拖拽式数据分析工具
随着人工智能的发展,数据分析也显得越来越重要,对于分析效率的要求也越来越高,而数据分析的门槛也需要逐步降低。需要允许用户通过简单的拖拽操作来完成相应的工作拖拽式工具提供了图像化的用户界面,用户可以选择所需要的数据源,并通过拖拽各种组件来清洗、转换数据,可以进行联合、聚合等操作。常见的组件包括过滤器、公式组件、统计组件。拖拽完成后,系统会自动生成代码,用户就不需要编写代码完成数据处理在分析建模方面,
随着人工智能的发展,数据分析也显得越来越重要,对于分析效率的要求也越来越高,而数据分析的门槛也需要逐步降低。需要允许用户通过简单的拖拽操作来完成相应的工作
拖拽式工具提供了图像化的用户界面,用户可以选择所需要的数据源,并通过拖拽各种组件来清洗、转换数据,可以进行联合、聚合等操作。常见的组件包括过滤器、公式组件、统计组件。拖拽完成后,系统会自动生成代码,用户就不需要编写代码完成数据处理
在分析建模方面,拖拽工具也提供了各种机器学习和数据分析算法的可视化模块,用户拖拽到不同的算法流程中,就可以快速对数据进行分析,生成报表。
现在比较知名的拖拽式数据分析工具包括Tablea、Microsoft Power BI、Trifacta等。随着移动互联网的发展,一些支持拖拽操作的BI工具也在兴起。下面给大家极少一块开源的拖拽式数据分析工具pygwalker
