hadoop3.2.4&hbase2.4.17 centos7 集群安装
站点特定配置- etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml和etc/hadoop/mapred-site.xml。复制etc/hadoop/core-site.xml,etc/hadoop/hdfs-site.xml,etc/hadoop/yarn-site.xml到其它节点。phoeni
1.环境准备
安装ssh:
yum install pdsh
yum install ssh
准备三台服务器 hadoop1,hadoop2,hadoop3
分别修改三台服务器ip映射(注意一定要新增到第一行,不然后面hbase安装会有各种问题,master注册到zookeeper会使用localhost,导致HRegionServer无法连接上master):
vi /etc/hosts
10.10.1.185 hadoop1
10.10.1.186 hadoop2
10.10.1.187 hadoop3
三台服务器创建hadoop账户:
useradd hadoop
#修改密码,按照格式输入密码
passwd hadoop
#切换到hadoop账户
su - hadoop
三台机器 ssh生成公钥和私钥:
# 执行该命令,按3下回车
ssh-keygen -t rsa
[root@dyuit185 deepfm]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:L1XtzVo6eTXwo52xGYIk/c/90cKTJxAgEO46C9CndwI root@dyuit185
The key's randomart image is:
+---[RSA 2048]----+
| oo. . |
| . ... . |
| . . oo.. |
| . . o.oooo |
|. E . . S ...o.*=|
| . + . o o**%|
| o = . . . .@O=|
| o = . Bo|
| . .|
+----[SHA256]-----+
分别在三台机器执行公匙拷贝:
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
jdk安装:
yum search jdk
#安装jdk8
yum install java-1.8.0-openjdk.x86_64
2.安装hadoop
下载:下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
解压hadoop:
tar -zxvf hadoop-3.2.4.tar.gz
设置java环境:
cd hadoop-3.2.4/etc/hadoop
vi hadoop-env.sh
#java路径查看,或者直接到/usr/lib/jvm 目录下查看
which java
#设置JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64
验证hadoop是否成功:
bin/hadoop version
2.hadoop集群安装
Hadoop的Java配置由两种重要的配置文件驱动:
只读默认配置- core-default.xml、hdfs-default.xml、yarn-default.xml和mapred-default.xml。
站点特定配置- etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml和etc/hadoop/mapred-site.xml。
此外,您可以通过etc/ Hadoop / Hadoop -env.sh和etc/ Hadoop /yarn-env.sh设置特定站点的值来控制发行版的bin/目录下的Hadoop脚本。
要配置Hadoop集群,您需要配置Hadoop守护进程执行的环境以及Hadoop守护进程的配置参数。
HDFS的守护进程有NameNode、SecondaryNameNode和DataNode。YARN守护进程包括ResourceManager、NodeManager和WebAppProxy。如果要使用MapReduce,那么MapReduce作业历史服务器也将运行。对于大型安装,它们通常在单独的主机上运行。
