【学习笔记】手写神经网络之word2vec
本章是对于深度学习中一些库的手写实现,我个人认为这一块是最重要的,因为我认为如果仅仅只是知道深度学习某些结构的原理而不去动手实现,并不能很好的理解深度学习,也不能体会到其中的精髓,因此,在这一章中我会花费大量时间去尽量实现一些常用的库或结构方法。本篇博客就是对word2vec的手写实现和理解。如有错误欢迎指出。例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了
系列文章目录
【第一章原理】【学习笔记】机器学习基础--线性回归_一无是处le的博客-CSDN博客
【第一章代码解释】 【线性回归】原生numpy实现波士顿房价预测_一无是处le的博客-CSDN博客
【第二章】 【学习笔记】机器学习基础--逻辑回归_一无是处le的博客-CSDN博客
【第三章】传统机器学习【先不写】
【第四章】聚类算法【先不写】
【第五章原理】【学习笔记】深度学习基础----DNN_一无是处le的博客-CSDN博客
目录
前言
本章是对于深度学习中一些库的手写实现,我个人认为这一块是最重要的,因为我认为如果仅仅只是知道深度学习某些结构的原理而不去动手实现,并不能很好的理解深度学习,也不能体会到其中的精髓,因此,在这一章中我会花费大量时间去尽量实现一些常用的库或结构方法。本篇博客就是对word2vec的手写实现和理解。如有错误欢迎指出。
一、word2vec是什么?
word2vec,其全称为word to vector,顾名思义,就是将单词(文本)转化成向量。这是nlp中不可或缺的一步,而word2vec是其中很常用的一种方法。正是因为有这一个步骤的存在,才让nlp领域发展的比cv或者语音领域慢,因为无论是图像还是声音,都早早的就有了一个存储的标准,例如图像的RGB等这些就是大家公认的存储方式,而计算机也早已能够通过人定的存储标准去识别这些图片和声音,但是文字和这两者不同,文字自从诞生起就是人类文化的延申,他仅仅能被我们人类自己理解,计算机无法去理解识别文字,因此该怎样让计算机能够识别文字,就成了一个很大的难题,这也导致nlp迟迟不能快速发展。而本章就是完全手写来实现,理解word2vec。
二、word2vec原理
在实现word2vec之前,我们需要先了解以下word2vec的工作原理。word2vec分为两种工作模式:CBOW和skip-gram两种模式。其中CBOW是通过上下文来预测中心词,而skipgram是通过中心词来预测上下文。两种方式各有优劣,总的来说CBOW适合训练文本短且不需要太强的语义理解,适合常用的文字,因此我们这里展示的word2vec方法是CBOW,如果你想实现skip-gram也可以自己跟着原理稍微改一下代码。
1.CBOW
其工作方式如下图所示:
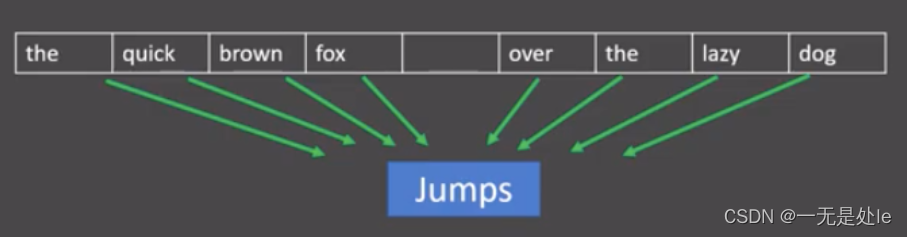
工作原理如下图所示:
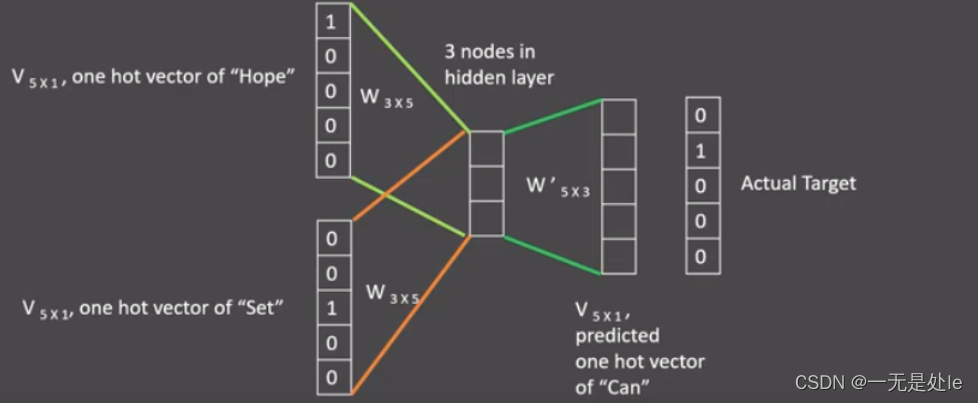
