数据挖掘-二项逻辑斯蒂回归模型算法的R实现
本次为学生时期所写的实验报告,代码程序为课堂学习和自学,对网络程序有所参考,如有雷同,望指出出处,谢谢!
基础知识来自教材:李航的《统计学习方法》
本人小白,仍在不断学习中,有错误的地方恳请大佬指出,谢谢!
本次实验将分别采用梯度下降法和牛顿法进行二项逻辑斯蒂回归模型参数估计
一、代码实现(R语言)
1.梯度下降法
#预备代码:
#计算似然函数:对i求和( yi*(w^T*x)-log(1+exp(w^T*x)) )
likelihood_fuc<-function(y,X,w){
N=nrow(X)
save=rep(NA,N)
for (i in 1:N) {
save[i]=y[i]*t(w)%*%X[i,]-log(1+exp(t(w)%*%X[i,]))
}
sum=sum(save)
sum
}
#梯度下降法
my_gradiant_descent<-function(X,y,w,ddmax,limit,lambda){
#X为n*p+1矩阵(n次观测,p个特征,最后一列全为1)
#y为n维列向量
#w输入初值w0(w为p+1维向量)
#ddmax为最大迭代次数
#limit为给定阈值
#lambda为一系列步长的预设值
N=dim(X)[1] #N为样本数
pai=rep(NA,N) #π(x)为n维列向量,记录每个给定xi(xi为p维向量)下y=1的概率
i=1
while (i<=ddmax){
#给定x、w时y=1的概率π(x)
pai=t(exp(t(w)%*%t(X))/(1+exp(t(w)%*%t(X)))) #pai为n×1的列向量
#计算此时梯度X^T*(π-y)
grad=t(X)%*%(pai-y)
grad_norm=sqrt(sum(grad^2)) #梯度的模长
#迭代的判断条件及其处理
if(grad_norm>=limit){
#选取最适宜步长(寻找给定w下使似然函数最大的步长)
result=rep(NA,length(lambda))
for (k in 1:length(lambda)) {
result[k]=likelihood_fuc(y,X,w-lambda[k]*grad)
}
lambdabest=lambda[which.max(result)]
#更新w
w=w-lambdabest*grad
#进入下一次迭代
i=i+1
}else{
break #若不满足阈值要求,则退出循环
}
}
w
}2.牛顿法
my_Newton_method<-function(X,y,w,ddmax,limit){
#X为n*p+1矩阵(n次观测,p个特征,最后一列全为1)
#y为n维列向量
#w输入初值w0(w为p+1维向量)
#ddmax为最大迭代次数
#limit为给定阈值
N=dim(X)[1] #N为样本数
pai=rep(NA,N)
#π(x)为n维列向量,记录每个给定xi(xi为p维向量)下y=1的概率
D=matrix(0,ncol=N,nrow = N) #D为n×n的空矩阵,用于后续海塞矩阵的便捷计算
i=1
while (i<=ddmax){
#给定x、w时y=1的概率π(x)
for(j in 1:N){
pai[j]=exp(t(w)%*%X[j,])/(1+exp(t(w)%*%X[j,]))
D[j,j]=pai[j]*(1-pai[j])
#D为对角矩阵,第(i,i)元素为π(xi)*(1-π(xi));其中xi为每一次观测的值,为p+1维向量
}
#计算此时梯度
grad=t(X)%*%(pai-y)
grad_norm=sqrt(sum(grad^2)) #梯度的模长
#迭代的判断条件及其处理
if(grad_norm>=limit){
#海塞矩阵求逆
invH=solve(t(X)%*%D%*%X)
#更新w
w=w-invH%*%grad
#进入下一次迭代
i=i+1
}else{
break
}
}
w
}3. S-折交叉验证函数编写
###梯度下降法交叉验证
Stest_gradiant_descent<- function(X,y,S,ddmax,limit,lambda,up,down){
#X为n*p+1矩阵(n次观测,p个特征,最后一列全为1)
#y为n维列向量
#S为折数
#ddmax为最大迭代次数;limit为阈值
#up、down为预设阈值:即概率P(Y=1|x)大于up时认定y为1,P(Y=1|x)小于给定down时认定y为0
#数据的行数
n = dim(X)[1]
percentage = rep(NA,S)
#进行1到S的循环,总长度为n(如1,2,3,4,1,2,3,4,1,2...),并进行打乱
CV.ID = sample(rep(1:S,length.out = n))
