西电数据挖掘实验:分类技术——二分网络上的链路预测
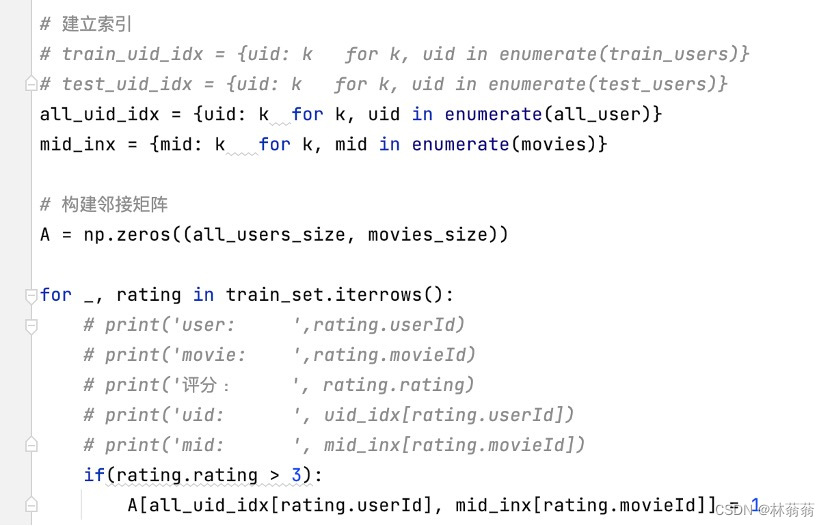
对于A矩阵,所有用户—所有电影都赋予一个值,即行:all_users_size,列:movies_size,首先给all_user、movies进行编号排序:all_uid_idx,mid_inx,每次从数据得到的用户、电影需要映射到序列函数中,得到其编号,如下图for循环中A[all_uid_idx[rating.userId], mid_inx[rating.movieId]]已知k_user
代码:experiments/数据挖掘 at main · ShutongLinn/experiments (github.com)
一、实验内容
基于网络结构的链路预测算法被广泛的应用于信息推荐系统中。算法不考虑用户和产品的内容特征,把它们看成抽象的节点,利用用户对产品的选择关系构建二部图。为用户评估它从未关注过的产品,预测用户潜在的消费倾向。
本实验依托ml-latest-small.zip中包括700个用户对9000部电影的100000条评价数据,对用户—电影进行建模,预测用户潜在的感兴趣的电影。
二、分析与设计
 |
|
|
A |
|
|
|
|
|
W |
|
|
|
|
|
f |
|
|
|
|
|
r |
|
|
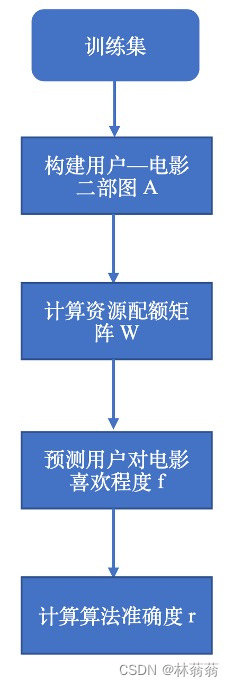
总体流程图 |


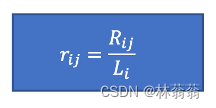
三、详细实现
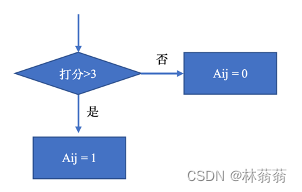
1、构建二部图A
对于A矩阵,所有用户—所有电影都赋予一个值,即行:all_users_size,列:movies_size,首先给all_user、movies进行编号排序:all_uid_idx,mid_inx,每次从数据得到的用户、电影需要映射到序列函数中,得到其编号,如下图for循环中A[all_uid_idx[rating.userId], mid_inx[rating.movieId]]
|
|
 |
|
二部图A |
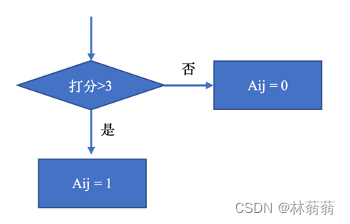
2、计算资源配额矩阵W
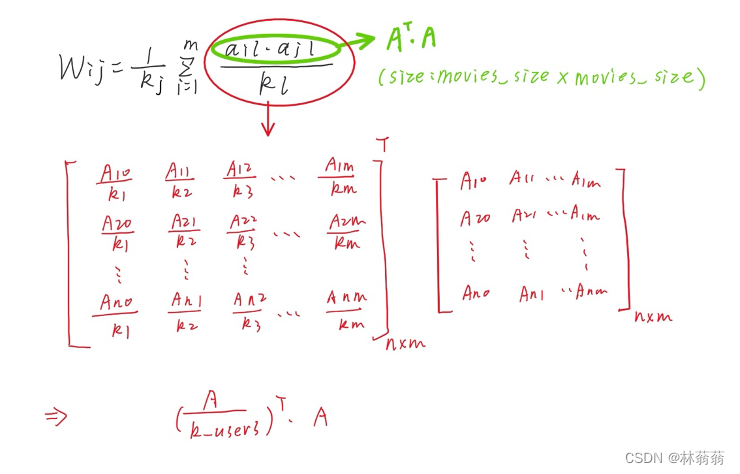 |
|
矩阵运算原理 |
 |
|
资源配额矩阵W |
3、预测f
|
|
 |
|
预测f |