HDFS:
- NameNode:这是HDFS文件系统的主服务器,负责管理文件系统的元数据。在HDFS中,文件被分成多个块,这些块分布在DataNode上。NameNode保存这些块的元数据信息,例如块的位置、大小等。NameNode还处理客户端的请求,例如打开文件、关闭文件等。
- SecondaryNameNode:虽然被称为SecondaryNameNode,但实际上它并不是NameNode的备份。SecondaryNameNode主要是用来辅助NameNode进行元数据检查和合并。在NameNode中,元数据信息是保存在内存中的,当NameNode重启时,这些信息会丢失。SecondaryNameNode会定期从NameNode获取元数据快照,并在本地保存这些快照。当NameNode重启后,SecondaryNameNode可以提供这些快照帮助NameNode恢复元数据。
- DataNode:DataNode是HDFS文件系统的存储节点,负责实际的数据存储和检索。客户端将文件分成块,并将这些块发送到DataNode。DataNode保存这些块,并响应客户端和NameNode的请求。
YARN:
- ResourceManager:ResourceManager是YARN资源管理的主要组件,负责全局的资源分配和管理。它接收来自各个应用程序的资源请求,并按照一定的策略将资源分配给应用程序。ResourceManager还负责监控应用程序的资源使用情况,如果某个应用程序超过了其资源限制,ResourceManager会将其从系统中驱逐。
- NodeManager:NodeManager是YARN中的节点管理器,负责管理一个计算节点上的所有资源,包括CPU、内存、磁盘等。NodeManager接收来自ResourceManager的资源分配指令,并将这些资源分配给各个应用程序。同时,NodeManager还负责监控应用程序的运行状态,如果某个应用程序崩溃或需要释放资源,NodeManager会将其从系统中移除。
- WebAppProxy:WebAppProxy是一个轻量级的代理组件,用于为YARN应用程序提供Web界面。它接收来自客户端的请求,并将其转发给相应的应用程序。通过WebAppProxy,用户可以通过浏览器查看应用程序的运行状态、监控资源使用情况等。需要注意的是,WebAppProxy并不是YARN守护进程的一部分,它通常作为一个独立的进程运行。
环境配置:
编辑 etc/hadoop/hadoop-env.sh
vi etc/hadoop/hadoop-env.sh
#jvm 路径 配置
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64
#jvm 配置
export HDFS_NAMENODE_OPTS="-XX:+AlwaysPreTouch -Xss1m -Xms2g -Xmx2g -XX:+UseG1GC -XX:+HeapDumpOnOutOfMemoryError -XX:G1HeapRegionSize=4m -XX:InitiatingHeapOccupancyPercent=30 -XX:G1ReservePercent=15"
#存放守护进程进程id文件的目录,需要手动先创建
export HADOOP_PID_DIR=/data/hadoop/hadoop_pid_dir
#存放守护进程日志文件的目录。如果日志文件不存在,则自动创建日志文件
export HADOOP_LOG_DIR=/data/hadoop/hadoop_log_dir/logs
编辑 etc/hadoop/yarn-env.sh
**vi etc/hadoop/yarn-env.sh**
#jvm 配置
export YARN_RESOURCEMANAGER_OPTS="-XX:+AlwaysPreTouch -Xss1m -Xms2g -Xmx2g -XX:+UseG1GC -XX:+HeapDumpOnOutOfMemoryError -XX:G1HeapRegionSize=4m -XX:InitiatingHeapOccupancyPercent=30 -XX:G1ReservePercent=15"
复制配置文件到其它节点:
scp etc/hadoop/yarn-env.sh hadoop2:/hadoop-3.2.4/etc/hadoop/
