2、动手学深度学习——线性神经网络:softmax回归的实现(从零实现+内置函数实现)
1、softmax回归
为了估计所有可能类别的条件概率,我们需要一个有多个输出的模型,每个类别对应一个输出。 为了解决线性模型的分类问题,我们需要和输出一样多的仿射函数(affine function)。 每个输出对应于它自己的仿射函数。 在我们的例子中,由于我们有4个特征和3个可能的输出类别, 我们将需要12个标量来表示权重(带下标的), 3个标量来表示偏置(带下标的)。 下面我们为每个输入计算三个未规范化的预测(logit): o 1 o_1 o1、 o 2 o_2 o2和 o 3 o_3 o3。
o 1 = x 1 w 11 + x 2 w 12 + x 3 w 13 + x 4 w 14 + b 1 , o 2 = x 1 w 21 + x 2 w 22 + x 3 w 23 + x 4 w 24 + b 2 , o 3 = x 1 w 31 + x 2 w 32 + x 3 w 33 + x 4 w 34 + b 3 . \begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{12} + x_3 w_{13} + x_4 w_{14} + b_1,\\ o_2 &= x_1 w_{21} + x_2 w_{22} + x_3 w_{23} + x_4 w_{24} + b_2,\\ o_3 &= x_1 w_{31} + x_2 w_{32} + x_3 w_{33} + x_4 w_{34} + b_3. \end{aligned} o1o2o3=x1w11+x2w12+x3w13+x4w14+b1,=x1w21+x2w22+x3w23+x4w24+b2,=x1w31+x2w32+x3w33+x4w34+b3.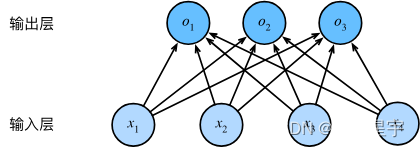
为了更简洁地表达模型,我们仍然使用线性代数符号。
通过向量形式表达为 o = W x + b \mathbf{o} = \mathbf{W} \mathbf{x} + \mathbf{b} o=Wx+b,
这是一种更适合数学和编写代码的形式。
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。
为了完成这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。如下式:
y ^ = s o f t m a x ( o ) 其中 y ^ j = exp ( o j ) ∑ k exp ( o k ) \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{其中}\quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)} y^=softmax(o)其中y^j=∑kexp(ok)exp(oj)
这里,对于所有的 j j j总有 0 ≤ y ^ j ≤ 1 0 \leq \hat{y}_j \leq 1 0≤y^j≤1。因此, y ^ \hat{\mathbf{y}} y^可以视为一个正确的概率分布。
softmax运算不会改变未规范化的预测 o \mathbf{o} o之间的大小次序,只会确定分配给每个类别的概率。因此,在预测过程中,我们仍然可以用下式来选择最有可能的类别。
argmax j y ^ j = argmax j o j . \operatorname*{argmax}_j \hat y_j = \operatorname*{argmax}_j o_j. jargmaxy^j=jargmaxoj.
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。
因此,softmax回归是一个线性模型(linear model)。
参考文章:3.4. softmax回归
2、softmax回归的从零开始实现
1. 获取数据集
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256 # 256为一批数据集
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 获取MNIST图像分类数据集
2. 初始化模型参数
原始数据集中的每个样本都是28×28的图像。 本节将展平每个图像,把它们看作长度为784的向量。 在后面的章节中,我们将讨论能够利用图像空间结构的特征, 但现在我们暂时只把每个像素位置看作一个特征。
因为我们的数据集有10个类别,所以网络输出维度为10。 因此,权重将构成一个784×10的矩阵, 偏置将构成一个的1×10行向量。 与线性回归一样,我们将使用正态分布初始化我们的权重W,偏置初始化为0。
num_inputs = 784 # 规定w的行数
num_outputs = 10 # 规定w的列数
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True) # 生成w为784×10的正态分布数据
b = torch.zeros(num_outputs, requires_grad=True) # 生成b为1×10的元素为0的向量
3. 定义softmax操作
softmax函数给出了一个向量 y ^ \hat{\mathbf{y}} y^,我们可以将其视为“对给定任意输入 x \mathbf{x} x的每个类的条件概率”。例如, y ^ 1 \hat{y}_1 y^1= P ( y = 猫 ∣ x ) P(y=\text{猫} \mid \mathbf{x}) P(y=猫∣x)。
假设整个数据集 { X , Y } \{\mathbf{X}, \mathbf{Y}\} {X,Y}具有 n n n个样本,其中索引 i i i的样本由特征向量 x ( i ) \mathbf{x}^{(i)} x(i)和独热标签向量 y ( i ) \mathbf{y}^{(i)} y(i)组成。我们可以将估计值与实际值进行比较:
P ( Y ∣ X ) = ∏ i = 1 n P ( y ( i ) ∣ x ( i ) ) . P(\mathbf{Y} \mid \mathbf{X}) = \prod_{i=1}^n P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}). P(Y∣X)=i=1∏nP(y(i)∣x(i)).