4、准确度r
|
|
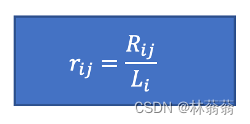
Li:对于用户i,有Li个产品未被选上;已知k_users[i]表示用户i的度,即Li = all_user_size – k_users[i]
 |
|
L |
Rij:测试集中用户i选择的电影j,而电影j依据向量 被排在第Rij位;建立升序索引,那f_sorted[I, index[i][j]排在第movies – j位
 |
|
R(f_sorted) |
如果在测试集中用户i选择的电影j,计算相对位置:
 |
|
B为测试集评分>3的矩阵 |
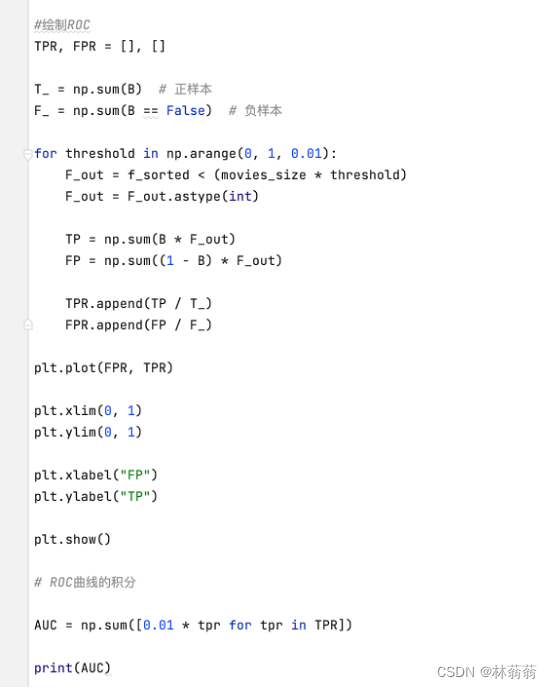
5、绘制ROC
|
|
四、实验结果
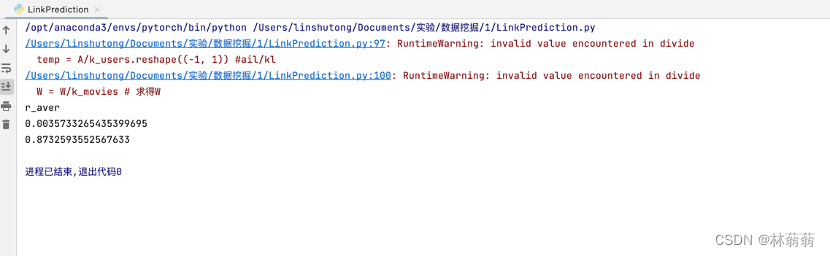 |
|
输出结果 r_aver = 0.003573… AUC = 0.873259… |
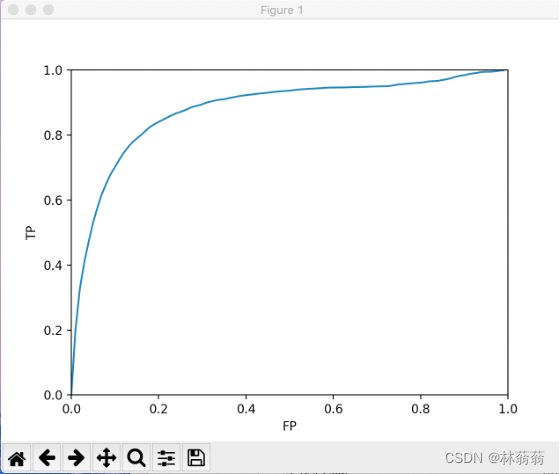 |
|
ROC曲线 |
运行警告:除数矩阵中存在元素0

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)