深度学习-Pytorch实现经典VGGNet网络
深度学习-Pytorch实现经典VGGNet网络
深度学习中,经典网络引领一波又一波的技术革命,从LetNet到当前最火的GPT所用的Transformer,它们把AI技术不断推向高潮。2012年AlexNet大放异彩,它把深度学习技术引领第一个高峰,打开人们的视野。
用pytorch构建CNN经典网络模型VGGNet,还可以用数据进行训练模型,得到一个优化的模型。
深度学习算法
深度学习-回顾经典AlexNet网络:山高我为峰-CSDN博客
GPT实战系列-如何用自己数据微调ChatGLM2模型训练_pytorch 训练chatglm2 模型-CSDN博客
VGGNet概述
2014年,牛津大学计算机视觉组(Visual Geometry Group)和DeepMind公司一起研发了新的卷积神经网络,并命名为VGGNet。VGGNet是比AlexNet更深的深度卷积神经网络,该模型获得了2014年ILSVRC竞赛的第二名。
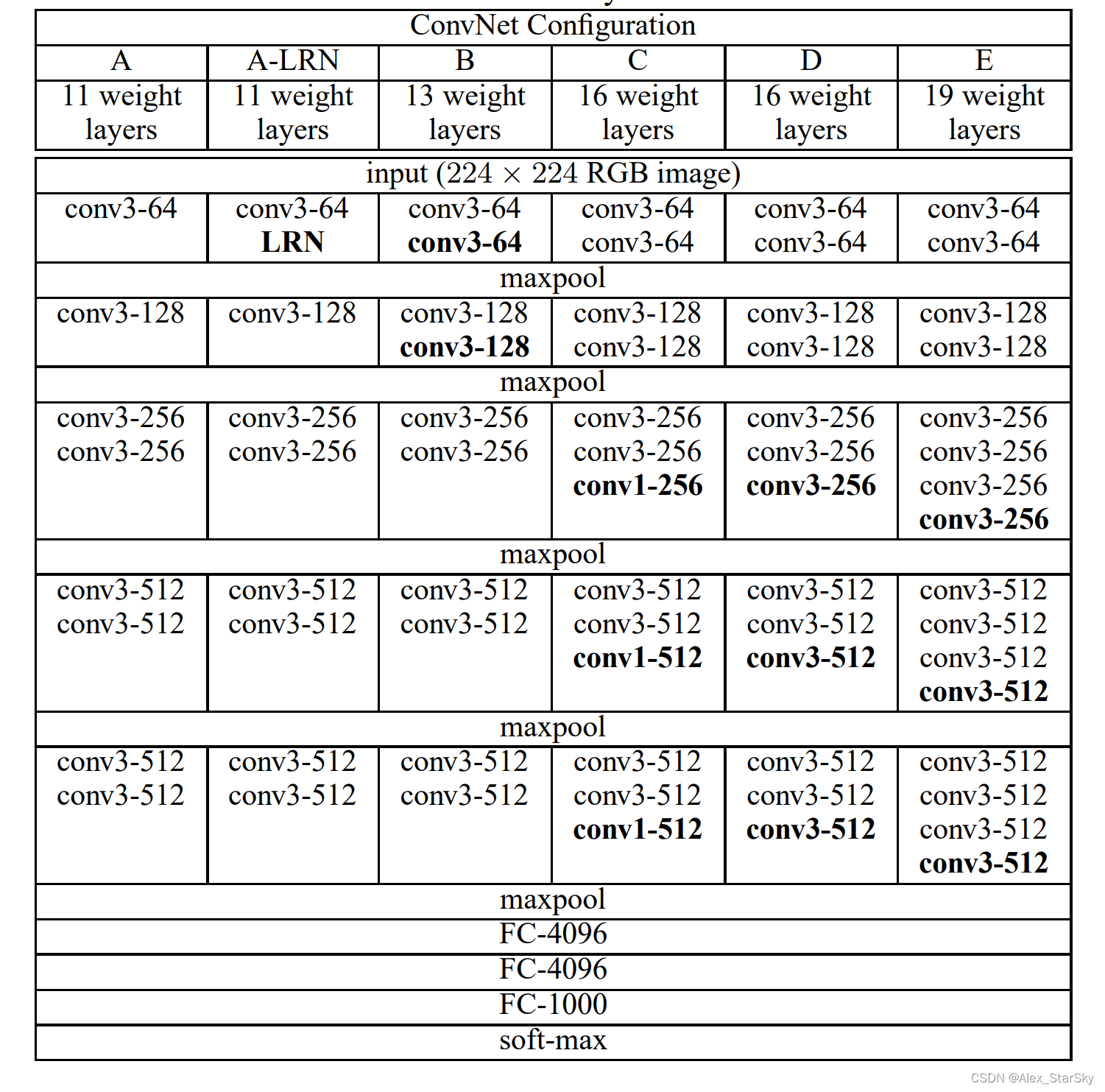
网络结构
VGG 的结构与 AlexNet 类似,区别是深度更深,但形式上更加简单。VGG由5层卷积层、3层全连接层、1层softmax输出层构成,层与层之间使用maxpool(最大化池)分开,所有隐藏层的激活单元都采用ReLU函数。
事实上,作者设计了6种网络结构,以下以常用的VGG16 D为例。
输入图像3通道分辨率:224x224x3
结构:
9层:图像输入后,5个卷积层,3个全连接层,1个输出层;
(1)C1:3x3 —>64个conv 3x3 --> ReLU–>64个conv 3x3–> ReLU --> 输出64个224×224特征图–> MaxPool 2x2 --> 输出 64个112x112;
(2)C2:3x3 —>128个conv 3x3 --> ReLU–>128个conv 3x3–> ReLU --> 输出128个112×112特征图–> MaxPool 2x2 --> 输出 128个56x56;
(3)C3:3x3 —>256个conv 3x3 --> ReLU–>256个conv 3x3–> ReLU --> 256个conv 3x3–> ReLU -->输出256个56×56特征图–> MaxPool 2x2 --> 输出 256个28x28;
(4)C4:3x3 —>512个conv 3x3 --> ReLU–>512个conv 3x3–> ReLU --> 512个conv 3x3–> ReLU -->输出512个28×28特征图–> MaxPool 2x2 --> 输出 512个14x14;
(5)C5:3x3 —>512个conv 3x3 --> ReLU–>512个conv 3x3–> ReLU --> 512个conv 3x3–> ReLU -->输出512个14×14特征图–> MaxPool 2x2 --> 输出 512个7x7;
(6)FC6 ---->7x7x512 展平77512一维向量–>输出4096个1x1–> ReLU --> Dropout;
(7)FC7 ----> 输入1x1x4096,输出1x1x4096–> ReLU --> Dropout
(8)FC8 ----> 输入1x1x4096,输出1x1x1000
(9)输出层—> 输入1x1x1000–>softmax -->输出 1000分类
整个VGGNet 16 D网络包含的参数数量为 138M个参数。
优势与不足
优势:采用小卷积核conv 3x3,增加卷积子层,网络深度从11层到19层,Maxpool 核缩小为2x2,特征通道更宽,全连接卷积,图像尺寸扩大224x224x3。
