简单介绍ogb包(open graph benchmark)(图神经网络的基准数据集)
Open Graph Benchmark (OGB) 是一个图深度学习的基准数据集。
·
简介
ogb 是 Open Graph Benchmark 的缩写,它是一个用于图机器学习的大规模基准库。ogb 提供了多种真实世界数据集以及评估器(evaluator),旨在促进图机器学习领域的发展和标准化评估方法的应用。该库特别适合于研究者、工程师和学生用来测试新的算法和技术,并确保这些技术在实际应用中具有竞争力。官网:https://ogb.stanford.edu/。该包斯坦福开发,源自论文:Open Graph Benchmark: Datasets for Machine Learning on Graphs。
主要特点
- 多样化的真实世界数据集:涵盖了不同类型的图数据集,包括节点分类、边预测和图分类任务。
- 标准评估协议:为每个数据集提供了具体的评估指标和分割策略,确保结果的可比性。
- 兼容性强:支持流行的图学习框架如 PyTorch Geometric 和 DGL(Deep Graph Library),便于集成到现有的工作流中。
- 持续更新:随着新数据集和挑战的出现,OGB 不断扩展其内容,保持前沿性。
数据集
那么其包含了哪些数据集呢?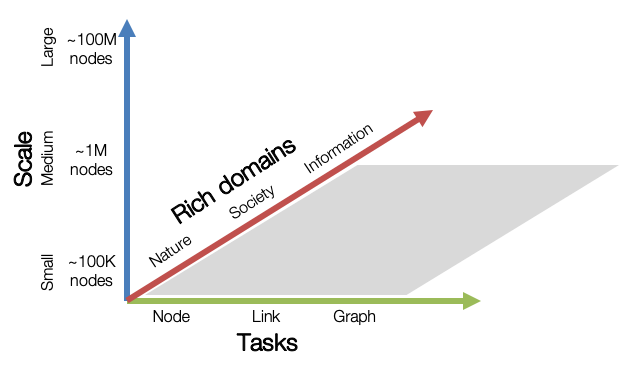
从上图可以看到,其包含了来自不同领域,不同数量级,不同任务的数据集。
下载
conda install ogb
#或者
pip install ogb
使用示例
其开发了一个包,名字叫做ogb,并且提供了接口给两大最流行的图神经网络库:DGL和PyG。
例如如果我们要做节点分类这个任务,可以如下使用ogb提供的基准数据集,
如果你使用DGL库:
import dgl
import torch
from ogb.nodeproppred import DglNodePropPredDataset#即node property prediction
dataset = DglNodePropPredDataset(name = d_name)#使用节点分类具体哪一个数据集。
如果你使用PyG库:
import torch_geometric
import torch
from ogb.nodeproppred import PygNodePropPredDataset
dataset = PygNodePropPredDataset(name = d_name)#使用节点分类具体哪一个数据集。
至于再接下来怎么用,那就是DGL和PyG的事情了,就是操作这个dataset即可。
那么问题是这些name有哪些选项呢?也就是说,哪里找这些数据集的名字,当然是官网喽。
不如我们要找节点分类的数据集有哪些:
https://ogb.stanford.edu/docs/nodeprop/#dgl
如下,这些name表示我们都可以用。
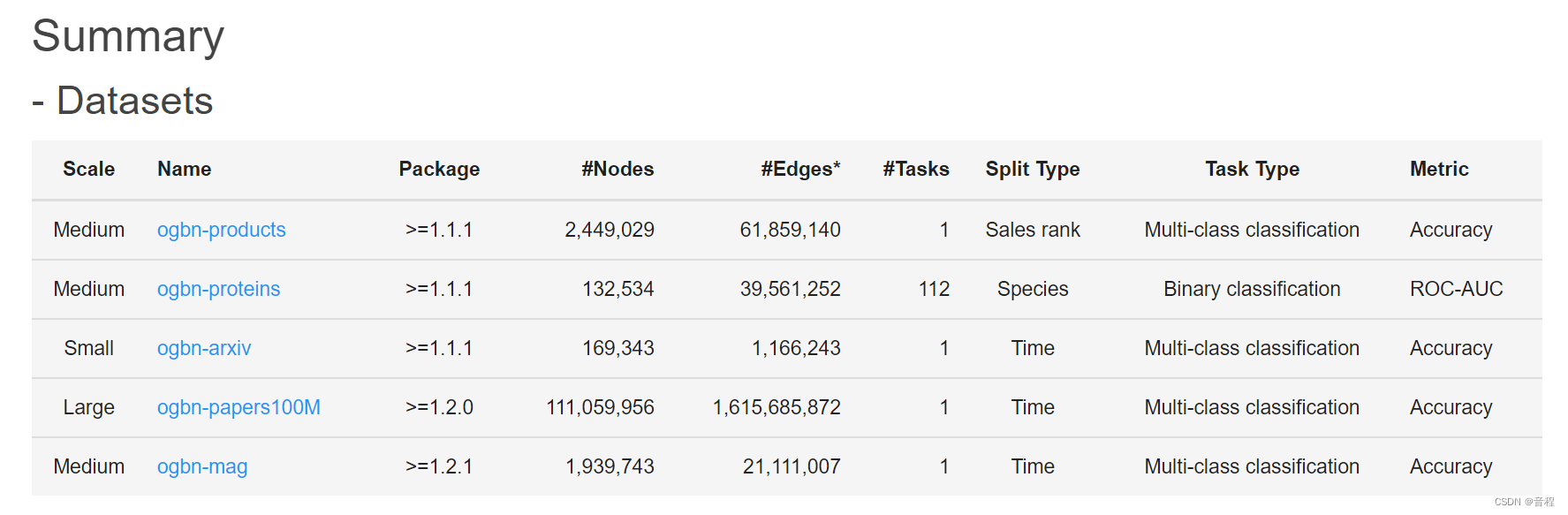
以下是一个简单的例子,展示了如何加载并使用 OGB 数据集进行节点分类任务:
from ogb.nodeproppred import NodePropPredDataset
import torch
# 加载数据集
dataset = NodePropPredDataset(name='ogbn-arxiv')
# 获取图数据和标签
graph, labels = dataset[0] # graph: 图结构;labels: 节点标签
# 获取训练/验证/测试集索引
split_idx = dataset.get_idx_split()
train_idx, valid_idx, test_idx = split_idx["train"], split_idx["valid"], split_idx["test"]
# 示例:打印一些基本信息
print('Number of nodes:', graph['num_nodes'])
print('Number of edges:', len(graph['edge_index'][0]))
print('Number of features per node:', graph['node_feat'].shape[1])
print('Number of classes:', dataset.num_classes)
# 假设你有一个模型 model 并想要训练它
# 这里只是一个伪代码示例
model = ... # 定义你的模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(100):
model.train()
optimizer.zero_grad()
out = model(graph['node_feat'], graph['edge_index'])
loss = criterion(out[train_idx], labels[train_idx].squeeze(1))
loss.backward()
optimizer.step()

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)