hadoop3入门(3)
hdfs简介
hdfs他是一个文件系统,用于存储文件,通过目录树来定位文件,他是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色
hdfs的使用场景:适合一次写入,多次读出的场景,一个文件经过创建,写入,关闭之后就不需要改变
hdfs的优点:
1.高容错性:数据自动保存多个副本,他通过增加副本的形式,提供容错性,某一个副本丢失以后,可以自动恢复
2.适合处理大数据
hdfs的缺点:
1.不适合低延时数据访问,比如说毫秒级的存储数据,是做不到的
2.无法高效的对大量小文件进行存储,存储大量小文件,会占用NameNode大量的内存来存储文件目录和块信息,这样是不可取的,因为NameNode的内存总数有限的,小文件存储的寻址时间会超过读取时间
3.不支持并发写入,文件随机修改,一个文件只能有一个写,不允许多个线程同时写,仅支持数据追加
NameNode(nn):就是Master,他是一个主管,管理者
1:管理hdfs的名称空间
2:配置副本策略
3:管理数据块(Block)映射信息
4:处理客户端读写请求
DataNode:就是Slave
NameNode下达命令,DataNode执行实际的操作
1.存储实际的数据块
2.执行数据块的读写操作
client:就是客户端
1.文件切分,文件上传hdfs的时候,client将文件切分成一个一个的block,然后进行上传
2.与NameNode交互,获取文件的位置信息
3.与DataNode交互,读取或者写入数据
4.client提供一些命令来管理hdfs,比如NameNode格式化
5.client可以通过一些命令来访问hdfs,比如对hdfs增删改操作
SecondaryNameNode:并非NameNode的热备,当NameNode挂掉的时候,他并不能马上替换NameNode并提供服务