根据最大似然估计,我们最大化 P ( Y ∣ X ) P(\mathbf{Y} \mid \mathbf{X}) P(Y∣X),相当于最小化负对数似然:
− log P ( Y ∣ X ) = ∑ i = 1 n − log P ( y ( i ) ∣ x ( i ) ) = ∑ i = 1 n l ( y ( i ) , y ^ ( i ) ) , -\log P(\mathbf{Y} \mid \mathbf{X}) = \sum_{i=1}^n -\log P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}) = \sum_{i=1}^n l(\mathbf{y}^{(i)}, \hat{\mathbf{y}}^{(i)}), −logP(Y∣X)=i=1∑n−logP(y(i)∣x(i))=i=1∑nl(y(i),y^(i)),
其中,对于任何标签 y \mathbf{y} y和模型预测 y ^ \hat{\mathbf{y}} y^,损失函数为:
l ( y , y ^ ) = − ∑ j = 1 q y j log y ^ j . l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j. l(y,y^)=−j=1∑qyjlogy^j.
由于所有 y ^ j \hat{y}_j y^j都是预测的概率,所以它们的对数永远不会大于 0 0 0。
因此,如果正确地预测实际标签,即如果实际标签 P ( y ∣ x ) = 1 P(\mathbf{y} \mid \mathbf{x})=1 P(y∣x)=1,则损失函数不能进一步最小化。注意,这往往是不可能的。例如,数据集中可能存在标签噪声(比如某些样本可能被误标),或输入特征没有足够的信息来完美地对每一个样本分类。
由于softmax和相关的损失函数很常见,因此我们需要更好地理解它的计算方式。利用softmax的定义,我们得到:
l ( y , y ^ ) = − ∑ j = 1 q y j log exp ( o j ) ∑ k = 1 q exp ( o k ) = ∑ j = 1 q y j log ∑ k = 1 q exp ( o k ) − ∑ j = 1 q y j o j = log ∑ k = 1 q exp ( o k ) − ∑ j = 1 q y j o j . \begin{aligned} l(\mathbf{y}, \hat{\mathbf{y}}) &= - \sum_{j=1}^q y_j \log \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)} \\ &= \sum_{j=1}^q y_j \log \sum_{k=1}^q \exp(o_k) - \sum_{j=1}^q y_j o_j\\ &= \log \sum_{k=1}^q \exp(o_k) - \sum_{j=1}^q y_j o_j. \end{aligned} l(y,y^)=−j=1∑qyjlog∑k=1qexp(ok)exp(oj)=j=1∑qyjlogk=1∑qexp(ok)−j=1∑qyjoj=logk=1∑qexp(ok)−j=1∑qyjoj.
考虑相对于任何未规范化的预测 o j o_j oj的导数,我们得到:
∂ o j l ( y , y ^ ) = exp ( o j ) ∑ k = 1 q exp ( o k ) − y j = s o f t m a x ( o ) j − y j . \partial_{o_j} l(\mathbf{y}, \hat{\mathbf{y}}) = \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)} - y_j = \mathrm{softmax}(\mathbf{o})_j - y_j. ∂ojl(y,y^)=∑k=1qexp(ok)exp(oj)−yj=softmax(o)j−yj.
换句话说,导数是我们softmax模型分配的概率与实际发生的情况(由独热标签向量表示)之间的差异。从这个意义上讲,这与我们在回归中看到的非常相似,其中梯度是观测值 y y y和估计值 y ^ \hat{y} y^之间的差异。
实现softmax由三个步骤组成:
- 对每个项求幂(使用
exp); - 对每一行求和(小批量中每个样本是一行),得到每个样本的规范化常数;
- 将每一行除以其规范化常数,确保结果的和为1。
在查看代码之前,我们回顾一下这个表达式:
s o f t m a x ( X ) i j = exp ( X i j ) ∑ k exp ( X i k ) . \mathrm{softmax}(\mathbf{X})_{ij} = \frac{\exp(\mathbf{X}_{ij})}{\sum_k \exp(\mathbf{X}_{ik})}. softmax(X)ij=∑kexp(Xik)exp(Xij).
