docker-compose监控nVidia GPU
可以选择docker-compose去运行nvidia_smi_exporter (推荐)可以选择docker run 去运行nvidia_smi_exporter。prometheus配置。
·
可以选择docker run 去运行nvidia_smi_exporter
docker run -d --name nvidia_smi_exporter --restart unless-stopped --device /dev/nvidiactl:/dev/nvidiactl --device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidia1:/dev/nvidia1 -v /usr/lib/x86_64-linux-gnu/libnvidia-ml.so:/usr/lib/x86_64-linux-gnu/libnvidia-ml.so -v /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1:/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1 -v /usr/bin/nvidia-smi:/usr/bin/nvidia-smi -p 9835:9835 utkuozdemir/nvidia_gpu_exporter:1.1.0可以选择docker-compose去运行nvidia_smi_exporter (推荐)
version: '3'
services:
nvidia_smi_exporter:
image: utkuozdemir/nvidia_gpu_exporter:1.1.0
container_name: nvidia_smi_exporter
restart: unless-stopped
devices:
- /dev/nvidiactl:/dev/nvidiactl
- /dev/nvidia0:/dev/nvidia0
- /dev/nvidia1:/dev/nvidia1
volumes:
- /usr/lib/x86_64-linux-gnu/libnvidia-ml.so:/usr/lib/x86_64-linux-gnu/libnvidia-ml.so
- /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1:/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1
- /usr/bin/nvidia-smi:/usr/bin/nvidia-smi
ports:
- "9835:9835"curl 127.0.0.1:9835/metrics
nvidia_smi_temperature_memory{uuid="a52aea53-bc0c-61ca-8f99-df0926347ce2"} 57
# HELP nvidia_smi_utilization_gpu_ratio utilization.gpu [%]
# TYPE nvidia_smi_utilization_gpu_ratio gauge
nvidia_smi_utilization_gpu_ratio{uuid="9aad4dc0-0be0-c871-2f84-6b990152f5ec"} 0
nvidia_smi_utilization_gpu_ratio{uuid="a52aea53-bc0c-61ca-8f99-df0926347ce2"} 1
# HELP nvidia_smi_utilization_memory_ratio utilization.memory [%]
# TYPE nvidia_smi_utilization_memory_ratio gauge
nvidia_smi_utilization_memory_ratio{uuid="9aad4dc0-0be0-c871-2f84-6b990152f5ec"} 0
nvidia_smi_utilization_memory_ratio{uuid="a52aea53-bc0c-61ca-8f99-df0926347ce2"} 0
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 22.55
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1.048576e+06
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 12
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 1.7002496e+07
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.70476923874e+09
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 7.40630528e+08
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 1.8446744073709552e+19
# HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served.
# TYPE promhttp_metric_handler_requests_in_flight gauge
promhttp_metric_handler_requests_in_flight 1
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 1447
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
等等..................告警规则
groups:
- name: example
rules:
- alert: GPU内存使用率高
expr: (nvidia_smi_memory_used_bytes / ignoring(instance) nvidia_smi_memory_total_bytes) > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "GPU memory usage is above 90%"
description: "The GPU({{ $labels.uuid }}) 已使用 90% 以上的内存超过5分钟."
- alert: GPU的温度过高
expr: nvidia_smi_temperature_gpu > 80
for: 5m
labels:
severity: warning
annotations:
summary: "GPU temperature is above 80 degrees"
description: "The GPU({{ $labels.uuid }}) 温度已经超过 80° 超过5分钟."
- alert: GPU的功率使用过高
expr: nvidia_smi_power_draw_watts / nvidia_smi_power_limit_watts > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "GPU power usage is above 90% of its limit"
description: "The GPU({{ $labels.uuid }}) 已使用超过 90% 的功率限制超过5分钟."