从上面两张图我们就可以很直观的明白CBOW的工作方式和原理:CBOW会先创建一个可以在文本数据中滑动的窗口,先将窗口中的上下文信息(包括中心预测词)进行one-hot编码【注意这里是只将窗口中的文本信息进行one-hot编码而非所有的训练文本,因为这样能够大幅度减少模型训练的参数,能大大加快训练速度并且不会损失太多的文本信息之间的关联】,之后将窗口中的上下文文本通过全连接求和得到一个稠密向量【
先通过全连接将上下文信息从one-hot这种稀疏的向量转化成稠密向量,再将得到的所有上下文进行求和】,这个稠密向量就可以看作是中心词的预测向量,此时可以通过softmax层连接起来,相当于做一个分类任务,然后进行反向传播不断减少损失得到最佳的参数矩阵,此时窗口中的中心词的稠密向量就是我们需要的文本向量。
2.skip-gram
其工作方式如下图所示:
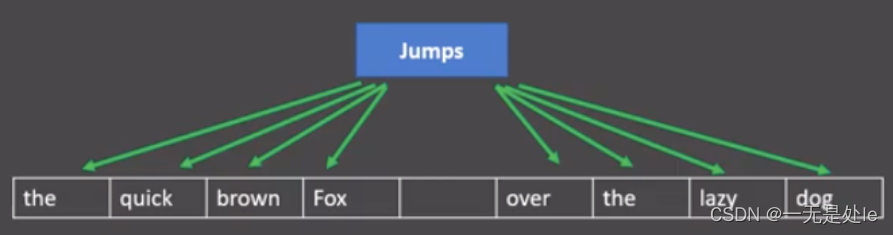
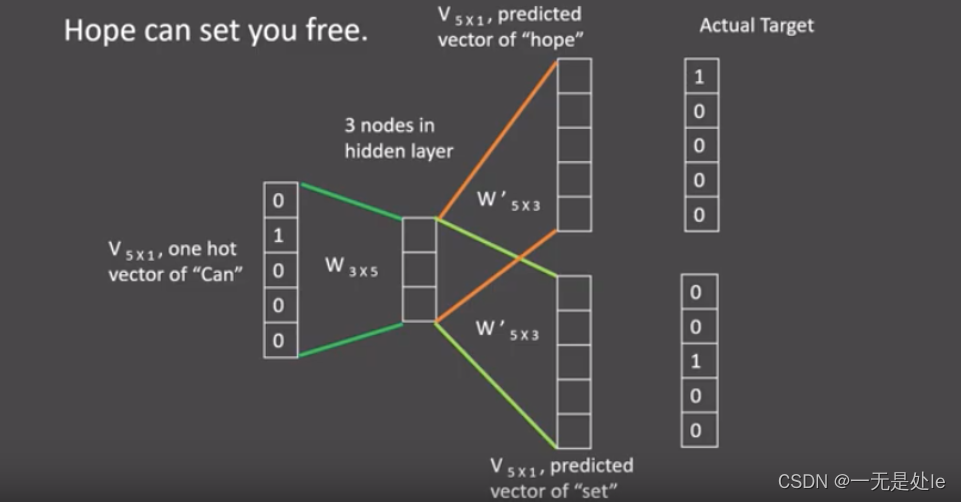
其工作原理如下图所示:(由于其原理本质跟上面的CBOW类似,因此这里不多赘述)
三、代码实现
1.引入库
由于我们需要手写实现,因此肯定不能调用相关的包,这里我们只调用numpy和jieba。
import numpy as np
import jieba
2.CBOW前向传播
代码如下(示例):
def word2vec(words, windows_size):
length = len(words)
n = windows_size * 2 + 1
# 词袋one_hot编码
bag = np.eye(n)
# 储存所有词向量
word_dict = {}
lr = 0.01
epochs = 1001
for i, word in enumerate(words):
# 初始化稠密向量的权重(这里为了去头尾我不加bias)
w_linear = [np.random.randn(n, 20) if (j + i) >= windows_size and (j + i - 1) <= length else np.zeros((n, 20))
for j in range(windows_size * 2)]
# 初始化全连接层的权重矩阵和bias
w_softmax = np.random.randn(20, n)
b_softmax = np.random.randn(1)
# x
temp_bag = [bag[x] for x in range(n) if x != windows_size]
# y
target = bag[windows_size]
for epoch in range(epochs):
# 词向量加权求和 output_linear
hidden_temp = sum(np.dot(temp_bag[j], w_linear[j]) for j in range(windows_size * 2))
# 全连接 z
z = np.dot(hidden_temp, w_softmax) + b_softmax