PyGWalker是个在Jupyter Notebook环境中运行的可视化探索式分析工具,仅一条命令即可生成一个可交互的图形界面,以类似Tableau/PowerBI的方式,通过拖拽字段进行数据分析。
过去在python中进行数据可视化分析时,经常需要查询大量的可视化类的代码,并编写的代码将其应用在数据集上。PyGWalker的目标是通过一行代码,将数据集转化为一个可视化分析工具,只需拖拉拽即可生成图表,从而减少数据分析师在数据可视化上的时间成本。
首先我们创建一个python虚拟环境并激活该环境
python -m venv venv
.\venv\Scripts\activate
然后安装该工具包和pandas以及jupyter
pip install pygwalker pandas jupyter
然后我们启动juypter,在terminal输入
jupyter notebook
出现如下界面

然后我们就可以进行数据分析了
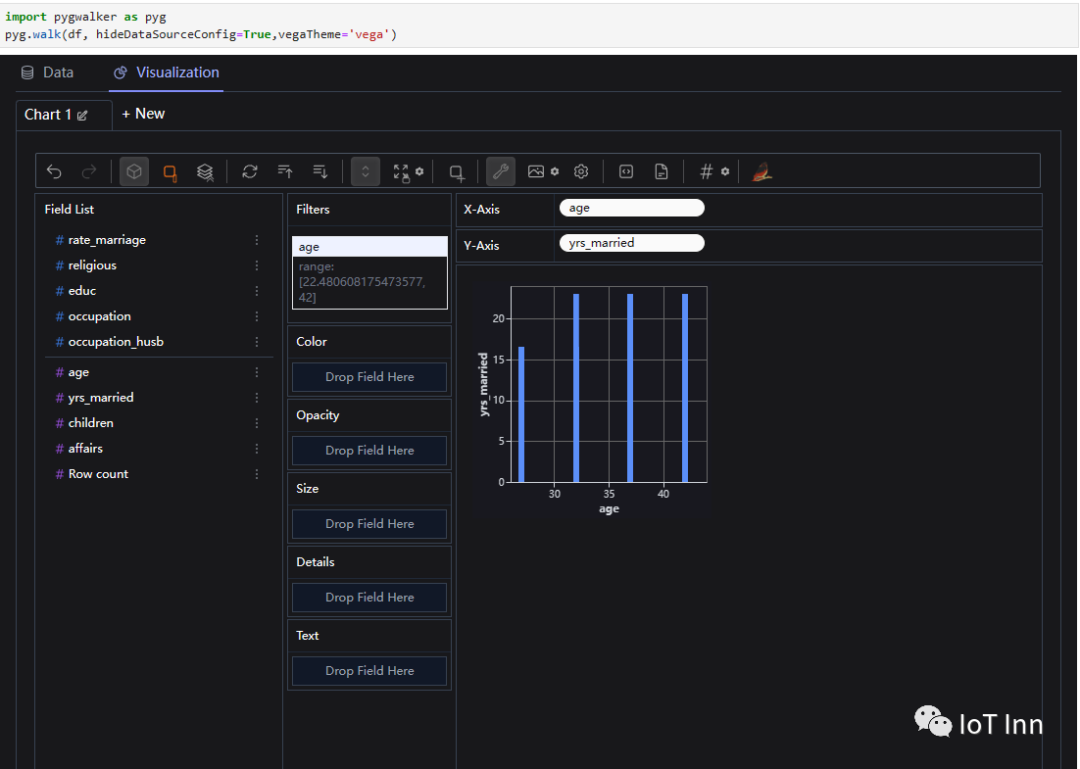
我们可以自己定义X,Y的label,进行柱状图的分析
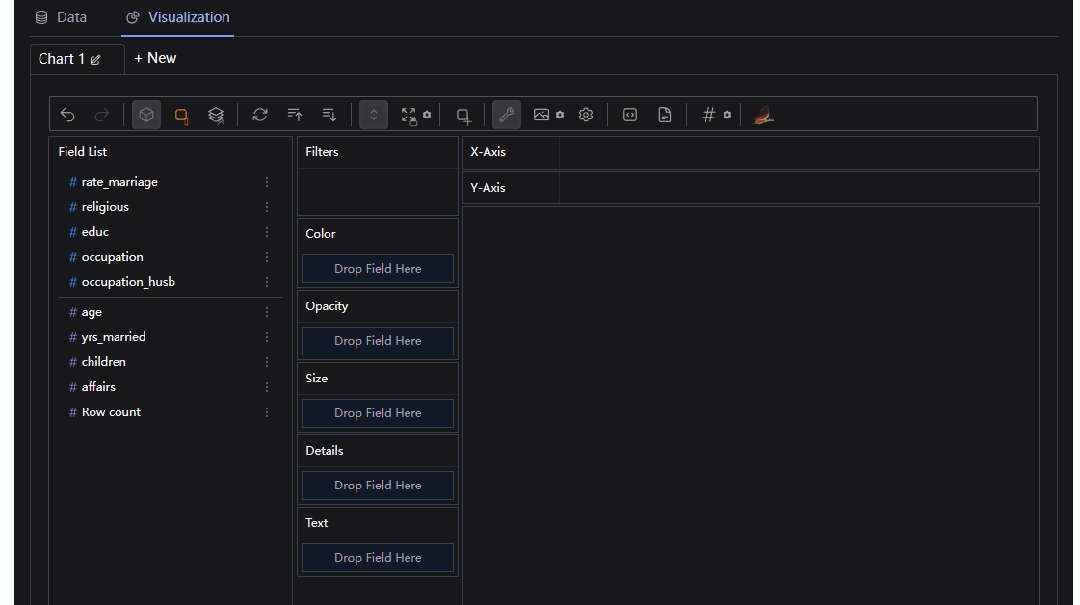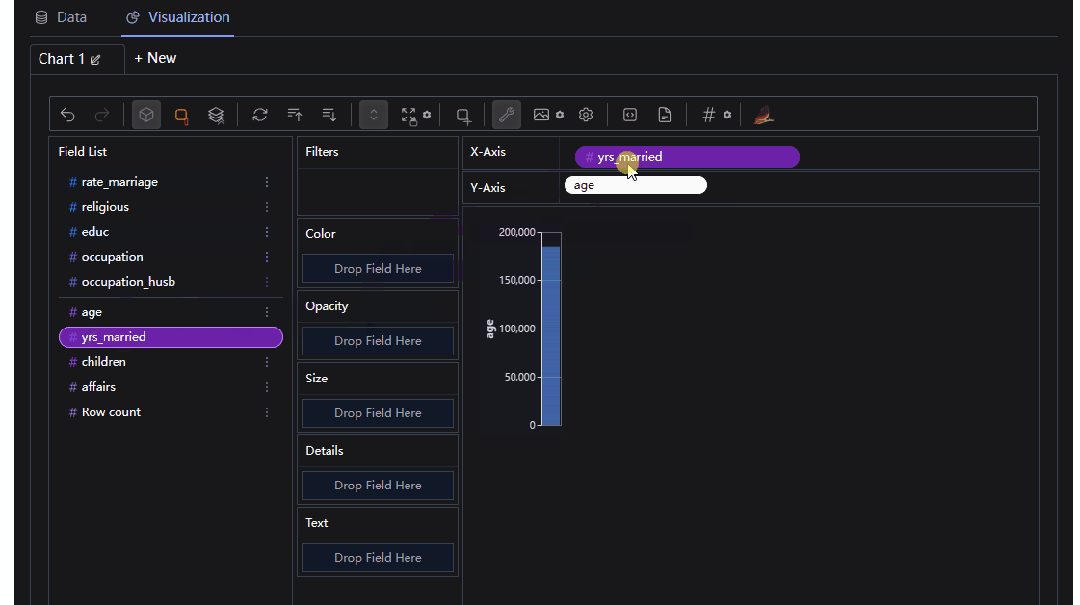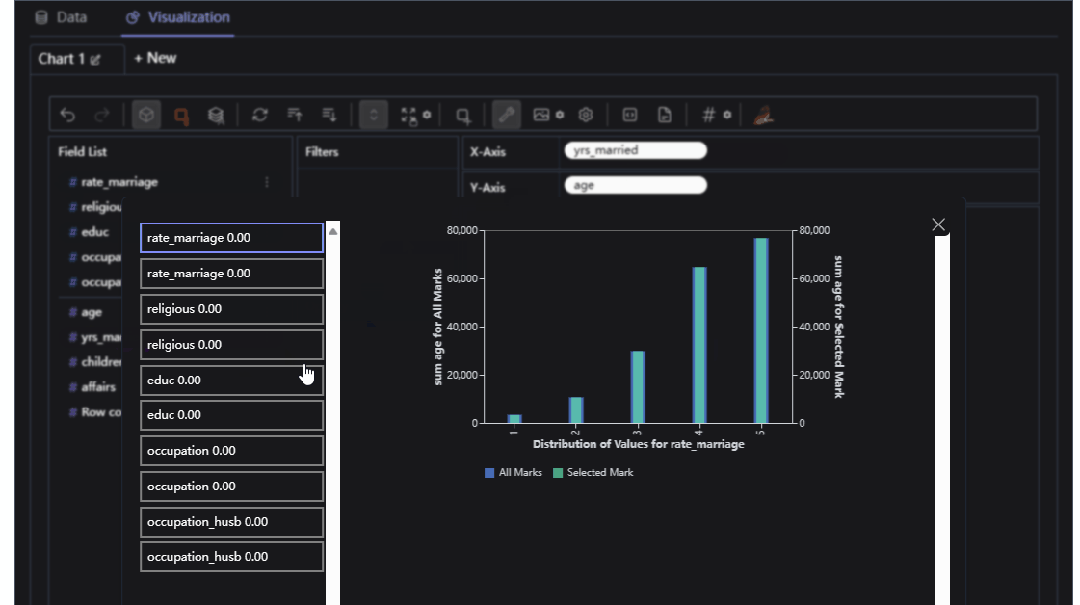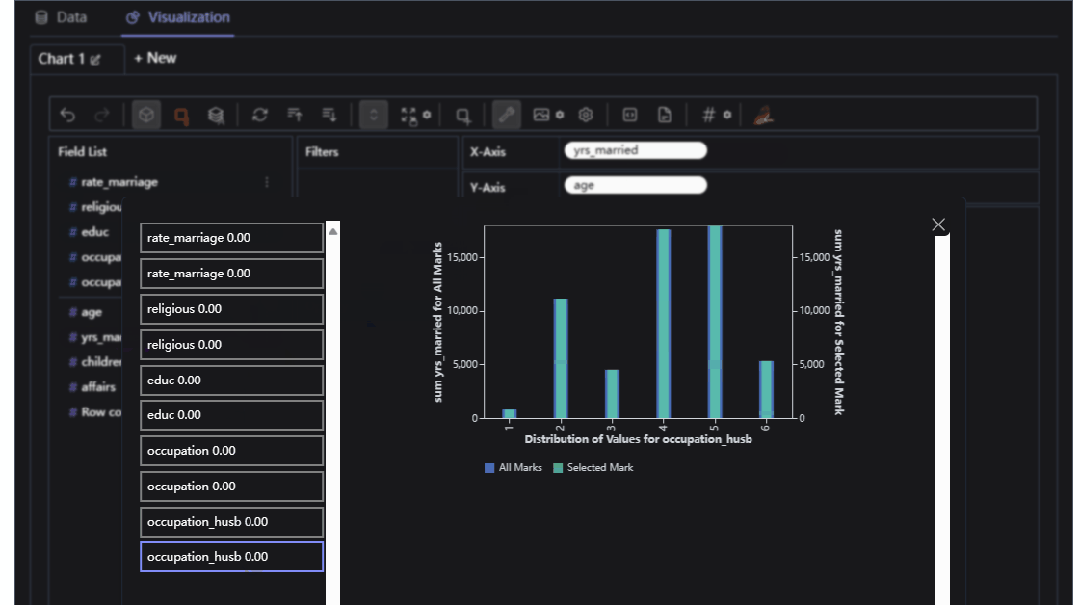