1.辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
2.在紧急情况下,可以辅助回复NameNode
hdfs中的文件在物理上是分块存储,块的大小可通过配置参数dfs.blocksize来设置,默认为128M
hdfs的shell命令
创建文件夹
前面必须加/
hadoop fs -mkdir /aa

剪切本地文件到hdfs
在本地创建一个bb.txt,内容自定义
vi bb.txt
bb.txt的内容
aaaaaaaaaaaa
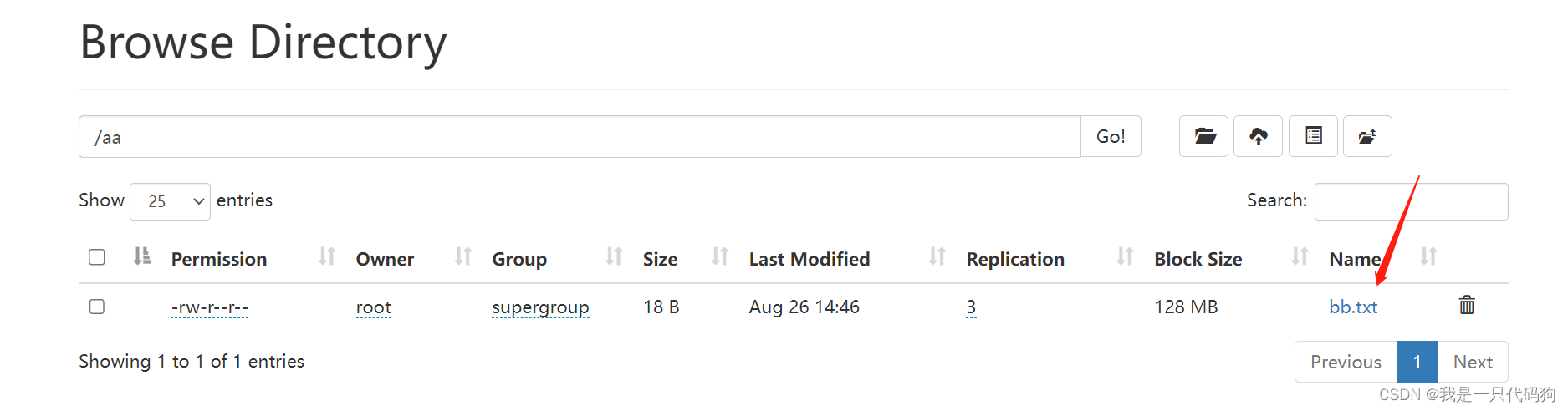
把本地的bb.txt放入到hdfs中aa文件夹中,并自动删除bb.txt
hadoop fs -moveFromLocal bb.txt /aa
拷贝本地文件到hdfs
把本地的cc.txt文件放入到hdfs中aa文件夹中,不会删除本地的cc.txt
hadoop fs -copyFromLocal cc.txt /aa
或者使用-put也是把cc.txt拷贝到hdfs的/aa文件夹下
hadoop fs -put cc.txt /aa
追加存在的文件到末尾
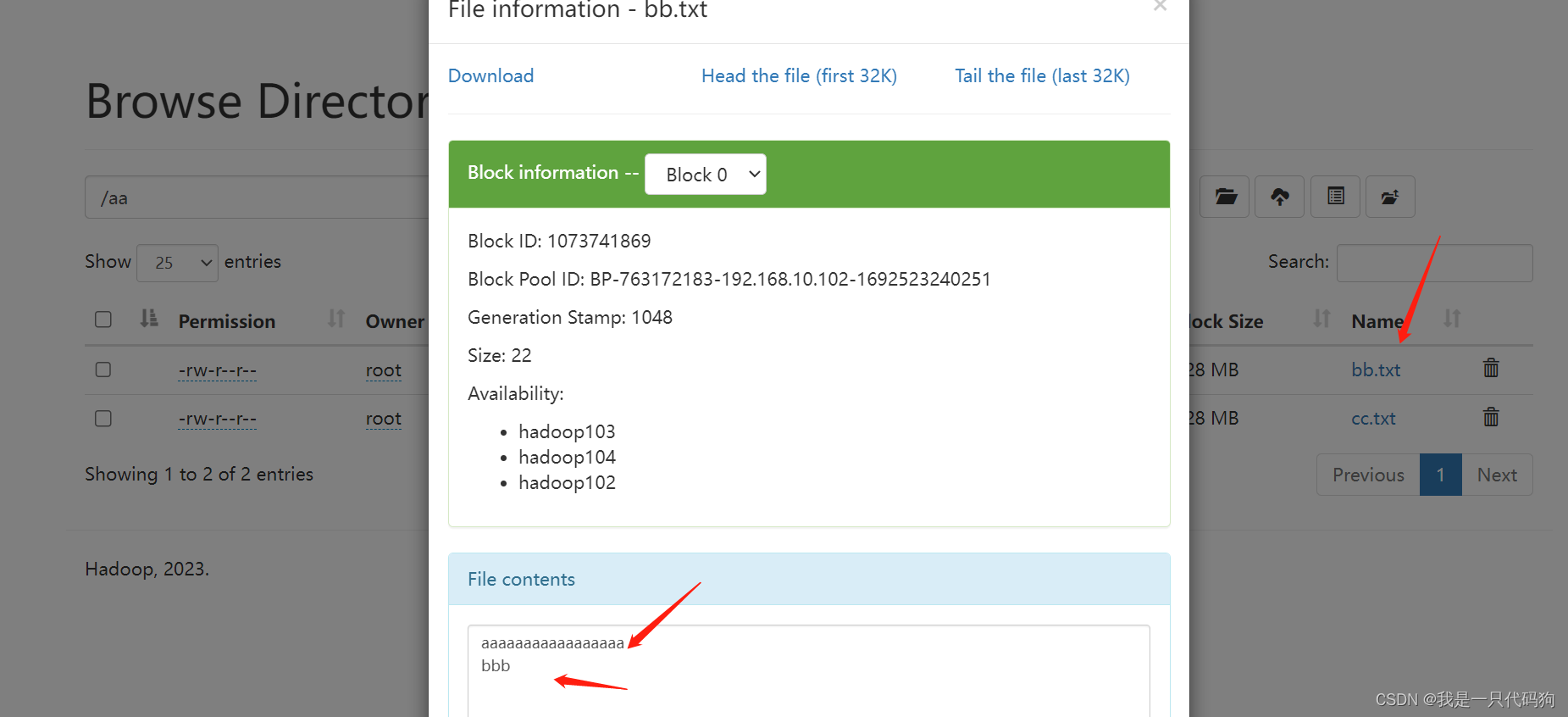
把本地cc.txt追加到,hdfs中aa文件夹下的bb.txt中
hadoop fs -appendToFile cc.txt /aa/bb.txt
 从hdfs下载到本地
从hdfs下载到本地
把aa文件夹下载下来
hadoop fs -get /aa

显示目录信息
hadoop fs -ls /aa
显示文件内容
hadoop fs -cat /aa/bb.txt
拷贝文件夹的内容到另一个文件夹
前提是先把bb文件夹在hdfs创建好
hadoop fs -cp /aa/bb.txt /dd
移动文件到另一个文件夹下