scp etc/hadoop/hadoop-env.sh hadoop2:/hadoop-3.2.4/etc/hadoop/
scp etc/hadoop/yarn-env.sh hadoop3:/hadoop-3.2.4/etc/hadoop/
scp etc/hadoop/hadoop-env.sh hadoop3:/hadoop-3.2.4/etc/hadoop/
hadoop进程分布如下
hadoop1:NameNode,DataNode,ResourceManager
hadoop2:DataNode,NodeManager,proxyserver
hadoop3:DataNode
编辑etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!--在SequenceFiles中使用的读写缓冲区的大小。 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
编辑etc/hadoop/hdfs-site.xml
<configuration>
<!--HDFS的复制因子 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--NameNode持久化存储命名空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/dfs_namenode_name_dir</value>
</property>
<!-- DataNode的本地文件系统上以逗号分隔的路径列表,它应该在其中存储其块-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dfs_datanode_data_dir</value>
</property>
</configuration>
编辑etc/hadoop/yarn-site.xml
<configuration>
<!-- 是否启用acl 默认false -->
<property>
<name>yarn.acl.enable</name>
<value>false</value>
</property>
<!-- ACL用于在集群上设置管理员。acl适用于逗号分隔的用户、逗号分隔的组。默认为特殊值*,表示任何人。空间的特殊价值意味着没有人能进入。-->
<property>
<name>yarn.admin.acl</name>
<value>*</value>
</property>
<!--ResourceManager host:客户端提交作业的端口 -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:3030</value>
</property>
<!--ResourceManager host: ApplicationMasters与Scheduler对话以获取资源的端口 -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:3031</value>
</property>
<!-- ResourceManager host: nodemanager的端口。-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:3032</value>
</property>
<!-- ResourceManager host:管理命令的端口。-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:3033</value>
</property>
<!-- ResourceManager web-ui host:port-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:3034</value>
</property>
<!-- ResourceManager proxyserver host:port-->
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop2:3035</value>
</property>