当然我们也可以进行相应的聚合运算
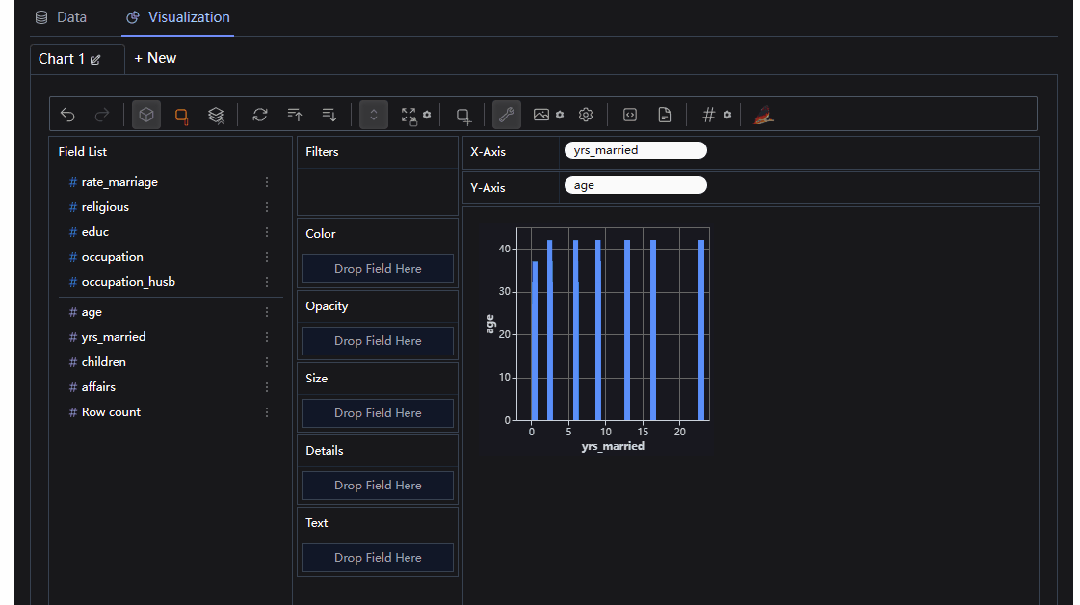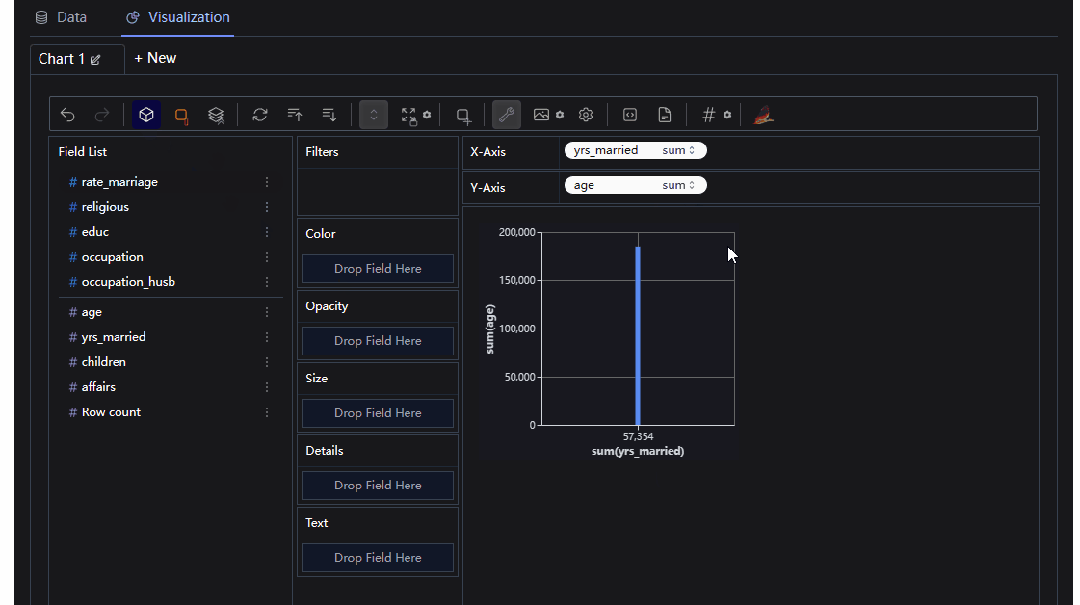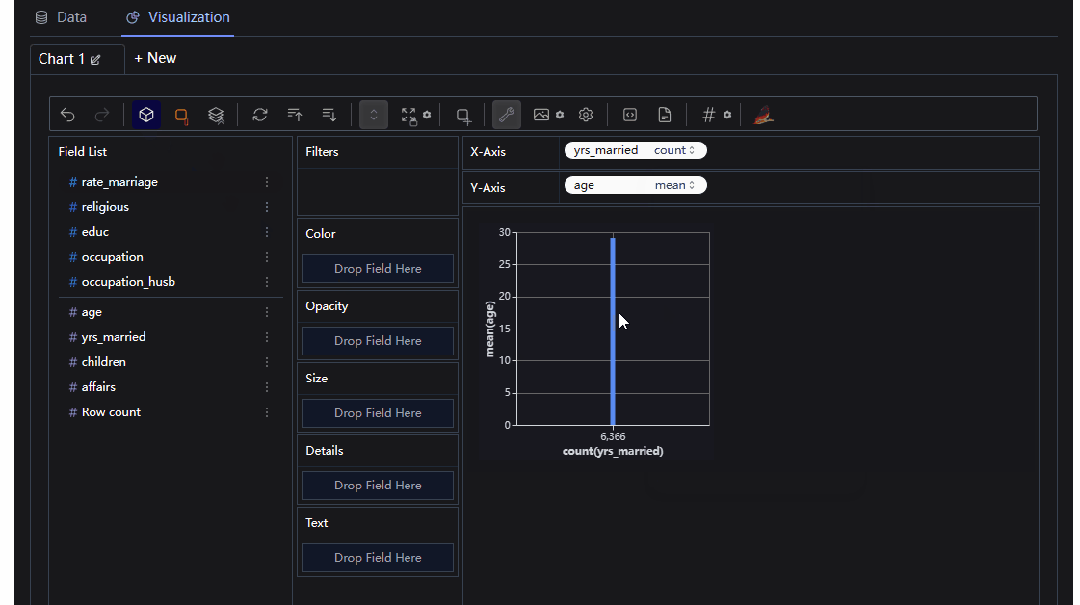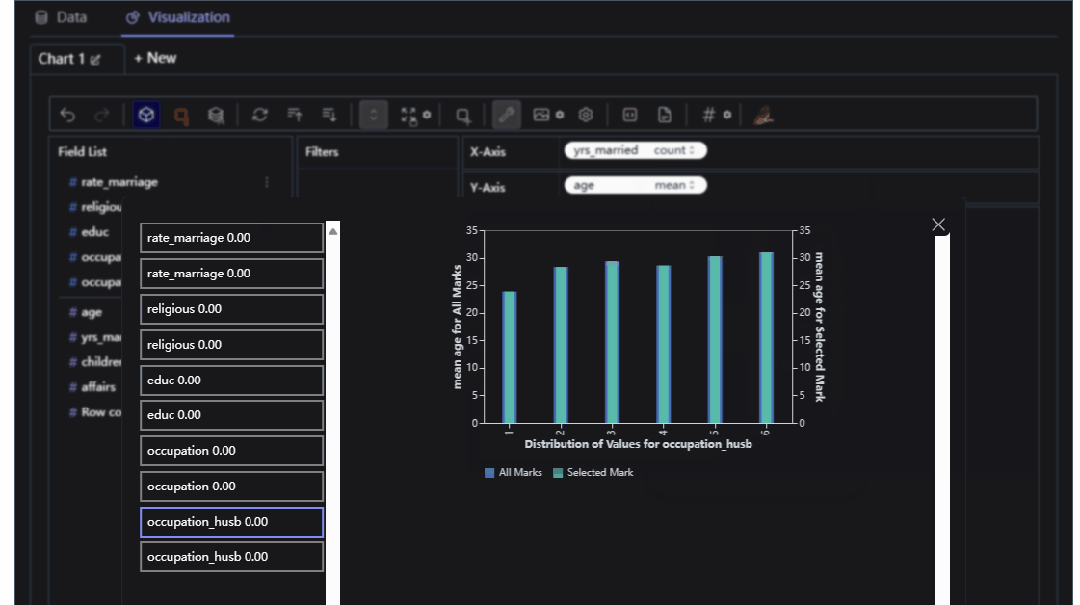
整体操作起来还是比较方便的,需要有一点点的python基础即可,感兴趣的朋友可以自己尝试下哟


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)