- alert: GPU_ECC错误过多
expr: increase(nvidia_smi_ecc_errors_corrected_volatile_total[1h]) > 0
for: 1h
labels:
severity: critical
annotations:
summary: "GPU ECC错误增加"
description: "在过去的一小时内,GPU({{ $labels.uuid }})的ECC错误数量有所增加。"
- alert: GPU瓦数过高
expr: nvidia_smi_power_draw_watts > 250
for: 5m
labels:
severity: warning
annotations:
summary: "GPU功耗超过250瓦"
description: "GPU({{ $labels.uuid }})的功耗已超过250瓦,持续时间超过5分钟。"
# - alert: 高GPU使用率
# expr: nvidia_smi_utilization_gpu_ratio > 0.9
# for: 1h
# labels:
# severity: 警告
# annotations:
# summary: GPU使用率过高
# description: GPU使用率超过90%,并且持续了超过1小时。
prometheus配置
- job_name: "A100服务器"
scrape_interval: 15s
static_configs:
- targets: ["IP:9835"]
labels:
instance: xxxxxgrafana模板
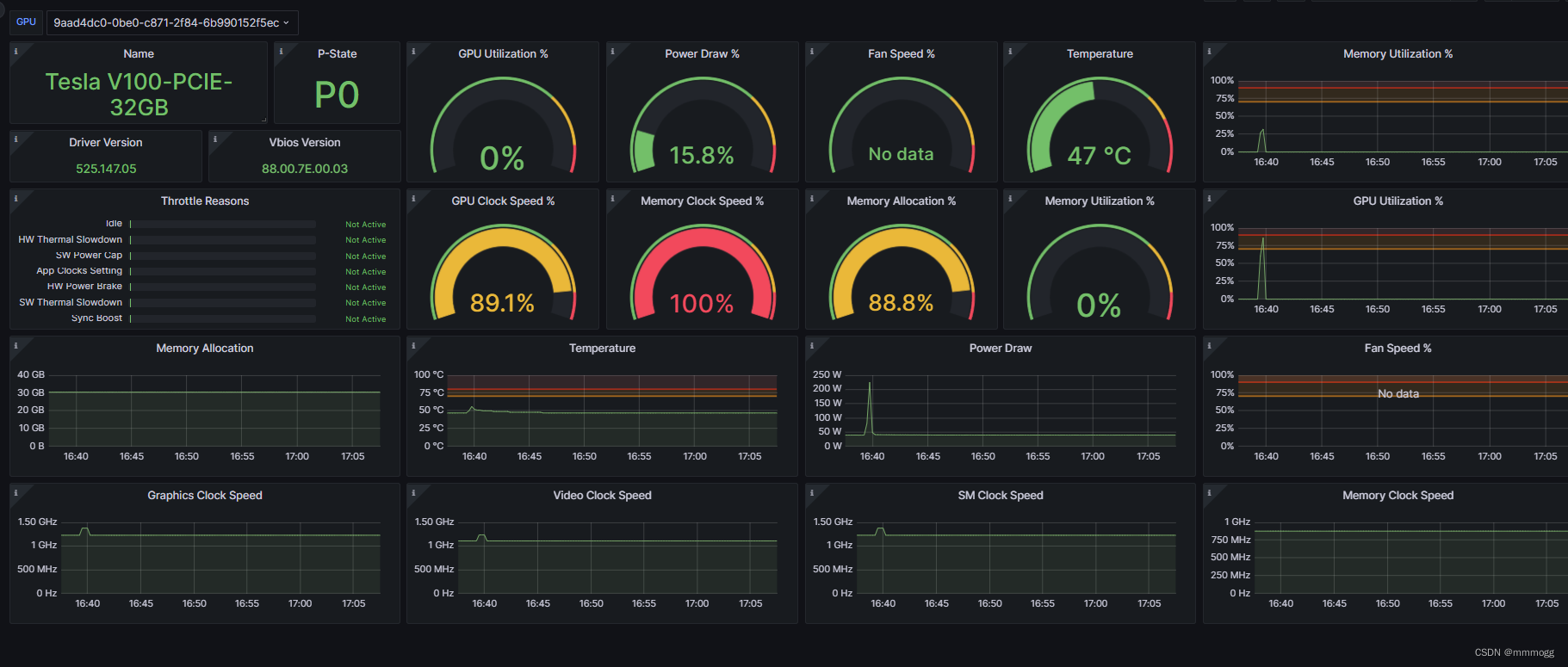
14574

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)