<!-- 写入中间数据的本地文件系统上以逗号分隔的路径列表。-->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn_nodemanager_local-dirs</value>
</property>
<!-- 用逗号分隔的本地文件系统中写入日志的路径列表。-->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/hadoop/yarn_nodemanager_log-dirs</value>
</property>
复制etc/hadoop/core-site.xml,etc/hadoop/hdfs-site.xml,etc/hadoop/yarn-site.xml到其它节点
第一次打开HDFS时,必须对其进行格式化。将一个新的分布式文件系统格式化为hdfs
所有节点都需要执行
$HADOOP_HOME/bin/hdfs namenode -format
在指定节点以HDFS方式启动HDFS NameNode:
在节点hadoop1启动
$HADOOP_HOME/bin/hdfs --daemon start namenode
#stop
$HADOOP_HOME/bin/hdfs --daemon stop namenode
在每个指定节点以HDFS的方式启动HDFS DataNode,命令如下
$HADOOP_HOME/bin/hdfs --daemon start datanode
#stop
$HADOOP_HOME/bin/hdfs --daemon stop datanode
在指定的ResourceManager上以YARN的身份运行,使用如下命令启动YARN
在节点hadoop1启动
$HADOOP_HOME/bin/yarn --daemon start resourcemanager
#stop
$HADOOP_HOME/bin/yarn --daemon stop resourcemanager
每个指定的主机上启动一个NodeManager作为yarn:
$HADOOP_HOME/bin/yarn --daemon start nodemanager
启动一个独立的WebAppProxy服务器。以yarn的形式在WebAppProxy服务器上运行。如果使用多个服务器进行负载平衡,则应该在每个服务器上运行负载平衡
$HADOOP_HOME/bin/yarn --daemon start proxyserver
#stop
$HADOOP_HOME/bin/yarn stop proxyserver
web可视化:
NameNode:http://hadoop1:9870/
ResourceManager: http://hadoop1:3034/
3.hbase集群安装
zookeeper3.7.2集群安装
分别在在各个节点创建zookeeper安装目录
#创建目录
mkdir -p $ZK_HOME/zookeeper
#修改目录权限
chown hadoop:hadoop $ZK_HOME/zookeeper
#切换到hadoop用户下载zookeeper安装包
su - hadoop
wget --no-check-certificate https://dlcdn.apache.org/zookeeper/zookeeper-3.7.2/apache-zookeeper-3.7.2-bin.tar.gz
#解压到安装目录
tar -zxvf apache-zookeeper-3.7.2-bin.tar.gz -C $ZK_HOME/zookeeper
#复制配置文件
cd $ZK_HOME/zookeeper/apache-zookeeper-3.7.2-bin/conf
#修改配置文件
vi zoo.cfg
zoo.cfg配置:
# ZooKeeper使用的基本时间单位为毫秒。它用于执行心跳,并且最小会话超时时间将是tickTime的两倍
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
#存储内存中数据库快照的位置,以及(除非另有指定)数据库更新的事务日志的位置。
dataDir=$ZK_HOME/zookeeper/data
# 监听客户端连接的端口
clientPort=2181
#admin端口
admin.serverPort=8081