hadoop fs -mv /aa/cc.txt /dd
显示文件末尾的数据
hadoop fs -tail /aa/bb.txt
删除文件
hadoop fs -rm /aa/bb.txt
递归删除所有文件
hadoop fs -rm -r /dd
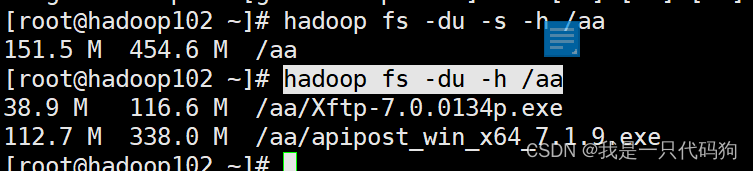
统计文件夹的大小信息
hadoop fs -du -s -h /aa
hadoop fs -du -h /aa
151.5m表示文件的大小,454.6m表示有3个副本,151.5*3
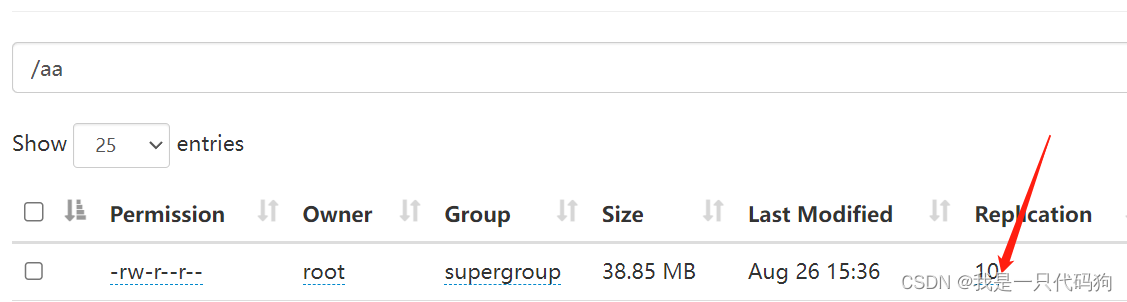
设置文件的副本数量为10
hadoop fs -setrep 10 /aa/bb.txt
hdfs的Api操作
配置环境变量,使得java代码能够访问linux环境
下载代码到windows
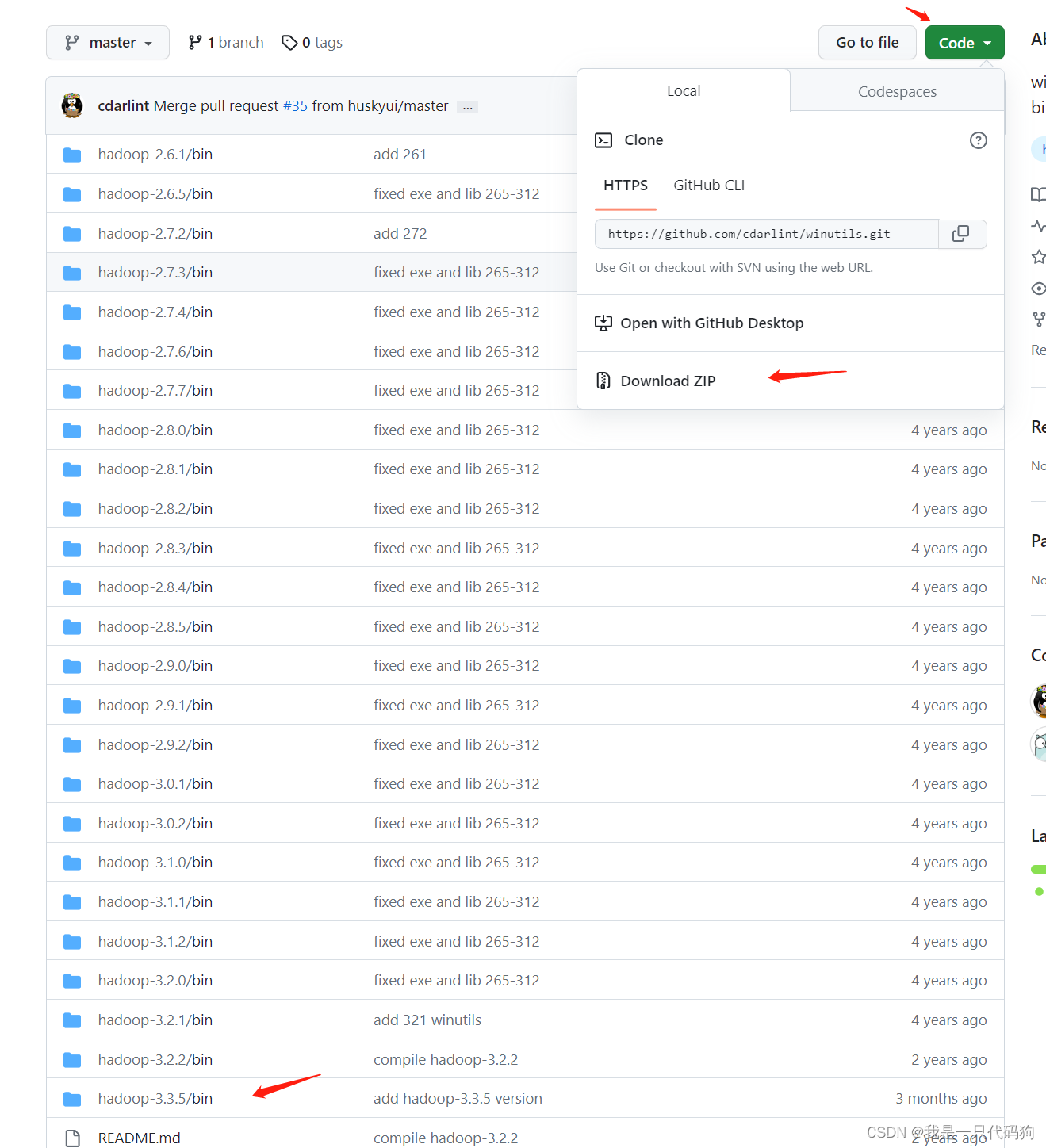
然后配置环境变量
HADOOP_HOME
F:\winutils-master\winutils-master\hadoop-3.3.5
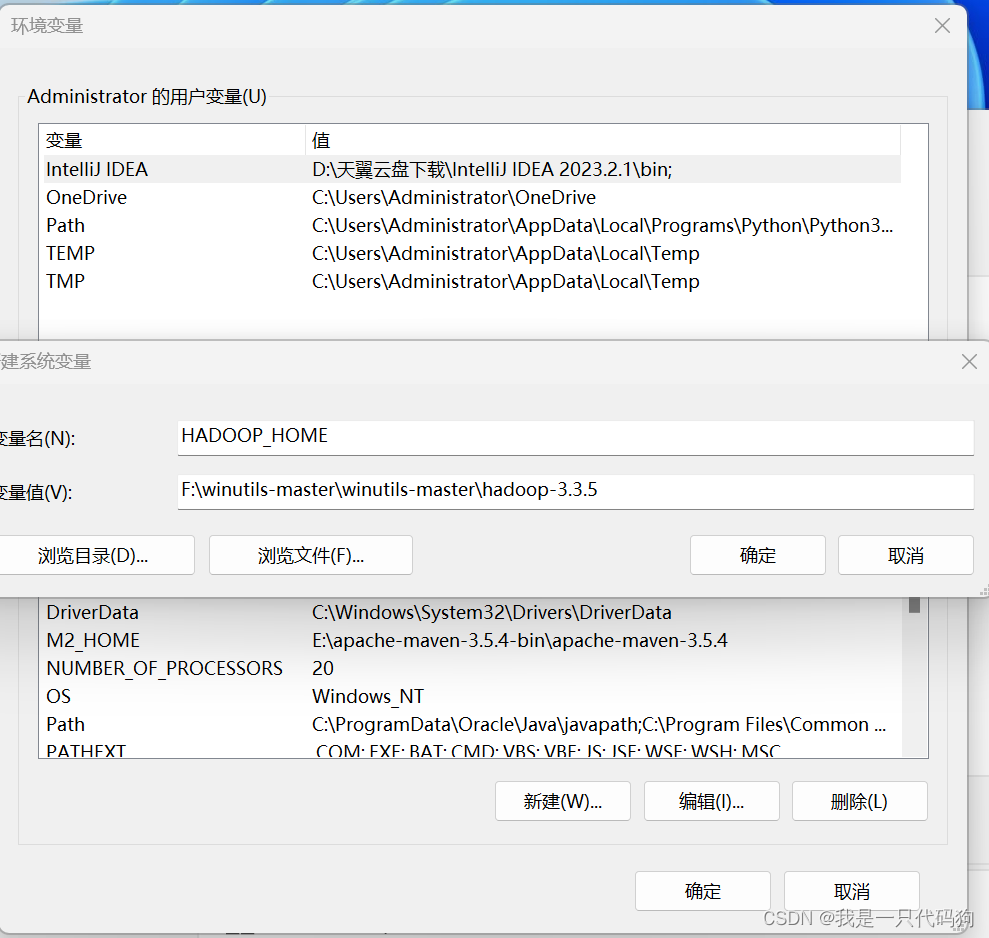
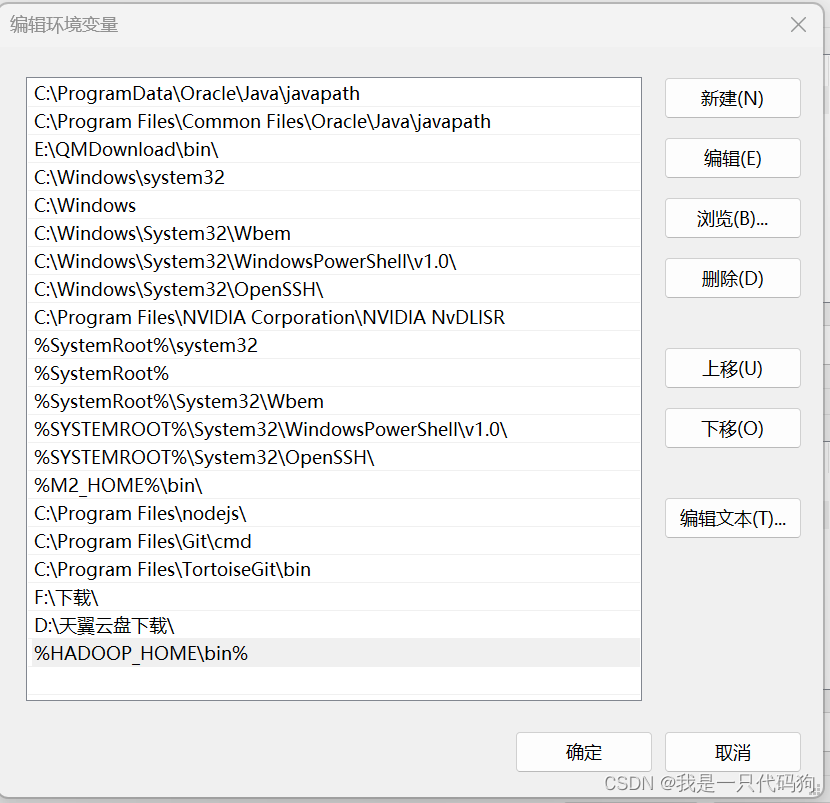
配置path变量
%HADOOP_HOME%\bin
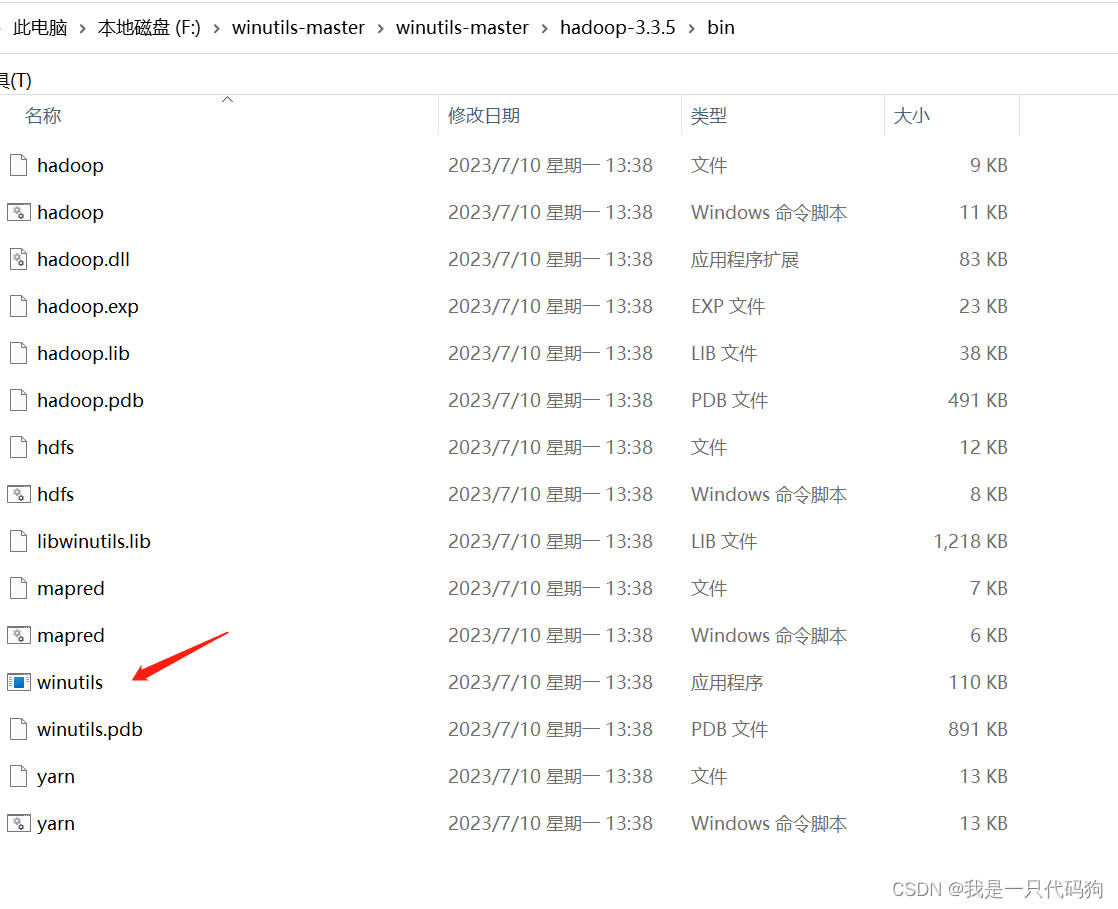
然后双击winutils.exe
springboot整合hdfs
pom.xml引入
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
设置hdfs配置类
package com.example.demo.config;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* hdfs配置类