for (j in 1:S){
X.test = X[CV.ID==j,]
#相当于从被分为S份的数据中随机抽取1份作为测试数据集,循环S次
y.test = y[CV.ID==j]
X.train = X[CV.ID!=j,]
#相当于从被分为S份的数据中随机抽取(S-1)份作为训练数据集,循环S次
y.train = y[CV.ID!=j]
w.hat=my_gradiant_descent(X.train,y.train,w=c(0,0,0,0,0),
ddmax,limit,lambda) #测试数据集中y的预测值
y.hat.prop=exp(t(w.hat)%*%t(X.test))/
(1+exp(t(w.hat)%*%t(X.test)))
#y.hat.prop为n维行向量,每个元素代表Y=1的概率
y.hat.prop[y.hat.prop>=up]=1 #预设概率大于up时为1,概率小于down时为0
y.hat.prop[y.hat.prop<down]=0
y.hat=y.hat.prop
#由准确率来判断误差大小
percentage[j] = sum(y.hat==y.test)/length(y.test)
}
correct = mean(percentage)
error = 1-mean(percentage)
plot(1:S,percentage,type="l") #绘制准确率的折线图
list(correct = correct,error = error,percentage = percentage)
}
###牛顿法交叉验证
Stest_Newton<- function(X,y,S,ddmax,limit,up,down){
#X为n*p+1矩阵(n次观测,p个特征,最后一列全为1)
#y为n维列向量
#S为折数
#ddmax为最大迭代次数;limit为阈值
#up、down为预设阈值:即概率P(Y=1|x)大于up时认定y为1,P(Y=1|x)小于给定down时认定y为0
#数据的行数
n = dim(X)[1]
percentage = rep(NA,S)
#进行1到S的循环,总长度为n(如1,2,3,4,1,2,3,4,1,2...),并进行打乱
CV.ID = sample(rep(1:S,length.out = n))
for (j in 1:S){
X.test = X[CV.ID==j,]
#相当于从被分为S份的数据中随机抽取1份作为测试数据集,循环S次
y.test = y[CV.ID==j]
X.train = X[CV.ID!=j,]
#相当于从被分为S份的数据中随机抽取(S-1)份作为训练数据集,循环S次
y.train = y[CV.ID!=j]
w.hat=my_Newton_method(X.train,y.train,w=c(0,0,0,0,0),
ddmax,limit) #测试数据集中y的预测值
y.hat.prop=exp(t(w.hat)%*%t(X.test))/
(1+exp(t(w.hat)%*%t(X.test)))
#y.hat.prop为n维行向量,每个元素代表Y=1的概率
y.hat.prop[y.hat.prop>=up]=1 #预设概率大于up时为1,概率小于down时为0
y.hat.prop[y.hat.prop<down]=0
y.hat=y.hat.prop
#由准确率来判断误差大小
percentage[j] = sum(y.hat==y.test)/length(y.test)
}
correct = mean(percentage)
error = 1-mean(percentage)
plot(1:S,percentage,type="l") #绘制准确率的折线图
list(correct = correct,error = error,percentage = percentage)
}二、检验
1.输入
##########数据处理####
##选择数据:iris数据集
iris <- read.csv("F:/大三下/数据挖掘/UCI数据集/Iris/iris.data",header = FALSE)
y<-iris[,5]
#由于为二项逻辑回归,考虑只选择y的种类为"Iris-setosa"和"Iris-virginica"的数据集
split=split(iris,factor(y),drop = TRUE)
#使用split函数将数据按特征列y的各取值进行分割成多个列表
#矩阵X
X=rbind(split[[1]],split[[3]])[,-5]
rownames(X)=NULL
X=cbind(X,1)
X=as.matrix(X)
X
#种类列y
y=rbind(split[[1]],split[[3]])[5]