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制,应用到每行的元素中
当调用sum运算符时,我们可以指定保持在原始张量的轴数,而不折叠求和的维度。 只求同一个轴上的元素,即同一列(轴0)让行向量相加或同一行(轴1)让列向量相加。
# 调用softmax示例
X = torch.normal(0, 1, (2, 5))
X_prob = softmax(X)
X_prob, X_prob.sum(1)
(tensor([[0.2968, 0.4115, 0.0945, 0.1603, 0.0368],
[0.2128, 0.5422, 0.0865, 0.1104, 0.0481]]),
tensor([1.0000, 1.0000]))
对于任何随机输入,我们将每个元素变成一个非负数。 此外,依据概率原理,每行总和为1。
注:虽然这在数学上看起来是正确的,但我们在代码实现中有点草率。 矩阵中的非常大或非常小的元素可能造成数值上溢或下溢,但我们没有采取措施来防止这点。
4. 定义模型
定义softmax操作后,我们可以实现softmax回归模型。 下面的代码定义了输入如何通过网络映射到输出。 注意,将数据传递到模型之前,我们使用reshape函数将每张原始图像展平为向量。
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
其中,将X的列变为与w的行相同,从而可正常实现矩阵乘法。
5. 定义损失函数
信息论的核心思想是量化数据中的信息内容。在信息论中,该数值被称为分布 P P P的熵(entropy)。可以通过以下方程得到:
H [ P ] = ∑ j − P ( j ) log P ( j ) . H[P] = \sum_j - P(j) \log P(j). H[P]=j∑−P(j)logP(j).
信息论的基本定理之一指出,为了对从分布 p p p中随机抽取的数据进行编码,我们至少需要 H [ P ] H[P] H[P]“纳特(nat)”对其进行编码。“纳特”相当于比特(bit),但是对数底为 e e e而不是2。因此,一个纳特是 1 log ( 2 ) ≈ 1.44 \frac{1}{\log(2)} \approx 1.44 log(2)1≈1.44比特。
我们规定,当某一事件发生的概率越大,它的确定性就会更强,熵值也会越小,那么就可以认为所具有的信息量就会越小。反之,如果一个事件发生的概率越小,它的确定性就会更小,熵值也会越大,那么它具有的信息量就会越大。
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
cross_entropy(y_hat, y)
# 输出内容
tensor([2.3026, 0.6931])
y_hat[range(len(y_hat)), y]:y_hat为预测每个样例中各个标签为真实标签的概率,y为每个样例中的真实标签。
(1)y_hat[ [0,1], [0, 2]]:代表选取y_hat中的第一个样本中的第一个样例和第二个样本中的第三个样例。
(2)y_hat[range(len(y_hat)), y]:代表选取真实样例在y_hat中发生的概率
# 调用示例
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y_hat[[0, 1], y]
tensor([0.1000, 0.5000])
5. 分类精度
当预测与标签分类y一致时,即是正确的。 分类精度即正确预测数量与总预测数量之比。 虽然直接优化精度可能很困难(因为精度的计算不可导), 但精度通常是我们最关心的性能衡量标准,我们在训练分类器时几乎总会关注它。
为了计算精度,我们执行以下操作。 首先,如果y_hat是矩阵,那么假定第二个维度存储每个类的预测分数。 我们使用argmax获得每行中最大元素的索引来获得预测类别。 然后我们将预测类别与真实y元素进行比较。 由于等式运算符“==”对数据类型很敏感, 因此我们将y_hat的数据类型转换为与y的数据类型一致。 结果是一个包含0(错)和1(对)的张量。 最后,我们求和会得到正确预测的数量。
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # 当数据规格为多样本多样例时
y_hat = y_hat.argmax(axis=1) # 选取每个样本中概率最大的样例
cmp = y_hat.type(y.dtype) == y # 将y_hat转化为与y相同的类型,然后比较预测是否正确
return float(cmp.type(y.dtype).sum()) # 返回预测正确的个数
accuracy(y_hat, y) / len(y) # 输出精度
对于任意数据迭代器data_iter可访问的数据集, 我们可以评估在任意模型net的精度。
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module): # 判定net是否为神经网络模型
net.eval() # 若为神经网络模型,则将模型设置为评估模式,不计算梯度
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter: # 从data_iter数据集中获取X和真实标签y
metric.add(accuracy(net(X), y), y.numel()) # 上述已经设置data_iter是256为一批,每256个数据计算一次预测情况
return metric[0] / metric[1]
这里定义一个实用程序类Accumulator,用于对多个变量进行累加。 在上面的evaluate_accuracy函数中, 我们在Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量。 当我们遍历数据集时,两者都将随着时间的推移而累加。
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
# 因为args传入的为两列数据(正确预测数,预测总数),因此for循环的第一轮迭代会加上正确预测数,第二轮迭代会加上预测总数
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
# data[0]:预测正确总数,data[1]:预测总数
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
调用示例
evaluate_accuracy(net, test_iter)
0.0598
由于我们使用随机权重初始化net模型, 因此该模型的精度应接近于随机猜测。 例如在有10个类别情况下的精度为0.1。
6. 训练
在这里,我们重构训练过程的实现以使其可重复使用。 首先,我们定义一个函数来训练一个迭代周期。 请注意,updater是更新模型参数的常用函数,它接受批量大小作为参数。 它可以是d2l.sgd函数,也可以是框架的内置优化函数。
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module): # 若为神经网络模型则设置为训练模式
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad() # 计算梯度前先清0
l.mean().backward() # 计算l的均值再反向传播计算梯度
updater.step() # 更新模型参数
else:
# 使用定制的优化器和损失函数
l.sum().backward() # 计算l求和再反向传播计算梯度
updater(X.shape[0]) # 根据X的样本数更新模型参数
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