#集群配置 server.myid = 节点地址:follower连接到leader的端口:选举leader端口
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
配置文件设置好然后同步到所有节点
创建myid:
在所有节点$ZK_HOME/zookeeper/data目录创建myid文件,设置myid,值在1-254范围内
cd $ZK_HOME/zookeeper/data
vi myid
启动所有节点zookeeper
cd $ZK_HOME/zookeeper/apache-zookeeper-3.7.2-bin
bin/zkServer.sh start
连接zookeeper:
bin/zkCli.sh -server 127.0.0.1:2181
删除命令:
deleteall /hbase
hbase集群安装
下载地址:https://dlcdn.apache.org/hbase/2.4.17/hbase-2.4.17-bin.tar.gz
hbase对应的java版本: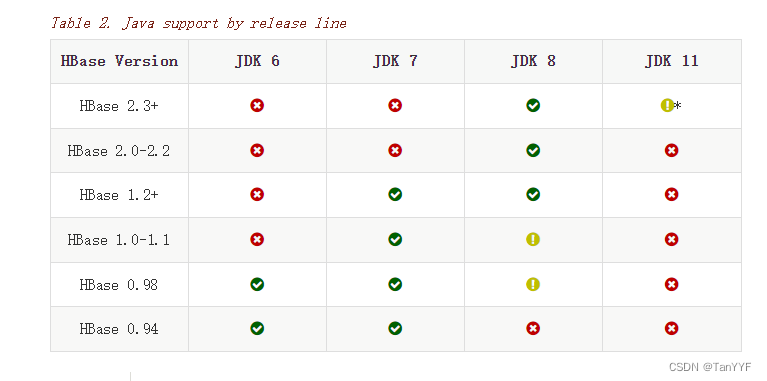
hbase对应的hadoop版本: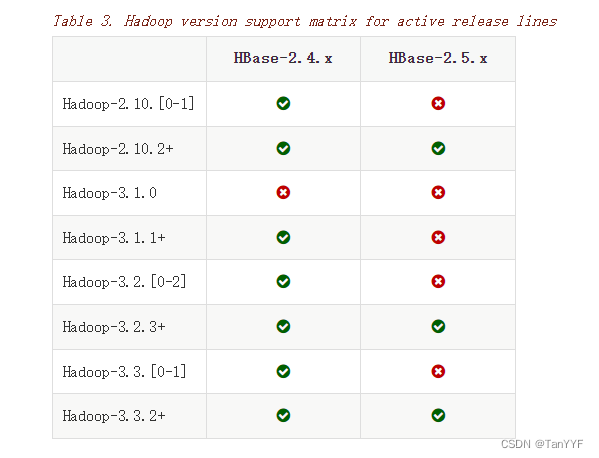
分别在在各个节点创建habse安装目录
#创建目录
mkdir -p $ZK_HOME/hbase
#修改目录权限
chown hadoop:hadoop $ZK_HOME/hbase
#切换到hadoop用户下载zookeeper安装包
su - hadoop
wget --no-check-certificate https://dlcdn.apache.org/hbase/2.4.17/hbase-2.4.17-bin.tar.gz
#解压到安装目录
tar -zxvf hbase-2.4.17-bin.tar.gz -C $ZK_HOME/hbase
服务器编辑 /etc/security/limits.conf,修改文件和进程数量限制(ulimit)
* soft nofile 655360
* hard nofile 655360
服务器节点配置如下:
| Node name | Master | RegionServer |
|---|---|---|
| hadoop1 | yes | no |
| hadoop2 | backup | yes |
| hadoop3 | no | yes |
conf/hbase-env.sh jvm配置
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64
export HBASE_OPTS="-XX:+AlwaysPreTouch -Xss1m -Xms2g -Xmx2g -XX:+UseG1GC -XX:+HeapDumpOnOutOfMemoryError -XX:G1HeapRegionSize=4m -XX:InitiatingHeapOccupancyPercent=30 -XX:G1ReservePercent=15"
#使用外部zookeeper
export HBASE_MANAGES_ZK=false
hadoop安装目录etc/hadoop/hdfs-site.xml添加属性:
<!-- HDFS DataNode每次服务的文件数量有上限-->
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
重启datanode,所有节点执行:
#停止datanode
bin/hdfs --daemon stop datanode
#启动datanode
bin/hdfs --daemon start datanode
#查询datanode
ps aux|grep datanode
conf/hdfs-site.xml 文件配置
<configuration>
<!-- 开启集群-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- hdfs-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<!-- zookeeper 集群配置-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<!--临时数据目录 zookeeper 数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>$ZK_HOME/zookeeper/data</value>