Pytorch实现
以下便是使用Pytorch实现的经典网络结构VGGNet16
class VGGNet16(nn.Module):
def __init__(self, num_classes, grayscale=False):
"""
num_classes: 分类的数量
grayscale:是否为灰度图
"""
super(VGGNet, self).__init__()
self.grayscale = grayscale
self.num_classes = num_classes
if self.grayscale: # 可以适用单通道和三通道的图像
in_channels = 1
else:
in_channels = 3
# 卷积神经网络
C1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
C2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
C3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
C4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
C5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.features = nn.Sequential(
C1,
C2,
C3,
C4,
C5
)
# 分类器
self.classifier = nn.Sequential(
nn.Linear(7*7*512, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096*1*1, 4096),
nn.ReLU()
nn.Dropout()
nn.Linear(4096, 1000)
)
def forward(self, x):
x = self.features(x) # 输出 特征图
x = torch.flatten(x, 1) # 展平
logits = self.classifier(x) # 输出
probas = F.softmax(logits, dim=1)
return logits, probas
大家可以和前面的对照差异,也可以一窥DeepLearning技术的突破点。
在VGGNet 是一大创举,DeepMind团队更闻名的是在围棋开创一片天地,AlphaGo风靡一时,把人工智能推向又一个高潮,CNN网络引领的深度学习蓬勃发展,造就人工智能技术革命的起点。
觉得有用 收藏 收藏 收藏
点个赞 点个赞 点个赞
End
深度学习
Caffe笔记:python图像识别与分类_python 怎么识别 caffe-CSDN博客
深度学习-Pytorch同时使用Numpy和Tensors各自特效-CSDN博客
深度学习-Pytorch运算的基本数据类型_pytorch支持的训练数据类型-CSDN博客
Python Faster R-CNN 安装配置记录_attributeerror: has no attribute 'smooth_l1_loss-CSDN博客
GPT专栏文章:
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
GPT实战系列-LangChain + ChatGLM3构建天气查询助手
GPT实战系列-大模型为我所用之借用ChatGLM3构建查询助手
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)