大学 数据分析 课程设计,2024年最新大数据开发开发两年
代码:p1% ggplot(aes(x=Gender,y=Purchase))+geom_boxplot()p1结果:代码:p2% ggplot(aes(x=City_Category,y=Purchase))+geom_boxplot()p2结果:代码:p3% ggplot(aes(x=as.factor(Marital_Status),y=Purchase,fill=Gender))+geom
- 对不同性别绘制箱线图:
代码:
p1<-bf %>% ggplot(aes(x=Gender,y=Purchase))+geom_boxplot()
p1
结果:

对不同城市绘制箱线图:
代码:
p2<-bf %>% ggplot(aes(x=City_Category,y=Purchase))+geom_boxplot()
p2
结果:

- 对消费者的婚姻状况绘制箱线图,我们分为男女两个方面:
代码:
p3<-bf %>% ggplot(aes(x=as.factor(Marital_Status),y=Purchase,fill=Gender))+geom_boxplot()
p3
结果:

从上面的3个箱形图中我们可以看出,男人在购物上花的钱比女人多。无论是是否结婚还是来自于不同城市,而且Age,Stay_In_Current_City_Years这两个变量本来应该保存成数字变量但是原始数据是使用字符型变量,所以需要我们进行进一步的处理。
统计年龄和所在城市的居住年份总数
我们使用年龄范围的平均值来代表每个阶段,可以看到各个年龄段出现的次数。然后我们根据Stay_In_Current_City_Years来统计消费者在当前城市停留最多的年数。
代码:

根据结果,我们可以发现:中年人(35-55岁)的比例最多;年轻人支付较少;就城市停留年数的统计数据看,停留一年的占大多数。
产品类别信息统计
首先我们通过用 table() 函数统计因子各水平的出现次数。可以看到:

共有18种产品,每种产品出现的次数各不相同。
针对不同的产品,我们通过对购买产品的数量、性别对产品的影响、价格对产品的影响三方面对数据进行分析,结果如下:
- 消费者最喜欢的产品类别:
代码:
p1<-bf %>% group_by(Product_Category_1) %>% count() %>% ggplot(aes(x=reorder(Product_Category_1,n),y=n))+geom_col(aes(factor(Product_Category_1)))+labs(x=“”,y=“”,title=“消费者最喜欢的产品类别”)
p1
结果:

- 不同性别各产品类别的喜爱程度
代码:
p2<-bf %>% group_by(Gender,Product_Category_1) %>% count() %>% ggplot(aes(x=as.factor(Product_Category_1),y=n,fill=as.factor(Gender)))+geom_bar(stat=“identity”,position=“dodge”)+labs(x=“”,y=“”,fill=“gender”,title=“不同性别各产品类别的喜爱程度”)
p2
结果:

- 各类别平均消费价格
代码:
p3<-bf %>% ggplot(aes(x=reorder(as.factor(Product_Category_1),Purchase),y=Purchase))+geom_point()+ggtitle(“各类别平均消费价格”)
p3
结果:

通过图像我们可以看到,消费者最喜欢的产品前三分别是5、1、8,男性消费者明显比女性多。
性别统计
由于每行代表一个单独的事务,我们必须首先按User_ID对数据进行分组以删除重复项。我们选择用户编号和性别两项,按照用户编号进行分组,运用distinct()去除重复项。
代码:
bf2 <- read.csv(“E:/data.csv”)
bf2_gender <- bf2 %>%
select(User_ID, Gender) %>%
group_by(User_ID) %>%
distinct()
head(bf2_gender)
summary(bf2_gender$Gender)
options(scipen=10000) # To remove scientific numbering
gender_ch <- ggplot(data = bf2_gender) +
geom_bar(mapping = aes(x = Gender, y = …count…)) +
labs(title = ‘性别分布’)
gender_ch
结果:

可以看到,在本次数据中,男性购买人数比女性购买人数多。
性别相关平均支出金额
代码:
total_P <- bf2%>%
select(User_ID, Gender, Purchase) %>%
group_by(User_ID) %>%
arrange(User_ID) %>%
summarise(Total_P= sum(Purchase))
user_G <- bf2%>%
select(User_ID, Gender) %>%
group_by(User_ID) %>%
arrange(User_ID) %>%
distinct()
head(user_G)
head(total_P)
user_P_G<-full_join(total_P, user_G, by = “User_ID”)
head(user_P_G)
avg_spending_G <- user_P_G %>%
group_by(Gender) %>%
summarize(Purchase = sum(as.numeric(Total_P)),
Count = n(),
Average = Purchase/Count)
head(avg_spending_G)
avg_gender <- ggplot(data =avg_spending_G) +
geom_bar(mapping = aes(x = Gender, y = Average, fill = Gender), stat = ‘identity’) +
labs(title = ‘不同性别的平均消费’) +
scale_fill_brewer(palette = ‘PuBuGn’)
avg_gender
结果:
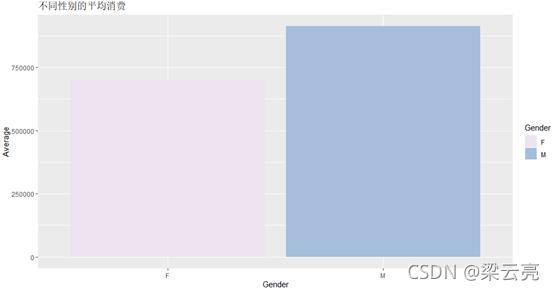
通过结果可以发现,即使女性购物者购买的商品少于男性,但他们的购买量几乎与男性购物者一样多。但是也要考虑规模因素,因为女性平均仍然比男性少花费25万。
畅销品
代码:
total_purchase= bf2 %>%
group_by(User_ID) %>%
summarise(Purchase_Amount= sum(Purchase))
top_sellers <- bf2 %>%
count(Product_ID, sort = TRUE)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
dl-1713019404068)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-LoPOyOoM-1713019404068)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)