# softmax激活 p
result = np.exp(z) / np.sum(np.exp(z))
# 计算损失(这里使用的交叉熵)
loss = -(np.dot(target, np.log(result).T) + np.dot(np.ones_like(target) - target,np.log(np.ones_like(result) - result).T)) / n其实这里不好理解的就只有result和loss的计算,事实上只要知道了计算公式就好理解了:
softmax:
loss: (y是真实值,p是预测值)
3.CBOW反向传播
这一部分才是重中之重,也是神经网络的精髓所在,代码示例如下:
def back_ward(x, output_linear, p, y):
n = len(y)
dL_dp = -(y / p + (np.ones_like(y) - y) / (np.ones_like(p) - p)) / n
dp_dz = p * (np.ones_like(p) - p)
dz_dw_softmax = output_linear
dz_dw_linear = x
dL_dz = dL_dp * dp_dz
dL_dw_softmax = np.outer(dz_dw_softmax, dL_dz)
dL_dw_linear = sum([np.outer(i, np.dot(dL_dz, dL_dw_softmax.T)) for i in dz_dw_linear])
dL_db_softmax = np.sum(dL_dz)
return dL_dw_softmax, dL_dw_linear, dL_db_softmax这一部分事实上不需要注释,全都是关于公式的计算,直接看代码肯定是很难看懂的,因此我们需要先对公式进行解析。我们目前的网络结构为一层线性全连接层,一层softmax全连接层,因此我们的梯度计算可以分为:
因为我们需要的仅仅是该神经网络中的两个层的权重参数矩阵,并且由于我们进行的是CBOW,上下文词预测中心词,这样就会在linear层那里有一个多个x对应一个 out,因此我们需要在计算dL_dw_linear时进行相加处理,不然会让矩阵的大小对不上。
四、完整代码
完整代码如下:
import numpy as np
import jieba
def softmax(vector):
return np.exp(vector) / np.sum(np.exp(vector))
def cross_entropy(n, inp, target):
result = -(np.dot(target, np.log(inp).T) + np.dot(np.ones_like(target) - target,
np.log(np.ones_like(inp) - inp).T)) / n
return result
# 这里的反向传播函数(微分)仅仅适用于cross_entropy(本项目中的函数)
def back_ward(x, output_linear, p, y):