在展示训练函数的实现之前,我们定义一个在动画中绘制数据的实用程序类Animator, 它能够简化本书其余部分的代码。
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
该训练函数将会运行多个迭代周期(由num_epochs指定)。 在每个迭代周期结束时,利用test_iter访问到的测试数据集对模型进行评估。 我们将利用Animator类来可视化训练进度。
训练函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter) # 测试精度
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics # 训练损失和训练精度
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
优化算法
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
现在,我们训练模型10个迭代周期。 请注意,迭代周期(num_epochs)和学习率(lr)都是可调节的超参数。 通过更改它们的值,我们可以提高模型的分类精度。
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
7. 预测
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)
* 完整代码
import torch
from IPython import display
from d2l import torch as d2l
# 获取数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
# 定义softmax操作
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制
# 定义模型
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
# 定义损失函数
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
# 分类精度
## 获取正确预测个数
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
## 评估精度:预测个数/预测总数
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
## 累积数类
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 训练
## 训练函数
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
## 绘图类
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
## 多批次读取数据训练并绘图
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
## 设置优化算法
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
## 训练模型
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
# 预测
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)
3、softmax回归的简洁实现
导入包
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
1. 初始化模型参数
softmax回归的输出层是一个全连接层,为了实现我们的模型, 我们只需在Sequential中添加一个带有10个输出的全连接层。 尽管,在这里使用Sequential并不是必要的, 但它是实现深度模型的基础。 我们仍然以均值0和标准差0.01随机初始化权重。
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m): # 初始化权重
if type(m) == nn.Linear: # 若输入的m属于神经网络线性层,则初始化为均值为m.weight,方差为0.01的数据
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
nn.Flatten():nn.Flatten()是PyTorch中的一个网络层,它用于保持第0维不变的情况下,将输入的多维数据展平为一维数据。在神经网络中,通常使用全连接层(Fully Connected Layer)来进行分类或回归任务,而全连接层的输入必须是一维数据。因此,当输入的数据是多维的时候,需要使用Flatten层将其展平。
例如,如果输入数据的形状为[batch_size, channels, height, width],其中batch_size表示批量大小,channels表示通道数,height表示高度,width表示宽度。那么经过Flatten层后,数据的形状将变为[batch_size, channels * height * width],即将多维数据展平为一维数据。
2. softmax模型和损失函数
在前面的例子中,我们计算了模型的输出,然后将此输出送入交叉熵损失。从数学上讲,这是一件完全合理的事情。然而,从计算角度来看,指数可能会造成数值稳定性问题。
回想一下,softmax函数 y ^ j = exp ( o j ) ∑ k exp ( o k ) \hat y_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)} y^j=∑kexp(ok)exp(oj) ,其中 y ^ j \hat y_j y^j 是预测的概率分布。 o j o_j oj是未规范化的预测 o \mathbf{o} o的第 j j j个元素。
如果 o k o_k ok中的一些数值非常大,那么 exp ( o k ) \exp(o_k) exp(ok) 可能大于数据类型容许的最大数字,即上溢(overflow)。这将使分母或分子变为inf(无穷大),最后得到的是0、inf或nan(不是数字)的 y ^ j \hat y_j y^j。在这些情况下,我们无法得到一个明确定义的交叉熵值。
解决这个问题的一个技巧是:在继续softmax计算之前,先从所有 o k o_k ok中减去 max ( o k ) \max(o_k) max(ok)。这里可以看到每个 o k o_k ok按常数进行的移动不会改变softmax的返回值:
y ^ j = exp ( o j − max ( o k ) ) exp ( max ( o k ) ) ∑ k exp ( o k − max ( o k ) ) exp ( max ( o k ) ) = exp ( o j − max ( o k ) ) ∑ k exp ( o k − max ( o k ) ) . \begin{aligned} \hat y_j & = \frac{\exp(o_j - \max(o_k))\exp(\max(o_k))}{\sum_k \exp(o_k - \max(o_k))\exp(\max(o_k))} \\ & = \frac{\exp(o_j - \max(o_k))}{\sum_k \exp(o_k - \max(o_k))}. \end{aligned} y^j=∑kexp(ok−max(ok))exp(max(ok))exp(oj−max(ok))exp(max(ok))=∑kexp(ok−max(ok))exp(oj−max(ok)).
