的概率。每个状态动作对对应算一次loss,然后反向传播计算梯度。最后整个episode完之后进行梯度下降。
2.代码实践
import gym
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import rl_utils
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1) # 0是对列做归一化,1是对行做归一化
class REINFORCE:
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
device):
self.policy_net = PolicyNet(state_dim, hidden_dim,
action_dim).to(device)
self.optimizer = torch.optim.Adam(self.policy_net.parameters(),
lr=learning_rate) # 使用Adam优化器
self.gamma = gamma # 折扣因子
self.device = device
def take_action(self, state): # 根据动作概率分布随机采样
state = torch.tensor([state], dtype=torch.float).to(self.device) # 1*4
probs = self.policy_net(state) # 1*2
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
reward_list = transition_dict['rewards']
state_list = transition_dict['states']
action_list = transition_dict['actions']
G = 0
self.optimizer.zero_grad()
for i in reversed(range(len(reward_list))): # 从最后一步算起
reward = reward_list[i]
state = torch.tensor([state_list[i]], # 1*4
dtype=torch.float).to(self.device)
action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device) # 1*1
log_prob = torch.log(self.policy_net(state).gather(1, action)) # 1*1
G = self.gamma * G + reward
loss = -log_prob * G # 每一步的损失函数
loss.backward() # 反向传播计算梯度
self.optimizer.step() # 梯度下降
learning_rate = 1e-3
num_episodes = 1000
hidden_dim = 128
gamma = 0.98
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = "CartPole-v0"
env = gym.make(env_name)
env.seed(0)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma,
device)
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
transition_dict = {
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': []
}
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
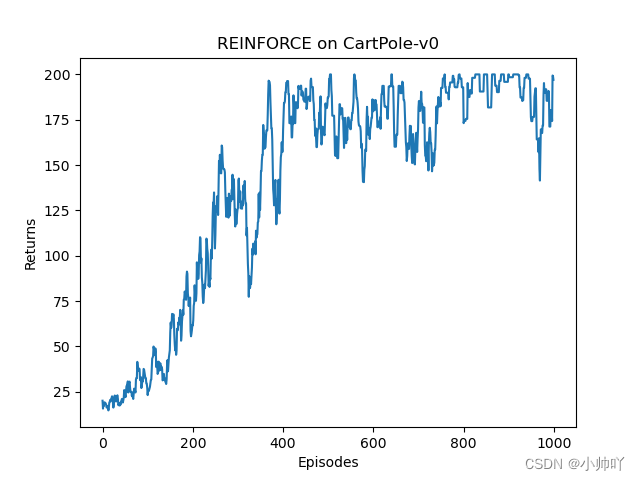
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hB8DSlMJ-1651247139129)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220429234402379.png)]](https://i-blog.csdnimg.cn/blog_migrate/855938762ff0d3a5854ccf97b9d2fc47.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rjWqYX2Y-1651247139130)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220429234415629.png)]](https://i-blog.csdnimg.cn/blog_migrate/f15077afbe22568e86dac54fe6569fa3.png)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)