n = len(y)
dL_dp = -(y / p + (np.ones_like(y) - y) / (np.ones_like(p) - p)) / n
dp_dz = p * (np.ones_like(p) - p)
dz_dw_softmax = output_linear
dz_dw_linear = x
dL_dz = dL_dp * dp_dz
dL_dw_softmax = np.outer(dz_dw_softmax, dL_dz)
dL_dw_linear = sum([np.outer(i, np.dot(dL_dz, dL_dw_softmax.T)) for i in dz_dw_linear])
dL_db_softmax = np.sum(dL_dz)
return dL_dw_softmax, dL_dw_linear, dL_db_softmax
def word2vec(words, windows_size):
length = len(words)
n = windows_size * 2 + 1
# 词袋one_hot编码
bag = np.eye(n)
sum_loss = 0
# 储存所有词向量
word_dict = {}
lr = 0.01
epochs = 1001
for i, word in enumerate(words):
temp_sum_loss = 0
# 打乱bag
# np.random.shuffle(bag)
# 初始化稠密向量的权重(这里为了去头尾我不加bias)
w_linear = [np.random.randn(n, 20) if (j + i) >= windows_size and (j + i - 1) <= length else np.zeros((n, 20))
for j in range(windows_size * 2)]
# 初始化全连接层的权重矩阵和bias
w_softmax = np.random.randn(20, n)
b_softmax = np.random.randn(1)
# x
temp_bag = [bag[x] for x in range(n) if x != windows_size]
# y
target = bag[windows_size]
for epoch in range(epochs):
# 词向量加权求和 output_linear
hidden_temp = sum(np.dot(temp_bag[j], w_linear[j]) for j in range(windows_size * 2))
# 全连接 z
z = np.dot(hidden_temp, w_softmax) + b_softmax
# 激活 p
result = softmax(z)
loss = cross_entropy(n, inp=result, target=target)
temp_sum_loss += loss