*/
@org.springframework.context.annotation.Configuration
public class HdfsConfig {
//获取hdfs的文件系统
@Bean
public FileSystem fs(){
//获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = null;
try {
//配置连接地址和端口 以及账号
fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration,"root");
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (URISyntaxException e) {
throw new RuntimeException(e);
}
return fs;
}
}
创建文件夹
package com.example.demo.controller;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
public class TestController {
@Autowired
private FileSystem fs;
/**
* 创建cc文件夹 到hdfs中
* @return
* @throws IOException
*/
@GetMapping("/mkdirs")
public String mkdirs() throws IOException {
fs.mkdirs(new Path("/cc"));
return "success";
}
}
其他命令
package com.example.demo.controller;
import org.apache.hadoop.fs.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.lang.reflect.Array;
import java.util.Arrays;
@RestController
public class TestController {
@Autowired
private FileSystem fs;
/**
* 创建cc文件夹 到hdfs中
* @return
* @throws IOException
*/
@GetMapping("/mkdirs")
public String mkdirs() throws IOException {
fs.mkdirs(new Path("/cc"));
return "success";
}
/**
* 上传本地文件到hdfs的aa文件夹下
* @return
* @throws IOException
*/
@GetMapping("/copyFromLocalFile")
public String copyFromLocalFile() throws IOException {
fs.copyFromLocalFile(new Path("F:/abc.txt"),new Path("/aa/"));
return "success";
}
/**
* 重命名
* @return
* @throws IOException
*/
@GetMapping("/rename")
public String rename() throws IOException {
//把hdfs的abc.txt文件改成666.txt
fs.rename(new Path("/aa/abc.txt"),new Path("/aa/666.txt"));
return "success";
}
/**
* 删除文件