在减法和规范化步骤之后,可能有些 o j − max ( o k ) o_j - \max(o_k) oj−max(ok)具有较大的负值。由于精度受限, exp ( o j − max ( o k ) ) \exp(o_j - \max(o_k)) exp(oj−max(ok))将有接近零的值,即下溢(underflow)。这些值可能会四舍五入为零,使 y ^ j \hat y_j y^j 为零,并且使得 log ( y ^ j ) \log(\hat y_j) log(y^j) 的值为-inf。反向传播几步后,我们可能会发现自己面对一屏幕可怕的nan结果。
尽管我们要计算指数函数,但我们最终在计算交叉熵损失时会取它们的对数。通过将softmax和交叉熵结合在一起,可以避免反向传播过程中可能会困扰我们的数值稳定性问题。如下面的等式所示,我们避免计算 exp ( o j − max ( o k ) ) \exp(o_j - \max(o_k)) exp(oj−max(ok)),而可以直接使用 o j − max ( o k ) o_j - \max(o_k) oj−max(ok),因为 log ( exp ( ⋅ ) ) \log(\exp(\cdot)) log(exp(⋅)) 被抵消了(log之后数值就不会过小)。
log ( y ^ j ) = log ( exp ( o j − max ( o k ) ) ∑ k exp ( o k − max ( o k ) ) ) = log ( exp ( o j − max ( o k ) ) ) − log ( ∑ k exp ( o k − max ( o k ) ) ) = o j − max ( o k ) − log ( ∑ k exp ( o k − max ( o k ) ) ) . \begin{aligned} \log{(\hat y_j)} & = \log\left( \frac{\exp(o_j - \max(o_k))}{\sum_k \exp(o_k - \max(o_k))}\right) \\ & = \log{(\exp(o_j - \max(o_k)))}-\log{\left( \sum_k \exp(o_k - \max(o_k)) \right)} \\ & = o_j - \max(o_k) -\log{\left( \sum_k \exp(o_k - \max(o_k)) \right)}. \end{aligned} log(y^j)=log(∑kexp(ok−max(ok))exp(oj−max(ok)))=log(exp(oj−max(ok)))−log(k∑exp(ok−max(ok)))=oj−max(ok)−log(k∑exp(ok−max(ok))).
我们也希望保留传统的softmax函数,以备我们需要评估通过模型输出的概率。但是,我们没有将softmax概率传递到损失函数中,而是在交叉熵损失函数中传递未规范化的预测,并同时计算softmax及其对数,这是一种类似"LogSumExp技巧"的聪明方式。
loss = nn.CrossEntropyLoss(reduction='none')
reduction参数被设置为’none’,表示不进行降维操作,即返回每个样本的损失值而不是对所有样本的损失值进行平均或求和。这意味着返回的损失值是一个与输入数据大小相同的张量,每个元素对应一个样本的损失值。
注:会在CrossEntropyLoss进行Softmax并减去最大,再进行log操作。
3. 优化算法
在这里,我们使用学习率为0.1的小批量随机梯度下降作为优化算法。 这与我们在线性回归例子中的相同,这说明了优化器的普适性。
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
4. 训练
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
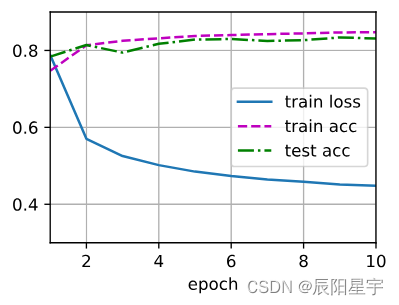
* 完整代码
import torch
from torch import nn
from d2l import torch as d2l
# 获取数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 设置训练模型
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 设置损失函数
loss = nn.CrossEntropyLoss(reduce='none')
# 设置优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.4)
# 进行训练
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
参考文章:3.7. softmax回归的简洁实现

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)