# 进行反向传播
dL_dw_softmax, dL_dw_linear, dL_db_softmax = back_ward(x=temp_bag, y=target, output_linear=hidden_temp, p=result)
# 更新参数
w_softmax -= lr * dL_dw_softmax
b_softmax -= lr * dL_db_softmax
w_linear -= lr * dL_dw_linear
sum_loss += temp_sum_loss / epochs
print("当前单词: {} 的损失为: {}".format(word, temp_sum_loss / epochs))
vector = sum(np.dot(temp_bag[j], w_linear[j]) for j in range(windows_size * 2))
# 将vector放入字典
if word in word_dict:
word_dict[word] = (word_dict[word] + vector) / 2
else:
word_dict[word] = vector
return (sum_loss / length), word_dict
words = '周树人(1881年9月25日—1936年10月19日),原名周樟寿,字豫山、豫亭,后改字豫才,笔名鲁迅,浙江绍兴人,为中国近代作家,' \
'新文化运动领袖之一,鲁迅生前创作了杂文、短中篇小说、文学、思想和社会评论、学术著作、自然科学著作、古代典籍校勘与研究、散文、' \
'现代散文诗、旧体诗、外国文学与学术翻译作品和木刻版画的研究,对于五四运动以后的中国社会思想文化发展产生了一定的影响,' \
'韩国文学评论家金良守称他为“二十世纪东亚文化地图上占最大领土的作家”,鲁迅在中国有“民族魂”之称。'
temp = jieba.lcut(words)
loss, word_dict = word2vec(words=temp, windows_size=2)
print()
print('loss = ', loss)
print('dict: ')
for i in set(temp):
print("word: {} vector: {}".format(i, word_dict[i]))
【注意这里的windows_size建议不要太大,因为我们初始化权重的时候用的是标准正太分布并且没有使用标准化来规范初始权重,windows_size过大容易出现梯度消失的问题,这个问题在我们实际中使用官方的初始化方法不会出现。】
五、代码运行结果展示
运行结果如下图所示:
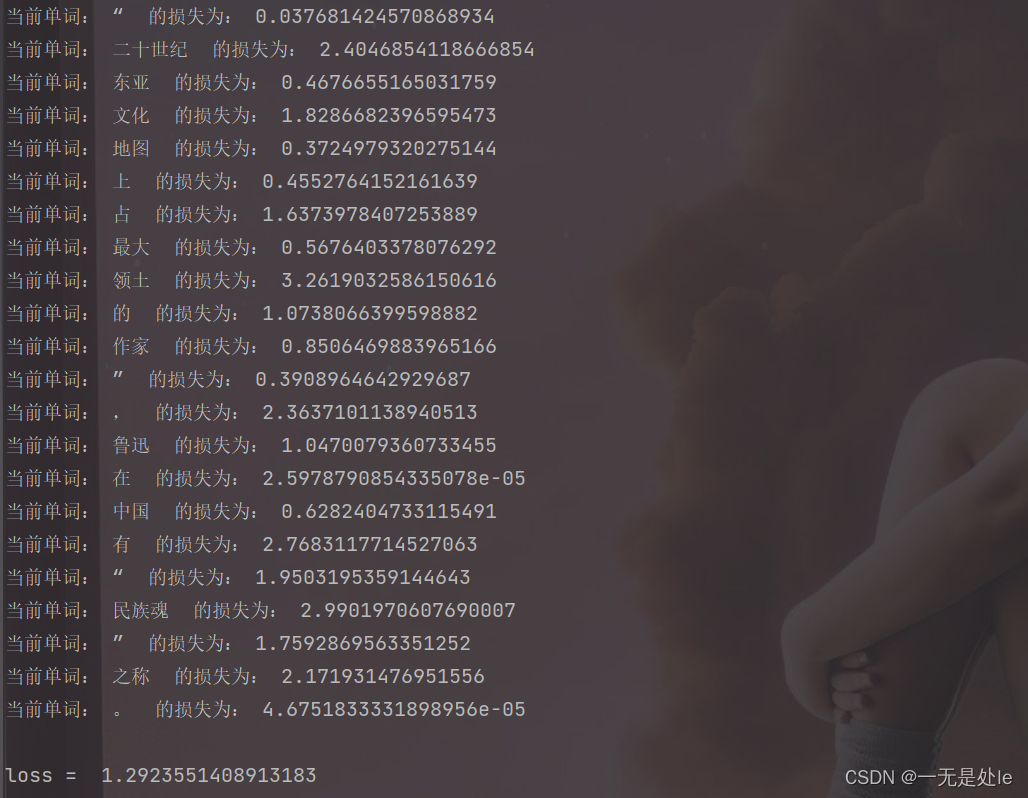
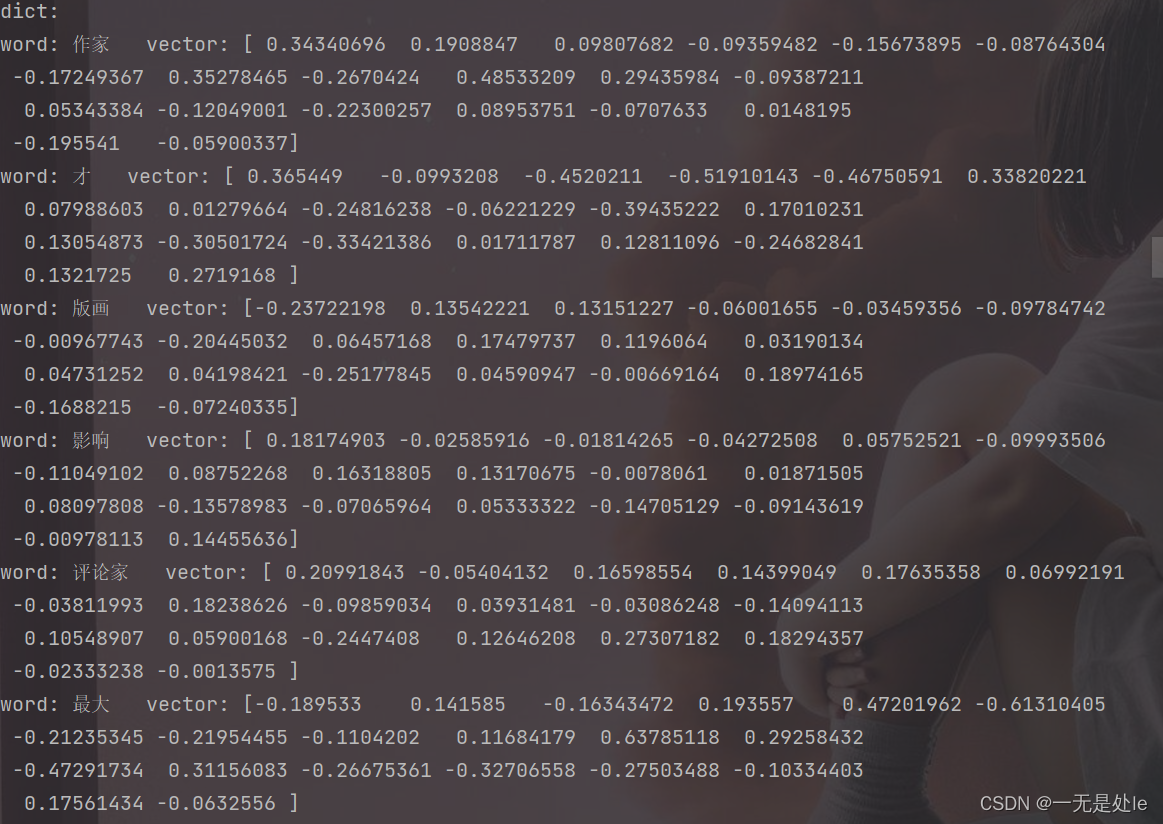
总结
这就是我本篇博客的所有内容,关于word2vec中的CBOW的手写代码实现,如有错误,欢迎指出。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)