* @return
* @throws IOException
*/
@GetMapping("/delete")
public String delete() throws IOException {
//把hdfs的文件删除 如果是true 递归删除,false 只能删除单个文件
fs.delete(new Path("/cc/aa.txt"),false);
return "success";
}
/**
* 查看hdfs的文件信息
* @return
* @throws IOException
*/
@GetMapping("/listFiles")
public String listFiles() throws IOException {
//true 表示递归
RemoteIterator<LocatedFileStatus> list = fs.listFiles(new Path("/"), true);
while (list.hasNext()) {
LocatedFileStatus next = list.next();
// Permission Owner Group Size Last Modified Replication Block Size Name
System.out.println("=========路径信息"+next.getPath()+"===============");
System.out.println("权限信息:"+next.getPermission());
System.out.println("操作人:"+next.getOwner());
System.out.println("分组:"+next.getGroup());
System.out.println("文件大小:"+next.getLen());
System.out.println("修改时间:"+next.getModificationTime());
System.out.println("副本数:"+next.getReplication());
System.out.println("块大小:"+next.getBlockSize());
System.out.println("文件名称:"+next.getPath().getName());
//获取块信息
System.out.println("--------------------");
BlockLocation[] blockLocations = next.getBlockLocations();
System.out.println("块信息:"+ Arrays.toString(blockLocations));
}
return "success";
}
/**
* 文件和文件夹的判断
* @return
* @throws IOException
*/
@GetMapping("/listStatus")
public String listStatus() throws IOException {
//判断这个文件夹下的内容 是文件还是文件夹
FileStatus[] fileStatuses = fs.listStatus(new Path("/cc"));
for (FileStatus x : fileStatuses) {
if(x.isFile()){
System.out.println(x.getPath().getName()+"是文件");
}else {
System.out.println(x.getPath().getName()+"是文件夹");
}
}
return "success";
}
}

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)