</property>
</configuration>
conf/regionservers 配置region节点 hadoop2,hadoop3
hadoop2
hadoop3
配置HBase使用hadoop2作为备份主节点
#新建文件
vi conf/backup-masters
#编辑内容
hadoop2
复制配置文件hadoop1到hadoop2,hadoop3
启动集群:
#启动
bin/start-hbase.sh
#关闭
bin/stop-hbase.sh
hdfs删除hbase目录:
bin/hdfs dfs -rmr /hbase
web ui 地址:
http://hadoop1:16010
4.使用DBeaver连接hbase
DBeaver下载地址:https://dbeaver.io/download/
phoenix下载地址:https://phoenix.apache.org/download.html
下载版本:https://dlcdn.apache.org/phoenix/phoenix-5.1.3/phoenix-hbase-2.4.0-5.1.3-bin.tar.gz
wget https://dlcdn.apache.org/phoenix/phoenix-5.1.3/phoenix-hbase-2.4.0-5.1.3-bin.tar.gz
tar -zxvf phoenix-hbase-2.4.0-5.1.3-bin.tar.gz
cd phoenix-hbase-2.4-5.1.3-bin
#将phoenix server jar复制到每个区域服务器和主服务器的lib目录中
scp phoenix-server-hbase-2.4-5.1.3.jar hadoop1:$HBASE_HOME/hbase-2.4.17/lib/
scp phoenix-server-hbase-2.4-5.1.3.jar hadoop2:$HBASE_HOME/hbase-2.4.17/lib/
scp phoenix-server-hbase-2.4-5.1.3.jar hadoop2:$HBASE_HOME/hbase-2.4.17/lib/
修改所有节点hbase-site.xml
vi $HBASE_HOME/conf/hbase-site.xml
新增属性:
<!-- 注意:为了开启hbase的namespace和phoenix的schema的映射,在程序中需要加这个配置文件,另外在linux服务上,也需要在hbase以及phoenix的hbase-site.xml配置文件中,加上以上两个配置,并使用xsync进行同步-->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
重启hbase,在master节点执行:
#停止
$HBASE_HOME/hbase-2.4.17/bin/stop-hbase.sh
#启动
$HBASE_HOME/hbase-2.4.17/bin/start-hbase.sh
DBeaver连接hbase
第一步创建链接,选择phoenix:
第二步填写服务器地址: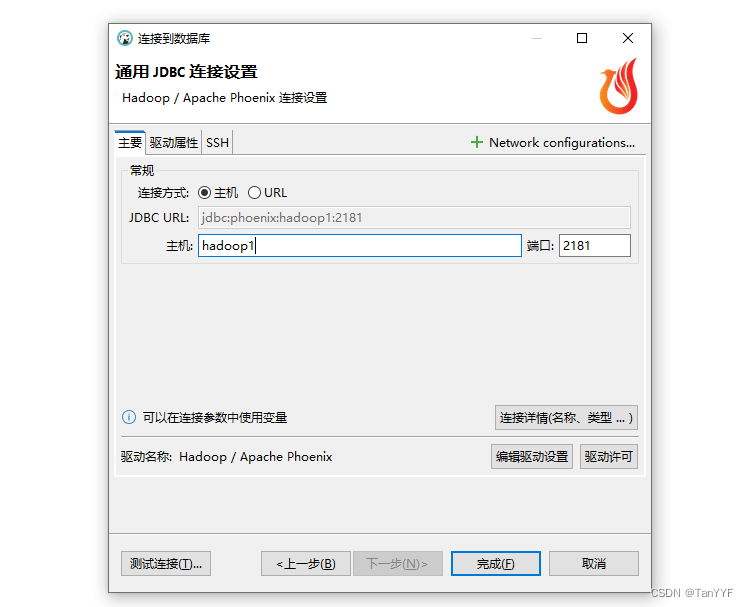
第三步编辑驱动设置: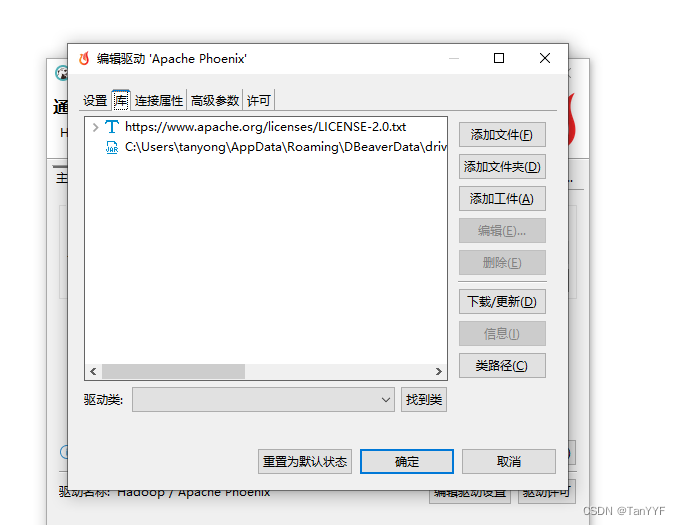
将旧的驱动删除,添加新的驱动phoenix-client-hbase-2.4-5.1.3.jar,点击查找类: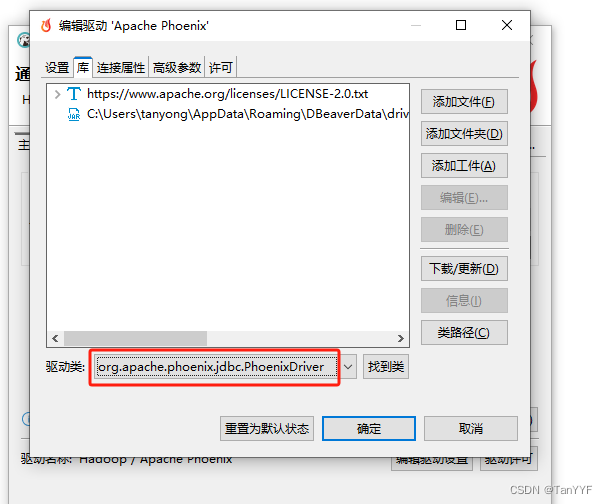
新增连接属性:
phoenix.schema.isNamespaceMappingEnabled:true
phoenix.schema.mapSystemTablesToNamespace:true
属性设置完,点击测试连接: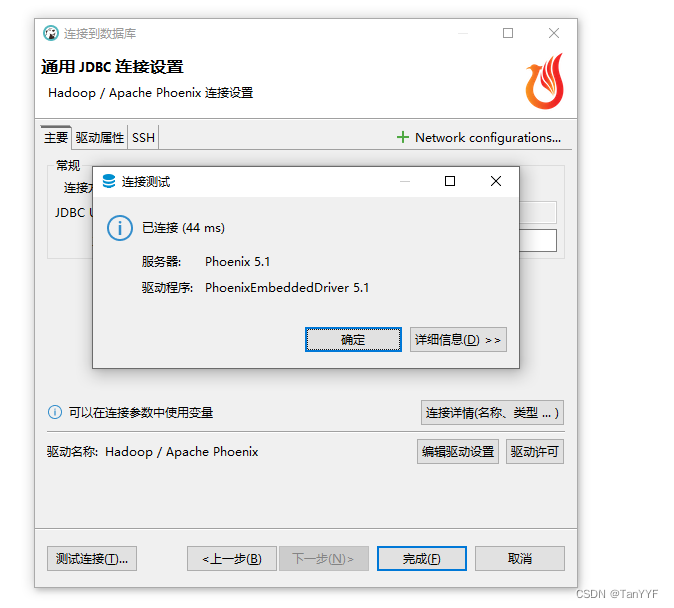
连接成功以后的效果:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)