rownames(y)=NULL
y[y=="Iris-setosa"]=1
y[y=="Iris-virginica"]=0
#将y两个取值"Iris-setosa"、"Iris-virginica"分别用1、0表示
y=as.numeric(as.matrix(y))
y
#此时X与y的类型均为矩阵,X的规格为n×(p+1)
################检验过程####
#给定概率精度0.9、0.1
Stest_gradiant_descent(X,y,S=5,ddmax=100,limit = 0.01,
lambda=seq(0.001,0.005,0.001),
up=0.9,down=0.1)
Stest_Newton(X,y,S=5,ddmax=100,limit = 0.01,up=0.9,down=0.1)
#给定概率精度0.9999、0.1
Stest_gradiant_descent(X,y,S=5,ddmax=100,limit = 0.01,
lambda=seq(0.001,0.005,0.001),
up=0.9999,down=0.1)
Stest_Newton(X,y,S=5,ddmax=100,limit = 0.01,up=0.9999,down=0.1)2.输出结果与分析
(1)给定概率精度0.9、0.1
①梯度下降法
>Stest_gradiant_descent(X,y,S=5,ddmax=100,limit = 0.01,lambda=seq(0.001,0.005,0.001),up=0.9,down=0.1)
$correct
[1] 1
$error
[1] 0
$percentage
[1] 1 1 1 1 1
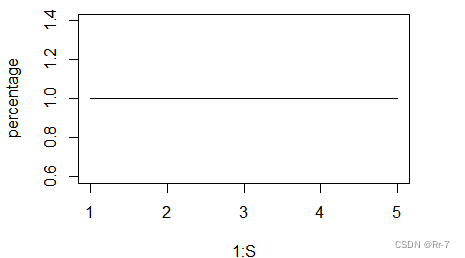
分析:由结果可知:给定概率精度0.9、0.1下,使用梯度下降法估计的w进行预测时,平均预测准确率为100%,五次交叉验证的预测准确率都为100%,预测效果很好
②牛顿法
> Stest_Newton(X,y,S=5,ddmax=100,limit = 0.01,up=0.9,down=0.1)
$correct
[1] 1
$error
[1] 0
$percentage
[1] 1 1 1 1 1
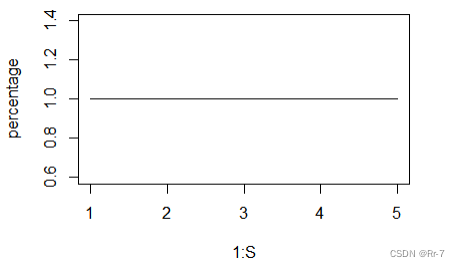
分析:由结果可知:给定概率精度0.9、0.1下,使用牛顿法估计的w进行预测时,平均预测准确率为100%,五次交叉验证的预测准确率都为100%,预测效果很好。
(2)给定概率精度0.9999、0.1
①梯度下降法
$correct
[1] 0.5
$error
[1] 0.5
$percentage
[1] 0.65 0.40 0.50 0.50 0.45
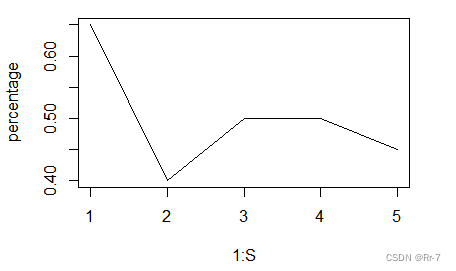
分析:由结果可知:给定概率精度0.9999、0.1下,使用梯度下降法估计的w进行预测时,平均预测准确率为50%,五次交叉验证的预测准确率均徘徊在50%之间,预测效果变差。
②牛顿法
> Stest_Newton(X,y,S=5,ddmax=100,limit = 0.01,up=0.9999,down=0.1)
$correct
[1] 0.95
$error
[1] 0.05
$percentage
[1] 0.95 0.90 0.95 1.00 0.95
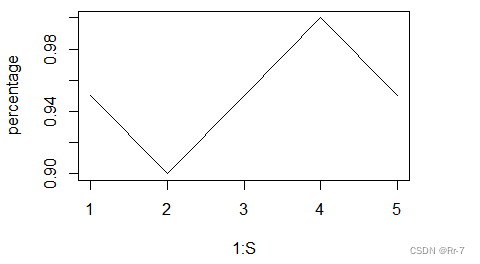
分析:由结果可知:给定概率精度0.9999、0.1下,使用牛顿法估计的w进行预测时,平均预测准确率为95%,五次交叉验证的预测准确率均在90%及以上,预测效果仍然较好。
三、小结
本次实验主要编写了梯度下降法和牛顿法对逻辑斯地回归似然函数参数进行估计。首先需熟练掌握二项逻辑斯地回归的似然函数的建立;其次在应用算法时需明确似然函数对参数w的一阶梯度和二阶梯度。梯度下降法牛顿法都是迭代算法,通过选取适当的初值x(0),不断迭代,更新x的值,进行目标函数的最小化,直至收敛。负梯度方向是使函数下降最快的方向,所以在迭代的每一步,以负梯度方向更新x的值从而达到减少函数值的目的。而梯度下降法与牛顿法的不同之处在于:梯度下降法使用一阶泰勒逼近;而牛顿法使用了二阶泰勒逼近。这使得两种算法对x的更新方法不同。在正式的函数编写和交叉验证中,可以发现牛顿法的运行速度较梯度下降法快,在适当精度下,通过牛顿法与梯度下降法估计的参数进行预测的准确率都很好,但在高精度情况下,梯度下降法估计的参数预测准确率有明显下降,而牛顿法则维持原来的较高的准确率水平。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)